【自然语言处理(NLP)】基于预训练模型的机器阅读理解

作者简介:在校大学生一枚,华为云享专家,阿里云专家博主,腾云先锋(TDP)成员,云曦智划项目总负责人,全国高等学校计算机教学与产业实践资源建设专家委员会(TIPCC)志愿者,以及编程爱好者,期待和大家一起学习,一起进步~
.
博客主页:ぃ灵彧が的学习日志
.
本文专栏:人工智能
.
专栏寄语:若你决定灿烂,山无遮,海无拦
.

文章目录
- 【自然语言处理(NLP)】基于预训练模型的机器阅读理解
- 前言
- (一)、任务描述
- (二)、安装说明
- 一、模型准备
- (一)、NLP下载
- (二)、示例流程
- 二、数据准备
- (一)、 加载PaddleNLP内置数据集
- (二)、数据处理
- (三)、调用`map()`方法批量处理数据
- (四)、Batchify和数据读入
- 三、模型结构
- (一)、使用PaddleNLP一键加载预训练模型
- (二)、设计loss function
- 四、设置Fine-Tune优化策略
- 五、模型训练与评估
- 总结
前言
(一)、任务描述
阅读理解是检索问答系统中的重要组成部分,最常见的数据集是单篇章、抽取式阅读理解数据集。
该示例展示了如何使用PaddleNLP快速实现基于预训练模型的机器阅读理解任务。
本示例使用的数据集是Dureaderrobust数据集。对于一个给定的问题q和一个篇章p,根据篇章内容,给出该问题的答案a。数据集中的每个样本,是一个三元组<q, p, a>,例如:
问题 q: 乔丹打了多少个赛季
篇章 p: 迈克尔.乔丹在NBA打了15个赛季。他在84年进入nba,期间在1993年10月6日第一次退役改打棒球,95年3月18日重新回归,在99年1月13日第二次退役,后于2001年10月31日复出,在03年最终退役…
参考答案 a: [‘15个’,‘15个赛季’]
阅读理解模型的鲁棒性是衡量该技术能否在实际应用中大规模落地的重要指标之一。随着当前技术的进步,模型虽然能够在一些阅读理解测试集上取得较好的性能,但在实际应用中,这些模型所表现出的鲁棒性仍然难以令人满意。

本示例使用的Dureaderrobust数据集作为首个关注阅读理解模型鲁棒性的中文数据集,旨在考察模型在真实应用场景中的过敏感性、过稳定性以及泛化能力等问题。
关于该数据集的详细内容,可参考数据集论文,或官方比赛链接。
(二)、安装说明
-
PaddlePaddle 安装
本项目依赖于 PaddlePaddle 2.0 及以上版本,请参考 安装指南 进行安装
-
PaddleNLP 安装
pip install --upgrade paddlenlp -i https://pypi.org/simple -
环境依赖
Python的版本要求 3.6+
一、模型准备
(一)、NLP下载
AI Studio平台后续会默认安装PaddleNLP,在此之前可使用如下命令安装
!pip install --upgrade paddlenlp -i https://pypi.org/simple
部分输出结果如下图1所示:
(二)、示例流程
与大多数NLP任务相同,本次机器阅读理解任务的示例展示分为以下四步:
首先我们从数据准备开始。
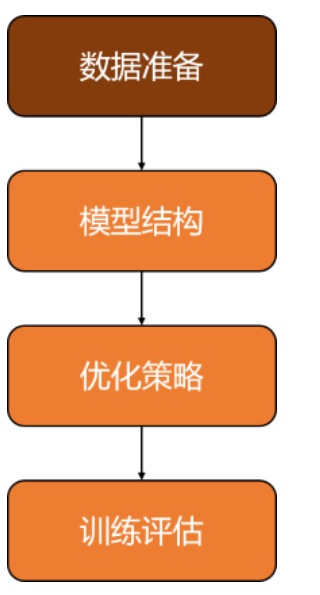
二、数据准备
数据准备流程如下:

(一)、 加载PaddleNLP内置数据集
使用PaddleNLP提供的load_datasetAPI,即可一键完成数据集加载。
from paddlenlp.datasets import load_dataset
train_ds, dev_ds = load_dataset('dureader_robust', splits=('train', 'dev'))
for idx in range(2):
print(train_ds[idx]['question'])
print(train_ds[idx]['context'])
print(train_ds[idx]['answers'])
print(train_ds[idx]['answer_starts'])
print()
输出结果如下图2所示:

(二)、数据处理
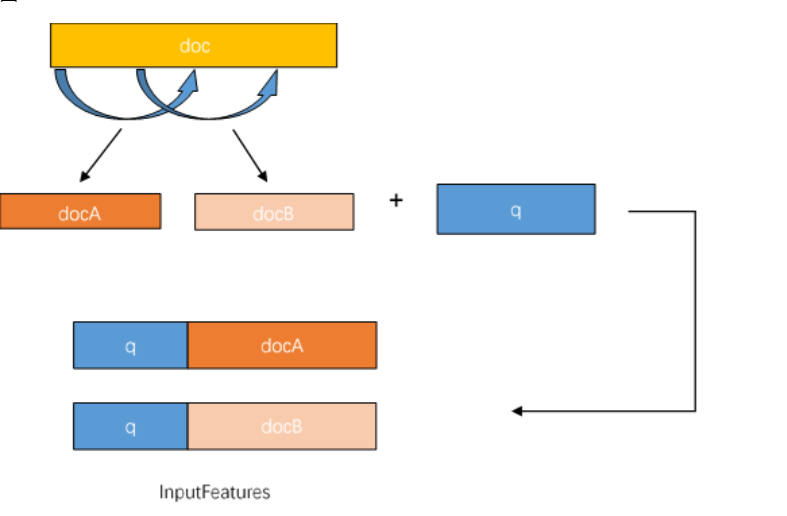
DuReaderrubust数据集采用SQuAD数据格式,InputFeature使用滑动窗口的方法生成,即一个example可能对应多个InputFeature。
由于文章加问题的文本长度可能大于max_seq_length,答案出现的位置有可能出现在文章最后,所以不能简单的对文章进行截断。
那么对于过长的文章,则采用滑动窗口将文章分成多段,分别与问题组合。再用对应的tokenizer转化为模型可接受的feature。doc_stride参数就是每次滑动的距离。滑动窗口生成InputFeature的过程如下图:
本基线中,我们使用的预训练模型是ERNIE,ERNIE对中文数据的处理是以字为单位。PaddleNLP对于各种预训练模型已经内置了相应的tokenizer,指定想要使用的模型名字即可加载对应的tokenizer。
tokenizer的作用是将原始输入文本转化成模型可以接受的输入数据形式。
import paddlenlp
# 设置模型名称
MODEL_NAME = 'ernie-1.0'
tokenizer = paddlenlp.transformers.ErnieTokenizer.from_pretrained(MODEL_NAME)
输出结果如下图3所示:
(三)、调用map()方法批量处理数据
由于我们传入了lazy=False,所以我们使用load_dataset()自定义的数据集是MapDataset对象。MapDataset是paddle.io.Dataset的功能增强版本。其内置的map()方法适合用来进行批量数据集处理。
map()方法接受的主要参数是一个用于数据处理的function。正好可以与tokenizer相配合。
以下是本基线中的用法:
from utils import prepare_train_features, prepare_validation_features
from functools import partial
max_seq_length = 512
doc_stride = 128
train_trans_func = partial(prepare_train_features,
max_seq_length=max_seq_length,
doc_stride=doc_stride,
tokenizer=tokenizer)
train_ds.map(train_trans_func, batched=True, num_workers=4)
dev_trans_func = partial(prepare_validation_features,
max_seq_length=max_seq_length,
doc_stride=doc_stride,
tokenizer=tokenizer)
dev_ds.map(dev_trans_func, batched=True, num_workers=4)
for idx in range(2):
print(train_ds[idx]['input_ids'])
print(train_ds[idx]['token_type_ids'])
print(train_ds[idx]['overflow_to_sample'])
print(train_ds[idx]['offset_mapping'])
print(train_ds[idx]['start_positions'])
print(train_ds[idx]['end_positions'])
print()
部分输出结果如下图4所示:

从以上结果可以看出,数据集中的example已经被转换成了模型可以接收的feature,包括input_ids、token_type_ids、答案的起始位置等信息。
其中:
input_ids: 表示输入文本的token ID。token_type_ids: 表示对应的token属于输入的问题还是答案。(Transformer类预训练模型支持单句以及句对输入)。overflow_to_sample: feature对应的example的编号。offset_mapping: 每个token的起始字符和结束字符在原文中对应的index(用于生成答案文本)。start_positions: 答案在这个feature中的开始位置。end_positions: 答案在这个feature中的结束位置。
数据处理的详细过程请参见utils.py。
更多有关数据处理的内容,请参考数据处理。
(四)、Batchify和数据读入
使用paddle.io.BatchSampler和paddlenlp.data中提供的方法把数据组成batch。
然后使用paddle.io.DataLoader接口多线程异步加载数据。
batchify_fn详解:
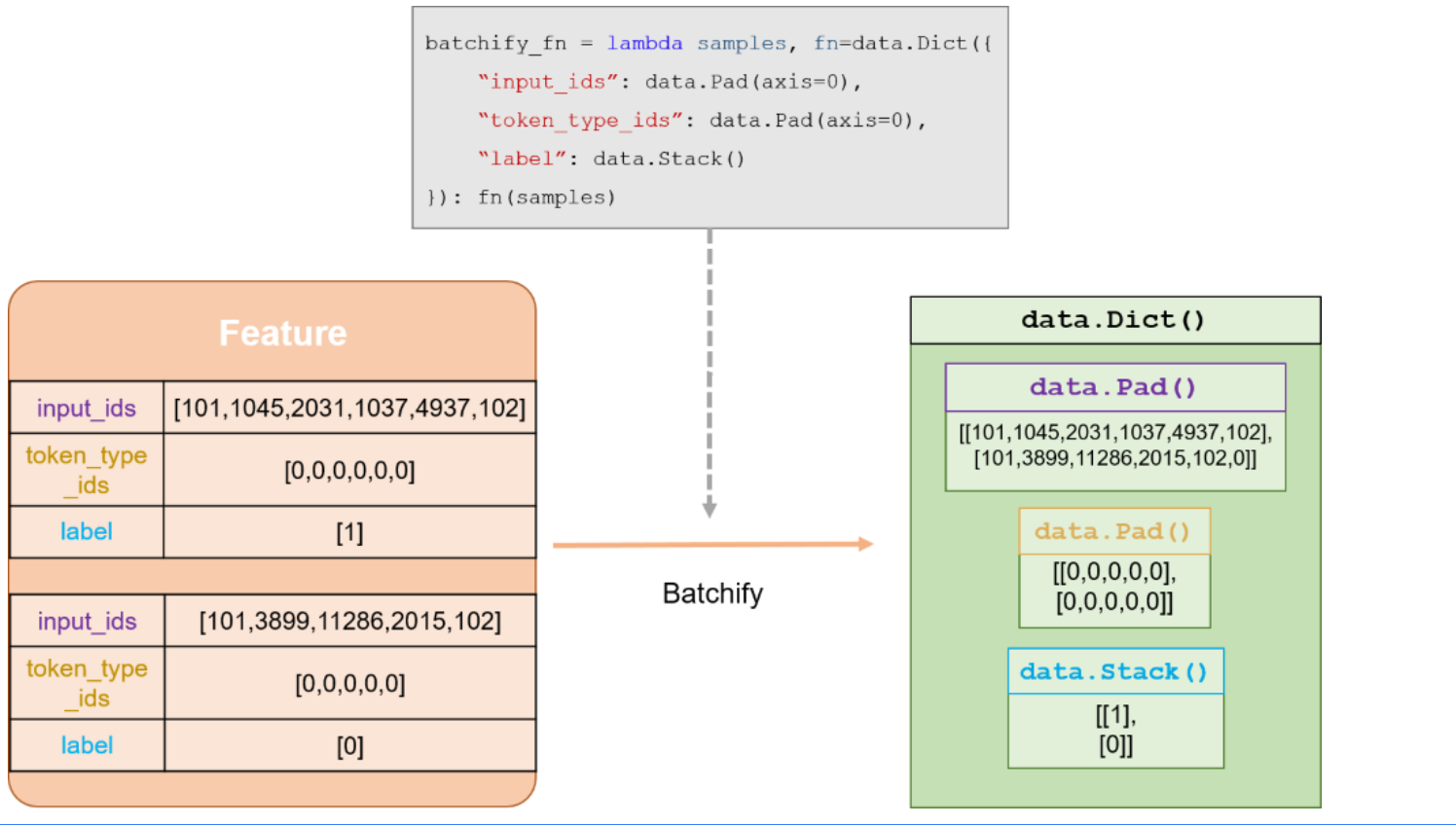
import paddle
from paddlenlp.data import Stack, Dict, Pad
batch_size = 16
# 定义BatchSampler
train_batch_sampler = paddle.io.DistributedBatchSampler(
train_ds, batch_size=batch_size, shuffle=True)
dev_batch_sampler = paddle.io.BatchSampler(
dev_ds, batch_size=batch_size, shuffle=False)
# 定义batchify_fn
train_batchify_fn = lambda samples, fn=Dict({
"input_ids": Pad(axis=0, pad_val=tokenizer.pad_token_id),
"token_type_ids": Pad(axis=0, pad_val=tokenizer.pad_token_type_id),
"start_positions": Stack(dtype="int64"),
"end_positions": Stack(dtype="int64")
}): fn(samples)
dev_batchify_fn = lambda samples, fn=Dict({
"input_ids": Pad(axis=0, pad_val=tokenizer.pad_token_id),
"token_type_ids": Pad(axis=0, pad_val=tokenizer.pad_token_type_id)
}): fn(samples)
# 构造DataLoader
train_data_loader = paddle.io.DataLoader(
dataset=train_ds,
batch_sampler=train_batch_sampler,
collate_fn=train_batchify_fn,
return_list=True)
dev_data_loader = paddle.io.DataLoader(
dataset=dev_ds,
batch_sampler=dev_batch_sampler,
collate_fn=dev_batchify_fn,
return_list=True)
到这里数据集准备就全部完成了,下一步我们需要组网并设计loss function。

三、模型结构
(一)、使用PaddleNLP一键加载预训练模型
以下项目以ERNIE为例,介绍如何将预训练模型Fine-tune完成DuReaderrobust阅读理解任务。
DuReaderrobust阅读理解任务的本质是答案抽取任务。根据输入的问题和文章,从预训练模型的sequence_output中预测答案在文章中的起始位置和结束位置。原理如下图所示:
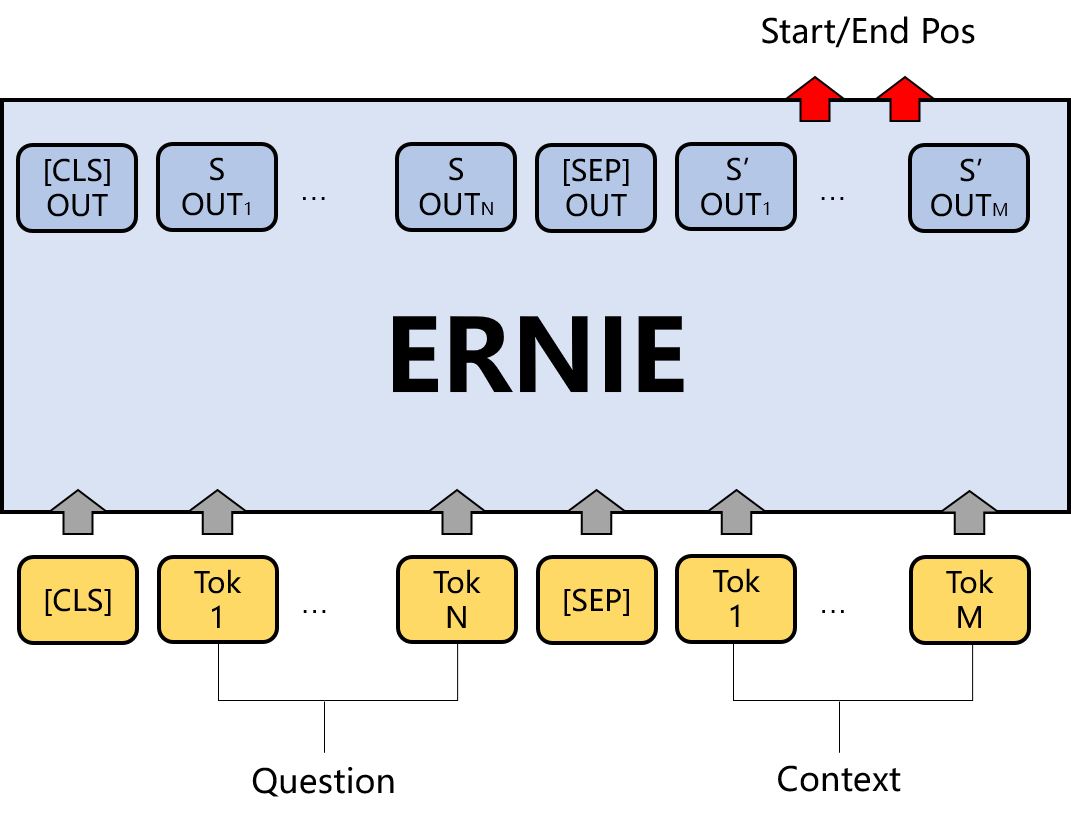
目前PaddleNLP已经内置了包括ERNIE在内的多种基于预训练模型的常用任务的下游网络,包括机器阅读理解。
这些网络在paddlenlp.transformers下,均可实现一键调用。
from paddlenlp.transformers import ErnieForQuestionAnswering
model = ErnieForQuestionAnswering.from_pretrained(MODEL_NAME)
输出结果如下图5所示:

(二)、设计loss function
模型的网络结构确定后我们就可以设计loss function了。
ErineForQuestionAnswering模型对将ErnieModel的sequence_output拆开成start_logits和end_logits输出,所以DuReaderrobust的loss由start_loss和end_loss两部分组成,我们需要自己定义loss function。
对于答案起始位置和结束位置的预测可以分别看成两个分类任务。所以设计的loss function如下:
class CrossEntropyLossForRobust(paddle.nn.Layer):
def __init__(self):
super(CrossEntropyLossForRobust, self).__init__()
def forward(self, y, label):
start_logits, end_logits = y # both shape are [batch_size, seq_len]
start_position, end_position = label
start_position = paddle.unsqueeze(start_position, axis=-1)
end_position = paddle.unsqueeze(end_position, axis=-1)
start_loss = paddle.nn.functional.softmax_with_cross_entropy(
logits=start_logits, label=start_position, soft_label=False)
start_loss = paddle.mean(start_loss)
end_loss = paddle.nn.functional.softmax_with_cross_entropy(
logits=end_logits, label=end_position, soft_label=False)
end_loss = paddle.mean(end_loss)
loss = (start_loss + end_loss) / 2
return loss
四、设置Fine-Tune优化策略
适用于ERNIE/BERT这类Transformer模型的学习率为warmup的动态学习率。
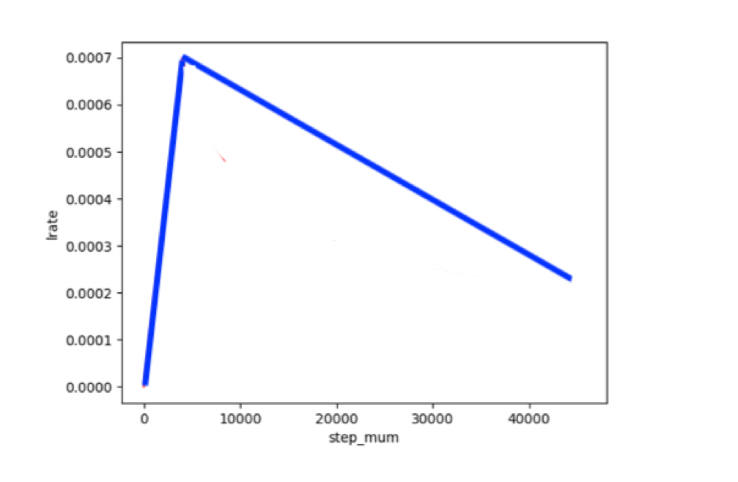
# 训练过程中的最大学习率
learning_rate = 3e-5
# 训练轮次
epochs = 1
# 学习率预热比例
warmup_proportion = 0.1
# 权重衰减系数,类似模型正则项策略,避免模型过拟合
weight_decay = 0.01
num_training_steps = len(train_data_loader) * epochs
# 学习率衰减策略
lr_scheduler = paddlenlp.transformers.LinearDecayWithWarmup(learning_rate, num_training_steps, warmup_proportion)
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in decay_params)
五、模型训练与评估
模型训练的过程通常有以下步骤:
- 从dataloader中取出一个batch data。
- 将batch data喂给model,做前向计算。
- 将前向计算结果传给损失函数,计算loss。
- loss反向回传,更新梯度。重复以上步骤。
每训练一个epoch时,程序通过evaluate()调用paddlenlp.metric.squad中的squad_evaluate(), compute_predictions()评估当前模型训练的效果,其中:
-
compute_predictions()用于生成可提交的答案;
-
squad_evaluate()用于返回评价指标。
二者适用于所有符合squad数据格式的答案抽取任务。这类任务使用F1和exact来评估预测的答案和真实答案的相似程度。
from utils import evaluate
criterion = CrossEntropyLossForRobust()
global_step = 0
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
global_step += 1
input_ids, segment_ids, start_positions, end_positions = batch
logits = model(input_ids=input_ids, token_type_ids=segment_ids)
loss = criterion(logits, (start_positions, end_positions))
if global_step % 100 == 0 :
print("global step %d, epoch: %d, batch: %d, loss: %.5f" % (global_step, epoch, step, loss))
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
evaluate(model=model, data_loader=dev_data_loader)
# 如果需要生成这个比赛(https://aistudio.baidu.com/aistudio/competition/detail/49?castk=LTE=)指定格式的结果,传入test_data_loader并设置do_pred=True即可
部分输出结果如下图6所示:

总结
本系列文章内容为根据清华社出版的《自然语言处理实践》所作的相关笔记和感悟,其中代码均为基于百度飞桨开发,若有任何侵权和不妥之处,请私信于我,定积极配合处理,看到必回!!!
最后,引用本次活动的一句话,来作为文章的结语~( ̄▽ ̄~)~:
【学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。】
ps:更多精彩内容还请进入本文专栏:人工智能,进行查看,欢迎大家支持与指教啊~( ̄▽ ̄~)~








![[附源码]JAVA毕业设计高速公路服务区管理系统(系统+LW)](https://img-blog.csdnimg.cn/9b9d1967330d450389b35f5b20c81641.png)