目录
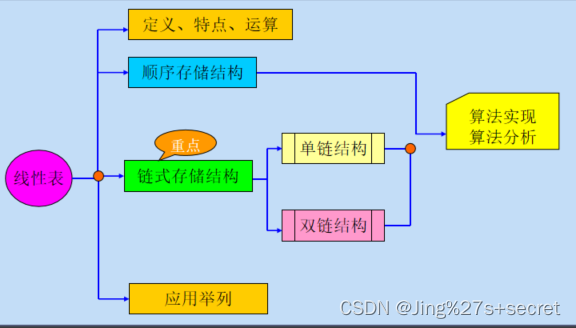
目录结构
线性表
线性表的特征:
顺序表存储结构的表示
顺序表存储结构的特点
顺序存储结构的表示
线性表的基本运算
基本运算的相关算法
线性表的基本运算
线性表
目录结构
线性表
线性表是包含若干数据元素的一个线性序列 记为:
L=(a0, ...... ai-1, ai, ai+1 ...... an-1)
L为表名,ai (0≤i≤n-1)为数据元素;
n为表长,n>0 时,线性表L为非空表,否则为空表。
线性表L可用二元组形式描述:
L= (D,R)
即线性表L包含数据元素集合D和关系集合R
D={ai | ai∈datatype ,i=0,1,2, ∙∙∙∙∙∙∙∙∙n-1 ,n≥0}
R={<ai , ai+1> | ai , ai+1∈D, 0≤i≤n-2}
关系符<ai, ai+1>在这里称为有序对 表示任意相邻的两个元素之间的一种先后次序关系
ai是ai+1的直接前驱, ai+1是ai的直接后继
设有一个顺序表L={1,2,3,4,5,6}; 他们的关系如图:

使用二元组描述L=(D,R),则
D={1 , 2 , 3 , 4 , 5 , 6}(n=6)
R={<1,2> , <2,3> , <3,4> , <4,5> , <5,6>}
线性表的特征:
1) 对非空表,a0是表头,无前驱;
2) an-1是表尾,无后继;
3) 其它的每个元素ai有且仅有一个直接前驱ai-1和一个直接后继ai+1。
顺序表存储结构的表示
若将线性表L=(a0,a1, ……,an-1)中的各元素依次存储于计算机一片连续的存储空间。
设Loc(ai)为ai的地址,Loc(a0)=b,每个元素占d个单元 则:Loc(ai)=b+i*d
顺序表存储结构的特点
逻辑上相邻的元素 ai, ai+1,其存储位置也是相邻的
对数据元素ai的存取为随机存取或按地址存取
存储密度高
存储密度D=(数据结构中元素所占存储空间)/(整个数据结构所占空间)
顺序存储结构的表示
顺序存储结构的不足:
对表的插入和删除等运算的时间复杂度较差。
在C语言中,可借助于一维数组类型来描述线性表的顺序存储结构
#define N 100
typedef int data_t;
typedef struct
{ data_t data[N]; //表的存储空间
int last; } sqlist, *sqlink;
线性表的基本运算
设线性表 L=(a0,a1, ……,an-1),对 L的基本运算有:
1)建立一个空表:list_create(L)
2)置空表:list_clear(L)
3)判断表是否为空:list_empty (L)。若表为空,返回值为1 , 否则返回 0
4)求表长:length (L)
5)取表中某个元素:GetList(L , i ), 即ai。要求0≤i≤length(L)-1
6)定位运算:Locate(L,x)。确定元素x在表L中的位置(或序号)
Locate(L,x)= i 当元素x=ai∈L,且ai是第一个与x相等时;
-1 x不属于L时。
7)插入:
Insert(L,x,i)。将元素x插入到表L中第i个元素ai之前,且表长+1。
插入前: (a0,a1,---,ai-1,ai,ai+1-------,an-1) 0≤i≤n,i=n时,x插入表尾
插入后: (a0,a1,---,ai-1, x, ai,ai+1-------,an-1)
8)删除: Delete(L,i)。删除表L中第i个元素ai,且表长减1, 要求0≤i≤n-1。 删除前: (a0,a1,---,ai-1,ai,ai+1-------,an-1) 删除后: (a0,a1,---,ai-1,ai+1-------,an)
基本运算的相关算法
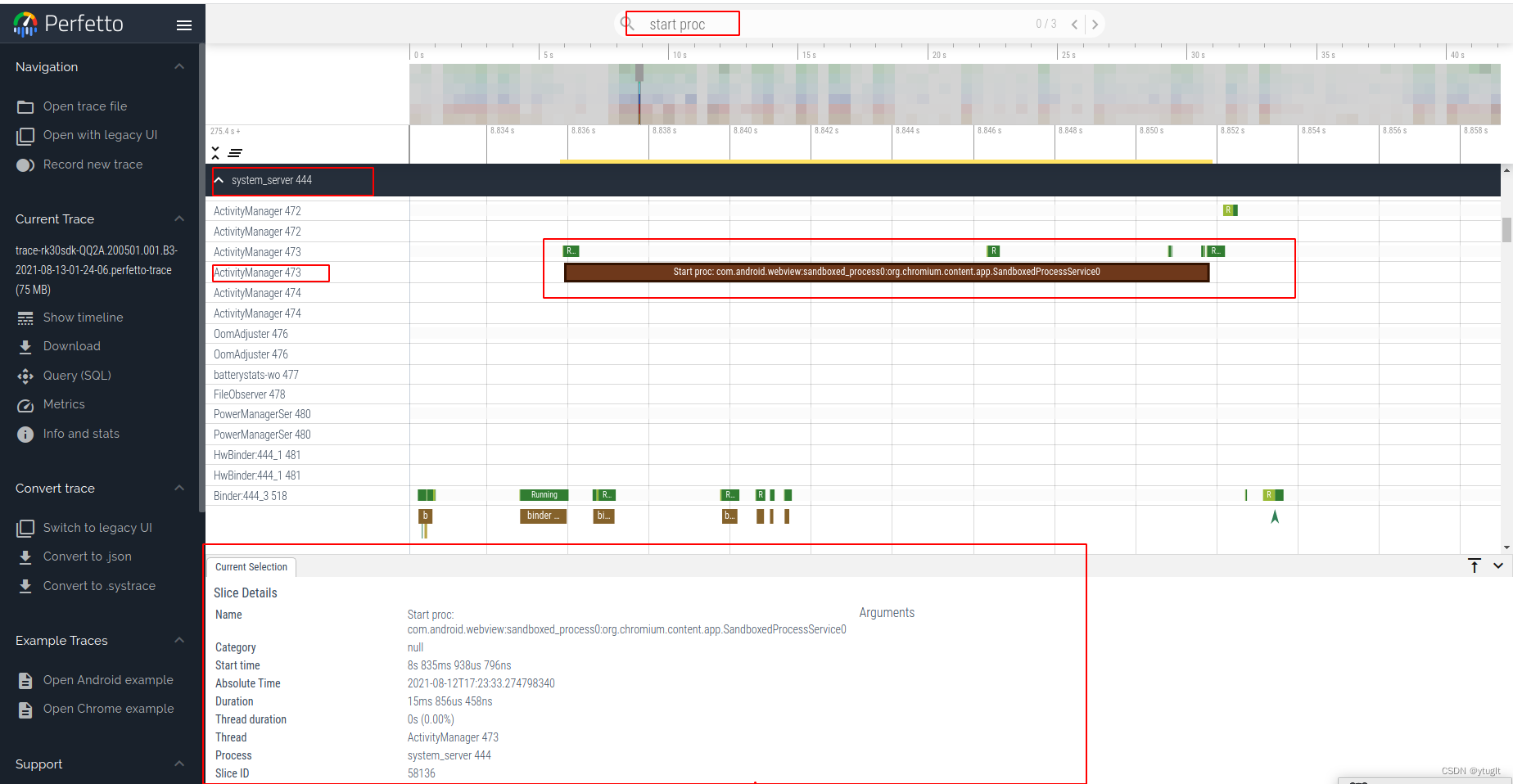
定位:确定给定元素x在表L中第一次出现的位置(或序号)。即实现Locate(L,x)。算法对应的存储结构如图所示。

算法思路:若表存在空闲空间,且参数i满足:0≤i≤L->last+1,则可进行正常插入。插入前,将表中(L->data[L->last]~L->data[i])部分顺序下移一个位置,然后将x插入L->data[i]处即可。算法对应的表结构。
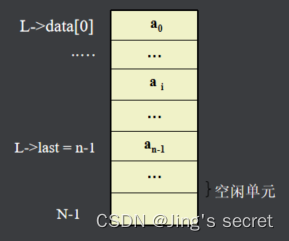
删除:将表中第i个元素ai从表中删除,即实现DeleteSqlist(L, i)。 算法思路: 若参数i满足:0≤i≤L->last, 将表中L->data[i+1]∽L->data[L->last] 部分顺序向上移动一个位置,覆盖L->data[i]。

线性表的基本运算

线性表
设计清除线性表L=(a0,a1,---,ai,-------,an-1)中重复元素的算法。
算法思路:对当前表L中的每个ai(0≤i≤n-2),依次与aj(i+1≤j≤n-1) 比较,若与ai相等,则删除之。
线性表的顺序存储的缺点
线性表的顺序存储结构有存储密度高及能够随机存取等优点,但存在以下不足:
(1)要求系统提供一片较大的连续存储空间。
(2)插入、删除等运算耗时,且存在元素在存储器中成片移动的现象;
sqlist.h 顺序表中函数的定义
sqlist.c 实现.h中的函数
test.c
写项目的时候注意结构清晰
软件复用(积累自己的经典代码)
注意代码的独立性 不能什么都放main函数中 注重代码分层
typedef int data_t;
//跟已有类型,给已有变量重命名,
//后跟分号,在编译的时候做处理
#define N 128
//定义一个宏,给宏赋值
//不用写分号,在预处理阶段展开
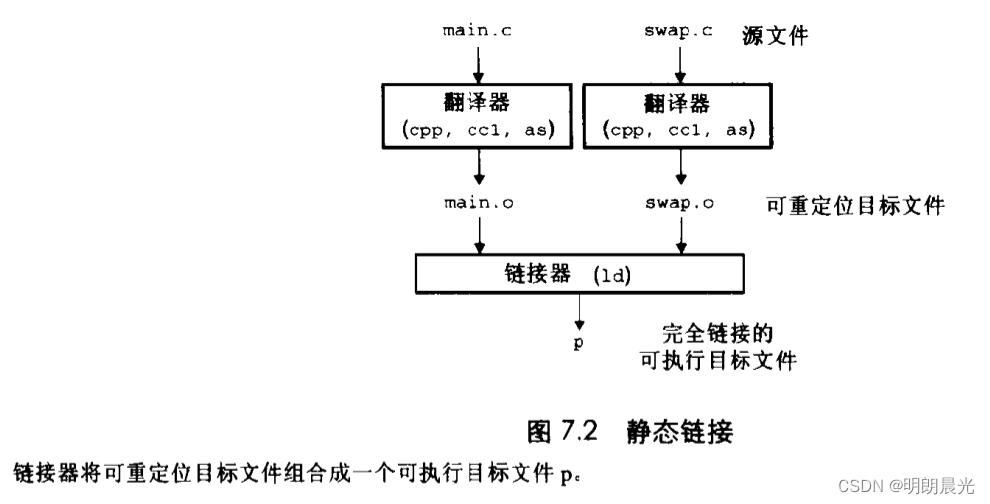
1.预处理
2.编译
3.汇编
4.链接
5.执行
123独立处理>.o文件
链接:.o文件 库文件 进行连接>a.out
每个文件生成独立的.o文件后才可以链接

![[Docker]Docker命令](https://img-blog.csdnimg.cn/3bdfe309e6c54dad81645d2252e36afd.png)