【YOLOv5改进系列】前期回顾:
【YOLOv5改进系列】前期回顾:
YOLOv5改进系列(0)——重要性能指标与训练结果评价及分析
YOLOv5改进系列(1)——添加SE注意力机制

目录
🚀一、CBAM注意力机制原理
1.1 CBAM方法介绍
1.2 通道注意力机制模块(CAM)
1.3 空间注意力机制模块(SAM)
🚀二、添加CBAM注意力机制方法(单独加)
2.1 添加顺序
2.2 具体添加步骤
第①步:在common.py中添加CBAM模块
第②步:在yolo.py文件里的parse_model函数加入类名
第③步:创建自定义的yaml文件
第④步:验证是否加入成功
第⑤步:修改train.py中 ‘--cfg’默认参数
🚀三、添加C3_CBAM注意力机制方法(在C3模块中添加)
第①步:在common.py中添加CBAMBottleneck和C3_CBAM模块
第②步:在yolo.py文件里的parse_model函数加入类名
第③步:创建自定义的yaml文件
第④步:验证是否加入成功
第⑤步:修改train.py中 ‘--cfg’默认参数

🚀一、CBAM注意力机制原理
论文题目:《CBAM: Convolutional Block Attention Module》
论文地址:https://arxiv.org/pdf/1807.06521.pdf
代码实现:CBAM.PyTorch
1.1 CBAM方法介绍
CBAM注意力机制是由通道注意力机制(channel)和空间注意力机制(spatial)组成。

在上一篇的SE中,我们学习了通道注意力机制(channel),而本篇的CBAM从通道channel 和 空间spatial 两个作用域出发,实现从通道到空间的顺序注意力结构。空间注意力可使神经网络更加关注图像中对分类起决定作用的像素区域而忽略无关紧要的区域,通道注意力则用于处理特征图通道的分配关系,同时对两个维度进行注意力分配增强了注意力机制对模型性能的提升效果。
1.2 通道注意力机制模块(CAM)
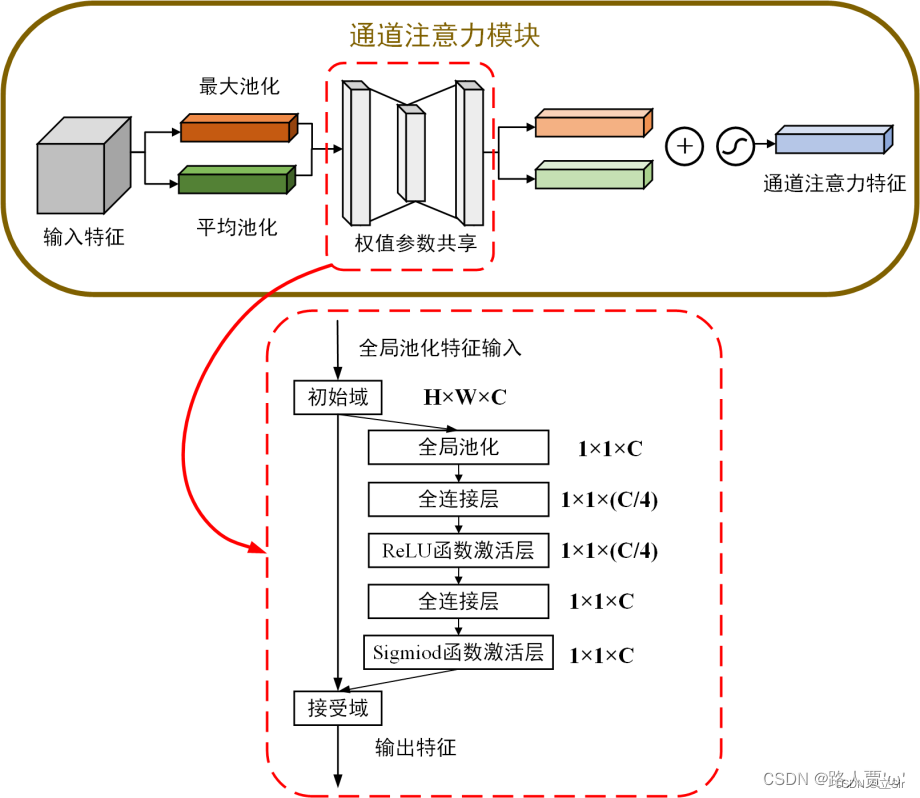
具体流程如下:
首先,将输入的特征图F(H×W×C)分别经过基于width和height的最大池化和平均池化,对特征映射基于两个维度压缩,得到两个1×1×C的特征图
接着,再将最大池化和平均池化的结果利用共享的全连接层(Shared MLP)进行处理,先通过一个全连接层下降通道数,再通过另一个全连接恢复通道数。
然后,将共享的全连接层所得到的结果进行相加再使用Sigmoid激活函数,进而生成最终的channel attention feature,即获得输入特征层每一个通道的权重(0~1之间)。
最后,将权重通过乘法逐通道加权到输入特征层上,生成Spatial attention模块需要的输入特征。
代码实现如下:
#(1)通道注意力机制
class channel_attention(nn.Module):
# 初始化, in_channel代表输入特征图的通道数, ratio代表第一个全连接的通道下降倍数
def __init__(self, in_channel, ratio=4):
# 继承父类初始化方法
super(channel_attention, self).__init__()
# 全局最大池化 [b,c,h,w]==>[b,c,1,1]
self.max_pool = nn.AdaptiveMaxPool2d(output_size=1)
# 全局平均池化 [b,c,h,w]==>[b,c,1,1]
self.avg_pool = nn.AdaptiveAvgPool2d(output_size=1)
# 第一个全连接层, 通道数下降4倍
self.fc1 = nn.Linear(in_features=in_channel, out_features=in_channel//ratio, bias=False)
# 第二个全连接层, 恢复通道数
self.fc2 = nn.Linear(in_features=in_channel//ratio, out_features=in_channel, bias=False)
# relu激活函数
self.relu = nn.ReLU()
# sigmoid激活函数
self.sigmoid = nn.Sigmoid()
# 前向传播
def forward(self, inputs):
# 获取输入特征图的shape
b, c, h, w = inputs.shape
# 输入图像做全局最大池化 [b,c,h,w]==>[b,c,1,1]
max_pool = self.max_pool(inputs)
# 输入图像的全局平均池化 [b,c,h,w]==>[b,c,1,1]
avg_pool = self.avg_pool(inputs)
# 调整池化结果的维度 [b,c,1,1]==>[b,c]
max_pool = max_pool.view([b,c])
avg_pool = avg_pool.view([b,c])
# 第一个全连接层下降通道数 [b,c]==>[b,c//4]
x_maxpool = self.fc1(max_pool)
x_avgpool = self.fc1(avg_pool)
# 激活函数
x_maxpool = self.relu(x_maxpool)
x_avgpool = self.relu(x_avgpool)
# 第二个全连接层恢复通道数 [b,c//4]==>[b,c]
x_maxpool = self.fc2(x_maxpool)
x_avgpool = self.fc2(x_avgpool)
# 将这两种池化结果相加 [b,c]==>[b,c]
x = x_maxpool + x_avgpool
# sigmoid函数权值归一化
x = self.sigmoid(x)
# 调整维度 [b,c]==>[b,c,1,1]
x = x.view([b,c,1,1])
# 输入特征图和通道权重相乘 [b,c,h,w]
outputs = inputs * x
return outputs1.3 空间注意力机制模块(SAM)

具体流程如下:
将上面CAM模块输出的特征图F’作为本模块的输入特征图。
首先,对输入特征图在通道维度下做最大池化和平均池化,将池化后的两张特征图在通道维度堆叠(concat)。
然后,经过一个7×7卷积(7×7比3×3效果要好)操作,降维为1个channel,即卷积核融合通道信息,特征图的shape从 [b,2,h,w] 变成 [b,1,h,w]。
最后,将卷积后的结果经过 sigmoid 函数对特征图的空间权重归一化,再将输入特征图和权重相乘。
代码实现如下:
#(2)空间注意力机制
class spatial_attention(nn.Module):
# 初始化,卷积核大小为7*7
def __init__(self, kernel_size=7):
# 继承父类初始化方法
super(spatial_attention, self).__init__()
# 为了保持卷积前后的特征图shape相同,卷积时需要padding
padding = kernel_size // 2
# 7*7卷积融合通道信息 [b,2,h,w]==>[b,1,h,w]
self.conv = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=kernel_size,
padding=padding, bias=False)
# sigmoid函数
self.sigmoid = nn.Sigmoid()
# 前向传播
def forward(self, inputs):
# 在通道维度上最大池化 [b,1,h,w] keepdim保留原有深度
# 返回值是在某维度的最大值和对应的索引
x_maxpool, _ = torch.max(inputs, dim=1, keepdim=True)
# 在通道维度上平均池化 [b,1,h,w]
x_avgpool = torch.mean(inputs, dim=1, keepdim=True)
# 池化后的结果在通道维度上堆叠 [b,2,h,w]
x = torch.cat([x_maxpool, x_avgpool], dim=1)
# 卷积融合通道信息 [b,2,h,w]==>[b,1,h,w]
x = self.conv(x)
# 空间权重归一化
x = self.sigmoid(x)
# 输入特征图和空间权重相乘
outputs = inputs * x
return outputs🚀二、添加CBAM注意力机制方法(单独加)
2.1 添加顺序
(1)models/common.py --> 加入新增的网络结构
(2) models/yolo.py --> 设定网络结构的传参细节,将CBAM类名加入其中。(当新的自定义模块中存在输入输出维度时,要使用qw调整输出维度)
(3) models/yolov5*.yaml --> 新建一个文件夹,如yolov5s_CBAM.yaml,修改现有模型结构配置文件。(当引入新的层时,要修改后续的结构中的from参数)
(4) train.py --> 修改‘--cfg’默认参数,训练时指定模型结构配置文件
2.2 具体添加步骤
第①步:在common.py中添加CBAM模块
将下面的CBAM代码复制粘贴到common.py文件的末尾
# CBAM
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu = nn.ReLU()
self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.f2(self.relu(self.f1(self.avg_pool(x))))
max_out = self.f2(self.relu(self.f1(self.max_pool(x))))
out = self.sigmoid(avg_out + max_out)
return out
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
# (特征图的大小-算子的size+2*padding)/步长+1
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 1*h*w
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
#2*h*w
x = self.conv(x)
#1*h*w
return self.sigmoid(x)
class CBAM(nn.Module):
def __init__(self, c1, c2, ratio=16, kernel_size=7): # ch_in, ch_out, number, shortcut, groups, expansion
super(CBAM, self).__init__()
self.channel_attention = ChannelAttention(c1, ratio)
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
out = self.channel_attention(x) * x
# c*h*w
# c*h*w * 1*h*w
out = self.spatial_attention(out) * out
return out
如下图所示:

第②步:在yolo.py文件里的parse_model函数加入类名
首先找到yolo.py里面parse_model函数的这一行
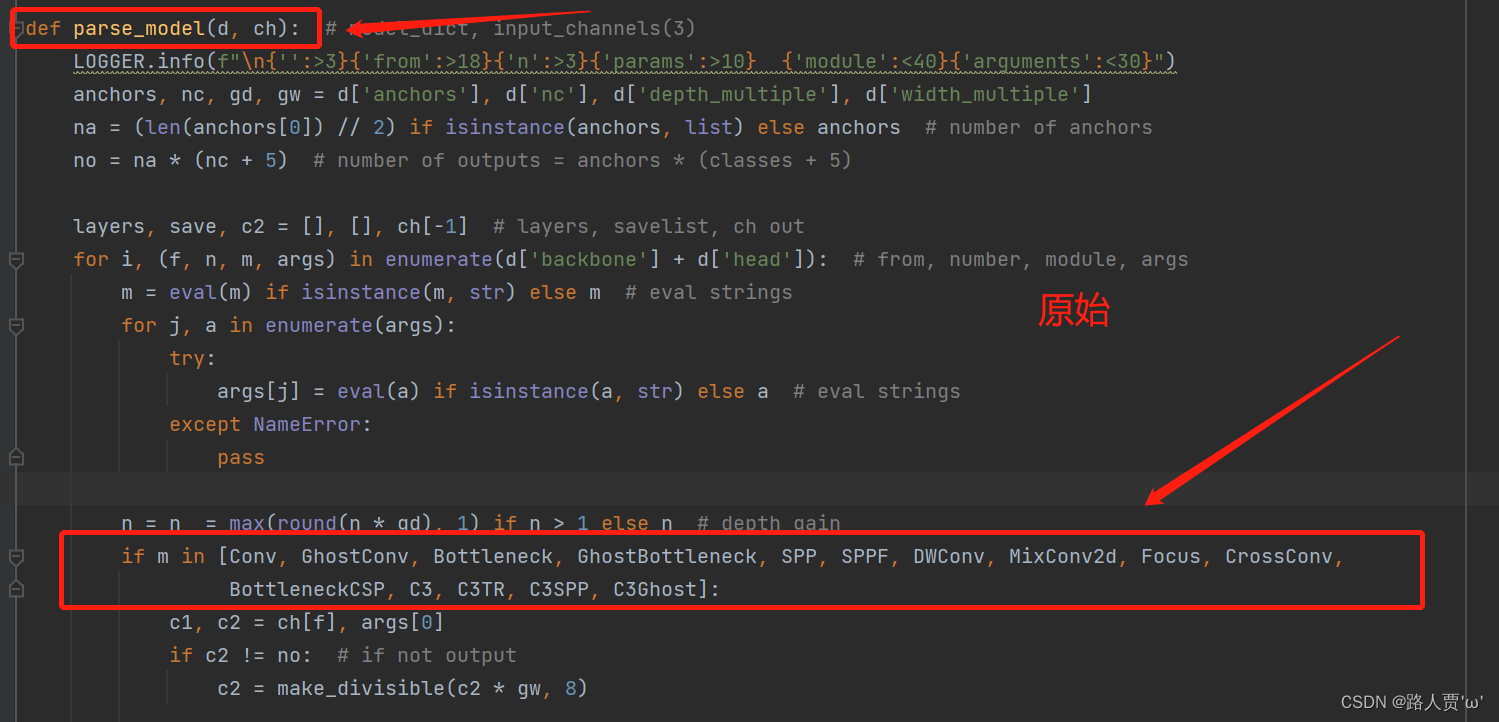
然后把CBAM添加到这个注册表里面

第③步:创建自定义的yaml文件
首先在models文件夹下复制yolov5s.yaml 文件,粘贴并重命名为 yolov5s_CBAM.yaml

接着修改 yolov5s_CBAM.yaml ,将CBAM模块加到我们想添加的位置。
注意力机制可以添加在backbone,Neck,Head等部分, 常见的有两种:一是在主干的 SPPF 前添加一层;二是将Backbone中的C3全部替换。
在这里我是用第一种:将 [-1,1,CBAM,[1024]]添加到 SPPF 的上一层,下一节使用第二种。即下图中所示位置:

同样的下面的head也得修改,p4,p5以及最后detect的总层数都得+1
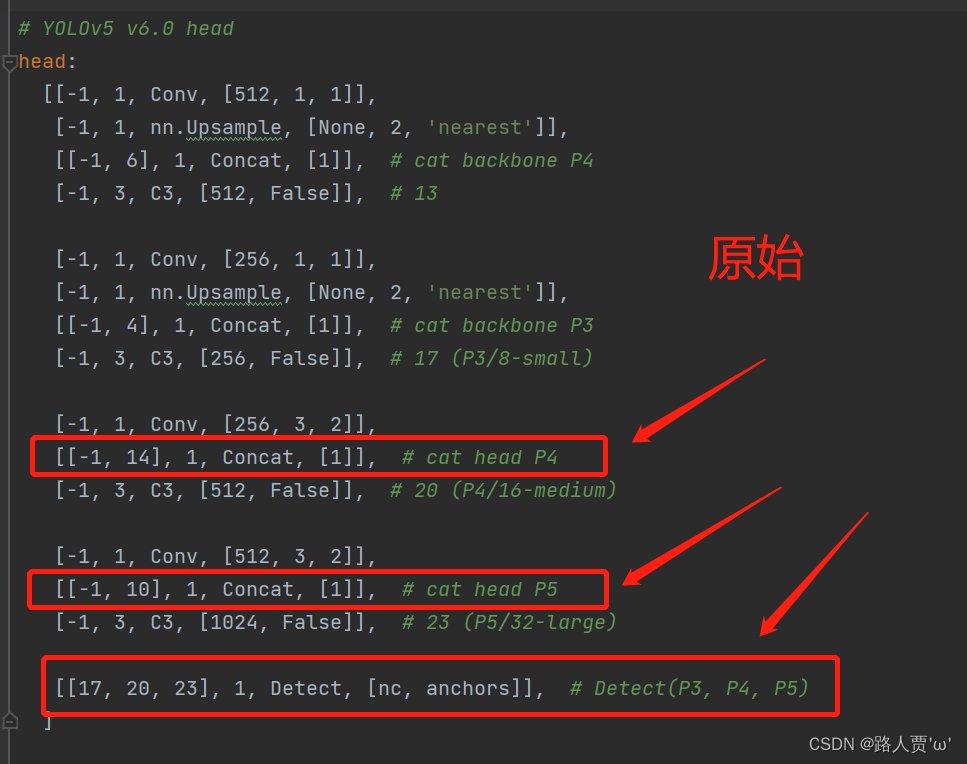
这里我们要把后面两个Concat的from系数分别由[ − 1 , 14 ] , [ − 1 , 10 ]改为[ − 1 , 15 ] , [ − 1 , 11 ]。然后将Detect原始的from系数[ 17 , 20 , 23 ]要改为[ 18 , 21 , 24 ] 。
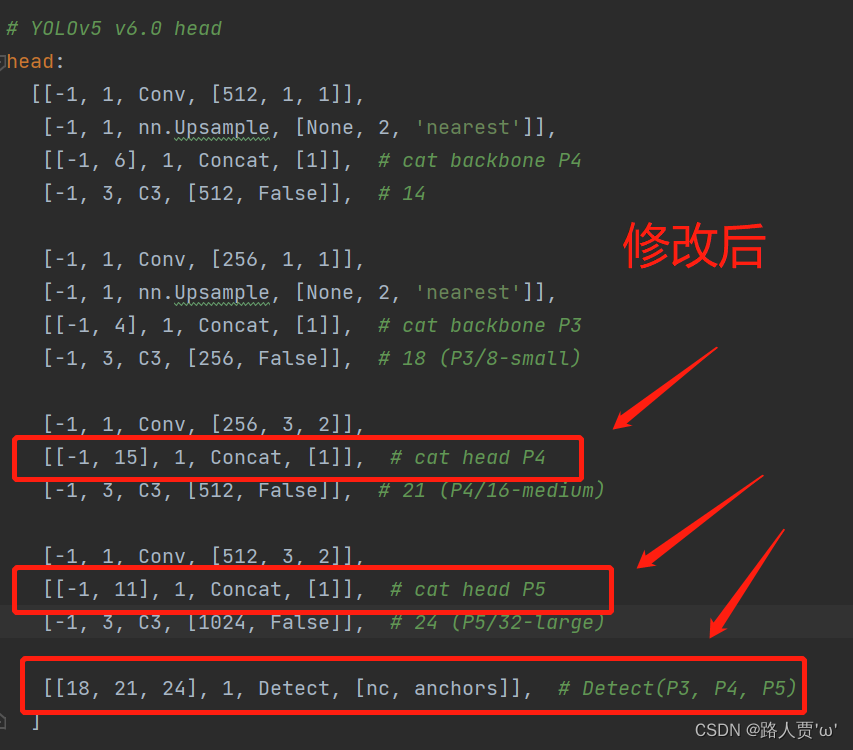
第④步:验证是否加入成功
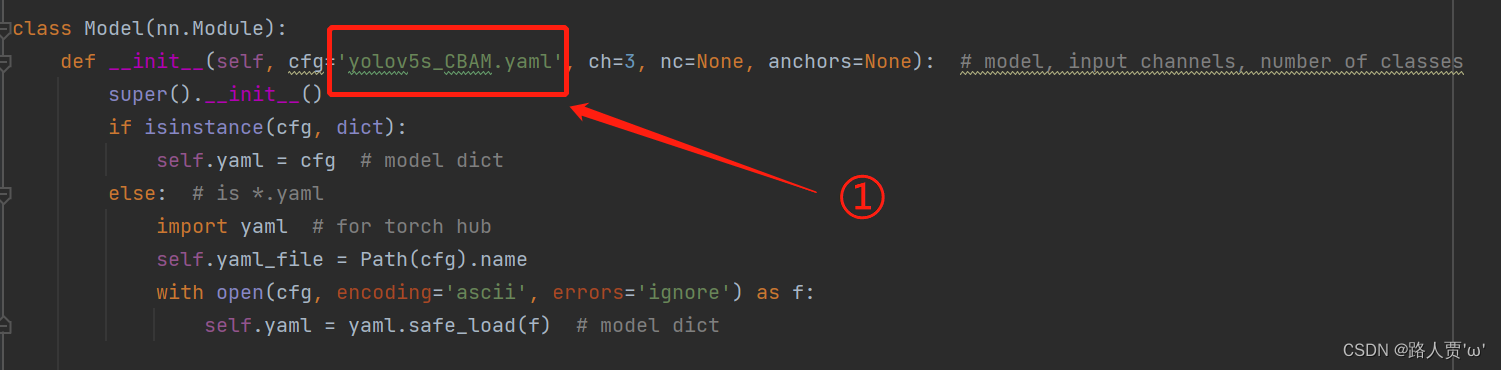
在yolo.py 文件里面配置改为我们刚才自定义的yolov5s_CBAM.yaml
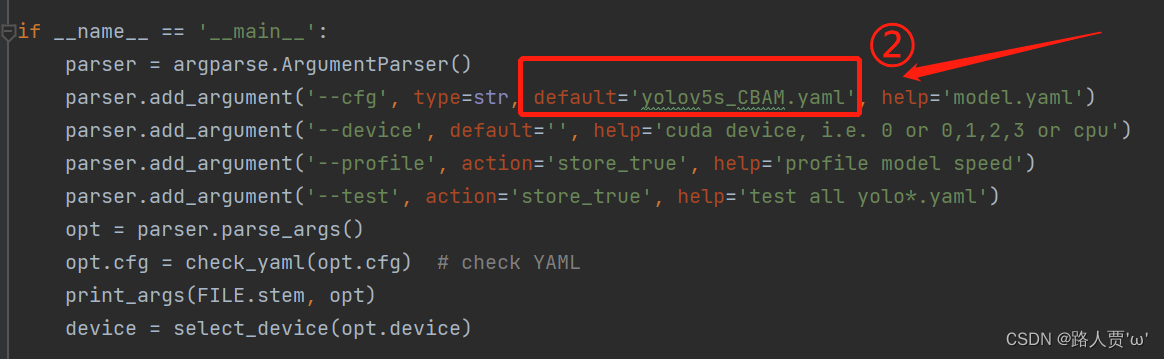
然后运行yolo.py
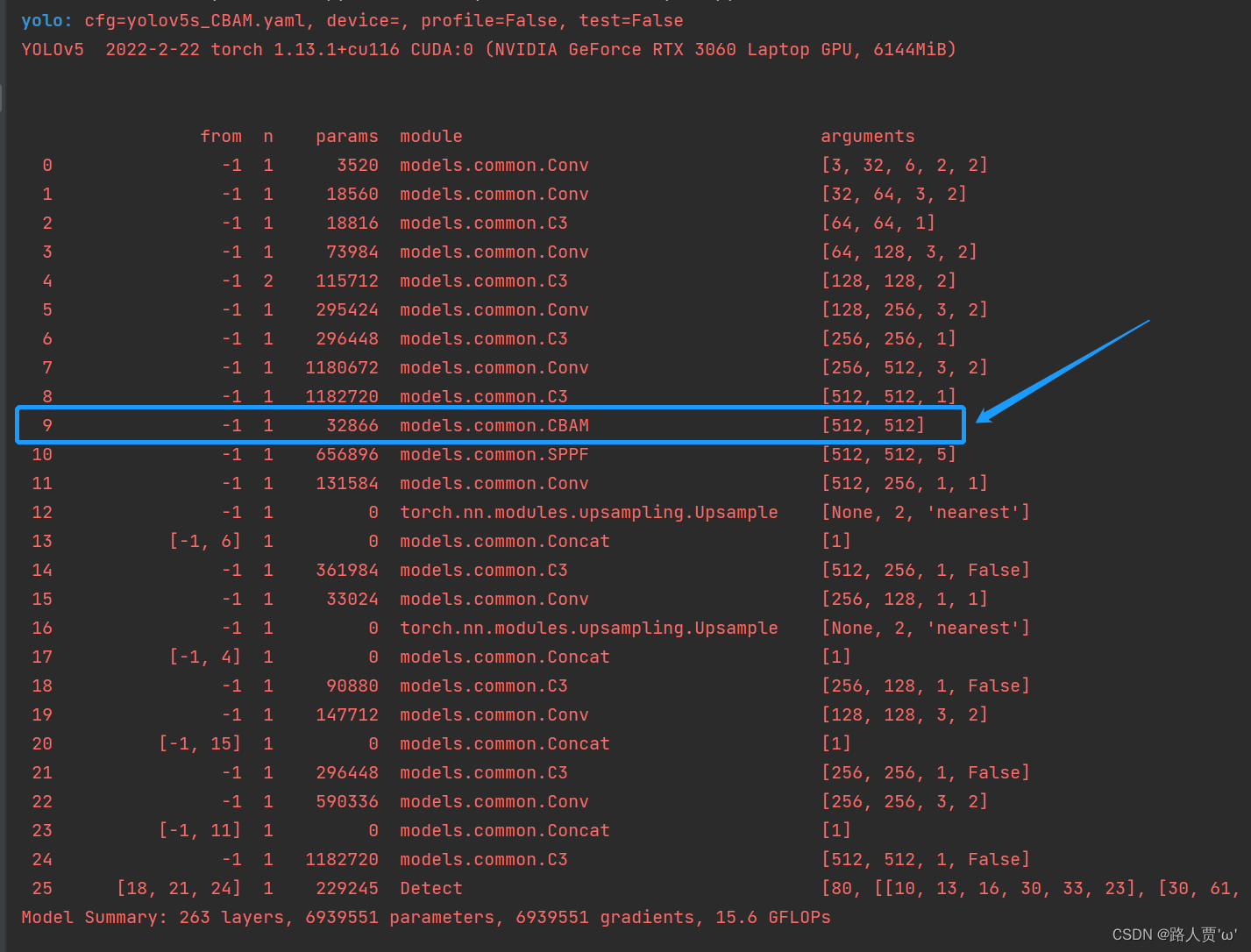
找到CBAM这一层,就说明我们添加成功啦!
第⑤步:修改train.py中 ‘--cfg’默认参数
我们先找到 train.py 文件的parse_opt函数,然后将第二行‘--cfg’的 default改为'models/yolov5s_CBAM.yaml',然后就可以开始训练啦~

🚀三、添加C3_CBAM注意力机制方法(在C3模块中添加)
上面是单独加注意力层,接下来的方法是在C3模块中加入注意力层。
刚才也提到了,这个策略是将CBAM注意力机制添加到Bottleneck,替换Backbone中的所有C3模块。
(因为步骤和上面相同,所以接下来只放重要步骤噢~)
第①步:在common.py中添加CBAMBottleneck和C3_CBAM模块
将下面的代码复制粘贴到common.py文件的末尾
# CBAM
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu = nn.ReLU()
self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.f2(self.relu(self.f1(self.avg_pool(x))))
max_out = self.f2(self.relu(self.f1(self.max_pool(x))))
out = self.sigmoid(avg_out + max_out)
return out
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
# (特征图的大小-算子的size+2*padding)/步长+1
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 1*h*w
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
#2*h*w
x = self.conv(x)
#1*h*w
return self.sigmoid(x)
class CBAMBottleneck(nn.Module):
# ch_in, ch_out, shortcut, groups, expansion, ratio, kernel_size
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5, ratio=16, kernel_size=7):
super(CBAMBottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
# 加入CBAM模块
self.channel_attention = ChannelAttention(c2, ratio)
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
# 考虑加入CBAM模块的位置:bottleneck模块刚开始时、bottleneck模块中shortcut之前,这里选择在shortcut之前
x2 = self.cv2(self.cv1(x)) # x和x2的channel数相同
# 在bottleneck模块中shortcut之前加入CBAM模块
out = self.channel_attention(x2) * x2
# print('outchannels:{}'.format(out.shape))
out = self.spatial_attention(out) * out
return x + out if self.add else out
class C3_CBAM(C3):
# C3 module with CBAMBottleneck()
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
self.m = nn.Sequential(*(CBAMBottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
第②步:在yolo.py文件里的parse_model函数加入类名
在yolo.py的parse_model函数中,加入CBAMBottleneck, C3_CBAM这两个模块

第③步:创建自定义的yaml文件
按照上面的步骤创建yolov5s_C3_CBAM.yaml文件,替换4个C3模块

# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3_CBAM, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3_CBAM, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 3, C3_CBAM, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3_CBAM, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]第④步:验证是否加入成功
在yolo.py 文件里面配置改为我们刚才自定义的yolov5s_C3_CBAM.yaml,然后运行

这样就OK啦~
第⑤步:修改train.py中 ‘--cfg’默认参数
接下来的训练就和上面一样,不再叙述啦~
完结~撒花✿✿ヽ(°▽°)ノ✿
PS:加入不同的位置效果不同,这两个我各训练100轮看了下效果,对于我的数据集来说,第2种比第1种mAP增加0.009。
🌟本人YOLOv5系列导航
🍀YOLOv5源码详解系列:
YOLOv5源码逐行超详细注释与解读(1)——项目目录结构解析
YOLOv5源码逐行超详细注释与解读(2)——推理部分detect.py
YOLOv5源码逐行超详细注释与解读(3)——训练部分train.py
YOLOv5源码逐行超详细注释与解读(4)——验证部分val(test).py
YOLOv5源码逐行超详细注释与解读(5)——配置文件yolov5s.yaml
YOLOv5源码逐行超详细注释与解读(6)——网络结构(1)yolo.py
YOLOv5源码逐行超详细注释与解读(7)——网络结构(2)common.py
🍀YOLOv5入门实践系列:
YOLOv5入门实践(1)——手把手带你环境配置搭建
YOLOv5入门实践(2)——手把手教你利用labelimg标注数据集
YOLOv5入门实践(3)——手把手教你划分自己的数据集
YOLOv5入门实践(4)——手把手教你训练自己的数据集
YOLOv5入门实践(5)——从零开始,手把手教你训练自己的目标检测模型(包含pyqt5界面)
本文参考(感谢大佬们):
b站:【YOLOv5 v6.1添加SE,CA,CBAM,ECA注意力机制教学,即插即用】
CSDN: 【深度学习】(1) CNN中的注意力机制(SE、ECA、CBAM)_立Sir的博客-CSDN博客
(强推) 手把手带你YOLOv5 (v6.1)添加注意力机制(二)(在C3模块中加入注意力机制)_迪菲赫尔曼的博客-CSDN博客