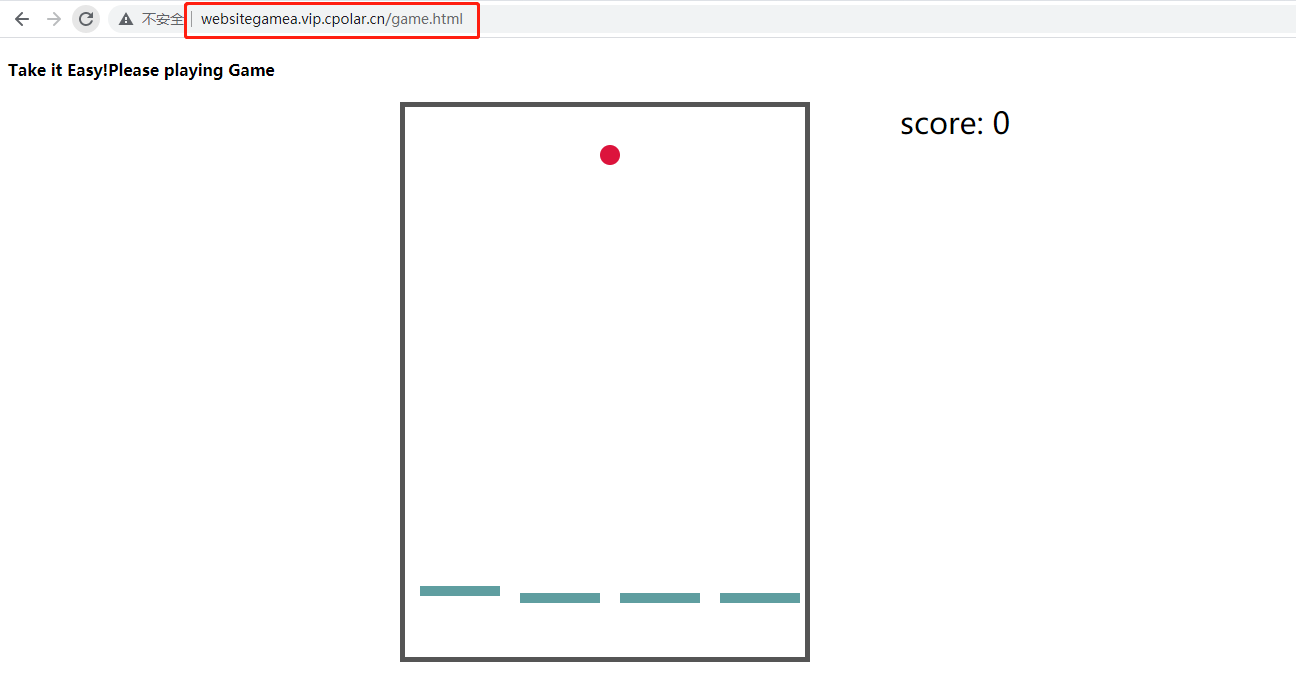
概述与简介
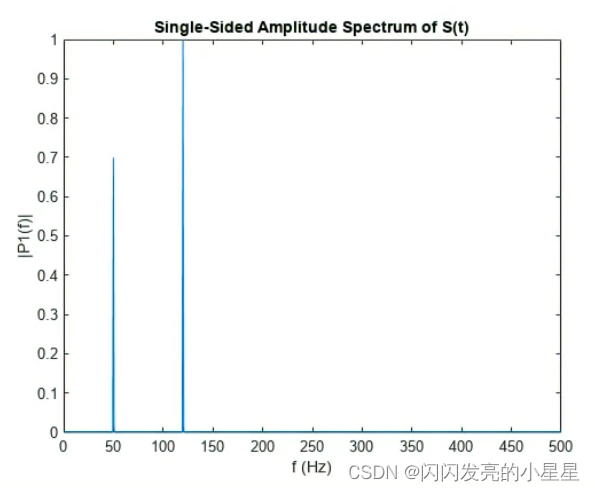
RT-DETR是一种实时目标检测模型,它结合了两种经典的目标检测方法:Transformer和DETR(Detection Transformer)。Transformer是一种用于序列建模的神经网络架构,最初是用于自然语言处理,但已经被证明在计算机视觉领域也非常有效。DETR是一种端到端的目标检测模型,它将目标检测任务转换为一个对象查询问题,并使用Transformer进行解决。RT-DETR采用了DETR的结构,但采用了一些优化措施,以实现实时目标检测。
在介绍RT-DETR之前,我们先来了解一下目标检测的基本概念。目标检测是计算机视觉领域的一个重要问题,它的目标是从图像或视频中检测出特定物体的位置和类别。在过去的几十年中,研究人员提出了许多目标检测方法,包括基于特征的方法、基于模板的方法、基于深度学习的方法等。其中,深度学习方法在最近几年中取得了很大的进展,尤其是基于卷积神经网络(CNN)的方法,如Faster R-CNN、YOLO、SSD等都已经取得了很好的效果。
当前目标检测存在问题
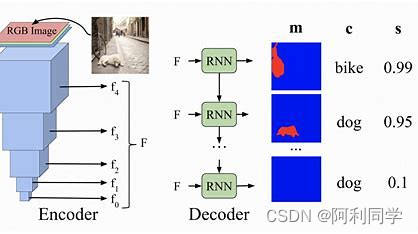
然而,这些方法都有一个共同的问题,那就是它们需要在图像的每个位置上进行计算,因此计算成本很高,不适合实时应用场景。为了解决这个问题,研究人员开始探索如何使用端到端的神经网络模型来实现目标检测。其中,DETR就是一种很有代表性的模型。
来源
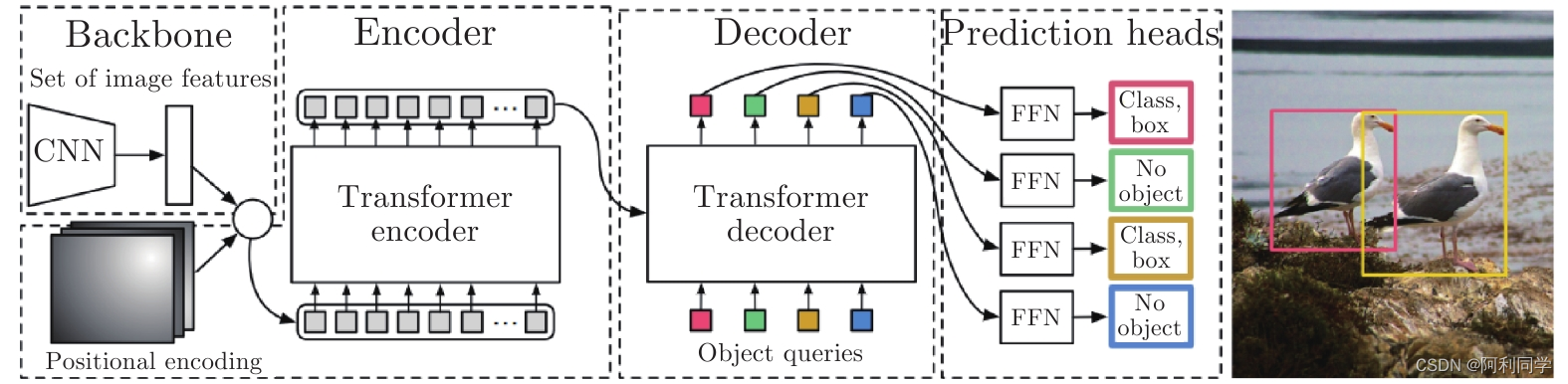
DETR是由Facebook AI研究团队提出的一种端到端的目标检测模型,它使用Transformer进行编码和解码。与传统的目标检测方法不同,DETR将目标检测问题转化为一个对象查询问题。具体来说,模型将图像中的每个像素位置视为查询向量,并使用Transformer编码器将其转换为一组特征向量。然后,模型使用一个解码器来预测每个对象的类别、边界框位置和对象特征向量,这些信息可以通过与查询向量的交互来获取。
DETR的优点
DETR的优点是它可以直接从图像中预测对象,而不需要通过预定义的锚框或候选框来进行检测。这种方法可以减少计算成本,并避免了由于不正确的框选导致的误检和漏检问题。此外,DETR还可以处理不同数量和大小的对象,并且可以直接输出对象特征向量,这些特征向量可以用于目标跟踪等后续任务。
然而,DETR的缺点是它的计算成本仍然很高,因此不适合实时应用场景。为了解决这个问题,研究人员开始探索如何对DETR进行优化,以实现实时目标检测。
原理
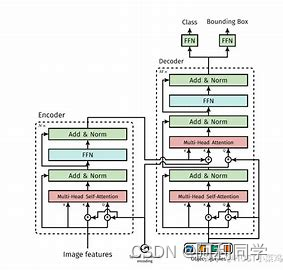
RT-DETR采用了与DETR相同的编码器和解码器结构,但对其进行了大量的优化。首先,RT-DETR使用了更小的特征图来减少计算成本。其次,RT-DETR使用更少的注意力头,以减少模型中的参数数量。此外,RT-DETR还引入了一种新的分组注意力机制,可以进一步提高性能。
具体来说,RT-DETR的编码器采用了ResNet50网络,但只保留了其前四个残差块,以减少特征图的大小。其解码器包括一个Transformer解码器和一个对象嵌入网络。与DETR不同的是,RT-DETR的Transformer解码器只有两个注意力头,而不是DETR的八个。此外,RT-DETR还使用了一种新的分组注意力机制,可以将注意力计算分为多个组,以提高计算效率。对象嵌入网络用于将每个对象的特征向量嵌入到模型中,以便进行后续的任务。
总结
RT-DETR的优点是它可以在保持较高精度的同时,实现实时目标检测,适用于许多应用场景,如自动驾驶、智能监控、机器人等。此外,RT-DETR还可以处理不同数量和大小的对象,并且可以直接输出对象特征向量,这些特征向量可以用于目标跟踪等后续任务。
总之,RT-DETR是一种非常有前景的实时目标检测模型,它结合了Transformer和DETR的优点,并采用了一系列优化措施,以实现实时目标检测。它已经在许多应用场景中得到了广泛的应用,并且随着计算硬件的不断提升,它的应用前景将会更加广阔。
部署
环境要求
cuda >= 11.7.1 ##联系方式qq1309399183
nccl >= 2.7
paddlepaddle-gpu >= 2.4.1
创建conda环境
conda create --name ppdet python=3.10
安装RT-DETR推荐的paddle版本
前往官网安装当前稳定的paddle版本[paddle-stable];
Clone项目代码
##联系方式qq1309399183
git clone -b develop \
https://github.com/PaddlePaddle/PaddleDetection.git