大家好,我是微学AI,今天给大家介绍一下深度学习实战29-AIGC项目:利用GPT-2(CPU环境)进行文本续写与生成歌词任务。在大家没有GPU算力的情况,大模型可能玩不动,推理速度慢,那么我们怎么才能跑去生成式的模型呢,我们可以试一下GPT-2完成一些简单的任务,让大家在CPU环境下也能进行生成式模型的推理。
一、GPT2模型
GPT-2是一种基于Transformer结构的大规模预训练语言模型,由OpenAI研发。Transformer模型之前讲过可以查看《深度学习实战24-人工智能(Pytorch)搭建transformer模型》。
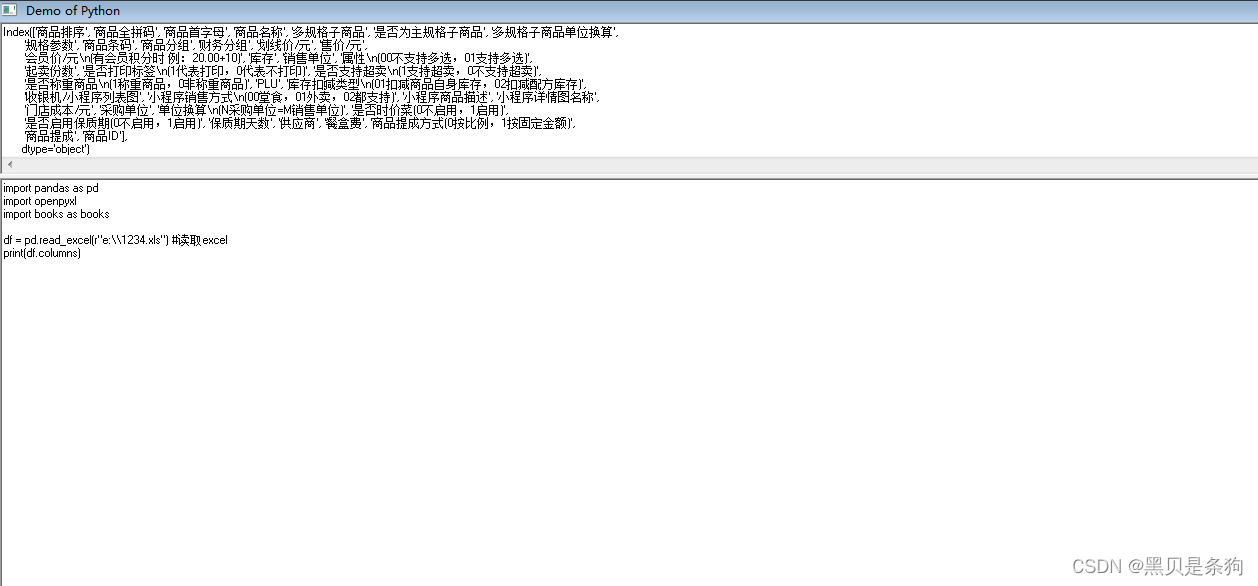
GPT2它可以通过对大量文本数据进行预训练学习,然后针对不同任务进行微调,以实现更好的表现。GPT-2的预训练采用了无监督的方式,利用海量的文本数据构建语言模型。预训练过程中,输入的文本序列首先经过Token Embedding层和Positional Encoding层,然后输入到多个Transformer Decoder层中。每个Decoder层都由多头自注意力机制、前向神经网络和残差连接组成。在训练过程中,模型根据当前输入的文本序列来预测序列中下一个单词出现的概率分布,并根据损失函数进行优化,使得预测结果更加准确。
二、GPT-2的结构
GPT-2的结构主要由以下三部分组成:
1.Positional Encoding:为单词或字符的向量表示增加位置信息,以保证模型能够区分不同位置上的单词或字符。
2.Token Embedding:将每个单词或字符转换为对应的向量表示。
3.Transformer Decoder:由多个Encoder和Decoder层组成,其中Encoder层用于编码输入的文本序列,而Decoder层用于生成下一个单词的概率分布
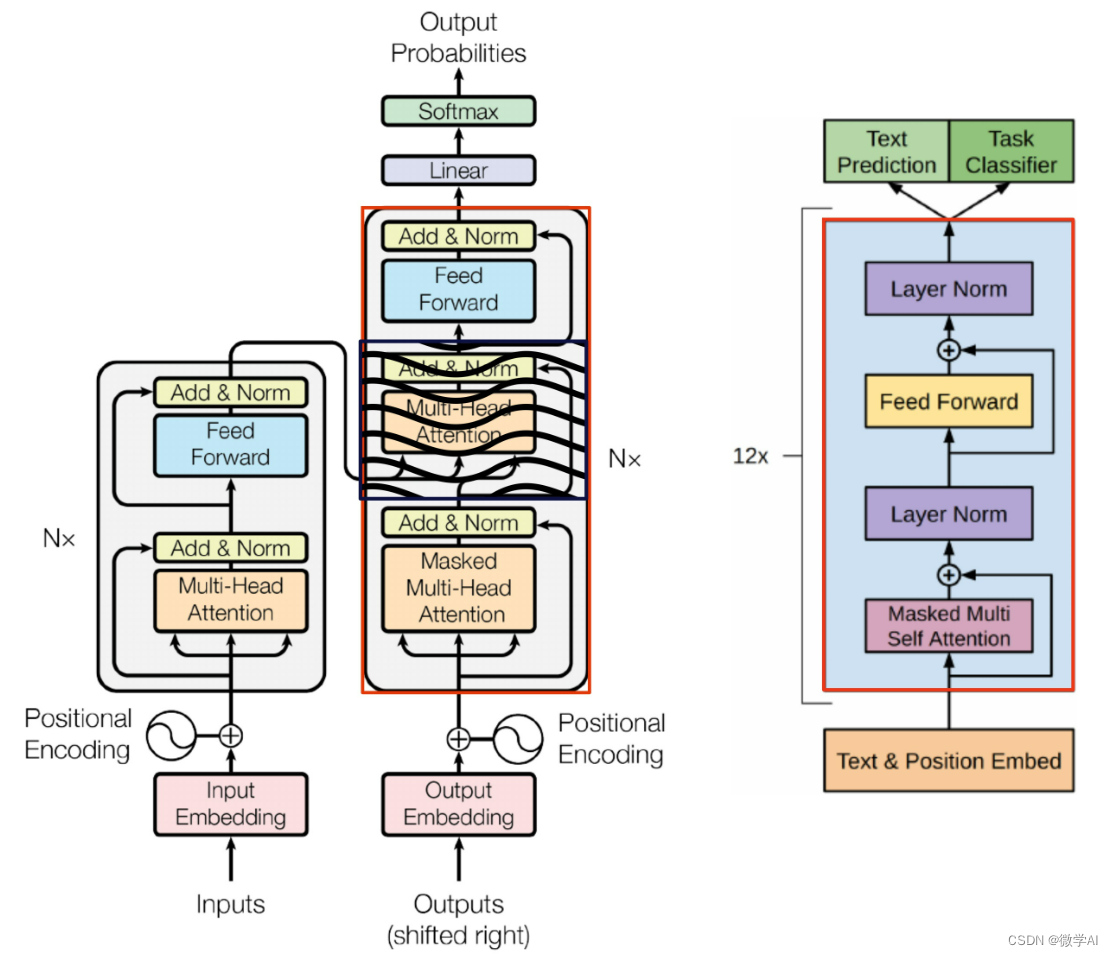
左:Trahformer模型; 右 : GPT Decoder Trahformer
三、GPT-2模型的特点
1.大规模预训练:GPT-2采用了海量的文本数据进行预训练,使得其在多个NLP任务上都表现出色。
2.自回归生成:GPT-2是一种自回归语言模型,可以根据前面已经生成的单词来生成后面的单词,从而生成连贯的文本内容。
3.多头注意力机制:GPT-2中使用了多头注意力机制,使得模型能够更好地捕捉输入序列之间的关系,提高了预测准确性。
四、GPT-2模型实现文本续写功能
from transformers import BertTokenizer, GPT2LMHeadModel, TextGenerationPipeline
tokenizer = BertTokenizer.from_pretrained("uer/gpt2-chinese-cluecorpussmall")
model = GPT2LMHeadModel.from_pretrained("uer/gpt2-chinese-cluecorpussmall")
text_generator = TextGenerationPipeline(model, tokenizer)
text = """会议主题:加快区块链技术创新附能实体经济
近几年来,区块链技术与越来越多的实体行业深度融合"""
result = text_generator(text, max_length=500, do_sample=True)
res = result[0]['generated_text'].replace(text,'')
print(res.replace(' ',''))生成结果:
。在中国,区块链拥有广泛的用户,很多客户希望能够以相同价格买到更多的产品。但是,区块链技术在中国一直被沿用至今,并且在逐渐取代了人们认为的现有产品。所以,对于一款商品来说,有一些问题尚且如此。此类问题的存在,使得人们对区块链的商业化和普及发展感到担忧。区块链能否成为未来全球交易市场中的一个新的方向?区块链技术能否改变商品交易中,消费者和机构之间的信息不对称、恶意盗窃和信用不良记录的现象,是否能够使这一市场重新开始?一切以商品来安全为前提,从这个角度上来说,这样的问题一直没有被解决。不过,无论如何,人们希望在价格、时间、地点等方面完成变革。在这个过程中,我们能够看到,以市场为标尺,以信息为动力的商品,以实体为主的金融体系,都在以价格为导向,以及价格的改变。而这个过程不仅仅是以市场为前提,而是一种精准定位系统,这包括我们的消费金融、智能硬件和互联网金融等相关服务的产品和服务。所以,区块链能否成为未来全球交易的新方向并不仅仅在于产品、服务和技术,而是在于通过区块链技术改变人们的消费行为。在大数据五、GPT-2模型实现歌词续写功能
from transformers import BertTokenizer, GPT2LMHeadModel, TextGenerationPipeline
tokenizer = BertTokenizer.from_pretrained("uer/gpt2-chinese-lyric")
model = GPT2LMHeadModel.from_pretrained("uer/gpt2-chinese-lyric")
text_generator = TextGenerationPipeline(model, tokenizer)
text = "最美的不是下雨天,是曾与你躲过雨的屋檐"
result = text_generator(text, max_length=120, do_sample=True)
res = result[0]['generated_text'].replace(text,'')
print(res.replace(' ',''))生成结果:
,那些被风吹散的缠绵,像是一个怀抱在怀间,我的爱情就像天边飞舞的流萤,在天下着一场一场的雨,是一种美丽的错觉是一种思念,我会把你慢慢的忘记,我会把你收藏在心底,让一切逝去不会再提起,就像在夜空里飞舞的
更多功能会持续更新!






![buu [AFCTF2018]花开藏宝地 1](https://img-blog.csdnimg.cn/6df4749ea0554a52842c3f4befa6c0e9.png)