编者按:本系列文章参考总结自IBM,FaceBook,Google等数据仓库构建英文文章,部分章节为直译过来,部分内容加上乐哥6年陌陌,快手等工作经验总结而来,让大家了解真实国外大厂数仓构建之路,国外同行对数仓的理解
1.什么是数据仓库,维度数据库,数据集市?
在最广泛的意义上,术语数据仓库是指包含非常大的历史数据存储的数据库。数据存储为一系列快照,其中每条记录代表特定时间的数据。通过分析这些快照,您可以在不同时间段之间进行比较。然后,您可以使用这些比较来帮助企业管理人员做出重要的业务决策;
数据仓库有多种叫法,最本质的的叫法维度数据库(下文会混合叫法), 维度数据库是数据仓库的最佳数据库类型。维度数据库是使用维度数据模型来组织数据的关系数据库。此模型在星型或雪花模式中使用事实表和维度表。
数据仓库可以理解为数据检索而优化的数据库,以方便报告和分析的生成。数据仓库包含关于许多主题领域(通常是整个企业)的信息。通常使用维度数据模型来设计数据仓库。使用星型和雪花模式将数据组织到维度表和事实表中。为了提高查询性能,对数据进行了反规范化处理。数据仓库的设计通常从分析已经存在的数据开始,以及如何以一种可以在以后使用的方式收集数据。不是将事务数据直接加载到仓库中,而是在将数据加载到仓库之前对其进行集成和转换。+
数据仓库的主要优点是它可以轻松访问和分析许多主题领域的大量信息。
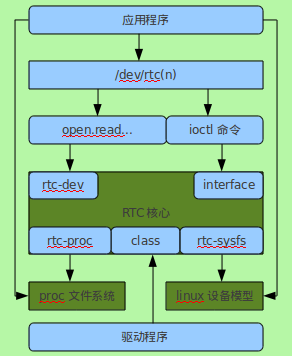
图 1. 以 DAILY_SALES 表作为事实表的示例雪花模式。

数据集市:面向企业的一个或多个特定主题领域(例如跟踪库存或交易)而不是整个企业的数据库。数据集市由各个部门或组使用。与数据仓库一样,您通常使用维度数据模型来构建数据集市。例如,数据集市可能使用由一个事实表和多个维度表组成的单个星型模式。数据集市的设计通常从分析用户需要的数据开始,而不是关注已经存在的数据。
2. 带有 DAILY_SALES 事实表的数据集市
2.数据仓库(维度数据库)与数据库的对比?
数据仓库数据库针对数据检索进行了优化。数据的重复或分组(称为数据库反规范化)可以提高查询性能,是数据仓库维度设计的自然结果。相比之下,传统的在线事务处理(OLTP)数据库将日常事务操作自动化。OLTP数据库针对数据存储进行了优化,并努力消除数据重复。实现这一目标的数据库称为规范化数据库
关系型数据库针对在线事务处理 (OLTP) 进行了优化,旨在满足企业的日常运营需求。OLTP 系统倾向于围绕特定流程组织数据,例如订单输入。通过使用规范化数据模型来调整数据库性能以满足这些操作需求,该模型使用数据库规范化规则存储数据。因此,数据库可以非常快速地检索少量记录。
维度数据模型的一些优点是数据检索往往非常快速,并且数据仓库的组织更易于用户理解和使用。如果您尝试使用专为 OLTP 设计的数据库作为数据仓库,查询性能会非常慢,并且很难对数据进行分析。
维度数据库(数据仓库)需要设计为支持检索大量记录并以不同方式汇总数据的查询。维度数据库往往是面向主题的(这下知道为啥要有主题域建设了吧),旨在回答诸如“哪些产品卖得好?”之类的问题。“某些产品在一年中的什么时候卖得最好?” “哪些地区的销售最弱?”
在维度数据模型中,数据表示为事实或维度。事实通常是有关交易的数字数据,例如订购的商品数量。维度是关于数字事实的参考信息,例如客户的姓名。加载到维度数据库中的任何新数据通常都是批量更新的,通常来自多个来源。
下表总结了 OLTP 和 OLAP 数据库之间的主要区别

企业试图解决的许多问题本质上都是多维的(区别数据库)。例如,按地区创建产品销售摘要、按产品按地区销售等的 SQL 查询可能需要在 OLTP 数据库上进行数小时的处理。但是,维度数据库可以在很短的时间内处理相同的查询。
复习一下数据库的三范式3NF模型,只有理解了3NF的要求与原理,才能区别三范式建模和维度建模的区别哈;
第一范式(又称1NF):确保每列的原子性.如果每列(或者每个属性)都是不可再分的最小数据单元(也称为最小的原子单元)则满足第一范式.例如:顾客表(姓名、编号、地址、……)其中"地址"列还可以细分为国家、省、市、区等。第二范式(又称2NF):在第一范式的基础上更进一层,目标是确保表中的每列都和主键相关.如果一个关系满足第一范式,并且除了主键以外的其它列,都依赖于该主键,则满足第二范式.例如:订单表(订单编号、产品编号、定购日期、价格、……),"订单编号"为主键,"产品编号"和主键列没有直接的关系,即"产品编号"列不依赖于主键列,应删除该列。第三范式(3NF):在第二范式的基础上更进一层,目标是确保每列都和主键列直接相关,而不是间接相关.如果一个关系满足第二范式,并且除了主键以外的其它列都不依赖于主键列,则满足第三范式.为了理解第三范式,需要根据Armstrong公里之一定义传递依赖。假设A、B和C是关系R的三个属性,如果A-〉B且B-〉C,则从这些函数依赖中,可以得出A-〉C,如上所述,依赖A-〉C是传递依赖。例如:订单表(订单编号,定购日期,顾客编号,顾客姓名,……),初看该表没有问题,满足第二范式,每列都和主键列"订单编号"相关,再细看你会发现"顾客姓名"和"顾客编号"相关,"顾客编号"和"订单编号"又相关,最后经过传递依赖,"顾客姓名"也和"订单编号"相关。为了满足第三范式,应去掉"顾客姓名"列,放入客户表中。
3.维度数据建模的概念
要构建维度数据库,您首先要为您的业务设计维度数据模型(维度建模),对此你需要了解维度模型与事务模型有何不同、什么是事实表和维度表以及如何有效地设计它们。学习如何分析组织中收集数据的业务流程,并使用该分析为您的维度数据设计模型
要构建维度数据库,您需要从维度数据模型开始。维度数据模型提供了一种使数据库简单易懂的方法。您可以将维度数据库设想为具有三个或四个维度的数据库多维数据集,其中用户可以沿其任何维度访问数据库的一部分。要创建维度数据库,您需要一个可让您可视化数据的模型。
举个例子:假设您的企业在不同市场销售产品,并且您希望评估一段时间内的表现。很容易将此业务流程想象为一个数据立方体,其中包含时间、产品和市场的维度。下图显示了这个维度模型。沿着立方体线的各种交叉点将包含业务量度。这些度量对应于特定的组合:产品、市场和时间数据。

维度模型的另一个名称是星型模型。数据库设计者之所以使用这个名称,是因为该模型的图表看起来像一个带有一个中央表格的星形,围绕该表格显示了一组其他表格。中央表是模式中唯一一个具有多个连接的表,将其连接到所有其他表。这个中心表称为事实表,其他表称为维度表。无论查询如何,维度表都只有一个将它们附加到事实表的连接。下图显示了在不同市场销售产品并评估一段时间内的业务绩效的企业的简单维度模型。

3.1 事实表
事实表存储业务的度量,并指向每个维度表最底层的键值。这些措施是关于该主题的定量或事实数据。
这些度量通常是数字的并且对应于问题的“多少”或“多少”方面。度量的示例是价格、产品销售、产品库存、收入等。度量可以基于表中的列,也可以通过计算得出。
下表显示了一个事实表,其度量是当日向该帐户销售该产品的销量、收入和利润的总和。

注意在设计事实表之前,您必须确定事实表的粒度。粒度对应于您在该事实表中定义单个最低记录的方式(一行)。粒度可能是单个事务、每日快照或每月快照。显示的事实表包含每天销售给每个帐户的每种产品的一行。因此,事实表的粒度表示为按天按帐户的产品。
3.2 数据模型的维度(维度表)
维度代表现实世界中的一组对象或事件。您为数据模型标识的每个维度都作为维度表实现。维度是使事实表的度量有意义的限定符,因为它们回答了问题的内容、时间和地点等方面。例如,考虑以下业务问题,其中红色字体就是维度
-
去年哪些账户的收入最高?
-
供应商的利润是多少?
-
每种产品售出多少件?
在前面的一组问题中,收入、利润和销售量是度量(而不是维度),因为每个都代表定量或事实数据。
关于维度模型大家还需要了解如下几个概念:
-
维度元素一个维度可以为不同的求和级别
定义多个维度元素。 -
维度属性维度属性是维度表中的一列
每个属性都描述了维度层次结构中的一个汇总级别。 -
维度表维度表是存储业务维度的文本描述的表
-
维度表包含层次结构中每个级别的元素和属性(如果适用)。
尖叫总结1:有时在设计过程中,不清楚来自生产数据源的数字数据字段是测量事实还是属性。通常,如果数值数据字段是每次采样时都会更改的测量值,则该字段是事实。如果字段是对或多或少恒定的事物的离散值描述,则它是维度属性。
4.如何构建维度数据模型
一个维度数据库(数仓)可以基于多个业务流程,并且可以包含许多事实表,这里描述的数据模型基于单个业务流程并具有一个事实表。
构建维度数据库流程(以后面试背诵这个建模流程哈)
-
选择要用于分析要建模的主题域的业务流程。
-
确定事实表的粒度。
-
确定每个事实表的维度和层次结构。
-
确定事实表的度量。
-
确定每个维度表的属性。
-
让用户验证数据模型。
今天到此结束吧,很多人听的还是云里雾里,下一篇结合实际讲解维度模型建设的流程以及结合案例落地哈;











![[附源码]JAVA毕业设计高速公路服务区管理系统(系统+LW)](https://img-blog.csdnimg.cn/9b9d1967330d450389b35f5b20c81641.png)