关注公众号,发现CV技术之美
今天向大家分享 CVPR 2022 论文『Large-scale Video Panoptic Segmentation in the Wild: A Benchmark』,介绍一个新的视频全景分割(Video Panoptic Segmentation)领域 Benchmark:VIPSeg。

论文链接:https://openaccess.thecvf.com/content/CVPR2022/papers/Miao_Large-Scale_Video_Panoptic_Segmentation_in_the_Wild_A_Benchmark_CVPR_2022_paper.pdf
项目链接:https://github.com/VIPSeg-Dataset/VIPSeg-Dataset/
01
前言
作者提出了一个新的视频全景分割(Video Panoptic Segmentation)领域 Benchmark:VIPSeg,与其他视频全景分割数据相比,VIPSeg有着数据量更多(3536个视频),场景更齐全(232个场景,124个类别)的优点。同时,作者也设计了一种基于切分短片(clip)的视频全景分割框架,在VIPSeg上达到了Sota性能。
02
VIPSeg数据集介绍
VIPSeg数据集共包含3536个视频,84750帧。并且均匀分布232个现实复杂野外场景。每个视频长度在3s~10s不等,帧间隔为 5fps。
VIPSeg与其他VPS数据集的对比如下表所示,可以明显看出VIPSeg的数据更多更丰富。

VIPSeg数据集各类别分布如下,可以看出各类别实例数量分布均匀,并没有很严重的长尾现象。
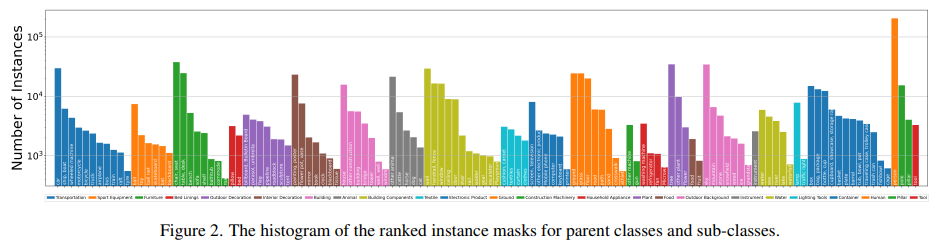
数据集中共包含124个类别,其中58个类为things(易于区分instance的,如:人,狗),66个类为stuff(不易区分instance,如:天空、草地)。

VIPSeg数据集的标注流程分为两个阶段,分别为Sparse Annotation and Tracking Loop 与 Dense Pixel-label Propagation Loop。
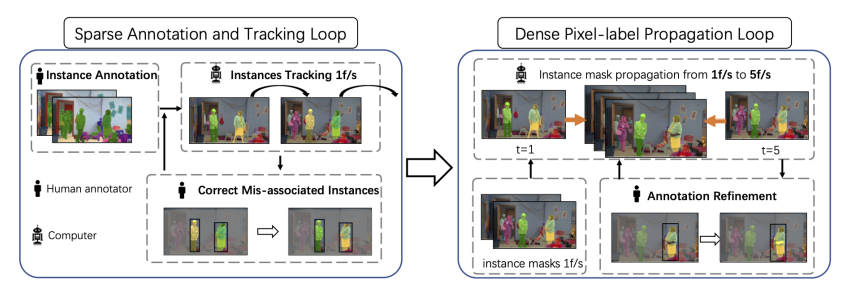
Sparse Annotation and Tracking Loop:稀疏标注阶段
在第一个阶段,作者先通过人工标注第一帧,再通过最先进的目标跟踪算法(AOT)获取 1 fps 的视频稀疏标注结果,再通过人工对此结果进行修正。
Dense Pixel-label Propagation Loop:稠密传播阶段
在第二个阶段,作者在 1 fps 的基础上 通过 AOT 对 Mask 进行传播,从而获取 5 fps 的 视频全景标注结果,再通过人工修正的方式对传播的结果进行修正。
03
基于Clip的视频全景分割方法
作者提出一个新的视频全景分割算法:ClipPanoFCN,基于对视频进行划分片段,先实现片段内的全景分割再全局规整的方法,实现了新的Sota 性能。
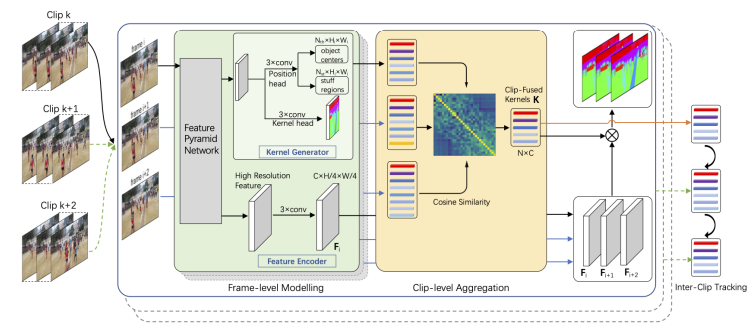
具体的,作者先将视频划分为不重叠的片段:Clip k,Clip k + 1...,再对每个片段分别进行全景分割。
Frame-level Modelling:帧级建模
在每一个Clip中,作者通过FPN对每一帧图像信息进行提取,再通过卷积层预测实例(things)的中心和非实例(stuff)的区域,以及每个像素点的类别置信度。最后通过在实例(things)中心附近选取置信度高的类别或者在非实例(stuff)区域通过求平均来获取最终的分割结果
Clip-level Aggregation:片段内整合
为了将图像级全景分割模型有效地应用于视频级,作者通过平均聚类的方法去除了多余标签,并且保证了片段内标签一致性。
Inter-clip Tracking:片段间整合
为了保持片段间标签的一致性,作者以一种类似于后处理的方法,通过计算不同片段间标签 Kernal 的相似度来聚合不同片段的结果。
基于Clip的视频全景分割方法,可以有效实现Clip内部的不同帧间信息交互,获取更好的标签特征Kernal,同时,不同Clip的视频可以并行处理,互不干扰,增加了实际应用时分割的速度。
04
实验
作者在自己提出的VIPSeg数据集上进行了验证,并与前人方法进行了比较。
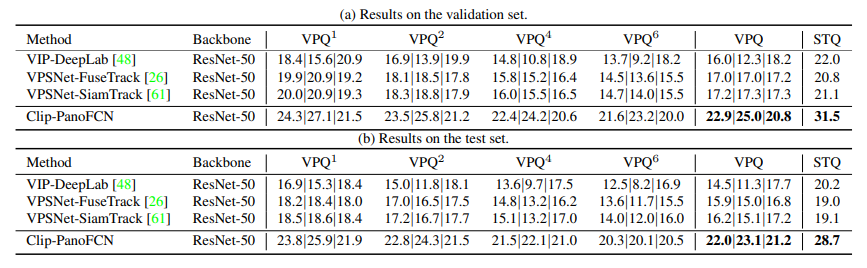
可以看出,ClipPanoFCN在两个指标(VPQ、STQ)上都取得最优性能。
05
结论
该文提出了一个新的大规模视频全景分割数据集:VIPSeg,提供了大规模的现实多场景下像素级全景标注。并且提出了一种新的基于Clip划分的视频全景分割算法,将视频分为多个片段,并行处理各片段并且整合各片段获取最终分割结果。

END
欢迎加入「全景分割」交流群👇备注:VPS





![[附源码]JAVA毕业设计高速公路服务区管理系统(系统+LW)](https://img-blog.csdnimg.cn/9b9d1967330d450389b35f5b20c81641.png)







![[附源码]Python计算机毕业设计Django的小区宠物管理系统](https://img-blog.csdnimg.cn/b98d387096d84b9593fc7eb098b83c2d.png)