go version 1.19.7
在 Go 语言中,sync.WaitGroup 是一个并发编程的同步工具,用于等待一组 Goroutine 执行完毕。
当需要等待多个 Goroutine 完成任务后才能执行下一步操作时,我们可以使用 sync.WaitGroup 实现协程间的同步。它提供了 Add()、Done() 和 Wait() 三个方法,分别用于计数、计数减一和等待协程执行完毕。
具体来说:
Add(delta int) 方法可以用于增加 WaitGroup 的计数器。每次调用 Add(),计数器就会增加 delta。如果
delta 为负数,则会减少计数器。如果计数器变为0,则表示所有协程执行完毕。Done() 方法用于减少 WaitGroup 的计数器,相当于 Add(-1),表示一个协程已经执行完毕。
Wait() 方法用于等待所有协程执行完毕。它会阻塞调用它的协程,直到所有协程执行完毕并调用 Done() 方法,或者等待超时。
WaitGroup 的使用示例如下:
var wg sync.WaitGroup
func main() {
wg.Add(2) // 增加计数器
go func() {
// 协程1 执行任务
wg.Done() // 完成任务,减少计数器
}()
go func() {
// 协程2 执行任务
wg.Done() // 完成任务,减少计数器
}()
wg.Wait() // 等待所有协程执行完毕
}
TIP
信号量
一个信号量(semaphore)S是一个整型变量,它除了初始化外只能通过两个标准的原子操作:wait() 和 signal() 来访问
当信号量>0 时,表示资源可用,则 wait 会对信号量执行减 1 操作。
当信号量<=0 时,表示资源暂时不可用,获取信号量时,当前的进程/线程会阻塞,直到信号量为正时被唤醒。
定义wait()
wait(S) {
while (S <= 0)
; // 忙等待
S--;
}
定义signal()
signal(S) {
S++;
}
结构
type WaitGroup struct {
// 告诉编辑器 waitgroup 对象不可复制, (sync.pool 也有这个)
noCopy noCopy
// 高32位是计数器(counters) 低32位是等待者数量(waiters)
// 这边计数器 其实是Add(int) 的数量的总和, 例如 Add(1) 后 再Add(1) 计数器的就是1 +1 =2
// 等待数量就是现在有多少goroutine 在执行wait() 等待被释放
state1 uint64
// 这个是信号量
// runtime_Semrelease 表示将信号量递增(对应信号量中的 signal 操作)
// runtime_Semacquire 表示将信号量递减(对应信号量中的 wait 操作)
state2 uint32
}
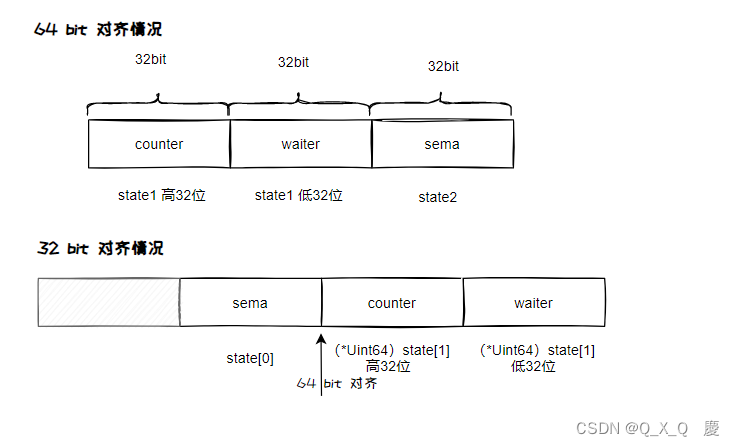
这边 state1 和state2 都是64位, 如果是32位的 需要重新处理获取这俩个值, 如下
func (wg *WaitGroup) state() (statep *uint64, semap *uint32) {
// &wg.state1获取wg.state1变量的地址;
// unsafe.Pointer(&wg.state1)将变量的地址转换为指针类型unsafe.Pointer;
// uintptr(unsafe.Pointer(&wg.state1))将指针类型unsafe.Pointer转换为uintptr类型,即将指针类型转换为无符号整数类型,以便进行位运算;
//%8对uintptr类型的地址值进行取模运算,判断地址是否是8的倍数。
// 即判断wg.state1 变量的地址 是否对齐了8字节边界, 对齐了说明是64位的编译器
if unsafe.Alignof(wg.state1) == 8 || uintptr(unsafe.Pointer(&wg.state1))%8 == 0 {
// 64位系统 原样返回即可
return &wg.state1, &wg.state2
} else {
// 32位系统需要重新获取 counter、waiter、sema
// &wg.state1获取wg.state1变量的地址;
// unsafe.Pointer(&wg.state1)将变量的地址转换为指针类型unsafe.Pointer;
// (*[3]uint32)将指针类型unsafe.Pointer转换为指向一个包含3个uint32类型的数组指针类型*[3]uint32。这里使用(*[3]uint32)是因为我们需要处理的是一个长度为3的数组,而不是单独的uint32值;
// 即 &wg.state1的地址被转换为类型为*[3]uint32的指针。
state := (*[3]uint32)(unsafe.Pointer(&wg.state1))
// 然后 截一下, 数组里第一个是信号量,
// 第二第三个 是counter 和 waiter ,把俩个 uint32 转成一个Uint64
return (*uint64)(unsafe.Pointer(&state[1])), &state[0]
}
}
TIP 内存对齐, 不深入
64位对齐是指将数据结构中的成员按照64位对齐方式进行排列的过程。在64位体系结构中,CPU访问内存的最小单位为8字节(64位),也就是说,如果访问的数据不是8字节的整数倍,那么CPU需要进行多次访问才能读取或写入完整的数据,这会导致额外的CPU开销和内存访问延迟。因此,在设计数据结构时,为了避免CPU访问内存的额外开销,需要对数据结构进行64位对齐。
具体来说,64位对齐的原则是,结构体中的每个成员的偏移量必须是8的倍数。如果成员的大小不是8的倍数,那么需要在成员之间填充空白,使得下一个成员的偏移量是8的倍数。
Add
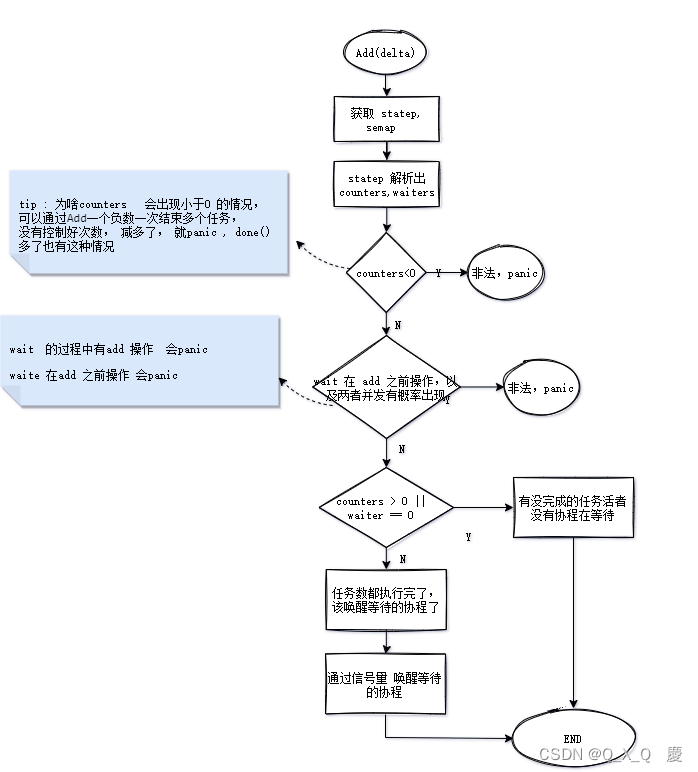
func (wg *WaitGroup) Add(delta int) {
// statep 高32位是计数器(counters) 低32位是等待者数量(waiters)
// semap 是信号量
// 获取 counters/waiters , 信号量
statep, semap := wg.state()
// 判断当前程序是否开启了竞态条件检查, 默认是false , 不深入, 后面相关代码忽略不显示
if race.Enabled {
_ = *statep
if delta < 0 {
race.ReleaseMerge(unsafe.Pointer(wg))
}
race.Disable()
defer race.Enable()
}
// 将int 的delta 变成 Uint64 再左移32位, 与statep 进行累加
// 相当于把 delta 与 state 的高32位计数器 值进行相加
state := atomic.AddUint64(statep, uint64(delta)<<32)
// 高32位, 计数器的值
v := int32(state >> 32)
// 低32位, 等待者的值
w := uint32(state)
// 计数器小于0 , panic
if v < 0 {
panic("sync: negative WaitGroup counter")
}
// 当 Wait 和 Add 并发执行时,会有概率触发下面的 panic
// 还有一种, wait 在add 在之前操作的时候, 也会触发panic
// 需要注意, 不要在被调用的goroutine内部调用Add , 应该在外面调用
if w != 0 && delta > 0 && v == int32(delta) {
panic("sync: WaitGroup misuse: Add called concurrently with Wait")
}
// v > 0: 说明还有待完成的任务数,此时不应该唤醒等待协程
// w = 0: 说明没有协程在等待
// 此时可以直接退出
if v > 0 || w == 0 {
return
}
// 存在等待的协程时,goroutine 已将计数器设置为0。
// 现在不可能同时出现状态突变:
// - Add 不能与 Wait 同时发生,
// - 如果看到计数器==0,则 Wait 不会增加等待的协程。
// 仍然要做一个廉价的健康检查,以检测 WaitGroup 的误用。
if *statep != state {
panic("sync: WaitGroup misuse: Add called concurrently with Wait")
}
// 此时v = 0 所有任务都完成了
// 将statep 置成0, 将 waiters 设成0
*statep = 0
// 唤醒等待者
// 可能有一堆等待者, (一堆协程等一个协程干完活, 一堆协程等一堆协程干完活)
for ; w != 0; w-- {
// signal,调用 Wait 的地方会解除阻塞
// semrelease 原子增加 semap 的值, 并通知阻塞在semacquire中正在等待的goroutine
// 第二、第三个参数 不深入
runtime_Semrelease(semap, false, 0)
}
}
Done
// 其实只是对 Add 的调用,但是它的效果是,将计数器的值减去 1 , 一个等待的协程 执行完成了
func (wg *WaitGroup) Done() {
wg.Add(-1)
}
Wait
// 注意点
// 1、 wait 只能在主流程中才能阻塞
// 2、 wait 过程中 不能add 会panic
func (wg *WaitGroup) Wait() {
// 获取计数器和信号量
statep, semap := wg.state()
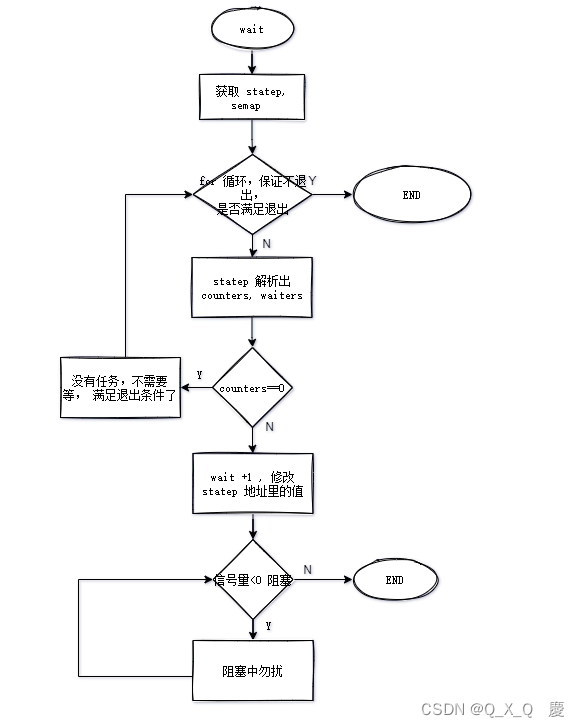
// 这边 我思考了一下, Q1 : 为啥不把 获取计数器和信号量放进循环里面
// 看注意点2, wait 过程中 不允许add , 这样每次都一样(注意这边的一样是指地址一样, 为什么强调地址, 看下面 Q2)不用重复获取了
for {
// 又卡了, Q2 :既然都一样了, 为啥 counter,waiter 需要重新解析啊
// add 操作会控制 信号量变化
// wait 操作会控制state 变化
// atomic.LoadUint64(statep) 原子加载, 保证statep已经写完了
// 那 statep 哪边写呢, 在后面
// atomic.CompareAndSwapUint64(statep, state, state+1) , 对state 进行自增加操作
// 看下 参数 func CompareAndSwapUint64(addr *uint64, old, new uint64) (swapped bool)
// 在这个地址上(statep) 把旧值(state)改成新值(state+1)
// 地址statep 没变, 存的值变了, 那这边肯定要重新解析, cool
state := atomic.LoadUint64(statep)
v := int32(state >> 32)
w := uint32(state)
// 计数器是0 了, 不需要等待, 返回
if v == 0 {
return
}
// 这边 上面Q2 的时候一起分析了
// state + 1 , 其实是对waiters 加1 (加了低32位上), 等待者加1
if atomic.CompareAndSwapUint64(statep, state, state+1) {
// 这会阻塞,直到 sema (信号量)大于 0
runtime_Semacquire(semap)
// 防止并发
if *statep != 0 {
panic("sync: WaitGroup is reused before previous Wait has returned")
}
// 解除阻塞状态
return
}
}
}
可继续深入学习的点
1、信号量
2、内存对齐
3、原子操作









![[Linux] Linux文件系统](https://img-blog.csdnimg.cn/7717723dda23463fac4bd0cd259a0cca.png)