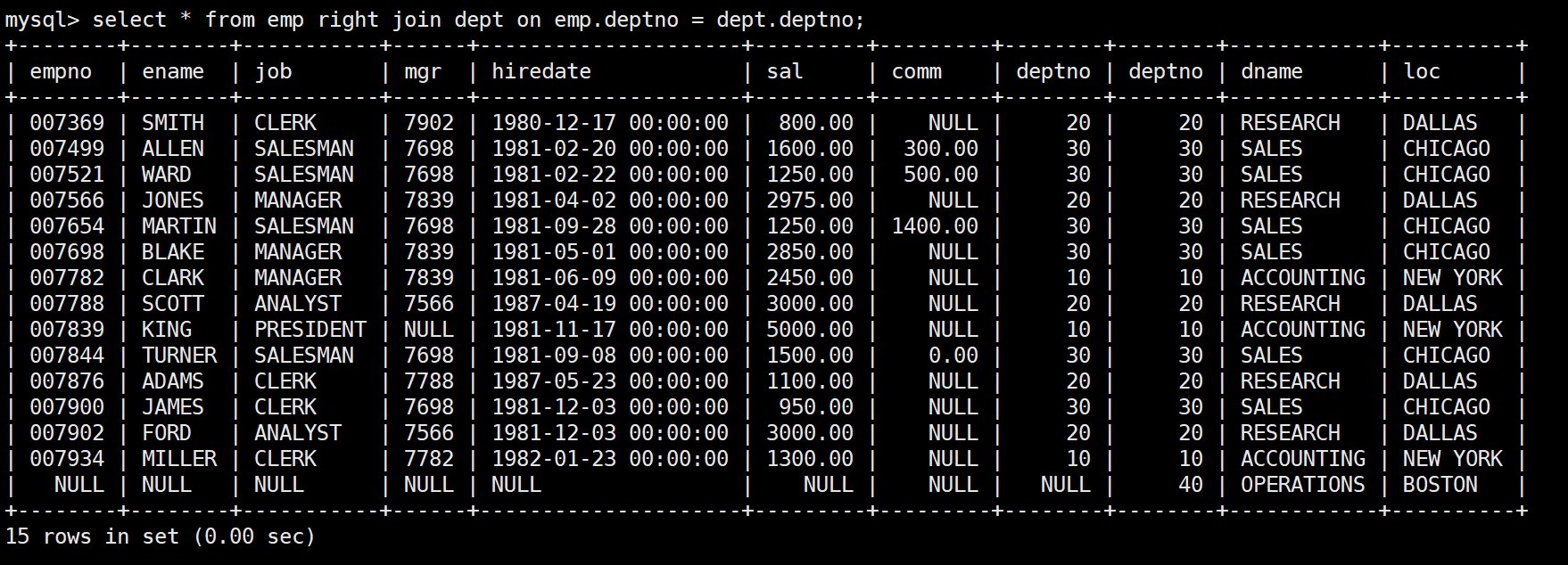
1. 字符集(character set)
1.1. 字符集与编码规则
字符集(character set)即为众多字符的集合。字符集为每个字符分配一个唯一的 ID,称为 “Code Point(码点)”。编码规则是将 Code Point 转换为 0、 1 二进制序列的规则。通俗地理解,不同的字符集规定了字符集中包含的字符范围,而编码规则规定了每个字符在计算机中的二进制表达方式。
1.2. 常见的字符集与编码规则
- GB2312
GB2312 是 1980 年发布的中国国家标准的简体中文字符的集合与每个汉字的编码方式。也就是说 GB2312 即是字符集,又是编码规则。
- GBK
GBK 是对 GB2312 的补充,完全兼容 GB2312。同 GB2312 一样, GBK 也即是字符集,又是编码规则。
- Unicode(Universal Multiple-Octet Coded Character Set)
Unicode 是由名为 Unicode 的学术机构推出的字符集,其目的是收录人类目前已知在用的所有字符,并为它们进行统一的分类和编号。但是, Unicode 只负责给字符编号,却不负责具体的编码规则。 也就是说 Unicode 只是字符集,其编码规则根据编码字节长度的不同,包括 UTF-8, UTF-16, UTF-32。
1.2.1. Unicode 编码规则
- UTF-8
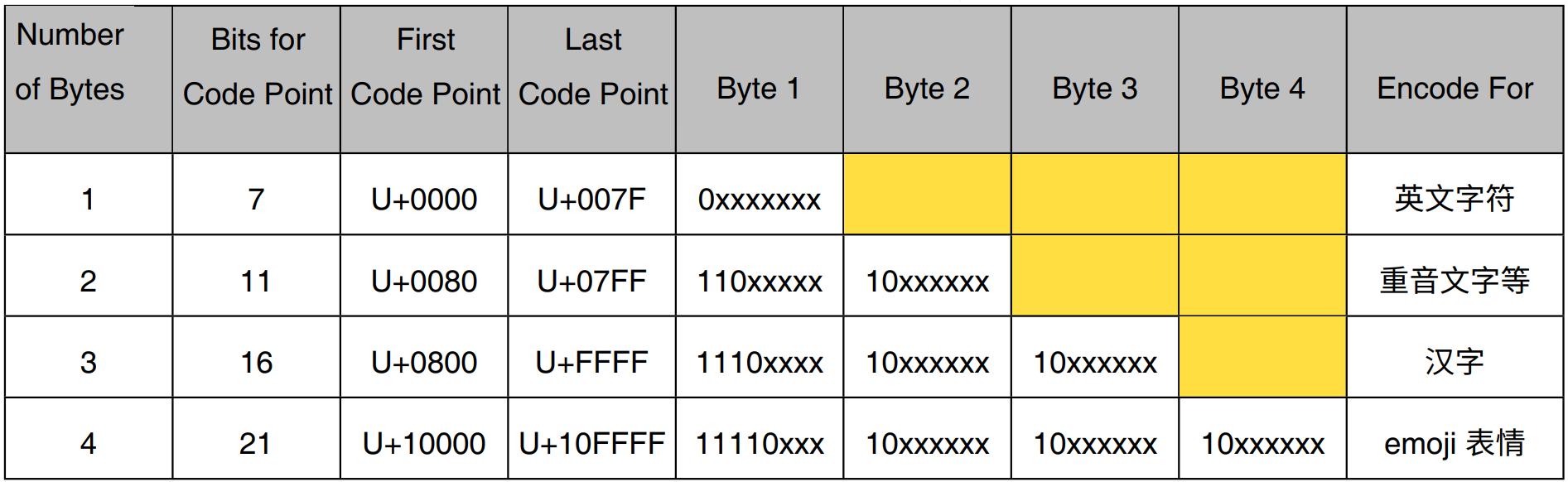
UTF-8 编码属于变长字节编码规则。即用 1-4 个字节表示 Unicode 字符集中的 1 个字符(如下表所示)。UTF-8 编码规定:最高位以 0 开头的,用 1 个字节表示 1 个字符,如英文字符;最高位以 110 开头的字节,与其后 1 个以 10 开头的字节拼接为一个整体,即用 2 个字节表示 1 个字符;最高位以 1110 开头的字节,与其后 2 个以 10 开头的字节拼接为一个整体,即用 3 个字节表示 1 个字符,如汉字。最高位以 11110 开头的字节,与其后 3 个以 10 开头的字节拼接为一个整体,即用 4 个字节表示 1 个字符,如 emoji 表情。
- UTF-16
UTF-16 编码属于定长字节编码规则,固定地使用 2 个字节来表示 Unicode 中的 1 个字符。
- UTF-32
UTF-32 编码属于定长字节编码规则,固定地使用 4 个字节来表示 Unicode 中的 1 个字符。其优点是根据 Unicode 中的字符编号,直接对字符编码,无需额外的解析工作。缺点是常用字符有大量的高位被 0 填充,造成空间浪费。
提示:为了便于统一管理各地区、各国家的编码规则,标准化组织用 “页码” 对众多的编码规则进行了编号,如 GBK 的页码为 956,而 UTF-8 的页码为 65001。这样,直接通过页码即可找到所需的编码规则。
注意:在 Windows 系统中,常常会同时出现 UTF-8 和 Unicode 两个编码规则。按道理, Unicode 只是字符集,不应出现在编码规则当中。其原因是,微软默认将 Unicode 当作 UTF-16 编码来处理。
2. 排序规则(Collation)
排序规则(Collation)定义了字符集中每个字符的大小、先后顺序以及等价规则等。如哪个字符应排在哪个字符之前、哪个字符与哪个字符相等。 Collation 依赖于字符集(Character Set),比如 utf8mb4_general_ci 排序规则,要求字符集需要为 utf8mb4; 而 gbk_chinese_ci 排序规则,则要求字符集为 gbk。
如果把字符看作人, Character Set 就相当于为每个字符发放一个身份证号,所有的身份证号组成了字符集。而 Collation 相当于规定字符在排队的时候,谁在前、谁在后。 字符集可以有多个 Collation ,相当于可灵活地按身高、体重、年龄等多种维度来为每个人排序,其排队的顺序与字符的身份证号无关。
3. TiDB 中的字符集与排序规则
3.1. TiDB 与 MySQL 中的字符集及排序规则
| 排序规则 | 排序结果 | 字符集 | TiDB 默认 | MySQL 默认 | 说明 |
|---|---|---|---|---|---|
| utf8_bin | 二进制存储 区分大小写 | utf8 | √ | MySQL 从 8.0.30 开始将 utf8 更名为 utf8mb3。 | |
| utf8_general_ci | 速度快,准确度低 不区分大小写 | utf8 | √ | MySQL 从 8.0.30 开始将 utf8 更名为 utf8mb3。 | |
| utf8_unicode_ci | 速度慢,准确度高 不区分大小写 | utf8 | MySQL 从 8.0.30 开始将 utf8 更名为 utf8mb3。 | ||
| utf8mb4_bin | 区分大小写 | utf8mb4 | √ | ||
| utf8mb4_general_ci | 速度快,准确度低 不区分大小写 | utf8mb4 | √ | ||
| utf8mb4_unicode_ci | 遵循 UCA 4.0.0 规范 速度慢,准确度高 不区分大小写 | utf8mb4 | |||
| utf8mb4_0900_ai_ci (MySQL 8.0 引入) | 遵循 UCA 9.0.0 规范 不区分音调 不区分大小写 | utf8mb4 | 不支持 | √(8.0 引入) | MySQL 从 8.0 引入; e、ē、é、ě、è 等价,E 与 e 等价。 |
| utf8mb4_0900_as_ci (MySQL 8.0 引入) | 遵循 UCA 9.0.0 规范 区分音调 不区分大小写 | utf8mb4 | 不支持 | 8.0 引入 | MySQL 从 8.0 引入; e、ē、é、ě、è 不等价,E 与 e 等价。 |
| utf8mb4_0900_as_cs (MySQL 8.0 引入) | 遵循 UCA 9.0.0 规范 区分音调 区分大小写 | utf8mb4 | 不支持 | 8.0 引入 | MySQL 从 8.0 引入; e、ē、é、ě、è 不等价,E 与 e 不等价。 |
| utf8mb4_0900_bin (MySQL 8.0 引入) | 遵循 UCA 9.0.0 规范 二进制存储 区分大小写 | utf8mb4 | 不支持 | 8.0 引入 | MySQL 从 8.0 引入; E 与 e 不等价。 |
| utf8mb4_zh_0900_as_ci (MySQL 8.0 引入) | 遵循 UCA 9.0.0 规范 区分音调 不区分大小写 | utf8mb4 | 不支持 | 8.0 引入 | _zh 特定于中文的 Unicode 排序规则, 类似的还有日语(ja)、俄语(ru)等。 |
| gbk_bin | 区分大小写 | gbk | √(未启用新排序框架时) | TiDB 5.4 引入了对 gbk 字符集的支持。 | |
| gbk_chinese_ci | 按拼音排序 不区分大小写 | gbk | √(启用新排序框架时) | √ | TiDB 5.4 引入了对 gbk 字符集的支持。 |
| gb18030_bin | 二进制存储 区分大小写 | gb18030 | 不支持 | ||
| gb18030_chinese_ci | 按拼音排序 不区分大小写 | gb18030 | 不支持 | √ | |
| gb18030_unicode_520_ci | 遵循 UCA 5.2.0 规范 不区分大小写 | gb18030 | 不支持 | ||
| gb2312_bin | 二进制存储 区分大小写 | gb2312 | 不支持 | ||
| gb2312_chinese_ci | 按拼音排序 不区分大小写 | gb2312 | 不支持 | √ |
排序规则名称中的关键字解释:- utf8(utf8mb3):用 1-3 个字节来编码 Unicode 字符集中的 1 个字符;MySQL 从 8.0.30 开始,将 utf8 名称调整为 utf8mb3,如字符集 utf8mb3 及以 utf8mb3_ 为前缀的排序规则。TiDB 因兼容 MySQL 5.7,所以仍延用旧的名称 utf8;- utf8mb4:使用 1-4 个字节来编码 Unicode 字符集中的 1 个字符,增加了对 Emoji 表情的支持;- _bin:二进制存储,区分大小写。如 E 与 e 不等价;- _cs:即 case sensitivity。区分大小写。如 E 与 e 不等价;- _ci:即 case insensitivity。不区分大小写。如 E 与 e 等价;- _as:即 accent sensitivity。区分音调,如 e、ē、é、ě、è 不等价;- _ai:即 accent insensitivity 。不区分音调,如 e、ē、é、ě、è 等价;- _general:排序速度快,准确度低;- _unicode:排序遵循 UCA 4.0.0 规范,速度慢,准确度高;MySQL 依据 UCA(Unicode Collation Algorithm)4.0.0 实现了 xxx_unicode_ci 排序规则;- _520、_0900:排序遵循 UCA 5.2.0、UCA 9.0.0 规范;MySQL 在实现遵循 > UCA 4.0.0 的排序规则时,在排序规则名称中包含 UCA 版本号。如,utf8_unicode_520_ci 遵循 UCA 5.2.0 规范进行排序;utf8mb4_0900_ai_ci(MySQL 8.0 引入)遵循 UCA 9.0.0 规范进行排序;- _chinese:按中文拼音排序,如 ē<é<ě<è;- _zh:特定于中文的 Unicode 排序。类似的还有 ja 特定于日语的排序、ru 特定于俄语的排序等;
3.2. new_collations_enabled_on_first_bootstrap
在 TiDB 4.0 之前, TiDB 只能在语法上支持(即不报错)的绝大部分 MySQL 排序规则,但在语义上将所有的排序规则都视作 _bin 二进制排序规则。从 TiDB v4.0 开始,在集群初始化时,引入了 TiDB 配置项 “new_collations_enabled_on_first_bootstrap” 以启用新的排序框架,用于在语义上支持不同的排序规则。
new_collations_enabled_on_first_bootstrap 仅 支 持 在 新 建 TiDB 集群 时, 在 TiDB 集 群 拓 扑 配 置 文 件 的
server_config.tidb标 签 中 指定 “new_collations_enabled_on_first_bootstrap:true”,一旦 TiDB 集群创建完毕,则无法变更此配置项的值。
server_config:
tidb:
new_collations_enabled_on_first_bootstrap: true
在 TiDB v4.x-v5.x 中,该配置项默认为 false,即不启用新排序框架,仅支持 utf8mb4_bin(大小写敏感)排序规则。从 TiDB v6.0.0 开始,该配置项的默认值为 true, TiDB 可支持 utf8_general_ci、utf8mb4_general_ci、 utf8_unicode_ci、 utf8mb4_unicode_ci、 gbk_chinese_ci 和 gbk_bin 这几种排序规则。
可通过系统表 mysql.tidb 确认是否启用了新的排序框架:
SELECT VARIABLE_VALUE FROM mysql.tidb WHERE VARIABLE_NAME=’new_collation_enabled’;
注意:在旧排序框架中, TiDB 不会处理字符串末尾的空格。如 “
a” 与 “a” 在 TiDB 中被视为不同的值,而在 MySQL 中会将通过 PADDING 为 “a” 末尾补齐空格,再与 “a” 相比较,即视为相同的值。在新排序框架中, TiDB 与 MySQL 兼容,会将 “a” 与 “a” 视为等价,只是在实现方式上与 MySQL 不同。 TiDB 通过裁剪 “a” 末尾的空格后,再与 “a” 相比较。
3.3. TiDB 中设置字符集与排序规则
可通过如下几种方式,分别为 TiDB 集群、数据库、库表、列设置字符集与排序规则:
- 设置 TiDB 集群默认字符集及默认排序规则。
默认字符集为 utf8mb4,默认排序规则为 utf8mb4_bin。可通过系统变量 character_set_server 设置 TiDB 集群默认的字符集,通过 collation_server 设置 TiDB 集群默认的排序规则。在 “CREATE DATABASE/SCHEMA” 时,若未显式指定字符集与排序规则,则默认继承系统变量 character_set_server 与 collation_server 的设置。
/* 1. 设置 TiDB 集群默认字符集的两种方式 */
mysql> SET @@GLOBAL.character_set_server = ”utf8mb4”;
mysql> SET GLOBAL character_set_server = ”utf8mb4”;
/* 2. 设置 TiDB 集群默认排序规则的两种方式 */
mysql> SET @@GLOBAL.collation_server = ”utf8mb4_bin”;
mysql> SET GLOBAL collation_server = ”utf8mb4_bin”;
/* 3. 查看 TiDB 集群默认字符集及默认排序规则 */
mysql> SELECT * FROM GLOBAL_VARIABLES WHERE variable_name IN (’character_set_server’,’collation_server’);
mysql> SHOW GLOBAL variables LIKE ’character_set_server’;
mysql> SHOW GLOBAL variables LIKE ’collation_server’;
- 为数据库指定字符集及默认排序规则。
若未显式为数据库指定字符集、排序规则,则继承自 TiDB 集群的字符集设置。可通过系统变量 @@character_set_database 和 @@collation_database 查看到当前数据库的字符集以及排序规则。也可通过系统表 information_schema.schemata 查看每个数据库的字符集与排序规则。
/* 1. 创建数据库(DATABASE/SCHEMA)时,指定默认字符集及排序规则 */
mysql> CREATE DATABASE DB_001 CHARACTER SET gbk COLLATE gbk_bin ;
mysql> CREATE SCHEMA DB_002 CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci ;
/* 2. 通过 @@character_set_database 与 @@collation_database 查看数据库的字符集及排序规则 * /
mysql> USE db_001;
mysql> SELECT @@character_set_database, @@collation_database ;
+--------------------------+----------------------+
| @@character_set_database | @@collation_database |
+--------------------------+----------------------+
| gbk | gbk_bin |
+--------------------------+----------------------+
1 row in set (0.00 sec )
mysql> USE db_002;
mysql> SELECT @@character_set_database, @@collation_database;
+--------------------------+----------------------+
| @@character_set_database | @@collation_database |
+--------------------------+----------------------+
| utf8mb4 | utf8mb4_general_ci |
+--------------------------+----------------------+
1 row in set (0.00 sec )
/* 3. 通过系统表 information_schema.schemata 查看每个数据库字符集及排序规则 */
mysql> SELECT schema_name , default_character_set_name , default_collation_name FROM information_schema.schemata WHERE schema_name in ('DB_001', 'DB_002');
/* 4. 通过ALTER DATABASE 调整数据库的字符集与排序规则 */
mysql> ALTER DATABASE db_002 CHARACTER SET gbk COLLATE gbk_chinese_ci;
mysql> SELECT @@character_set_database , @@collation_database ;
+--------------------------+----------------------+
| @@character_set_database | @@collation_database |
+--------------------------+----------------------+
| utf8mb4 | utf8mb4_general_ci |
+--------------------------+----------------------+
1 row in set (0.00 sec )
- 为表指定字符集及排序规则。
若未为表显式指定字符集与排序规则,则继承自其所属数据库的字符集设置。
mysql> use db_001;
mysql> SELECT @@character_set_database, @@collation_database;
+--------------------------+----------------------+
| @@character_set_database | @@collation_database |
+--------------------------+----------------------+
| gbk | gbk_bin |
+--------------------------+----------------------+
mysql> CREATE TABLE tb_001(id int, name varchar(32)) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin;
/* 2. 未指定字符集设置,继承自 DB_001 数据库的字符集设置 */
mysql> CREATE TABLE tb_002(id int, name varchar(32));
mysql> SELECT table_name, table_collation FROM INFORMATION_SCHEMA.TABLES WHERE table_schema = 'DB_001';
+------------+-----------------+
| table_name | table_collation |
+------------+-----------------+
| tb_001 | utf8mb4_bin |
| tb_002 | gbk_bin |
+------------+-----------------+
2 rows in set (0.00 sec)
- 为列指定字符集及排序规则。
若未为列指定字符集与排序规则,则继承自其所属表的字符集设置。
mysql> USE db_001 ;
mysql> CREATE TABLE tb_003(
id int ,
name1 varchar(32) , /* 继承自表的字符集设置 */
name2 varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci /* 显式指定列的字符集设置 */
) CHARACTER SET gbk COLLATE gbk_bin; /* 显式指定表的字符集设置 */
mysql> SELECT table_name, column_name, column_type, character_set_name, collation_name
FROM INFORMATION_SCHEMA.COLUMNS
WHERE table_schema = 'DB_001' AND table_name = 'tb_003';
+------------+-------------+-------------+--------------------+--------------------+
| table_name | column_name | column_type | character_set_name | collation_name |
+------------+-------------+-------------+--------------------+--------------------+
| tb_003 | id|int(11) | NULL | NULL | |
| tb_003 | name1 | varchar(32) | gbk | gbk_bin |
| tb_003 | name2 | varchar(32) | utf8mb4 | utf8mb4_unicode_ci |
+------------+-------------+-------------+--------------------+--------------------+
- 为字符串指定字符集及排序规则。
若未指定,则继承自系统变量 character_set_connection 和 collation_connection 。注意,TiDB 不支持使用 _gbk 为字符串指定字符集。
mysql> SELECT _utf8mb4 '盛京征信' COLLATE utf8mb4_bin;
+--------------------------------------------+
| _utf8mb4 '盛京征信' COLLATE utf8mb4_bin |
+--------------------------------------------+
| 盛京征信 |
+--------------------------------------------+
1 row in set (0.00 sec )
mysql> SELECT _utf8mb4 '盛京征信' COLLATE utf8mb4_unicode_ci;
+---------------------------------------------------+
| _utf8mb4 '盛京征信' COLLATE utf8mb4_unicode_ci |
+---------------------------------------------------+
| 盛京征信 |
+---------------------------------------------------+
1 row in set (0.00 sec )
3.4. TiDB 中的 GBK 字符集
TiDB v5.4.0 开始支持 GBK 字符集,在未启用新排序框架时,GBK 的默认排序规则为 gbk_bin。启用新排序框架(new_collations_enabled_on_first_bootstrap=true)后,即可与 MySQL 保持一致,即 GBK 的默认排序规则为 gbk_chinese_ci。
截至 TiDB v6.1.0,TiDB 中 gbk 字符集具有如下的限制:
- 截至 TiDB v6.1.0,不支持通过
ALTER TABLE语句将gbk字符集与其他字符集进行互转。 - TiDB 不支持使用
_gbk,如 “SELECT _gbk '盛京征信' COLLATE gbk_chinese_bin;”。 - 对于
ENUM和SET类型中的二进制字符,TiDB 都会将其作为utf8mb4字符集处理。 - TiFlash 目前不支持 GBK 字符集。
- TiDB Data Migration (DM) 在 v5.4.0 之前不支持将
charset=GBK的表迁移到 TiDB。 - TiDB Lightning 在 v5.4.0 之前不支持导入
charset=GBK的表。 - TiCDC 在 v6.1.0 之前不支持同步
charset=GBK的表。另外,所有版本的 TiCDC 都不支持同步charset=GBK的表到版本低于 6.1.0 的 TiDB 集群。 - TiDB BR 在 v5.4.0 之前不支持恢复
charset=GBK的表。另外,任何版本的 BR 都不支持恢复charset=GBK的表到版本低于 5.4.0 的 TiDB 集群。