文章目录
1.将下面字典创建为DataFrame 2.提取含有字符串“python”的行 3.输出df所有列名 4.修改第列名 5.统计grame列中每种编程语言出现的次数 6 将空值用上下值的平均值填充 7 列值大于3的数 8 去重列 9 计算列平均值 10 将列转换列表 11 保存到excel 12 查询行列 13 列值大于3小月7的值 14 交换两列位置 15 列值最大所在行 16 查最后5行数据 17 删最后一行数据 18 增加最后一行数据 19 排序 20 统计列的长度 21 读取Excel文件,csv文件 22 查看df前5行 24 分组并计算平均值 26 createtime提取为月-日 27 查看数值型列的统计 28 根据id将数据分为三组 29 按降序排列 30 取第30行数据 31 取中位数 32 水平频率分布直方图 33 水平密度曲线 34 删列: 35 合并为新的一列 37.计算最大值与最小值之差 38.将第一行与最后一行拼接 39.将第8行数据添加至末尾 40.查看每列的数据类型
import pandas as pd
import numpy as np
data = { 'grame' : [ 'python' , 'java' , 'c' , np. nan, 'python' ] ,
'score' : [ '22' , '33' , '66' , '00' , '66' ] }
df = pd. DataFrame( data)
print ( df)
print ( df[ df[ 'grame' ] == 'python' ] )
print ( df. columns)
colNameDict = {
'grame' : '内容' ,
'score' : '分数'
}
df. rename( columns= colNameDict, inplace= True )
print ( df)
df[ '内容' ] . value_counts( )
DataFramedata_dict= { "Grammer" : [ "Python" , "C" , "Java" , "GO" , np. nan, "SQL" , "PHP" , "python" ] ,
"Score" : [ 1 , 2 , np. nan, 4 , 5 , 6 , 7 , 10 ] }
df = pd. DataFrame( DataFramedata_dict)
df[ 'Score' ] = df[ 'Score' ] . fillna( df[ 'Score' ] . interpolate( ) )
print ( df[ df[ 'Score' ] > 3 ] )
df = df. drop_duplicates( [ 'Grammer' ] )
print ( df)
print ( df[ 'Score' ] . mean( ) )
print ( df[ 'Grammer' ] . to_list( ) )
print ( df. to_excel( r'test.xlsx' ) )
print ( df. shape)
print ( df[ ( df[ 'Score' ] > 3 ) & ( df[ 'Score' ] < 7 ) ] )
df[ [ 'Grammer' , 'Score' ] ] = df[ [ 'Score' , 'Grammer' ] ]
print ( df)
col = df. columns[ [ 1 , 0 ] ]
print ( df[ col] )
print ( df[ df[ 'Score' ] == df[ 'Score' ] . max ( ) ] )
print ( df. tail( ) )
df. drop( len ( df) - 1 , inplace= True )
print ( df)
DataFramedata_dict2 = { 'Grammer' : [ 'php' ] , 'Score' : [ 9 ] }
df2 = pd. DataFrame( DataFramedata_dict2)
pd. concat( [ df, df2] )
print ( df)
df. sort_values( 'Score' , inplace= True )
print ( df)
df[ 'Grammer' ] = df[ 'Grammer' ] . fillna( '' )
df[ 'len_G' ] = df[ 'Grammer' ] . map ( lambda x: len ( x) )
print ( df)
dfe = pd. read_excel( r'C:\Users\Administrator\Desktop\目标.xlsx' ,
header = 0 , sheet_name= 1 )
df = pd. read_csv( r'..\..\lh_common_org_region.csv' , encoding= "GBK" )
print ( df. head( ) )
df. groupby( 'ORG_REGION_NAME' ) . mean( )
print ( df. groupby( 'ORG_REGION_NAME' ) [ 'id' ] . mean( ) )
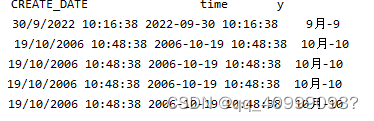
df[ 'CREATE_DATE' ] . fillna( '01/01/2000 00:00:00' , inplace= True )
df[ 'time' ] = pd. to_datetime( df[ 'CREATE_DATE' ] , format = '%d/%m/%Y %H:%M:%S' )
df[ '月-日' ] = df[ 'time' ] . dt. month. astype( int ) . astype( str ) +
"月-" + df[ 'time' ] . dt. month. astype( int ) . astype( str )
print ( df)
print ( df. describe( ) )
bins = [ 0 , 2000 , 5000 , 10000 ]
group_names = [ '低' , '中' , '高' ]
df[ 'categories' ] = pd. cut( df[ 'id' ] , bins, labels= group_names)
print ( df)
print ( df. sort_values( [ 'id' ] , ascending= False ) )
print ( df. iloc[ 29 ] )
print ( np. median( df[ 'id' ] ) )
import pandas as pd
df = pd. read_csv( r'..\..\lh_common_org_region.csv' , encoding= "GBK" )
import matplotlib as plt
df. ORG_ID. plot( kind= "hist" )
df. ORG_ID. plot( kind= "kde" )
del df[ 'id' ]
print ( df)
df[ 'test' ] = df[ 'ORG_REGION_NAME' ] + df[ 'ORG_ID' ] . astype( str )
print ( df)
m = df[ [ 'id' ] ] . apply ( lambda x: x. max ( ) - x. min ( ) )
print ( m)
print ( pd. concat( [ df[ : 1 ] , df[ - 1 : ] ] ) )
df. append( df. iloc[ 7 ] )
df. dtypes


![[附源码]计算机毕业设计JAVA闲置物品线上交易系统](https://img-blog.csdnimg.cn/bbd4bc35d2be4b5a9d7097e291a67326.png)

![L. Paid Leave(贪心)[CCPC Finals 2021]](https://img-blog.csdnimg.cn/6506b439fac14d668f9eadd877d23f9d.png)


![[附源码]计算机毕业设计JAVA鲜花销售管理系统](https://img-blog.csdnimg.cn/e7ce9c3ed2d14927a43ef29b58df40ec.png)