截止到上一篇《PostgreSQL11 | 查询数据》属于pgsql的基础部分就算是都总结完了,从这一篇(第9章)开始一直到本专栏最后一篇文章(第14章)都是进阶部分,sql量会减弱,抽象的概念会越来越多,前面几章因为sql实操多,基本和原书一致,在后面的几章,原书的内容会大致缩减到一半,另一半会适宜的添加来源自己见解、b站视频、论坛文章和百度百科等多种渠道信息的总结。
索引
索引,在关系数据库中,索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
目录
索引
索引的用途
索引的组成
索引的特点
索引的结构
索引的种类
索引的设计原则
pgsql索引
创建索引
图形化创建索引
sql语句创建索引
重命名索引
图形化操作
SQL语句操作
删除索引
图形化操作
SQL语句操作
PostgreSQL 11 新特性 1——创建索引时支持INCLUDE方式
索引的用途
为数据库数据建立合适的索引可以加快查找数据的速度,在少量数据下,普通数据库和有索引的数据库的查询速度基本一样,但在庞大数量级的数据下,查找一条记录所耗费的时间则会有很大的差距。
比如下面这个来自b站的教学视频中所展示的

(原视频中是mysql数据库,我们只理解效果和原理)
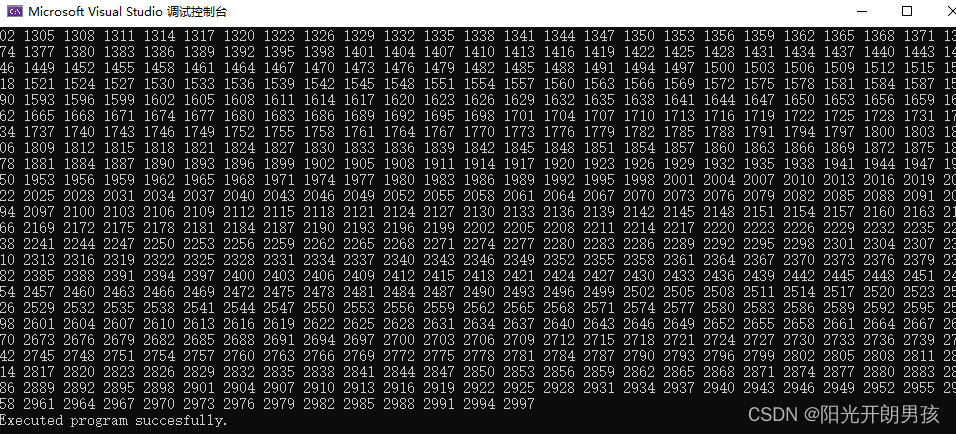
我们可以看到,在没有建立索引之前,查询第五百万条数据(庞大数据中的最后一条数据)所使用的时间是1.477s,而在建立索引后,所用时间仅需0.01s
那么也就是说,要想快,就需要建立一个合适的索引。不仅可以加快查询速度,还可以减少磁盘的i/o次数,因为数据在物理上也是连续的。
索引的组成
索引键值、对应的指针或rowid(指示存储位置)
索引的特点
为了快速查找,索引键值是有序的
优点:
- 通过创建唯一索引,可以保证数据库表中每一行数据的唯一性。
- 可以大大加快数据的查询速度。
- 加速表和表之间的连接。
- 在使用分组和排序子句进行数据查询时,可以有效减少分组和排序的时间。
缺点:
- 创建索引和维护索引要耗费时间。且随着数据量的增加而增加。
- 索引需要占用磁盘空间。
- 当表中的数据进行增加、删除或修改时,所以也要动态维护,降低了数据的维护速度。

从 图2 中也可以看出,为500w条数据创建索引,索引占用了 90,112kb 的空间。

而建立索引时,也耗费了 9.722s
索引的结构
为了实现对索引键值的快速查找,索引并不采用两列表结构
常用的结构:B+树、哈希hash、位图
B+树:适合处理那些能够按照顺序存储的数据
哈希hash:只能处理简单的等于比较
具体可以查看这篇文章
索引的种类
聚簇索引、非聚簇索引
聚簇索引:物理排序,在索引上按顺序,数据存放也按顺序排
非聚簇索引:逻辑排序,仅索引排序,数据无序存放
唯一值索引、非唯一值索引:索引键值是否允许重复
单列索引与复合索引:单列与多列
反键索引、函数索引、倒排索引....
索引的设计原则
索引设计不合理或者缺少索引都会对数据库和应用程序的性能造成障碍。
设计索引时,应该考虑以下准则:
- 索引并非越多越好,一个表中如有大量的索引,不但占用磁盘空间将增大,而且会影响 INSERT、DELETE、UPDATE 等语句的性能,因为当表中的数据更改的同时,索引也会进行调整和更新。
- 避免对经常更新的表进行过多的索引,并且索引中的列尽可能少。对经常用于查询的字段应该创建索引,但要避免添加不必要的字段。
- 数据量小的表最好不要使用索引,由于数据较少,查询花费的时间可能比遍历索引的时间还要短,索引可能不会产生优化效果。
- 在条件表达式中经常用到的不同值较多的列上建立检索,在不同值少的列上不要建立索引。如果建立索引,不但不会提高查询效率,反而会严重降低更新速度。
- 当唯一性是某种数据本身的特征时,指定唯一索引能够确保定义的列的数据完整性,提高查询速度。
- 在频繁进行排序或分组 (进行 GROUP BY或ORDER BY 操作)的列上建立索引如果待排序的列有多个,可以在这些列上建立组合索引。
pgsql索引
创建索引
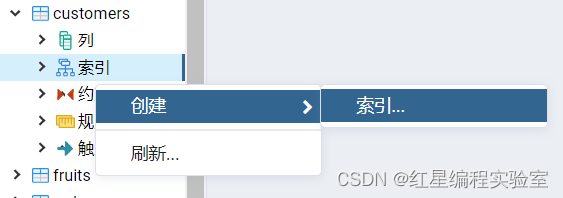
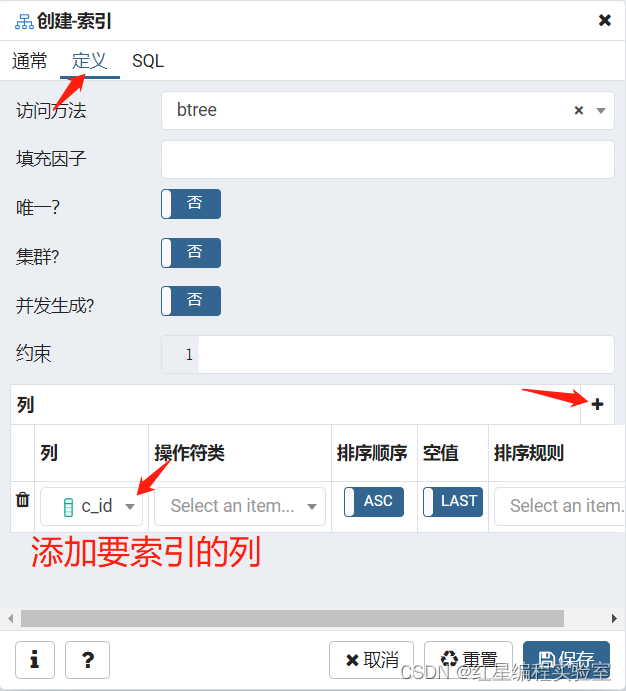
图形化创建索引
对于一个已建表创建索引,图形操作为:


sql语句创建索引
使用 CREATE INDEX 语句在已经存在的表中创建索引,基本语法结构为:
CREATE[UNIQUE|FULLTEXT|SPATIAL]INDEX index_name
ON table_name (col_name[length],...)[ASC | DESC]
在创建索引前,首先要创建数据表,SQL 语句如下:
create table book
(
bookid int not null,
bookname varchar(255) not null,
authors varchar(255) null,
info varchar(255) null,
comment varchar(255) null,
year_publication date not null
);
1.创建普通索引
只用于加快查询速度,没有唯一性约束的限制
例:在book表上的bookname字段建立名为bknameindex的普通索引
create index bknameindex on book(bookname);
2.创建唯一索引
用于减少查询索引列操作的执行时间,尤其是对于庞大的数据表。要求索引值必须的唯一的,允许有空值。
例:在 book 表的 bookId 字段上建立名称为 unigididx 的唯一索引,SQL语句如下:
create unique index uniqididx on book(bookid);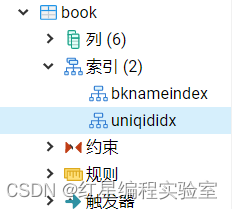
3.创建单列索引
单列索引是在书籍表中某一字段上创建的索引,一个表中可以创建多个单列索引。上面两个索引也是单列索引。
例:在 book 表的 comment 字段上建立单列索引,SQL 语句如下:
create index Bkcmtidx on book(comment);
4.创建组合索引
组合索引是在多个字段上创建一个索引
例:在 book 表的 authors 和 info 字段上建立组合索引,SQL 语句如下:
create index bkauandinfoidx on book(authors,info);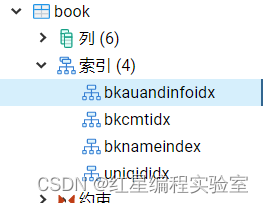
重命名索引
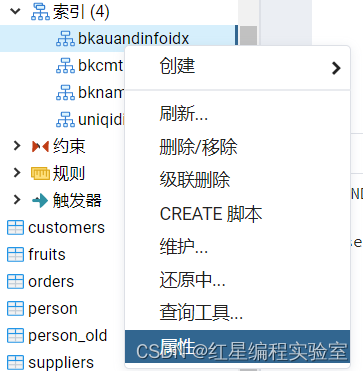
索引创建后可以根据需要对数据库中的索引进行重命名操作,常见的方法包括在对象浏览器中修改和使用SQL语句修改。
图形化操作
SQL语句操作
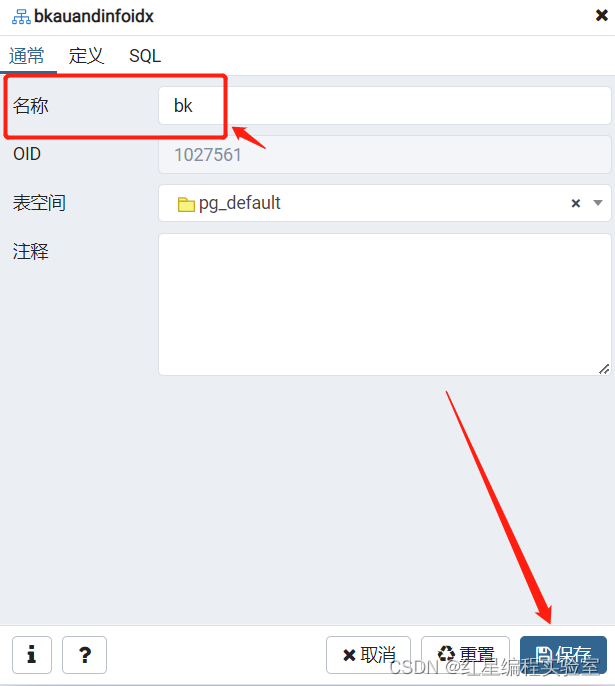
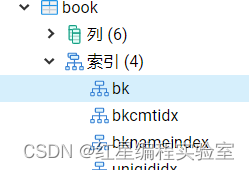
例:把上面修改的bk再重命名回去
alter index public.bk rename to bkauandinfoidx;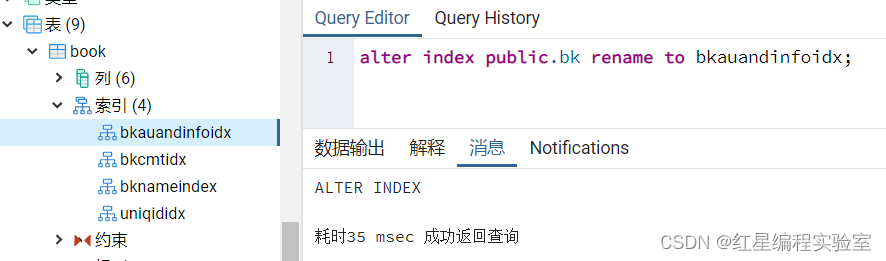
删除索引
图形化操作
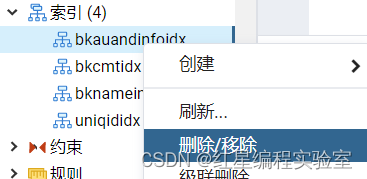
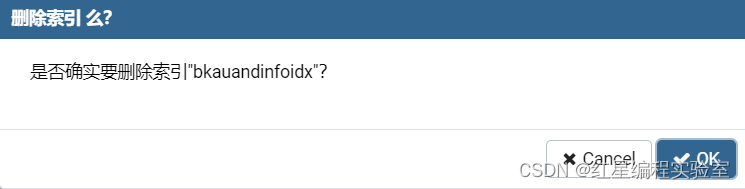

SQL语句操作
删除索引的格式为:
DROP INDEX index_name;
例:删除 book 表中名称为 bkauandinfoidx 的组合索引,SQL 语句如下:
drop index bknameindex;
PostgreSQL 11 新特性 1——创建索引时支持INCLUDE方式
有关 PostgreSQL 11 新特性 1——创建索引时支持INCLUDE方式 的相关内容请通过原教材《postgresql11从入门到精通》(清华大学出版社)第238页开始了解,PostgreSQL 11 新特性 2——执行并创建索引 在原书239页,综合案例—创建索引 在原书240页,常见问题及解答在原书242页,经典习题在原书242页,该部分作为自由了解范围请购买原著自行学习,感谢理解。
作者的话(Alvin):
本文根据原书《PostgreSql11 从入门到精通》(清华大学出版社)第9章总结整理,为提问与解答可以帮助更多人,本博客模拟GitHub的issue方案,所以私信已关,有问题请在评论区直接指正与提问,允许转发、复制或引用本文章,必须遵守开源法则注释来源与作者,感谢您的阅读
知识来源:
1.《PostgreSql11 从入门到精通》(清华大学出版社)第9章
2.【索引的使用】https://www.bilibili.com/video/BV1jR4y1o7jM?vd_source=6324e6978c492079d2e70fc2e94674d0
索引的使用
3.【数据库原理与应用——索引】https://www.bilibili.com/video/BV1hS4y1c7Uf?vd_source=6324e6978c492079d2e70fc2e94674d0
数据库原理与应用——索引
4.【【MySQL】燃到爆的索引讲解❁从未见过如此燃的技术类视频】https://www.bilibili.com/video/BV1sQ4y1K7tF?vd_source=6324e6978c492079d2e70fc2e94674d0
【MySQL】燃到爆的索引讲解❁从未见过如此燃的技术类视频
5.【数据库索引的结构】
https://blog.csdn.net/qq_16681169/article/details/50787624
数据库索引的结构