编译 | 于洲
今天我们介绍由Novartis集团的Novartis与德克萨斯大学达拉斯分校的Baris Coskunuzer为第一作者发表在NeurIPS 2022会议上的工作,文章介绍了一种新的虚拟筛选方法——ToDD模型,该方法使用了多参数持久性同调(MP)来生成化合物的拓扑指纹。与传统虚拟筛选方法使用规范分子表示不同,该方法生成的指纹是多维向量,利用原子亚结构的周期性特性在多个分辨率级别提取它们的持久同调特征。作者表明预训练的Triplet网络的边际损失微调在区分嵌入空间中的化合物和排名它们成为有效候选药物的可能性方面获得了极具竞争力的结果。这种方法生成的拓扑指纹为搜索与描述与药物发现和开发相关的化学空间提供了一种新方式,并发现使用MP签名增强下的ToDD 模型在基准数据集上达到了最先进的结果。

背景介绍
传统的虚拟筛选方法使用标准分子表示法,但面临着处理大规模虚拟化化合物数据时性能下降的问题。因此,本文为了解决以上问题,提出了一种新的方法——ToDD,利用多参数持久性同调算法生成多维向量的拓扑指纹,并利用原子亚结构的周期性属性提取它们在多个分辨率级别上的持久性同调特征。这种算法可以在预测的Triplet网络通过边界损失微调的方法中产生高竞争力的结果,用于区分化合物并排名其成为有效药物候选物的可能性。
本文的创新和贡献:
本文开发了一种革命性的方法来生成分子指纹。使用多持久性,本文为化合物产生高度表达和独特的拓扑指纹,而不依赖于规模和复杂性。这为描述和搜索与药物发现和开发相关的化学空间提供了一种新的方法。
本文为TDA中的多参数持久性带来了新的视角,并产生了计算效率高的化学数据多维指纹,可以成功地将多个域函数合并到PH过程中。这些MP指纹利用线性表示的计算能力,适合集成到广泛的ML、DL和统计方法中2;并为潜在拓扑信息的高效计算提取开辟了一条道路。
本文证明了多维持久性指纹具有与目前最现有的单个持久性摘要所展示的相同的重要稳定性保证。
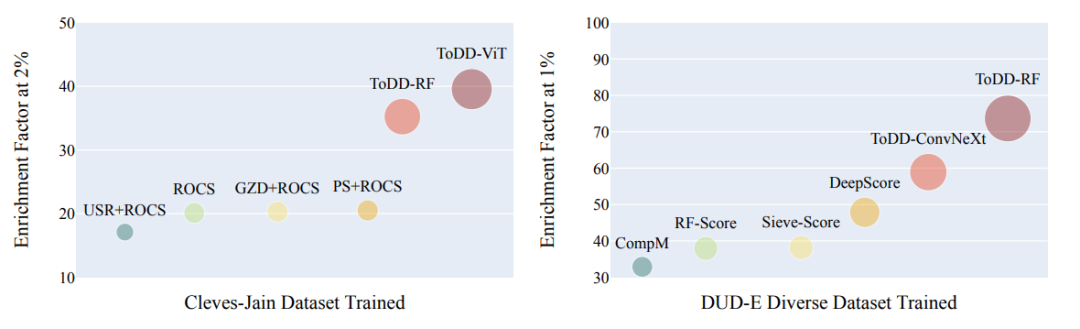
本文在VS中进行了大量的数值实验,表明ToDD模型在很大程度上优于所有最先进的方法。
方法介绍
ToDD框架通过扩展单持久性(SP)指纹,将化合物指纹生成为多维向量。虽然本文的结构适用于各种形式的数据,但在这里本文关注的是图形,特别是用于虚拟筛选的化合物。本文利用2或3个函数/权重(如原子质量、部分电荷、键类型、电子亲和能、电离能)对每个化合物进行图过滤,得到其指纹的二维矩阵(或3D数组)。本文的框架基本上是利用MP方法将给定的SP向量化扩展为多维向量。从技术上讲,通过使用现有的SP向量化,本文在多持久性模块中有效地使用其中一个过滤方向作为切片方向,从而生成多维向量。本文用两个步骤来解释本文的过程。
利用多维持久性同调,生成化合物的拓扑指纹。首先以双函数亚级双滤(sublevel bifiltration with 2 functions)的方法从给定的化合物中获得相关的子结构,然后为每一行(共有M行)获取持久化图,最后一步是在这些M个持久化图上进行向量化。具体而言,通过对化合物的原子亚结构的周期性属性进行分析,提取它们的持久同调特征,并在多个分辨率级别上产生拓扑指纹。
在图1和图2中,本文给出了化合物胞嘧啶通过原子序数和部分电荷函数的亚级双滤的例子:
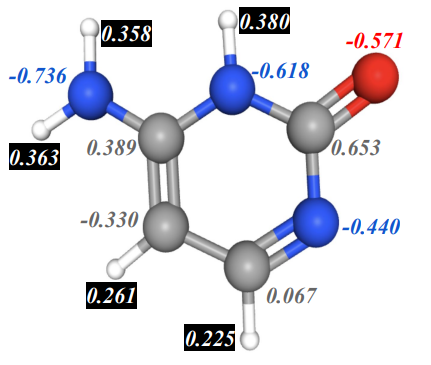
图1:胞嘧啶

图2:胞嘧啶的亚级双滤是由滤过函数的原子电荷f和原子序数g引起的。
使用预训练的Triplet网络,对产生的拓扑指纹进行边际损失微调,实现化合物的筛选和排名。通过这种方法,能够在处理大规模化合物数据集时,提高传统VS方法的性能。
实验介绍
数据集:本文实验采用了两个数据集进行测试:Cleves-Jain 数据集和 DUD-E Diverse 数据集。Cleves-Jain 数据集包含 1149 种化合物,其中共有 22 个药物靶点,每个靶点只有 2-3 种模板活性化合物用于模型训练,其余活性化合物用于模型测试。此外,数据集中还包含 850 种假药化合物作为 decoy。而 DUD-E Diverse 数据集则是一个综合性的配体数据集,涵盖了102个靶点和约150万种化合物。该数据集划分为 7 个类别,并针对每个类别选择了一个代表性的靶点集。DUD - E的“多样化子集”包含了每个类别的目标,为VS方法提供了一个平衡的基准数据集。不同的子集包含来自8个目标集和8个decoy集的116,105个化合物。每个目标使用一组decoy。在测试中,本文从每个靶点集中随机选择一个正样本,将其与相应的 decoy 集合并,构成测试集。两个数据集都是公认有效的测试数据集,能够用于评估虚拟筛选方法的性能。
实验过程:本文的实验过程包括以下几个方面。首先,文章使用的是MP(multiparameter persistence)同调算法来生成分子拓扑指纹。其次,选择了不同的机器学习模型进行计算,包括使用Triplet网络架构的ToDD-ViT和ToDD-ConvNeXt,以及使用随机森林(Random Forest)的ToDD-RF。实验中使用了Enrichment Factor和ROC-AUC分数来评估所有模型的性能表现。此外,作者在文章中还进行了对比实验来验证其结果的可靠性。在可解释性方面,作者还使用了Morgan指纹方法对其进行了量化分析。
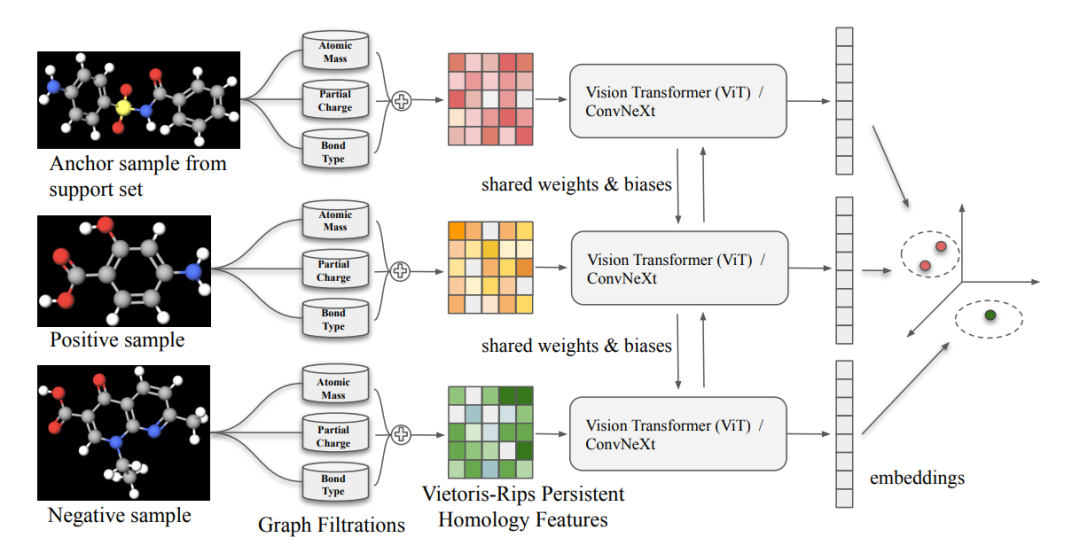
图3:端到端模型管道
实验结果:本文的实验结果证明了使用基于多参数持久化同调的拓扑化合物指纹作为虚拟筛选方法在计算辅助药物开发中具有非常高的竞争力。本文的方法可以生成多维化合物指纹的拓扑特征,从而实现了搜索和描述与药物发现和开发相关的化学空间的新方式。在各个基准数据集上,应用本文的方法可以实现前沿的结果,相对于其他虚拟筛选方法,ToDD模型可以在各个数据集和不同的EF 1% 水平上实现最佳性能。
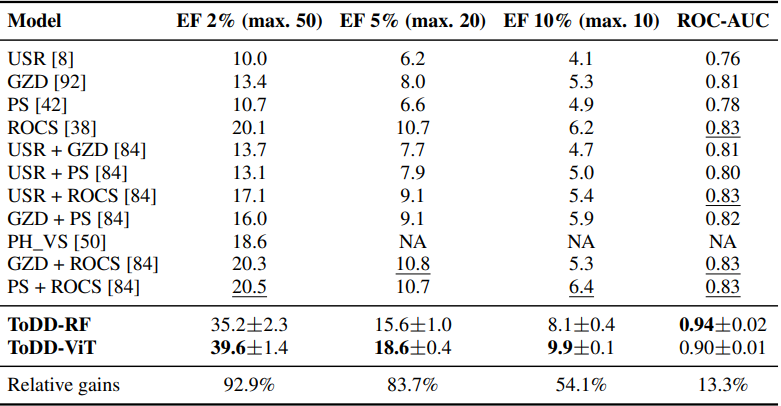
表1:Cleves-Jain数据集上ToDD与其他虚拟筛选方法EF 2%、5%、10%及ROC-AUC值的比较

表2:EF 1% (max. 100) ToDD与其他虚拟筛选方法在DUD- E多样性子集的8个目标上的差异
结论
本文提出了VS中的拓扑指纹的新想法,允许更深入地了解化合物的结构组织。本文已经在基准数据集上评估了ToDD方法在计算机辅助药物发现方面的预测性能。此外,本文已经证明了本文的拓扑描述符是模型不可知的,并已被证明是极具竞争力的,在所有基线上明确地产生最先进的结果。以不同的VS模式丰富ToDD模型,并将其应用于超大型虚拟复合库是未来的研究方向。这种捕获化合物化学信息的新方法为从药物发现的早期阶段到开发中配方的最后阶段的制药管道的各个层面提供了一个变革性的视角。
参考资料
Demir, A., Coskunuzer, B., Gel, Y., Segovia-Dominguez, I., Chen, Y. and Kiziltan, B., 2022. ToDD: Topological Compound Fingerprinting in Computer-Aided Drug Discovery. Advances in Neural Information Processing Systems, 35, pp.27978-27993.





![PCB制板基础知识[详细版]](https://img-blog.csdnimg.cn/img_convert/c71da814f301ed251107800d628a5cf3.png)