文章目录
- 数据结构
- 时间复杂度、空间复杂度
- 包装类、装箱与拆箱
- 泛型
- 擦除机制
数据结构
当我们在成为一名程序员的这条道路上努力的时候,我们一定经常听到这个词数据结构。那么究竟什么是数据结构呢?数据结构顾名思义,就是数据+结构,数据就是数据,结构就是用来描述或者组织数据的,为什么会有那么多种的数据结构呢?是因为日常生活中的场景是多变的,那么我们组织数据描述数据的方式也应该是多变的,所以才会有这么多的数据结构来支持我们组织数据。现在我们还不能学习数据结构,因为有一些前置的知识我们还没有学习,那么下面我们就来了解一下这些前置知识吧!
时间复杂度、空间复杂度
使用数据结构组织数据,那么如何衡量组织的好坏呢?这里我们又要引入一个词——算法,数据结构和算法是相辅相成的,那么如何衡量算法的好坏,我们就需要考虑算法的效率问题,这时我们就好考虑算法的时间复杂度、空间复杂度。
时间复杂度:
简单一点说,时间复杂度就是在一个算法中代码的执行次数。专业一点来说,算法的时间复杂度是一个数学函数,定量描述了该算法的运行时间,运算时间与其中语句的执行次数成正比。
如何描述时间复杂度,时间复杂度怎么算呢?我们使用大O渐进法。
大O渐进法规则
1、用常数1取代运行时间中的所有加法常数
2、在修改后的运行次数函数中,只保留最高阶项
3、如果最高阶存在并且不是1,则去除与这个项目相乘的常数。
4、执行完前面三部,就得到了大O阶
因为不可能每个算法我们都在计算机上执行一下计算一下执行时间,所以我们说的时间复杂度只是粗略的计算代码的执行时间,所以才有了大O渐进法规则,去掉了那些影响不大的杂项。光说无用,下面我们来上手计算一个时间复杂度:
首先看这样一个代码:
public static void bubble_sort(int[] arr) {
for(int i = 0; i < arr.length - 1;i++ ) {
for(int j = 0;j < arr.length - i - 1;j++) {
if(arr[j] > arr[j + 1]) {
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
这个代码的时间复杂度怎么算呢?我们可以将arr.length 看做n,那么最外层循环需要执行的次数就是n - 1次,内层循环每次执行的次数n -1、n - 2 ...... 1,是一个等差数列,那么要求这个算法的时间复杂度就是求他代码的执行次数,也就是要求n -1、n - 2 ...... 1这个等差数列的前n项和,之后再通过大O渐进法进行化简,所以通过计算我们可以得出:该算法的时间复杂度为O(n^2)。
public static int binarySearch(int[] arr,int num) {
int left = 0;
int right = arr.length - 1;
while(left <= right) {
int mid = (right - left)/2 + left;
if(arr[mid] > num) {
right = mid - 1;
}else if(arr[mid] < num) {
left = mid + 1;
}else {
return mid;
}
}
return -1;
}
上面这个算法的时间复杂度怎么算呢?我们光看代码是看不出来的,计算时间复杂度不只需要看代码还需要结合思想,我们通过读代码发现这是一个二分查找,我们需要结合他的思想找到相应的规律计算出代码的执行次数:二分查找每一次查找会舍弃一半的数据,当我们只有两个数据的时候,我们需要查找的次数为两次,第一次舍弃一半的数据,第二次找到数据。当有4个数据的时候,我们需要查找3次,第一次舍弃两个数据,第二次舍弃一个数据,最后找到数据,当有八个数据的时候,我们需要查找4次。我们把我们获取到的数据放在一个表格当中:
| 数据个数 | 查找次数 |
|---|---|
| 2 | 2 |
| 4 | 3 |
| 8 | 4 |
| n | ??? |
通过观察数据我们总结出了一个公式:2^(2-1) = 2、2^(3-1) = 4 、2^(4-1) = 8也就是说2^(查找次数 - 1) = 数据个数所以我们可以算出n个数据时的查找次数并且是使用大O渐进法化简后为:O(logN)
空间复杂度:
空间复杂度是对一个算法再运行过程中临时占用存储空间的大小的量度。空间复杂度算的是变量的个数,空间复杂度也跟时间复杂度类似,也用大O渐进法。
因为大多时候判断算法的效率还是计算时间复杂度,所以这里我们只简单提一下空间复杂度:我们来看这个代码:
public static long factoral(int n) {
return n < 2 ? n : factoral(n - 1)*n;
}
他的空间复杂度是多少呢?因为每一次递归都会开辟内存空间-栈帧,每个栈帧中都用一个常量,所以空间复杂度为O(n)
包装类、装箱与拆箱
在Java中我们说一切皆对象,难道基本数据类型也是对象嘛?虽然他们不是对象,但Java中为每个基本数据类型提供了包装类。
| 基本数据类型 | 包装类 |
|---|---|
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| char | Character |
| boolean | Boolean |
public static void main(String[] args) {
int num = 1;
Integer i = Integer.valueOf(num);
Integer i2 = new Integer(num);
int num2 = i.intValue();
System.out.println(i + " " + i2+ " " + num2);
}
上图就是装箱和拆箱的操作,我们发现很复杂,为了简便我们代码的编写Java为我们提供了自动装箱和自动拆箱的操作。
public static void main(String[] args) {
Integer i = 10;
int num = i;
}
这样也可以实现装箱和拆箱的操作。了解完装箱和拆箱我们来看一道面试题:
public static void main(String[] args) {
Integer a = 127;
Integer b = 127;
Integer c = 128;
Integer d = 128;
System.out.println(a == b);
System.out.println(c == d);
}
上面这行代码的输出的结果什么呢?兄弟们可能会觉得包装类是引用数据类型,所以==比较的是引用指向对象的地址,所以abcd都不相同,输出两个false结果真的是这样嘛?

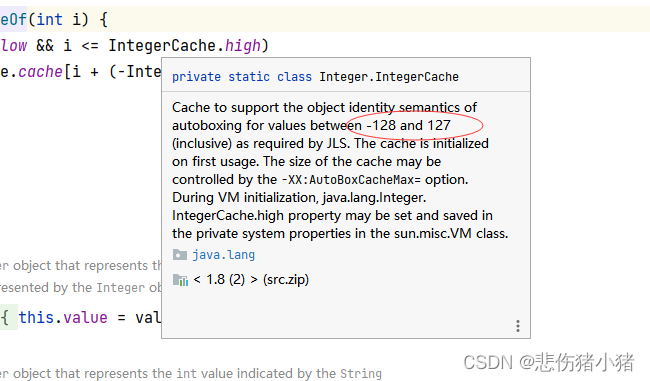
结果和我们所推测的并不相同,这是为什么呢?在自动装箱时同样会调用Integer类的valueOf()方法,所以我们去看看源码的逻辑是怎样的

当我们的形参在这个IntegerCache.low IntegerCache.high之间就不会new一个新对象,而超过这个范围的数据就需要重新new一个对象。所以 Integer a = 127; Integer b = 127;并没有重新创建对象,所以a == b输出的true。
泛型
package demo1;
class Myarray {
public String[] array = new String[3];
public int[] array1 = new int[3];
public String getArray(int pos) {
return array[pos];
}
public void setArray(String array,int pos) {
this.array[pos] = array;
}
public int getArray1(int pos) {
return this.array1[pos];
}
public void setArray1(int array1,int pos) {
this.array1[pos] = array1;
}
}
public class Test {
public static void main(String[] args) {
Myarray myarray = new Myarray();
myarray.setArray("abc",0);
myarray.setArray1(10,0);
System.out.println(myarray.getArray(0));
System.out.println(myarray.getArray1(0));
}
}
我们来看上面的这个代码,我们发现这样创建数组非常的麻烦,每个类型的数组都要写一份get set方法。我们可不可以写一个数组让他可以存储任意类型的数据呢?在之前我们提到了装箱和拆箱的概念,所有基本类型都又对应的包装类,而在Java中所有类的父类是Object类,我们可不可以使用Object去创建数组呢?
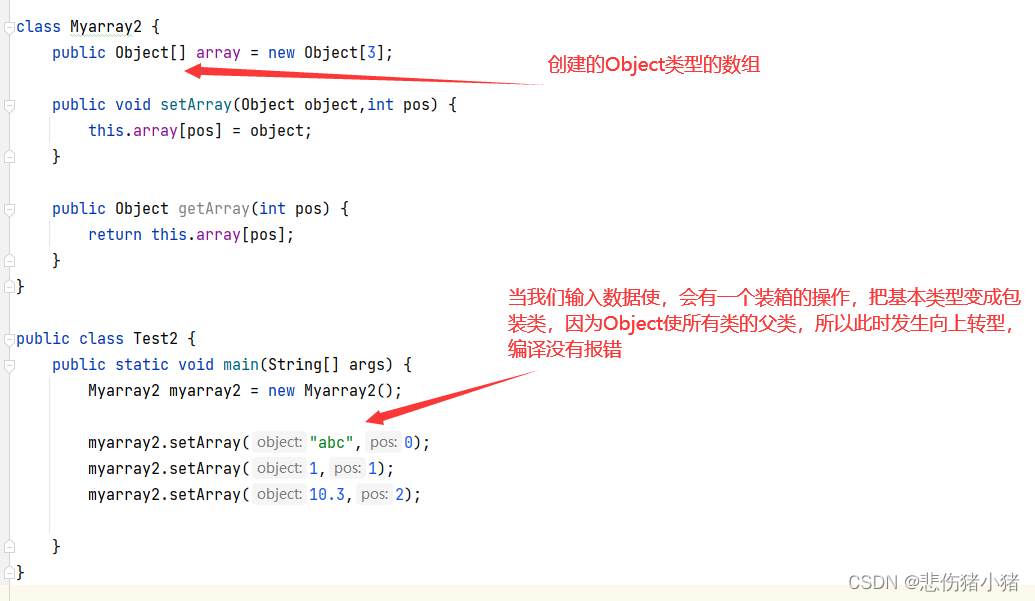
虽然我们在存储数据时编译通过了并没有报错,但是当我们去访问数据时,编译报错,原因如下图。

所以这样非常不好,因为如果数组中有非常多的元素,难道我需要记住所有元素的类型嘛?显然是不现实的,那如何解决问题呢?所以泛型就要出场了,泛型的主要目的:就是指定当前的容器,要持有什么类型的对象,让编译器去做检查。
泛型的语法:
创建:
class 泛型类名称<类型参数列表> { }
使用:
泛型类<类型参数>变量名 = new 泛型类<类型实参>(构造方法);
我们可以对上面的代码进行修改:
package demo2;
import java.util.Arrays;
class Myarray<T> {
public T[] array = (T[])new Object[3];
public void setArray (T t,int pos) {
this.array[pos] = t;
}
public T getArray (int pos ) {
return this.array[pos];
}
@Override
public String toString() {
return "Myarray{" +
"array=" + Arrays.toString(array) +
'}';
}
}
public class Test {
public static void main(String[] args) {
Myarray<Integer> myarray = new Myarray<>();
myarray.setArray(10,0);
myarray.setArray(20,1);
System.out.println(myarray);
Myarray<String> myarray1 = new Myarray<>();
myarray1.setArray("abc",0);
myarray1.setArray("def",1);
System.out.println(myarray1);
}
}
这样我们就可以实现我们的需求了。
擦除机制
说了这么多,泛型类究竟是如何编译的呢?我们去看一看源码:
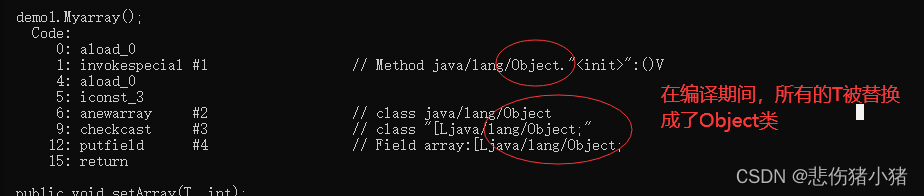
我们发现在编译的过程中所有的泛型T被替换成了Object类,这种机制我们称为:擦除机制,运行时既然没有泛型的概念,那泛型究竟起了什么作用呢?
泛型的作用:
1、储存数据的时候,可以帮助我们进行自动的类型转换。
2、在读取元素时,可以帮助我们进行类型转换。
3、泛型可以将数据类型参数化,进行传递。

那么既然所有的T都会被替换为Object我们在创建数组时public T[] array = (T[])new Object[3];这个语句是否完美呢?我们是不是可以直接public Object[] array = new Object[3];

泛型其实是一个比较复杂的语法,我们现在只进行简单的了解,在之后的学习中我们还需要把他拿出来进行讲解。
![[附源码]计算机毕业设计JAVA校园快递管理系统](https://img-blog.csdnimg.cn/1c129fa6d5eb411fa0be419bde6c0b90.png)





![[附源码]计算机毕业设计JAVA闲置物品线上交易系统](https://img-blog.csdnimg.cn/bbd4bc35d2be4b5a9d7097e291a67326.png)

![L. Paid Leave(贪心)[CCPC Finals 2021]](https://img-blog.csdnimg.cn/6506b439fac14d668f9eadd877d23f9d.png)


![[附源码]计算机毕业设计JAVA鲜花销售管理系统](https://img-blog.csdnimg.cn/e7ce9c3ed2d14927a43ef29b58df40ec.png)