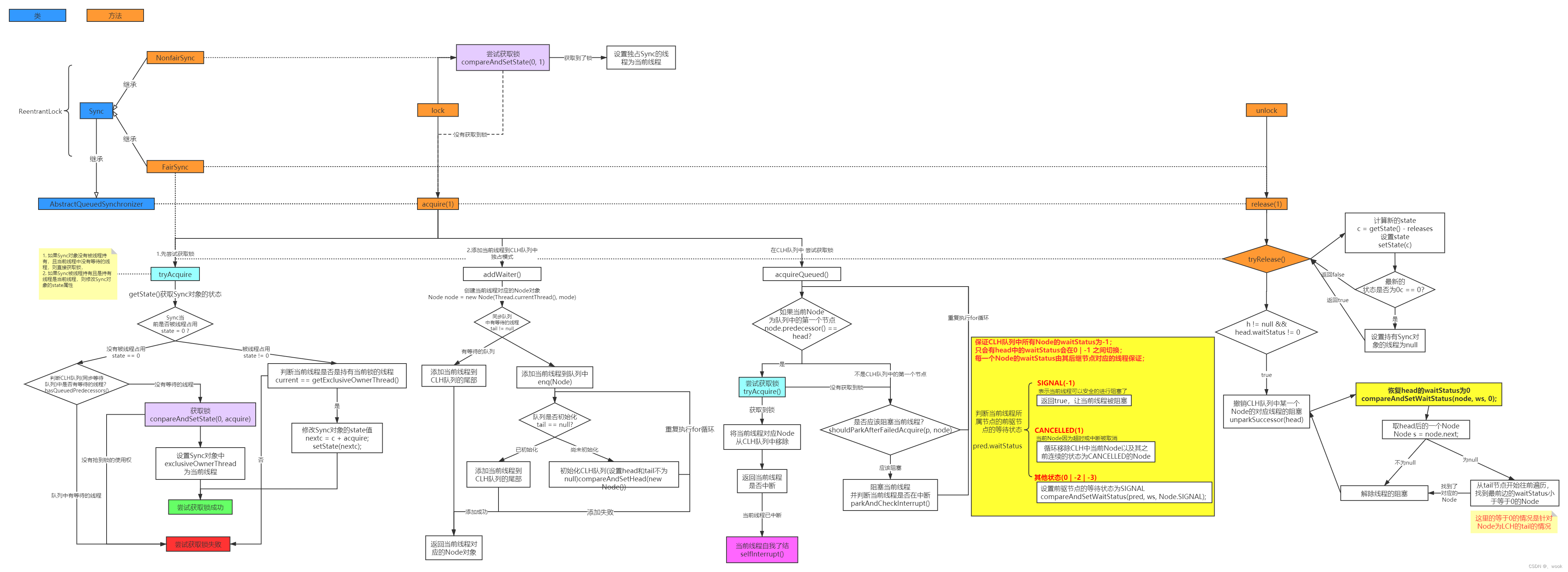
MapReduce源码解读-2
- MapReduce
- InputFormat类
- getSplits
- CreateRecordReader
- Mapper类
- OutputCollector
- MapOutputBuffer
- Partitioner 分区
- 环形缓冲区 Circular buffer
- 初始化
- Spill、Sort溢写、排序
- Merge 合并
- combiner 规约
- Reduce阶段
- ReduceTask
- 第一层调用 ReduceTask.run -shuffle 操作
- ShuffleConsumerPlugin
- init初始化
- run方法
- Shuffle-Copy
- Shuffle-Merge操作
- Reduce类
- OutputFormat
- Shuffle
- Shuffle是什么?
- Shuffle弊端
MapReduce
InputFormat类
概述
整个MapReduce一InputFormat开始,其负责读书待处理的数据,默认的实现叫做TextInputFormat。
InputFormat 核心逻辑体现在两个方面:
- 如何读取待处理目录下的文件。是一个一个还是一次多个?
- 读取数据的的行为是什么以及返回什么样的结果?是一行一行读还是按字节来进行读取?
可以说不同的实现有不同的处理逻辑
存在以下问题
- 对于待处理的目录下的所有文件,MapReduce程序面临的首要问题就是 :究竟启动多少个MapTask来处理本次job?
- MapTask个数越多,并行度越高,是否就越好?
- 不管划分多少个并行处理,划分的标准是什么?
- 不重复?不丢失?
getSplits
maptask的并行度问题,指的是map阶段有多少个并行的task共同处理任务。
map阶段并行度由客户端在job提交时决定,即客户端提交job之前会对待处理的数据进行逻辑切片,切片完成会形成切片规划文件(job.split),每隔逻辑切片最终对应启动一个maptask
切片逻辑机制由FileInputFormat实现类的getSplits()方法完成而其默认实现为TextInputFormat实现的
MapTask切片机制(逻辑规划)
以split size 逐个遍历待处理的文件,形成逻辑规划文件,在默认情况下,有多少个文件,就应该启动多少个MapTask

在getSplits方法中,创建了一个集合splits,用于存储最终的切片信息,生成的切片信息在客户端提交job时,也就是JobSubmitter.writeSplits方法中,把所有的切片信息进行排序,大的切片在前,然后序列化到一个文件中,此文件叫做逻辑切片文件(job.split),提交到作业准备区路径下
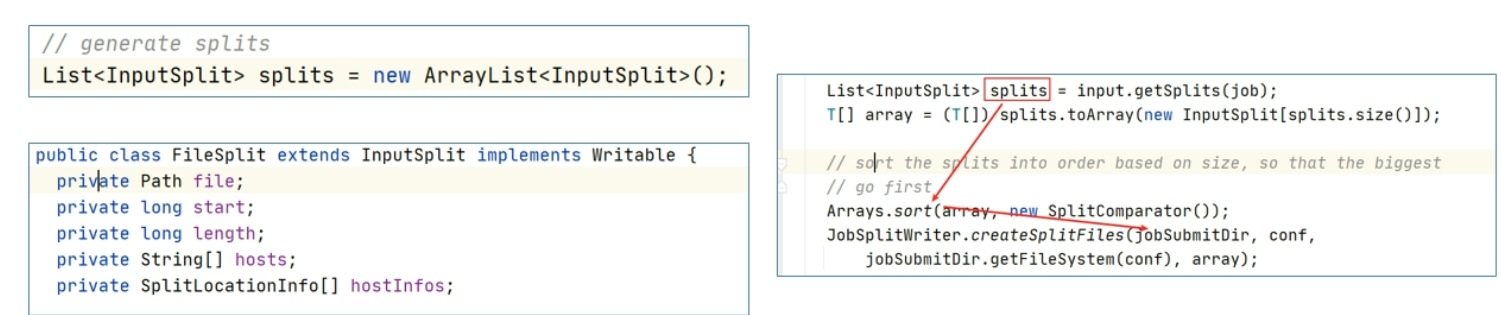
在进行逻辑切片时,假如说一个文件的大小是129MB 大小,那么根据默认的逻辑切片规则将会形成一大一下的两个切片(0-128 128-129),并且将启动两个maptask,这样子显然对资源的利用率不高
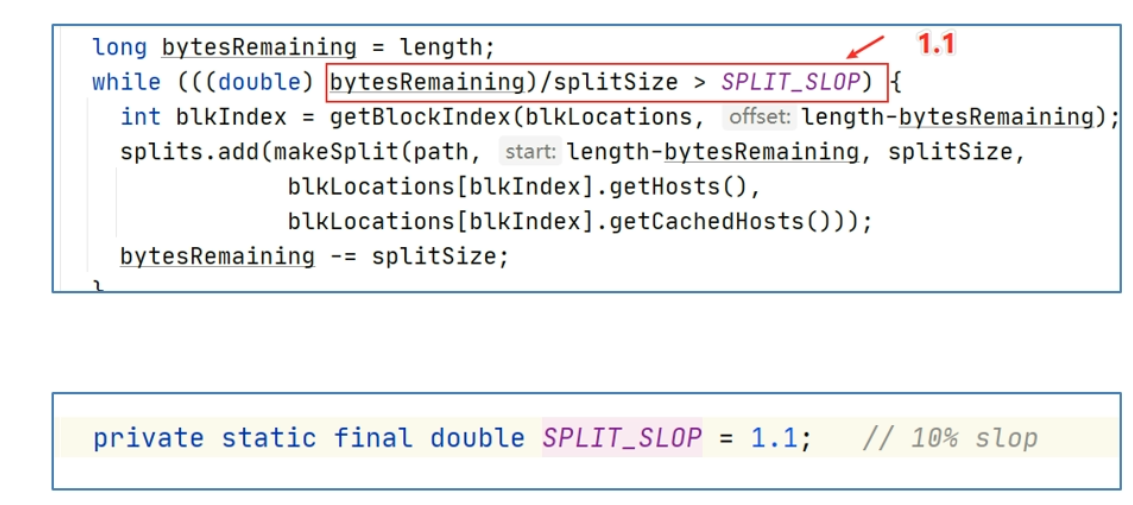
因此在设计中,MapReduce时刻会进行bytesRemaining,剩下文件大小,如果剩下的文件大小不满足bytesRemaining/splitSize > SPLIT_SLOP,那么将不会再继续split,而是将剩下的作为一个切片的整体,其中SPLIT_SLOP的大小为1.1
CreateRecordReader
InputFormat.createRecordReader方法用于创建RecordReader
RecordReader类最终负责读取切片数据,默认实现是LineRecordReader:一行一行读取数据
在LineRecordReader中,核心方法有initalize 初始化方法、nextKeyValue读取数据方法
nextKeyValue
nextKeyValue方法用于判断是否还有下一行数据以及定义了按行读取数据的逻辑:
一行行读取数据,返回<K,V>键值对类型数据,其中key是每行起始位置offset偏移量,value为这一行的数据
优化措施
由于文件在HDFS上进行存储,物理上会进行分块存储,可能会导致文件内容的完整性破坏,为了避免这个文通,在实际读取split数据的时候,每个maptask会进行读取行为调整
每个maptask都多处理下一个split的第一行数据如果不是第一个切片就会舍弃第一行,除了第一个,每隔maptask都会舍弃自己的第一行不去处理
Mapper类
mapper中有三个方法,分别是 setup初始化方法、map方法、cleanup扫尾清理方法
而maptask的业务处理核心是在map方法中定义的,用户可以在自定义的mapper中重写父类的map方法逻辑.
对于map方法,如果用户不重写,父类中也有默认的实现逻辑:输入什么,原封不动的输出什么,也就是说对数据不进行任何处理。
此外map方法的调用周期、次数取决于父类中run方法,在LineRecordReader.nextKeyValue返回true时,意味着还有数据,LineRecordReader没读取一行数据,返回一个kv键值对,就会调用一次map方法
因此得出结论:mapper阶段默认情况下是基于行处理输入数据的
OutputCollector
map最终调用context.write方法将最终结果输出,至于输出的数据到哪里,取决于MR程序是否有Reduce阶段,如果有reduce阶段,则创建输出收集器OutputCollector,对结果收集,如果没有reduce阶段,则创建outputFormat,默认实现是TextOutputFormat,直接将处理的结果输出到指定目录文件中
在createSortingCollector方法内部,核心是创建具体的输出收集器MapOutputBuffer
MapOutputBuffer是口语中俗称的map输出的内存缓冲区
当创建好MapOutputBuffer之后,在返回给MapTask之前对其进行了init初始化
MapOutputBuffer
在MapReduce具有reducetask阶段的时候,maptask的输出并不只是直接输出到磁盘上,而是被输出收集器首先收集到内存缓冲区,最终持久化到磁盘上,这个过程称之为MapReduce在Map端的Shuffle过程,主要包括:
- Partitioner 分区
- Circular buffer 内存缓冲分区
- Spill 、sort溢写、排序
- merge 合并
- combiner 规约
Partitioner 分区
write最终调用的是MapTask中的Write方法,write方法中把输出的数据kv通过收集器写入了环形缓冲区,再写入之前这里还进行了数据分区计算。partitioner.getPartition(key,value,partitions)就是计算每隔mapper的输出分区编号是多少
需要注意的是,只有reducetask > 1 才会进行分区计算
@Override
public void write(K key, V value) throws IOException, InterruptedException {
collector.collect(key, value,
partitioner.getPartition(key, value, partitions));
}
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
环形缓冲区 Circular buffer
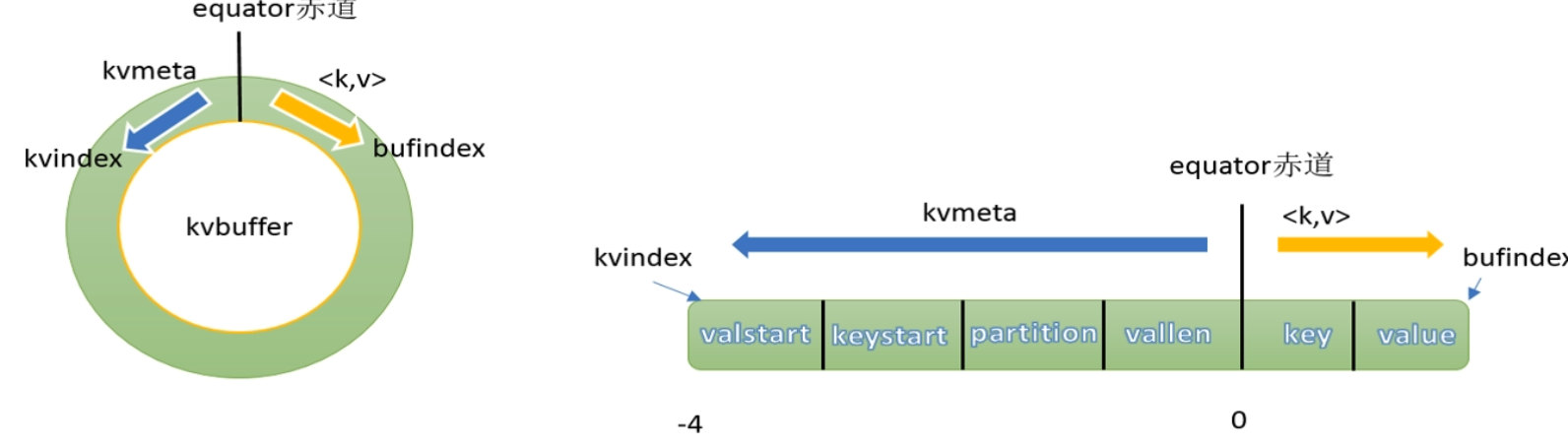
环形缓冲区本质上就是一个字节数组,叫做kvbuffer,默认大小为100M,缓冲区的作用是批量收集map方法的输出结果,减少磁盘IO的影响
环形缓冲区中不仅存放着key、value的序列化之后的数据,还存储着一些元数据,存储key、value的元数据的区域,叫做kvmeta,每隔key、value都对应着一个元数据,元数据由4个int组成: key的起始位置、value的起始位置、partition、value 的长度

key/value序列化的数据和元数据在环形缓冲区中的存储时由equator(赤道)分割的,是相邻不重叠的两个区域。
key/value按照索引递增的方向存储,meta则按照索引递减的方向存储,将其数组抽象为一个环形结构后,以equator为界限,key/value顺时针存储,meta逆时针存储数据的索引叫做bufindex,元数据索引叫做kvindex.
kvindex每次都向下跳4个格子,然后再向上一个格子一个格子的填充四元组数据,比如说kvindex初始位置时-4,当地一个写完之后(Kvindex +0 )的位置存放value的起始位置、(Kvindex +1 )的位置存放key的其实位置、(Kvindex+2)的位置存放partition的值、(Kvindex + 3) 的位置存放value的长度,然后Kvindex跳到-8的位置
初始化
在MapTask中创建OutputCollector(实现是MapOutputBuffer)的时候,对环形缓冲区进行了初始化的动作,在初始化的过程中,主要是构造环形缓冲区的抽象数据结构,包括但不限于:设置缓冲区大小、溢出比、初始化kvbuffer、kvmeta、设置equator表示分界线、构造排序的实现类、combiner、压缩编码等,其方法为MapOutputBuffer.init

数据收集
收集数据到环形缓冲区核心逻辑有:序列化key到字节数组,序列化value到字节数组,写入该条数据的元数据(其实位置、partition、长度)、更新kvindex。(MapOutputBuffer.collect)。
以下是部分源码解读
public void init(MapOutputCollector.Context context
) throws IOException, ClassNotFoundException {
job = context.getJobConf();
reporter = context.getReporter();
mapTask = context.getMapTask();
mapOutputFile = mapTask.getMapOutputFile();
sortPhase = mapTask.getSortPhase();
spilledRecordsCounter = reporter.getCounter(TaskCounter.SPILLED_RECORDS);
partitions = job.getNumReduceTasks();
rfs = ((LocalFileSystem)FileSystem.getLocal(job)).getRaw();
//sanity checks
final float spillper =
//溢出百分比0.8 环形缓冲区达到80% 开始溢写操作
job.getFloat(JobContext.MAP_SORT_SPILL_PERCENT, (float)0.8);
final int sortmb = job.getInt(MRJobConfig.IO_SORT_MB,
MRJobConfig.DEFAULT_IO_SORT_MB); // 缓冲区大小 默认为100MB
indexCacheMemoryLimit = job.getInt(JobContext.INDEX_CACHE_MEMORY_LIMIT,
INDEX_CACHE_MEMORY_LIMIT_DEFAULT);
if (spillper > (float)1.0 || spillper <= (float)0.0) {
throw new IOException("Invalid \"" + JobContext.MAP_SORT_SPILL_PERCENT +
"\": " + spillper); // 校验溢出比是否合规
}
if ((sortmb & 0x7FF) != sortmb) {
throw new IOException( // 环形缓冲区合格校验
"Invalid \"" + JobContext.IO_SORT_MB + "\": " + sortmb);
}
// 创建排序实现类,默认采用快速排列 QuickSort
sorter = ReflectionUtils.newInstance(job.getClass(
MRJobConfig.MAP_SORT_CLASS, QuickSort.class,
IndexedSorter.class), job);
// buffers and accounting
// 上面的IO_SORT_MB 的单位时MB,左移20为将单位转换为byte
int maxMemUsage = sortmb << 20;
// 计算buffer中做多有多少个byte来存储元数据
maxMemUsage -= maxMemUsage % METASIZE;
// 元数据数组 以byte 为单位
kvbuffer = new byte[maxMemUsage];
bufvoid = kvbuffer.length;
// 讲kvbuffer转换为int型的kvmeta 以int为单位,也就是4byte
kvmeta = ByteBuffer.wrap(kvbuffer)
.order(ByteOrder.nativeOrder())
.asIntBuffer();
// 设置kvbuffer 和 kvmeta之间的分界线
setEquator(0);
bufstart = bufend = bufindex = equator;
kvstart = kvend = kvindex;
maxRec = kvmeta.capacity() / NMETA;
softLimit = (int)(kvbuffer.length * spillper);
// 比较重要,作为spill的动态衡量标准
bufferRemaining = softLimit;
LOG.info(JobContext.IO_SORT_MB + ": " + sortmb);
LOG.info("soft limit at " + softLimit);
LOG.info("bufstart = " + bufstart + "; bufvoid = " + bufvoid);
LOG.info("kvstart = " + kvstart + "; length = " + maxRec);
// k/v serialization
// 创建排序实现类,可以选择自定义,也可以默认
comparator = job.getOutputKeyComparator();
keyClass = (Class<K>)job.getMapOutputKeyClass();
valClass = (Class<V>)job.getMapOutputValueClass();
serializationFactory = new SerializationFactory(job);
keySerializer = serializationFactory.getSerializer(keyClass);
keySerializer.open(bb);
valSerializer = serializationFactory.getSerializer(valClass);
valSerializer.open(bb);
// output counters
// output counters 输出计数器
mapOutputByteCounter = reporter.getCounter(TaskCounter.MAP_OUTPUT_BYTES);
mapOutputRecordCounter =
reporter.getCounter(TaskCounter.MAP_OUTPUT_RECORDS);
fileOutputByteCounter = reporter
.getCounter(TaskCounter.MAP_OUTPUT_MATERIALIZED_BYTES);
// compression
if (job.getCompressMapOutput()) {
Class<? extends CompressionCodec> codecClass =
job.getMapOutputCompressorClass(DefaultCodec.class);
codec = ReflectionUtils.newInstance(codecClass, job);
} else {
codec = null;
}
// combiner
final Counters.Counter combineInputCounter =
reporter.getCounter(TaskCounter.COMBINE_INPUT_RECORDS);
combinerRunner = CombinerRunner.create(job, getTaskID(),
combineInputCounter,
reporter, null);
if (combinerRunner != null) {
final Counters.Counter combineOutputCounter =
reporter.getCounter(TaskCounter.COMBINE_OUTPUT_RECORDS);
combineCollector= new CombineOutputCollector<K,V>(combineOutputCounter, reporter, job);
} else {
combineCollector = null;
}
spillInProgress = false;
minSpillsForCombine = job.getInt(JobContext.MAP_COMBINE_MIN_SPILLS, 3);
spillThread.setDaemon(true);
spillThread.setName("SpillThread");
spillLock.lock();
try {
spillThread.start();
while (!spillThreadRunning) {
spillDone.await();
}
} catch (InterruptedException e) {
throw new IOException("Spill thread failed to initialize", e);
} finally {
spillLock.unlock();
}
if (sortSpillException != null) {
throw new IOException("Spill thread failed to initialize",
sortSpillException);
}
}
Spill、Sort溢写、排序
Spill的意义和好处
环形缓冲区虽然可以减少IO次数,但是内存总归有容量限制,不能把所有数据一直写入到内存中,数据最终还要落入磁盘上存储,所以需要在一定条件下将缓冲区中的数据临时写入磁盘,然后重新利用这块缓冲区,这个从内存往磁盘中写入数据的过程被称为Spill,中文可译为溢写
触发Spill阈值
这个缓冲区有个溢写的比例spill.percent 这个比例默认是0.8,当环形缓冲区的数据达到阈值(buffer.size * spill.percent = 100 MB *0.8 = 80MB),spill线程启动
spill线程是由startSpill()方法唤醒的,在进行spill操作的时候,此时map向buffer的写入操作并没有阻塞,剩下的20MB可以继续使用,MapOutputBuffer.collect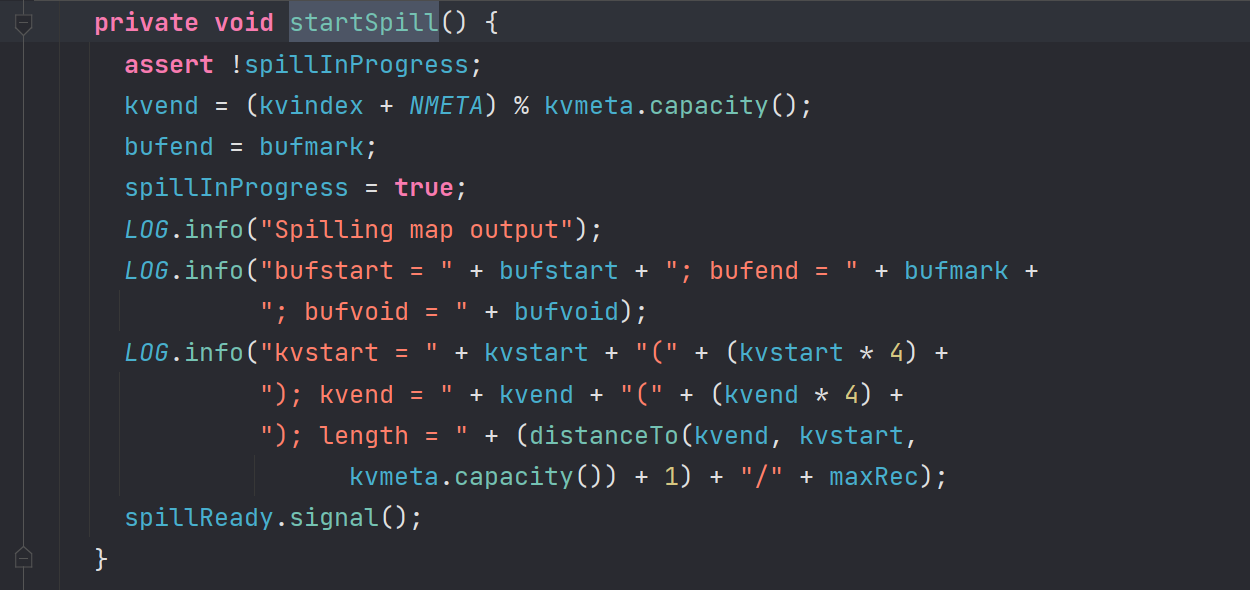
在这里唤醒一个线程,这个线程是SpillThread线程,而这个线程内部的核心逻辑是sortAndSpill方法
private void sortAndSpill() throws IOException, ClassNotFoundException,
InterruptedException {
//approximate the length of the output file to be the length of the
//buffer + header lengths for the partitions
final long size = distanceTo(bufstart, bufend, bufvoid) +
partitions * APPROX_HEADER_LENGTH;
FSDataOutputStream out = null;
FSDataOutputStream partitionOut = null;
try {
// create spill file
// 记录spill的索引信息,通过索引来区分partition的边界和其实位置
final SpillRecord spillRec = new SpillRecord(partitions);
// 创建写入磁盘的spill
final Path filename =
mapOutputFile.getSpillFileForWrite(numSpills, size);
// 打开文件流
out = rfs.create(filename);
final int mstart = kvend / NMETA;
final int mend = 1 + // kvend is a valid record
(kvstart >= kvend
? kvstart
: kvmeta.capacity() + kvstart) / NMETA;
// 开始进行排序,排序的规则是队员数据进行排序,调整数据顺序
// 排序规则是MapOutputBuffer.compare,先对partition进行排序其次对key值进行排序
sorter.sort(MapOutputBuffer.this, mstart, mend, reporter);
int spindex = mstart;
final IndexRecord rec = new IndexRecord();
final InMemValBytes value = new InMemValBytes();
for (int i = 0; i < partitions; ++i) {
// 溢写时的临时文件时IFile格式的
IFile.Writer<K, V> writer = null;
try {
long segmentStart = out.getPos();
partitionOut = CryptoUtils.wrapIfNecessary(job, out, false);
writer = new Writer<K, V>(job, partitionOut, keyClass, valClass, codec,
spilledRecordsCounter);
// 往磁盘写数据时先判断是否有combiner
if (combinerRunner == null) {
// spill directly
// 如果没有设置 combiner 直接spill
DataInputBuffer key = new DataInputBuffer();
// 写入相同的partition 的数据
while (spindex < mend &&
kvmeta.get(offsetFor(spindex % maxRec) + PARTITION) == i) {
final int kvoff = offsetFor(spindex % maxRec);
int keystart = kvmeta.get(kvoff + KEYSTART);
int valstart = kvmeta.get(kvoff + VALSTART);
key.reset(kvbuffer, keystart, valstart - keystart);
getVBytesForOffset(kvoff, value);
writer.append(key, value);
++spindex;
}
} else {
// 如果设置了combiner 则执行一下的逻辑
// 计算当前分区的开始spstart和结束spindex的位置
int spstart = spindex;
while (spindex < mend &&
kvmeta.get(offsetFor(spindex % maxRec)
+ PARTITION) == i) {
++spindex;
}
// Note: we would like to avoid the combiner if we've fewer
// than some threshold of records for a partition
if (spstart != spindex) {
combineCollector.setWriter(writer);
RawKeyValueIterator kvIter =
new MRResultIterator(spstart, spindex);
combinerRunner.combine(kvIter, combineCollector);
}
}
// close the writer
// 关闭写入流
writer.close();
if (partitionOut != out) {
partitionOut.close();
partitionOut = null;
}
// record offsets
// 记录当前partition的信息到索引文件spillRec中
rec.startOffset = segmentStart;
rec.rawLength = writer.getRawLength() + CryptoUtils.cryptoPadding(job);
rec.partLength = writer.getCompressedLength() + CryptoUtils.cryptoPadding(job);
// spillRec中存放了Spill中partition的信息,便于后续堆排序时,取出partition相关数据进行排序
spillRec.putIndex(rec, i);
writer = null;
} finally {
if (null != writer) writer.close();
}
}
// 判断内存中的spillRec文件是否超出阈值,超出则将spillRec文件写入磁盘
if (totalIndexCacheMemory >= indexCacheMemoryLimit) {
// create spill index file
// 创建磁盘索引index索引文件
Path indexFilename =
mapOutputFile.getSpillIndexFileForWrite(numSpills, partitions
* MAP_OUTPUT_INDEX_RECORD_LENGTH);
//将内存中的spillRec写入磁盘编程index索引文件
spillRec.writeToFile(indexFilename, job);
} else {
indexCacheList.add(spillRec);
totalIndexCacheMemory +=
spillRec.size() * MAP_OUTPUT_INDEX_RECORD_LENGTH;
}
LOG.info("Finished spill " + numSpills);
++numSpills;
} finally {
if (out != null) out.close();
if (partitionOut != null) {
partitionOut.close();
}
}
}
当环形缓冲区中数据已经达到了上限80%,则会通过startSpill 唤醒SpillThread线程,线程内部的核心方法是sortAndSpll方法,在内部他会对数据进行一个排序,排序是根据元数据进行排序的,排序规则是先判断分区 后根据k进行排序,排序后将数据写入,但是再写入前先要判断是否启动了combiner,如果设置了combiner那么就先执行其逻辑,如果没有设置,那么则直接写入。再写入文件是,还要对其进行一个记录,这个记录由spillRec 进行存储,但是如果spillRec的大小超过了1MB,那么再写入的时候也会将spillRec写入到磁盘中。等于说写入磁盘的不仅仅是数据,还有SpillRec
需要注意的是整个排序仅对元数据进行了排序,而对真实数据没有进行排序,所谓元数据就是描述数据的数据,其记录了相应的信息,当写入时会根据排好序的元数据找到对应的kvbuffer,并将其写入到磁盘中,使得写入到磁盘中的数据是有序的
Merge 合并
每次spill都会在磁盘上生成一个临时文件,如果map的输出结果真的特别大,有多个这样的spill发生,磁盘上相应的就会有多个临时文件存在,这样子不利于reducetask处理数据
合并(merge)会将所有溢出文件合并在一起以确保最终一个maptask对应的一个输出结果文件
一次最多可以合并多少个文件由mapreduce.task.io.sort.factor指定,默认为10,如果超过了讲进行多次merge合并
合并之后的最终结果还包含索引文件,索引文件描述了数据中分区范围信息,一边reducetask能够轻松获取与其相关的分区数据
combiner 规约
作用
对map端的输出先进性一次局部合并,以减少map和reduce节点之间的数据传输量,以提高网络IO性能,是MapReduce的一种优化手段之一,默认情况下不开启
生效阶段
当job设置了Combiner,在spill和merge的两个阶段都可能执行

Reduce阶段
整体流程简述
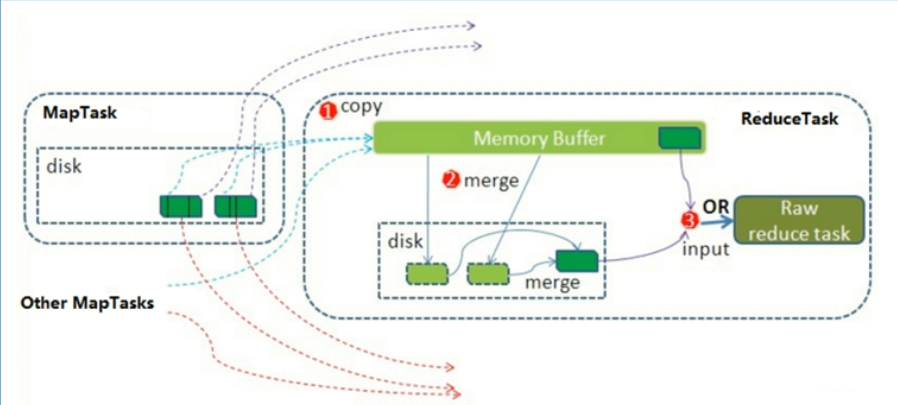
Reduce大致分为copy、sort、reduce三个阶段,重点在前两个阶段
copy阶段包含一个eventFetcher来获取已完成的map列表,由Fetcher(采集器)线程区copy数据,到哥哥maptask那里去拉去属于自己的分区的数据,在此过程红会启动两个merge线程,分别为inMemoryMerger和onDiskMerger,分别将内存中的数据merge到磁盘和将磁盘中的数据进行merge。
带数据copy完成之后,开始进行sort阶段,sort阶段主要是执行finalMerge操作,纯粹的sort阶段
最后就是reduce阶段,调用用户定义的reduce函数进行处理
ReduceTask
概述
在MapReduce程序中,Map阶段之后进行的阶段叫做reduce阶段,该运行的task叫做reduceTask。
ReduceTask类作为reducetask的载体,调用的就是类的run方法,开启reduce阶段任务
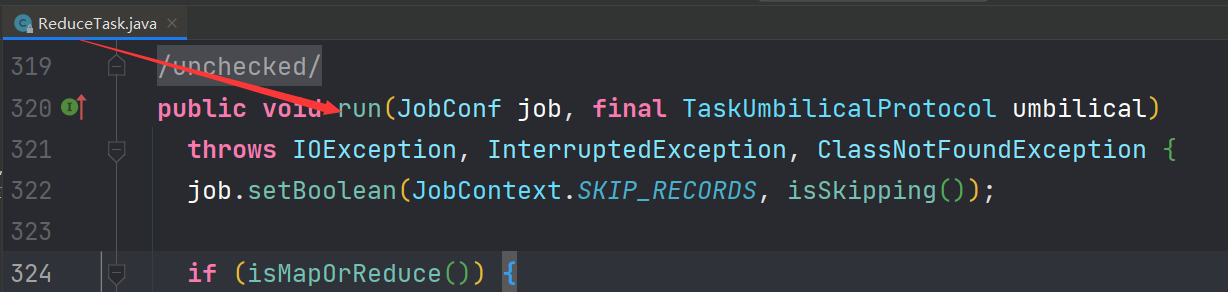
第一层调用 ReduceTask.run -shuffle 操作
在ReduceTask.run方法中跟shuffle相关操作,出了shuffle核心任务之外还创建了reducetask工作相关的一些组件,包括但不限于:code解编码器、CombineOutputColletcor输出收集器、shuffleConsumerPlugin(fu则reduce端shuffle插件)、shuffleContext上下文对象、GroupingComparator分组比较器
public void run(JobConf job, final TaskUmbilicalProtocol umbilical)
throws IOException, InterruptedException, ClassNotFoundException {
job.setBoolean(JobContext.SKIP_RECORDS, isSkipping());
// 判断是否为reducetask,如果是,整个task分为3个阶段,copy拉取数据、sort排序数据、reduce聚合
if (isMapOrReduce()) {
copyPhase = getProgress().addPhase("copy");
sortPhase = getProgress().addPhase("sort");
reducePhase = getProgress().addPhase("reduce");
}
// start thread that will handle communication with parent
TaskReporter reporter = startReporter(umbilical);
// 是否启用新的API 默认情况下都是新的API
boolean useNewApi = job.getUseNewReducer();
initialize(job, getJobID(), reporter, useNewApi);
// check if it is a cleanupJobTask
if (jobCleanup) {
runJobCleanupTask(umbilical, reporter);
return;
}
if (jobSetup) {
runJobSetupTask(umbilical, reporter);
return;
}
if (taskCleanup) {
runTaskCleanupTask(umbilical, reporter);
return;
}
// Initialize the codec
// 如果map的数据进行了压缩编码,这里就初始化解码器,用于解压缩
codec = initCodec();
// 存储reduce拉去过来的经过排序、合并后的全量数据
RawKeyValueIterator rIter = null;
// reduce端shuffle操作插件,是个接口,默认实现类Shuffle.class
ShuffleConsumerPlugin shuffleConsumerPlugin = null;
// 判断用户是否设置了combiner 如果是,创建combiner输出收集器
// mapper --> combiner --> reduce
Class combinerClass = conf.getCombinerClass();
CombineOutputCollector combineCollector =
(null != combinerClass) ?
new CombineOutputCollector(reduceCombineOutputCounter, reporter, conf) : null;
// 创建reduce端用于shuffle操作的插件类,默认是显示shuffle.class
Class<? extends ShuffleConsumerPlugin> clazz =
job.getClass(MRConfig.SHUFFLE_CONSUMER_PLUGIN, Shuffle.class, ShuffleConsumerPlugin.class);
shuffleConsumerPlugin = ReflectionUtils.newInstance(clazz, job);
LOG.info("Using ShuffleConsumerPlugin: " + shuffleConsumerPlugin);
//创建shuffleCOntext上下文对象
ShuffleConsumerPlugin.Context shuffleContext =
new ShuffleConsumerPlugin.Context(getTaskID(), job, FileSystem.getLocal(job), umbilical,
super.lDirAlloc, reporter, codec,
combinerClass, combineCollector,
spilledRecordsCounter, reduceCombineInputCounter,
shuffledMapsCounter,
reduceShuffleBytes, failedShuffleCounter,
mergedMapOutputsCounter,
taskStatus, copyPhase, sortPhase, this,
mapOutputFile, localMapFiles); // localMapFiles如果不为空则表示本地模式运行MR
// 初始化shuffle
shuffleConsumerPlugin.init(shuffleContext);
// 运行shuffle,shuffle完毕之后的数据由rIter封装
rIter = shuffleConsumerPlugin.run();
// free up the data structures
// shuffle结束 清空在磁盘上map输出的数据
mapOutputFilesOnDisk.clear();
sortPhase.complete(); // sort is complete 排序结束
setPhase(TaskStatus.Phase.REDUCE); // 进入reduce阶段
statusUpdate(umbilical);
Class keyClass = job.getMapOutputKeyClass();
Class valueClass = job.getMapOutputValueClass();
// 获取分组比较器
RawComparator comparator = job.getOutputValueGroupingComparator();
// 判断使用newAPI还是old API
if (useNewApi) {
runNewReducer(job, umbilical, reporter, rIter, comparator,
keyClass, valueClass);
} else {
runOldReducer(job, umbilical, reporter, rIter, comparator,
keyClass, valueClass);
}
shuffleConsumerPlugin.close();
done(umbilical, reporter);
}
private <INKEY,INVALUE,OUTKEY,OUTVALUE>
void runNewReducer(JobConf job,
final TaskUmbilicalProtocol umbilical,
final TaskReporter reporter,
RawKeyValueIterator rIter, // shuffle 后的数据
RawComparator<INKEY> comparator, // 比较器
Class<INKEY> keyClass,
Class<INVALUE> valueClass
) throws IOException,InterruptedException,
ClassNotFoundException {
// wrap value iterator to report progress.
final RawKeyValueIterator rawIter = rIter;
rIter = new RawKeyValueIterator() {
public void close() throws IOException {
rawIter.close();
}
public DataInputBuffer getKey() throws IOException {
return rawIter.getKey();
}
public Progress getProgress() {
return rawIter.getProgress();
}
public DataInputBuffer getValue() throws IOException {
return rawIter.getValue();
}
public boolean next() throws IOException {
boolean ret = rawIter.next();
reporter.setProgress(rawIter.getProgress().getProgress());
return ret;
}
};
// make a task context so we can get the classes
// 创建task上席文
org.apache.hadoop.mapreduce.TaskAttemptContext taskContext =
new org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl(job,
getTaskID(), reporter);
// make a reducer
// 提取创建用户编写指定的reducer类
org.apache.hadoop.mapreduce.Reducer<INKEY,INVALUE,OUTKEY,OUTVALUE> reducer =
(org.apache.hadoop.mapreduce.Reducer<INKEY,INVALUE,OUTKEY,OUTVALUE>)
ReflectionUtils.newInstance(taskContext.getReducerClass(), job);
// 创建FileOutputFormat用于输出数据,默认实现是TextPutFormat
org.apache.hadoop.mapreduce.RecordWriter<OUTKEY,OUTVALUE> trackedRW =
new NewTrackingRecordWriter<OUTKEY, OUTVALUE>(this, taskContext);
job.setBoolean("mapred.skip.on", isSkipping());
job.setBoolean(JobContext.SKIP_RECORDS, isSkipping());
// 创建ReduceContext对象,将shuffle结果rIter、比较器comparator传进去
org.apache.hadoop.mapreduce.Reducer.Context
reducerContext = createReduceContext(reducer, job, getTaskID(),
rIter, reduceInputKeyCounter,
reduceInputValueCounter,
trackedRW,
committer,
reporter, comparator, keyClass,
valueClass);
try {
// 调用Reduce的run方法进行数据处理
reducer.run(reducerContext);
} finally {
trackedRW.close(reducerContext);
}
}
public void run(Context context) throws IOException, InterruptedException {
setup(context);
try {
// reducer 中先调用while循环,循环条件是nextKey,nextKey调用的是nextKeyValue
while (context.nextKey()) {
// reducer中先调context.getValues()只是返回一个Iterator
reduce(context.getCurrentKey(), context.getValues(), context);
// If a back up store is used, reset it
Iterator<VALUEIN> iter = context.getValues().iterator();
if(iter instanceof ReduceContext.ValueIterator) {
((ReduceContext.ValueIterator<VALUEIN>)iter).resetBackupStore();
}
}
} finally {
cleanup(context);
}
}
ShuffleConsumerPlugin
注意ShuffleConsumerPlugin是一个接口,默认的实现只有一个Shuffle.class,其完整的定义了整个reduce阶段shuffle的完整过程,在ReduceTask类中,和ShuffleConsumerPlugin相关的两个操作就有两个方法: init初始化、run运行
init初始化
初始化的过程中,核心逻辑就是创建MergeManagerImpl类,在MergeManagerImpl类中,核心的有:确定shuffle时的一些条件,是否允许内存存到内存合并。启动两个merge线程,分别为inMemoryMerge和onDiskMerge,分别将内存中的数据merge到磁盘和将磁盘中的数据进行
确定shuffle时的一些条件参数
我们查看其init方法,可以看到在最后创建了一个mergeManager,而createMergeManager方法内部直接返回了一个MergeManagerImpl方法。查看内部方法
启动MemtoMemMerge线程
因为fetch来数据首先存放在内存的,正常情况下内存中对数据进行合并时最快的,可惜的是默认情况下,是不开启内存到内存的合并的
启动inMemoryMerger(内存到磁盘合并)、onDiskMerger(磁盘到磁盘合并)线程
public MergeManagerImpl(TaskAttemptID reduceId, JobConf jobConf,
FileSystem localFS,
LocalDirAllocator localDirAllocator,
Reporter reporter,
CompressionCodec codec,
Class<? extends Reducer> combinerClass,
CombineOutputCollector<K,V> combineCollector,
Counters.Counter spilledRecordsCounter,
Counters.Counter reduceCombineInputCounter,
Counters.Counter mergedMapOutputsCounter,
ExceptionReporter exceptionReporter,
Progress mergePhase, MapOutputFile mapOutputFile) {
this.reduceId = reduceId;
this.jobConf = jobConf;
this.localDirAllocator = localDirAllocator;
this.exceptionReporter = exceptionReporter;
this.reporter = reporter;
this.codec = codec;
this.combinerClass = combinerClass;
this.combineCollector = combineCollector;
this.reduceCombineInputCounter = reduceCombineInputCounter;
this.spilledRecordsCounter = spilledRecordsCounter;
this.mergedMapOutputsCounter = mergedMapOutputsCounter;
this.mapOutputFile = mapOutputFile;
this.mapOutputFile.setConf(jobConf);
this.localFS = localFS;
this.rfs = ((LocalFileSystem)localFS).getRaw();
//reducetask最大可以使用的内存用于shuffle的比例: 70%
final float maxInMemCopyUse =
jobConf.getFloat(MRJobConfig.SHUFFLE_INPUT_BUFFER_PERCENT,
MRJobConfig.DEFAULT_SHUFFLE_INPUT_BUFFER_PERCENT);
if (maxInMemCopyUse > 1.0 || maxInMemCopyUse < 0.0) {
throw new IllegalArgumentException("Invalid value for " +
MRJobConfig.SHUFFLE_INPUT_BUFFER_PERCENT + ": " +
maxInMemCopyUse);
}
// Allow unit tests to fix Runtime memory
// reducetask最大可以使用内存用于shuffle的大小: 运行时最大内存*0.7
// 意思是shuffle在reduce内存中的数据最多使用内存量为0.7*maxHeap of reduce task
this.memoryLimit = (long)(jobConf.getLong(
MRJobConfig.REDUCE_MEMORY_TOTAL_BYTES,
Runtime.getRuntime().maxMemory()) * maxInMemCopyUse);
// 排序问简式一次merge合并的数量 DEFAULT_IO_SORT_FACTOR = 10
this.ioSortFactor = jobConf.getInt(MRJobConfig.IO_SORT_FACTOR,
MRJobConfig.DEFAULT_IO_SORT_FACTOR);
// 单词shuffle可以消耗的内存限制的最大百分比 0.25
final float singleShuffleMemoryLimitPercent =
jobConf.getFloat(MRJobConfig.SHUFFLE_MEMORY_LIMIT_PERCENT,
DEFAULT_SHUFFLE_MEMORY_LIMIT_PERCENT);
if (singleShuffleMemoryLimitPercent < 0.0f
|| singleShuffleMemoryLimitPercent > 1.0f) {
throw new IllegalArgumentException("Invalid value for "
+ MRJobConfig.SHUFFLE_MEMORY_LIMIT_PERCENT + ": "
+ singleShuffleMemoryLimitPercent);
}
usedMemory = 0L;
commitMemory = 0L;
long maxSingleShuffleLimitConfiged =
(long)(memoryLimit * singleShuffleMemoryLimitPercent);
if(maxSingleShuffleLimitConfiged > Integer.MAX_VALUE) {
maxSingleShuffleLimitConfiged = Integer.MAX_VALUE;
LOG.info("The max number of bytes for a single in-memory shuffle cannot" +
" be larger than Integer.MAX_VALUE. Setting it to Integer.MAX_VALUE");
}
this.maxSingleShuffleLimit = maxSingleShuffleLimitConfiged;
// 内存到内存merge的阈值时10
this.memToMemMergeOutputsThreshold =
jobConf.getInt(MRJobConfig.REDUCE_MEMTOMEM_THRESHOLD, ioSortFactor);
this.mergeThreshold = (long)(this.memoryLimit *
jobConf.getFloat(
MRJobConfig.SHUFFLE_MERGE_PERCENT,
MRJobConfig.DEFAULT_SHUFFLE_MERGE_PERCENT));
LOG.info("MergerManager: memoryLimit=" + memoryLimit + ", " +
"maxSingleShuffleLimit=" + maxSingleShuffleLimit + ", " +
"mergeThreshold=" + mergeThreshold + ", " +
"ioSortFactor=" + ioSortFactor + ", " +
"memToMemMergeOutputsThreshold=" + memToMemMergeOutputsThreshold);
if (this.maxSingleShuffleLimit >= this.mergeThreshold) {
throw new RuntimeException("Invalid configuration: "
+ "maxSingleShuffleLimit should be less than mergeThreshold "
+ "maxSingleShuffleLimit: " + this.maxSingleShuffleLimit
+ "mergeThreshold: " + this.mergeThreshold);
}
// 是否允许内存到内存的merge合并 默认为false
boolean allowMemToMemMerge =
jobConf.getBoolean(MRJobConfig.REDUCE_MEMTOMEM_ENABLED, false);
if (allowMemToMemMerge) {
this.memToMemMerger = // 如果开启执行内存到内存合并:IntermediateMemoryToMemoryMerge
new IntermediateMemoryToMemoryMerger(this,
memToMemMergeOutputsThreshold);
this.memToMemMerger.start();
} else {
this.memToMemMerger = null;
}
// 内存到磁盘合并 磁盘到磁盘合并
this.inMemoryMerger = createInMemoryMerger();
this.inMemoryMerger.start(); // 本质上是一个MergeThread 线程
this.onDiskMerger = new OnDiskMerger(this);
this.onDiskMerger.start(); // 本质上是一个MergeThread线程
this.mergePhase = mergePhase;
}
run方法
public RawKeyValueIterator run() throws IOException, InterruptedException {
// Scale the maximum events we fetch per RPC call to mitigate OOM issues
// on the ApplicationMaster when a thundering herd of reducers fetch events
// TODO: This should not be necessary after HADOOP-8942
int eventsPerReducer = Math.max(MIN_EVENTS_TO_FETCH,
MAX_RPC_OUTSTANDING_EVENTS / jobConf.getNumReduceTasks());
int maxEventsToFetch = Math.min(MAX_EVENTS_TO_FETCH, eventsPerReducer);
// Start the map-completion events fetcher thread
//创建EventsFetchr线程,来获取已完成的maps
final EventFetcher<K,V> eventFetcher =
new EventFetcher<K,V>(reduceId, umbilical, scheduler, this,
maxEventsToFetch);
eventFetcher.start();// 启动eventFetcher线程
// Start the map-output fetcher threads
// localMapFiles是一个Map集合,类型为<TaskAttemptID,MapOutputFile>
//如果时本地模式LocalJobRunner运行的mapreduce程序,则localMapFiles就记录maptaskID__>map输出结果文件位置的映射关系
//mapreduce程序,则该map集合为空
boolean isLocal = localMapFiles != null;
// 如果时本地线程运行,启动一个fetcher线程拉取数据,否则启动5个线程并发拉取
final int numFetchers = isLocal ? 1 :
jobConf.getInt(MRJobConfig.SHUFFLE_PARALLEL_COPIES, 5);
Fetcher<K,V>[] fetchers = new Fetcher[numFetchers];
if (isLocal) {// 在本地模式运行 启动一个fetcher线程拉去数据
fetchers[0] = new LocalFetcher<K, V>(jobConf, reduceId, scheduler,
merger, reporter, metrics, this, reduceTask.getShuffleSecret(),
localMapFiles);
fetchers[0].start();
} else {//分布式模式下 分别启动5个fetcher线程拉取数据 numFetchers :上文中出现过,如果没有获取默认为5
for (int i=0; i < numFetchers; ++i) {
fetchers[i] = new Fetcher<K,V>(jobConf, reduceId, scheduler, merger, // 创建fetcher线程 --> Fetcher构造方法
reporter, metrics, this,
reduceTask.getShuffleSecret());
fetchers[i].start(); // fetcher 线程启动 --> Fetcher.run();
}
}
// Wait for shuffle to complete successfully
//判断两个线程是否结束
while (!scheduler.waitUntilDone(PROGRESS_FREQUENCY)) {
reporter.progress();
synchronized (this) {
if (throwable != null) {
throw new ShuffleError("error in shuffle in " + throwingThreadName,
throwable);
}
}
}
// Stop the event-fetcher thread
// 停止 EventFetcher线程
eventFetcher.shutDown();
// Stop the map-output fetcher threads
// 停止 Fetcher线程
for (Fetcher<K,V> fetcher : fetchers) {
fetcher.shutDown();
}
// stop the scheduler
scheduler.close();
copyPhase.complete(); // copy is already complete 拉取赋值数据过程结束
taskStatus.setPhase(TaskStatus.Phase.SORT); // 进入排序sort阶段
reduceTask.statusUpdate(umbilical);
// Finish the on-going merges...
RawKeyValueIterator kvIter = null;
try {
kvIter = merger.close();
} catch (Throwable e) {
throw new ShuffleError("Error while doing final merge " , e);
}
// Sanity check
synchronized (this) {
if (throwable != null) {
throw new ShuffleError("error in shuffle in " + throwingThreadName,
throwable);
}
}
return kvIter;
}
Shuffle-Copy
Reduce 进程启动一些数据copy线程(Fetcher) ,通过HTTP方式请求maptask获取属于自己的文件,如果是本地模式运行,则启动一个fetcher线程来拉取数据,否则启动5个线程并发拉取数据
final int numFetchers = isLocal ? 1 :
jobConf.getInt(MRJobConfig.SHUFFLE_PARALLEL_COPIES, 5);
拉取线程的核心类时Fetcher类。关键方法时其中的run方法。run方法中通过copyMapOutput方法来拉取数据,那么数据拉取到哪里?需要进行一个判断,如果拉去过来的大小小于内存的大小,那么就存放在内存中,如果大于了则放置在磁盘中。后续合并也是如此,根据数据量的大小考虑在磁盘合并还是内存合并。
public void run() {
try {
while (!stopped && !Thread.currentThread().isInterrupted()) {// job 未结束 当前线程未中断
MapHost host = null;
try {
// If merge is on, block
// 如果reduce正在merge,暂停merge,以便于有空闲资源接受fetch来的数据
merger.waitForResource();
// Get a host to shuffle from
//获取所有maptask正处于PENDING 待处理状态的主机
host = scheduler.getHost();
metrics.threadBusy();
// Shuffle
//核心方法
copyFromHost(host);
} finally {
if (host != null) {
// 如果shuffle fetcher拉取失败,将失败的状态修改成PENDING 会尝试继续拉取
scheduler.freeHost(host);
metrics.threadFree();
}
}
}
} catch (InterruptedException ie) {
return;
} catch (Throwable t) {
exceptionReporter.reportException(t);
}
}
//核心方法 参数MapHost记录已经准备好待处理的《MapHost信息
protected void copyFromHost(MapHost host) throws IOException {
// reset retryStartTime for a new host
retryStartTime = 0;
// Get completed maps on 'host'
// 从mapHost中获取待处理的mapID 所谓待处理指的是map阶段已经结束等待fetch拉取
List<TaskAttemptID> maps = scheduler.getMapsForHost(host);
// Sanity check to catch hosts with only 'OBSOLETE' maps,
// especially at the tail of large jobs
if (maps.size() == 0) {
return;
}
if(LOG.isDebugEnabled()) {
LOG.debug("Fetcher " + id + " going to fetch from " + host + " for: "
+ maps);
}
// List of maps to be fetched yet
// 尚未拉取数据maps清单
Set<TaskAttemptID> remaining = new HashSet<TaskAttemptID>(maps);
// Construct the url and connect
// 构造URL并进行连接
URL url = getMapOutputURL(host, maps);
DataInputStream input = null;
try {
input = openShuffleUrl(host, remaining, url); // 建立拉取数据的输入流
if (input == null) {
return;
}
// Loop through available map-outputs and fetch them
// On any error, faildTasks is not null and we exit
// after putting back the remaining maps to the
// yet_to_be_fetched list and marking the failed tasks.
TaskAttemptID[] failedTasks = null;
//如果剩还有剩下没拉区的 继续拉区 拉取失败的,会把失败的任务记录下来并存放在failedTasks中
while (!remaining.isEmpty() && failedTasks == null) {
try {
//拉取拷贝map的输出数据
failedTasks = copyMapOutput(host, input, remaining, fetchRetryEnabled);
} catch (IOException e) {
IOUtils.cleanupWithLogger(LOG, input);
//针对出现异常的情况 会再次尝试
// Setup connection again if disconnected by NM
connection.disconnect();
// Get map output from remaining tasks only.
url = getMapOutputURL(host, remaining);
input = openShuffleUrl(host, remaining, url);
if (input == null) {
return;
}
}
}
// 处理失败的任务
if(failedTasks != null && failedTasks.length > 0) {
LOG.warn("copyMapOutput failed for tasks "+Arrays.toString(failedTasks));
scheduler.hostFailed(host.getHostName());
for(TaskAttemptID left: failedTasks) {
scheduler.copyFailed(left, host, true, false);
}
}
// Sanity check
if (failedTasks == null && !remaining.isEmpty()) {
throw new IOException("server didn't return all expected map outputs: "
+ remaining.size() + " left.");
}
input.close();
input = null;
} finally {
if (input != null) {
IOUtils.cleanupWithLogger(LOG, input);
input = null;
}
for (TaskAttemptID left : remaining) {
scheduler.putBackKnownMapOutput(host, left);
}
}
}
Shuffle-Merge操作
对于从属于不同maptask拉去过来的数据,需要进行merge合并成完整的数据,最终调用reduce方法进行业务处理。reduce的merge合并分为3中:内存到内存合并、内存安东磁盘合并、磁盘到磁盘合并
哪到哪指的是: 合并之前的数据在哪以及合并之后的数据位置在哪
其中内存读到内存合并默认不开启,因为我们通常关注后两种合并。
在启动Fetcher线程copy数据的过程中已经启动了两个merge线程,分别为inMemoryMerger和onDIskMerger。分别将内存中的数据merge到磁盘和将磁盘中的数据进行merge
可以从Shuffle.init –> createMergeManager–>New MergeManagerImpl 中确定
当所有的Fetcher拉取数据结束之后,会进行最终一次合并,最终合并的所有数据保存在kvIter中
在合并过程中会对其进行排序,默认情况下是key的字典序(WritableComparable)如果用户设置比较器,则以用户设置的为准
Reduce类
在合并、排序结束之后,进入到reduce阶段,开始调用用户编写的reduce方法进行业务逻辑处理。
reduce.run方法 : 首次在Reduce.run中调用context.nextKey()决定是否进入while循环,然后调用nextKeyValue讲key/value的值从input中取出,其次通过context.getValues讲Iterator传入reduce中,在reduce中通过Iterator.hasNext查看次key是否有下个value,然后通过Iterator.next调用nextkeyValue去input中读取Value,然后循环迭代Iterator,读取input中相同key的Value。
也就是说reduce中相同key的value在Iterator.next中通过nextKeyValue读取,没调用一次next就获取一次value。简单地说就是key相同的被分为一组,一组中所有的value会组成一个Iteratable,key则是当前value对应的key
OutputFormat
Reduce阶段的最后是通过调用context.write方法将数据写出的,负责输出数据的组件叫做outputFormat,默认实现是TextOutPutFormat。而正真负责写数据的组件时LineRecordWriter,Write就定义在其中。这一点和输入组件很是类似,LineRecordWriter的行为是一次输出写一行,再有输出换行写
在构造LineRecordWriter的时候,已经设置了key、value之间是以\t制表符分隔的
Shuffle
Shuffle是什么?
Shuffle本意是洗牌、混洗的意思,把一组有规则的数据尽量打乱成无规则的数据,而MapRedcue中,Shuffle更像是洗牌的逆流程,指的是讲map端的无规则输出按指定的规则“打乱”成具有一定规则的数据,以便于Reduce端进行接受处理。
一般把从map产生开始到Reduce取得数据作为输出之前的过程都称之为shuffle,shuffle是MapReduce的核心
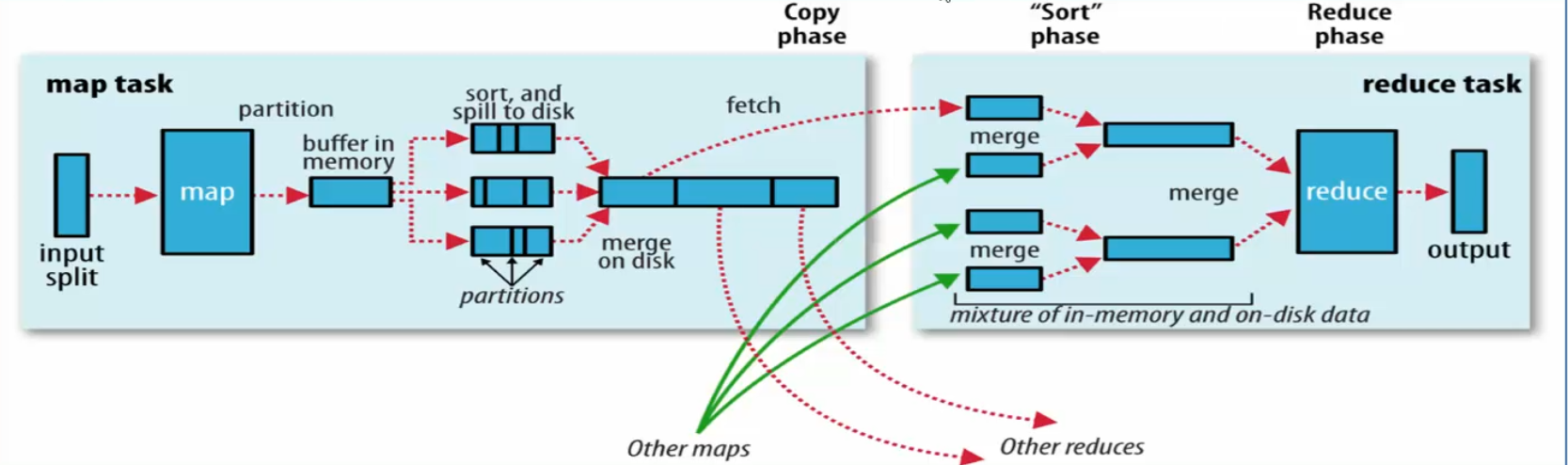
广义上shuffle指的是map方法产生输出开始。(一般来说更加偏向于广义上的shuffle)这样子就包括了 【Map阶段】- - - Partition、Spill、Sort、Merge - - - - 【Reduce阶段】Copy、Merge、Sort
从狭义上讲shuffle指定的是maptask结束产生中间结果开始,这样子就只包括了reduce解毒丹的Copy、Merge、Sort
Shuffle弊端
- shuffle过程
繁琐、琐碎,设计了多个阶段的任务交接 - shuffle中
频繁进行IO操作,反复设计内存到磁盘、磁盘到内存、内存在到磁盘的过程,效率极低 - shuffle阶段,大量的数据从map阶段输出,发送到reduce阶段,这
一过程中,可能会涉及到大量的网络IO