目录
一、匹配 Unicode 字符
1. 匹配 emoji 符号
(1)确定 emoji 符号的 Unicode 范围
(2)emoji 符号的存储
(3)正则表达式匹配
2. 匹配中文
(1)确定中文的 Unicode 范围
(2)正则表达式匹配
3. 中文转拼音
(1)创建自定义函数
(2)测试
(3)regexp_replace 中执行函数
4. 单词首字母大写其他小写
(1)创建自定义函数
(2)测试
(3)受限的转换
二、用八进制数匹配字符
三、匹配 Unicode 字符属性
1. Unicode Property
(1)匹配所有标点
(2)匹配所有空白符
(3)匹配所有非标点字符
2. Unicode Block
(1)匹配CJK(中文、日文、韩文)字符
(2)匹配CJK(中文、日文、韩文)标点
3. Unicode Script
四、匹配控制字符
有时我们需要匹配 ASCII 范围之外的字符。现在已经有了可以表示超过10万个字符的Unicode 标准(http://www.unicode.org)。然而,Unicode 也没有完全舍弃 ASCII,它将 ASCII 加入了它的基本拉丁(Basic Latin)码表中(参见http://www.unicode.org/charts/PDF/U0000.pdf)。第一个示例文本是法国哲学家伏尔泰(1694—1778)的一段话。Qu'est-ce que la tolérance? c'est l'apanage de l'humanité. Nous sommes tous pétris de faiblesses et d'erreurs; pardonnons-nous réciproquement nos sottises, c'est la première loi de la nature.
一、匹配 Unicode 字符
在 https://www.dute.org/regex 中用正则表达式 \u00e9 匹配文本的结果如下图所示。

\u 之后紧跟十六进制值 00e9(这里不区分大小写,即00E9也可以)。00e9对应十进制值233,在 ASCII 范围(0~127)之外。注意在图中字母 é(小写e加上一个重音符)被标亮了。这是因为在 Unicode 中 é 就是代码点 U+00E9,所以就被 \u00e9 匹配。
在MySQL中匹配的结果如下:
mysql> set @s:='Qu\'est-ce que la tolérance? c\'est l''apanage de l\'humanité. Nous sommes tous pétris de faiblesses et d\'erreurs; pardonnons-nous réciproquement nos sottises, c\'est la première loi de la nature.';
Query OK, 0 rows affected (0.00 sec)
mysql> select regexp_replace(@s,'([^\\u00e9])','');
+--------------------------------------+
| regexp_replace(@s,'([^\\u00e9])','') |
+--------------------------------------+
| éééé |
+--------------------------------------+
1 row in set (0.00 sec)下面是一段日本诗人松尾芭蕉(Matsuo Basho,他恰巧是在伏尔泰出生的前一周去世的)的俳句。
古池
蛙飛び込む
水の音
—芭蕉 (1644-1694)用正则表达式 \u6c60 匹配,这是“池”字所对应的日文字符的代码点。该字会被标亮,如下图所示。

在MySQL中可以查询任意Unicode字符的代码点。
mysql> select hex(convert('é' using ucs2)),hex(convert('池' using ucs2));
+-------------------------------+--------------------------------+
| hex(convert('é' using ucs2)) | hex(convert('池' using ucs2)) |
+-------------------------------+--------------------------------+
| 00E9 | 6C60 |
+-------------------------------+--------------------------------+
1 row in set (0.00 sec)UCS2(Universal Multiple-Octet Coded Character Set)是一种使用两个字节(16位)表示 Unicode 字符集的编码方式,它能够表示 Unicode 字符集中的所有字符。
也可以从 Unicode 代码点反查字符:
mysql> select convert(unhex('00E9') using ucs2), convert(unhex('6C60') using ucs2);
+-----------------------------------+-----------------------------------+
| convert(unhex('00E9') using ucs2) | convert(unhex('6C60') using ucs2) |
+-----------------------------------+-----------------------------------+
| é | 池 |
+-----------------------------------+-----------------------------------+
1 row in set (0.00 sec)1. 匹配 emoji 符号
需求是在 MySQL 表中查询出所有包含 emoji 符号的数据。
(1)确定 emoji 符号的 Unicode 范围
首先要做的是确定 emoji 符号的 Unicode 范围。https://unicode.org/emoji/charts/full-emoji-list.html 页面中的 code 列给出了最新版本的所有 emoji 符号的 Unicode 编码。
(2)emoji 符号的存储
emoji 符号以 UTF-16 方式实现储存。以 Unicode 1F43B 为例,存储的代码点为\ud83d\udc3b。计算过程如下:
- 将0x1F43B去掉高位得到 0xf43b
- 转换成二进制是 0000 1111 0100 0011 1011
- 根据前十位和后十位,分割成上十位:0000 1111 01 = 0x3d 下十位:00 0011 1011 = 0x3b
- 高位加上 0xd800 得到 0xd83d
- 低位加上0xdc00得到0xdc3b
这样就得到了高低位。MySQL 实现如下:
mysql> set @c:='f43b';
Query OK, 0 rows affected (0.00 sec)
mysql> select conv(conv('800',16,10) + conv(h,16,10),10,16) h,
-> conv(conv('c00',16,10) + conv(l,16,10),10,16) l
-> from
-> (
-> select conv(substr(concat('0000',conv(@c,16,2)),1,10),2,16) h,
-> conv(substr(concat('0000',conv(@c,16,2)),11,20),2,16) l) t;
+------+------+
| h | l |
+------+------+
| 83D | C3B |
+------+------+
1 row in set (0.00 sec)emoji在字符串里面的存储,参考 https://zhuanlan.zhihu.com/p/105805517。
(3)正则表达式匹配
通过对 Unicode 范围的计算,emoji 对应的编码区间用正则表达表示为:
\u00a9|\u00ae|[\u2000-\u3300]|[\ud83c-\ud83e][\ud000-\udfff]因此可以通过类似下面的查询找出所有包含emoji符号的数据:
select userid,nickname
from space.space_user
where regexp_like(nickname,'(\\u00a9|\\u00ae|[\\u2000-\\u3300]|[\\ud83c-\\ud83e][\\ud000-\\udfff])')
limit 10;注意这个正则表达式不是严格匹配,其区间范围是 emoji 符号编码范围的超集,也就是说除覆盖现有全部 emoji 符号还存在空的代码点。该正则表达式可以满足目前 emoji 符号不断扩充的需求。
2. 匹配中文
需求是在MySQL表中查询出所有包含中文(包括标点符号)的数据。
(1)确定中文的 Unicode 范围
与 emoji 类似,对于中文匹配也要先确定其 Unicode 范围。参见 http://www.hlc8.com/a.php?id=46c988af5d6c11e180bd752c7be30365。在绝大多数应用场合中,可以仅下面的集合作为 CJK 判断的依据。
- 基本汉字20902字:4E00-9FA5
- 基本汉字补充90字:9FA6-9FFF
- 扩展A 6592字:3400-4DBF
- 全角ASCII、中英文标点:FF00-FFEF
- CJK部首补充:2E80-2EFF
- CJK标点符号:3000-303F
- CJK笔划:31C0-31EF
(2)正则表达式匹配
中文对应的编码区间用正则表达表示为:
[\u4E00-\u9FA5]|[\u9FA6-\u9FFF]|[\u3400-\u4DBF]|[\uFF00-\uFFEF]|[\u2E80-\u2EFF]|[\u3000-\u303F]|[\u31C0-\u31EF]因此可以通过类似下面的查询找出所有包含中文的数据:
select userid,nickname
from space.space_user
where regexp_like(nickname,'([\\u4E00-\\u9FA5]|[\\u9FA6-\\u9FFF]|[\\u3400-\\u4DBF]|[\\uFF00-\\uFFEF]|[\\u2E80-\\u2EFF]|[\\u3000-\\u303F]|[\\u31C0-\\u31EF])')
limit 10;注意这个正则表达式不是严格匹配,其区间范围是中文编码范围的超集,也存在空代码点。正则表达式是从左向右进行匹配的,大多数情况下,最左边两万汉字已可以完成匹配比较。
3. 中文转拼音
这里的实现与正则表达式无关。在后面会说明为什么加此一节。
需求是将字符串中的汉字转为拼音。创建一个汉字转拼音的函数,在其中判断每个字符是否为中文,如果是则查询拼音表取得对应的拼音,否则原样返回。网上的大部分 MySQL 转拼音函数都是通过创建一个拼音对照表,然后在自定义函数中查询该表实现的。以下对这种实现做了修改,具有以下特点:
- 不需要拼音表。
- 与数据库字符集无关。
- 根据参数可分别返回全拼小写、全拼大写、全拼首字母大写。
- 不考虑多音字拼音上下文语义的正确性。
- 通过嵌套使用 MySQL 的 elt、interval 函数确定一个汉字对应的唯一拼音。
(1)创建自定义函数
drop function if exists to_pinyin;
delimiter //
create function to_pinyin(name varchar(255) charset gbk, flag int) returns varchar(255) charset gbk
begin
declare mycode int;
declare tmp_lcode varchar(2) charset gbk;
declare lcode int;
declare tmp_rcode varchar(2) charset gbk;
declare rcode int;
declare l_pin_yin_ varchar(6);
declare mypy varchar(255) charset gbk default '';
declare lp int;
set mycode = 0;
set lp = 1;
set name = hex(name);
while lp < length(name) do
set tmp_lcode = substring(name, lp, 2);
set lcode = cast(ascii(unhex(tmp_lcode)) as unsigned);
set tmp_rcode = substring(name, lp + 2, 2);
set rcode = cast(ascii(unhex(tmp_rcode)) as unsigned);
if lcode > 128 then
set mycode =abs(65536 - lcode * 256 - rcode);
-- 取对应的拼音
set l_pin_yin_ = elt(interval(0-mycode,
-20319,-20317,-20304,-20295,-20292,-20283,-20265,-20257,-20242,-20230,-20051,-20036,
-20032,-20026,-20002,-19990,-19986,-19982,-19976,-19805,-19784,-19775,-19774,-19763,
-19756,-19751,-19746,-19741,-19739,-19728,-19725,-19715,-19540,-19531,-19525,-19515,
-19500,-19484,-19479,-19467,-19289,-19288,-19281,-19275,-19270,-19263,-19261,-19249,
-19243,-19242,-19238,-19235,-19227,-19224,-19218,-19212,-19038,-19023,-19018,-19006,
-19003,-18996,-18977,-18961,-18952,-18783,-18774,-18773,-18763,-18756,-18741,-18735,
-18731,-18722,-18710,-18697,-18696,-18526,-18518,-18501,-18490,-18478,-18463,-18448,
-18447,-18446,-18239,-18237,-18231,-18220,-18211,-18201,-18184,-18183,-18181,-18012,
-17997,-17988,-17970,-17964,-17961,-17950,-17947,-17931,-17928,-17922,-17759,-17752,
-17733,-17730,-17721,-17703,-17701,-17697,-17692,-17683,-17676,-17496,-17487,-17482,
-17468,-17454,-17433,-17427,-17417,-17202,-17185,-16983,-16970,-16942,-16915,-16733,
-16708,-16706,-16689,-16664,-16657,-16647,-16474,-16470,-16465,-16459,-16452,-16448,
-16433,-16429,-16427,-16423,-16419,-16412,-16407,-16403,-16401,-16393,-16220,-16216,
-16212,-16205,-16202,-16187,-16180,-16171,-16169,-16158,-16155,-15959,-15958,-15944,
-15933,-15920,-15915,-15903,-15889,-15878,-15707,-15701,-15681,-15667,-15661,-15659,
-15652,-15640,-15631,-15625,-15454,-15448,-15436,-15435,-15419,-15416,-15408,-15394,
-15385,-15377,-15375,-15369,-15363,-15362,-15183,-15180,-15165,-15158,-15153,-15150,
-15149,-15144,-15143,-15141,-15140,-15139,-15128,-15121,-15119,-15117,-15110,-15109,
-14941,-14937,-14933,-14930,-14929,-14928,-14926,-14922,-14921,-14914,-14908,-14902,
-14894,-14889,-14882,-14873,-14871,-14857,-14678,-14674,-14670,-14668,-14663,-14654,
-14645,-14630,-14594,-14429,-14407,-14399,-14384,-14379,-14368,-14355,-14353,-14345,
-14170,-14159,-14151,-14149,-14145,-14140,-14137,-14135,-14125,-14123,-14122,-14112,
-14109,-14099,-14097,-14094,-14092,-14090,-14087,-14083,-13917,-13914,-13910,-13907,
-13906,-13905,-13896,-13894,-13878,-13870,-13859,-13847,-13831,-13658,-13611,-13601,
-13406,-13404,-13400,-13398,-13395,-13391,-13387,-13383,-13367,-13359,-13356,-13343,
-13340,-13329,-13326,-13318,-13147,-13138,-13120,-13107,-13096,-13095,-13091,-13076,
-13068,-13063,-13060,-12888,-12875,-12871,-12860,-12858,-12852,-12849,-12838,-12831,
-12829,-12812,-12802,-12607,-12597,-12594,-12585,-12556,-12359,-12346,-12320,-12300,
-12120,-12099,-12089,-12074,-12067,-12058,-12039,-11867,-11861,-11847,-11831,-11798,
-11781,-11604,-11589,-11536,-11358,-11340,-11339,-11324,-11303,-11097,-11077,-11067,
-11055,-11052,-11045,-11041,-11038,-11024,-11020,-11019,-11018,-11014,-10838,-10832,
-10815,-10800,-10790,-10780,-10764,-10587,-10544,-10533,-10519,-10331,-10329,-10328,
-10322,-10315,-10309,-10307,-10296,-10281,-10274,-10270,-10262,-10260,-10256,-10254),
'a','ai','an','ang','ao','ba','bai','ban','bang','bao','bei','ben',
'beng','bi','bian','biao','bie','bin','bing','bo','bu','ca','cai','can',
'cang','cao','ce','ceng','cha','chai','chan','chang','chao','che','chen','cheng',
'chi','chong','chou','chu','chuai','chuan','chuang','chui','chun','chuo','ci','cong',
'cou','cu','cuan','cui','cun','cuo','da','dai','dan','dang','dao','de',
'deng','di','dian','diao','die','ding','diu','dong','dou','du','duan','dui',
'dun','duo','e','en','er','fa','fan','fang','fei','fen','feng','fo',
'fou','fu','ga','gai','gan','gang','gao','ge','gei','gen','geng','gong',
'gou','gu','gua','guai','guan','guang','gui','gun','guo','ha','hai','han',
'hang','hao','he','hei','hen','heng','hong','hou','hu','hua','huai','huan',
'huang','hui','hun','huo','ji','jia','jian','jiang','jiao','jie','jin','jing',
'jiong','jiu','ju','juan','jue','jun','ka','kai','kan','kang','kao','ke',
'ken','keng','kong','kou','ku','kua','kuai','kuan','kuang','kui','kun','kuo',
'la','lai','lan','lang','lao','le','lei','leng','li','lia','lian','liang',
'liao','lie','lin','ling','liu','long','lou','lu','lv','luan','lue','lun',
'luo','ma','mai','man','mang','mao','me','mei','men','meng','mi','mian',
'miao','mie','min','ming','miu','mo','mou','mu','na','nai','nan','nang',
'nao','ne','nei','nen','neng','ni','nian','niang','niao','nie','nin','ning',
'niu','nong','nu','nv','nuan','nue','nuo','o','ou','pa','pai','pan',
'pang','pao','pei','pen','peng','pi','pian','piao','pie','pin','ping','po',
'pu','qi','qia','qian','qiang','qiao','qie','qin','qing','qiong','qiu','qu',
'quan','que','qun','ran','rang','rao','re','ren','reng','ri','rong','rou',
'ru','ruan','rui','run','ruo','sa','sai','san','sang','sao','se','sen',
'seng','sha','shai','shan','shang','shao','she','shen','sheng','shi','shou','shu',
'shua','shuai','shuan','shuang','shui','shun','shuo','si','song','sou','su','suan',
'sui','sun','suo','ta','tai','tan','tang','tao','te','teng','ti','tian',
'tiao','tie','ting','tong','tou','tu','tuan','tui','tun','tuo','wa','wai',
'wan','wang','wei','wen','weng','wo','wu','xi','xia','xian','xiang','xiao',
'xie','xin','xing','xiong','xiu','xu','xuan','xue','xun','ya','yan','yang',
'yao','ye','yi','yin','ying','yo','yong','you','yu','yuan','yue','yun',
'za','zai','zan','zang','zao','ze','zei','zen','zeng','zha','zhai','zhan',
'zhang','zhao','zhe','zhen','zheng','zhi','zhong','zhou','zhu','zhua','zhuai','zhuan',
'zhuang','zhui','zhun','zhuo','zi','zong','zou','zu','zuan','zui','zun','zuo');
if l_pin_yin_ is null then -- 非汉字取原字符
set mypy = concat(mypy,convert(unhex(substring(name, lp, 4)) using gbk));
else -- 汉字取拼音
set l_pin_yin_ = case flag
when 1 then lower(l_pin_yin_)
when 2 then upper(l_pin_yin_)
when 3 then concat(upper(substr(l_pin_yin_,1,1)),lower(substr(l_pin_yin_,2)))
else lower(l_pin_yin_)
end;
set mypy = concat(mypy,l_pin_yin_);
end if;
set lp = lp + 4;
else -- ASCII字符
set mypy = concat(mypy,char(cast(ascii(unhex(substring(name, lp, 2))) as unsigned)));
set lp = lp + 2;
end if;
end while;
return mypy;
end;
//
delimiter ;(2)测试
mysql> set @s:='123 中a 华b人 c 民 d共和国 Good!';
Query OK, 0 rows affected (0.00 sec)
mysql> select to_pinyin(@s,1);
+---------------------------------------------+
| to_pinyin(@s,1) |
+---------------------------------------------+
| 123 zhonga huabren c min dgongheguo Good! |
+---------------------------------------------+
1 row in set (0.00 sec)
mysql> select to_pinyin(@s,2);
+---------------------------------------------+
| to_pinyin(@s,2) |
+---------------------------------------------+
| 123 ZHONGa HUAbREN c MIN dGONGHEGUO Good! |
+---------------------------------------------+
1 row in set (0.00 sec)
mysql> select to_pinyin(@s,3);
+---------------------------------------------+
| to_pinyin(@s,3) |
+---------------------------------------------+
| 123 Zhonga HuabRen c Min dGongHeGuo Good! |
+---------------------------------------------+
1 row in set (0.00 sec)
mysql> select to_pinyin(@s,4);
+---------------------------------------------+
| to_pinyin(@s,4) |
+---------------------------------------------+
| 123 zhonga huabren c min dgongheguo Good! |
+---------------------------------------------+
1 row in set (0.00 sec)(3)regexp_replace 中执行函数
列举这个函数的原因是,我原本打算用 regexp_replace 函数,在第三个参数中引用捕获分组的方式一次性完成替换逻辑,但未能如愿,因为函数是在正则表达式匹配之前执行(后面会看到有例外)。如下所示,upper 函数先于正则表达式执行,将参数中的常量字符变成大写,然后捕获组 $1 才会原样输出。
mysql> select regexp_replace('abc','(abc)',upper('$1z d e f'));
+--------------------------------------------------+
| regexp_replace('abc','(abc)',upper('$1z d e f')) |
+--------------------------------------------------+
| abcZ D E F |
+--------------------------------------------------+
1 row in set (0.00 sec)4. 单词首字母大写其他小写
可以用 \w+ 匹配英语单词,然后用在循环用 regexp_substr 依次取单词,并将单词首字母转大写,单词其他字母转小写,非单词字符原样返回。
(1)创建自定义函数
drop function if exists initcap;
delimiter //
create function initcap(x text) returns text charset utf8mb4
reads sql data
deterministic
begin
set @str='';
set @r='\\w+';
set @ret='';
set @loc=0;
set @len=0;
while x regexp @r do
-- 单词
set @str=regexp_substr(x,@r);
-- 单词首位置
set @loc=locate(@str, x);
-- 单词长度,取长度前先进行字符集转换是为了适配 8.0.17 版本前的 bug
set @len=length(convert(@str using utf8mb4));
-- 返回字符串
set @ret=concat(@ret,substring(x,1,@loc-1),upper(substring(@str,1,1)),lower(substring(@str,2)));
-- 剩余字符串
select substring(x, @loc+@len) into x;
end while;
return concat(@ret,substring(x,1));
end;
//
delimiter ;(2)测试
mysql> set @s:='this ,\&。! $fskldj IS tEST string... ...';
Query OK, 0 rows affected (0.00 sec)
mysql> select initcap(@s);
+------------------------------------------------------+
| initcap(@s) |
+------------------------------------------------------+
| This ,&。! $Fskldj Is Test String... ... |
+------------------------------------------------------+
1 row in set (0.00 sec)(3)受限的转换
需求是这样的,将单词首字母转大写,其他字母转小写,但以点号 . 结尾的单词不做转换。先看实现:
mysql> select regexp_replace(initcap(regexp_replace('ABC&EFG dd.dd.', '(\\w+\\.)', concat(char(0),'a$1'))), concat(char(0),'.'),'') a;
+----------------+
| a |
+----------------+
| Abc&Efg dd.dd. |
+----------------+
1 row in set (0.00 sec)内层的 regexp_replace('ABC&EFG dd.dd.', '(\\w+\\.)', concat(char(0),'a$1')) 将 (\w+\.) 匹配点号结尾的单词拼接上一个标识字符串,这里是 char(0)加上字符 a 。前面说过 regexp_replace 的第三个参数中的函数会在正则表达式匹配前执行,但 concat 函数是个例外,它会拼接到匹配的字符串上,如:
mysql> select initcap(regexp_replace('ABC&EFG d.d.', '(\\w+\\.)', concat('Z','a$1'))) a;
+------------------+
| a |
+------------------+
| Abc&Efg Zad.Zad. |
+------------------+
1 row in set (0.00 sec)initcap(regexp_replace('ABC&EFG dd.dd.', '(\\w+\\.)', concat(char(0),'a$1'))) 将单词首字母大写,包括以点号 . 结尾的单词。
mysql> select initcap(regexp_replace('ABC&EFG dd.dd.', '(\\w+\\.)', concat(char(0),'a$1'))) ;
+-------------------------------------------------------------------------------+
| initcap(regexp_replace('ABC&EFG dd.dd.', '(\\w+\\.)', concat(char(0),'a$1'))) |
+-------------------------------------------------------------------------------+
| Abc&Efg Add. Add. |
+-------------------------------------------------------------------------------+
1 row in set (0.00 sec)最外层的 regexp_replace 将匹配 char(0)加上任意单一字符的标识字符串替换掉,剩下的就是符合要求的结果。
二、用八进制数匹配字符
还可以使用八进制数来匹配字符,八进制数以 8 为基数,使用数字 0到7 计数。在正则表达式处理器中,就是要在反斜线(\)后加三位数字。比如,以下八进制数:\351,等同于:\u00e9。
mysql> set @s:='Qu\'est-ce que la tolérance? c\'est l''apanage de l\'humanité. Nous sommes tous pétris de faiblesses et d\'erreurs; pardonnons-nous réciproquement nos sottises, c\'est la première loi de la nature.';
Query OK, 0 rows affected (0.00 sec)
mysql> select regexp_replace(@s,'([^\\0351])',''),regexp_replace(@s,'([^\\u00e9])','');
+-------------------------------------+--------------------------------------+
| regexp_replace(@s,'([^\\0351])','') | regexp_replace(@s,'([^\\u00e9])','') |
+-------------------------------------+--------------------------------------+
| éééé | éééé |
+-------------------------------------+--------------------------------------+
1 row in set (0.00 sec)在 MySQL 中,八进制的表示需要在数字前添加 0。
三、匹配 Unicode 字符属性
参考:https://www.cnblogs.com/gaara0305/p/10118664.html
每一个 Unicode 字符,除了有 Code Point (代码点)与之对应外,还具体其他属性。在正则表达式中常用到三种 Unicode 属性:Unicode Property、Unicode Block、Unicode Script,分别对应字符功能、所属代码区段、书写系统;它们的表现形式都类似 \p{property}。
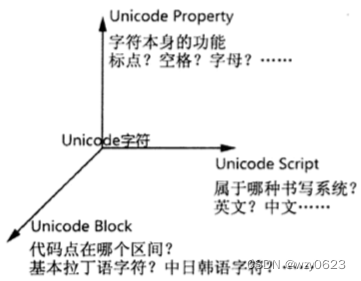
1. Unicode Property
Unicode Property 的记法类似 \p{L}、\p{P}。它按照字符的功能分类 Unicode 字符,每个 Unicode 字符只能属于一个 Unicode Property。可以这样理解 Unicode Property:它并不关心字符所属的语言,只关心字符的功能,比如 \p{Z} 表示任意的空白字符或不可见的分隔符;\p{P} 表示任意标点字符,等等。遇到中英文混排、全角、半角字符同时出现的情况,看可以用 \p{Z} 匹配所有的空白字符(而不用关心空格到底是全角空格还是半角空格),用 \p{P} 匹配所有的标点字符(而不用关心逗号到底是中文逗号还是英文逗号)。
如果把 Unicode Property 理解为一个“字符组”,一定还有对应的排除型字符组,此排除型字符组的通行记法是将 \p{property} 中的小写改为大写 P,写作 \P{property}。
(1)匹配所有标点
mysql> select regexp_replace('Unicode, 字符,属性!','\\p{P}','');
+-----------------------------------------------------------+
| regexp_replace('Unicode, 字符,属性!','\\p{P}','') |
+-----------------------------------------------------------+
| Unicode 字符属性 |
+-----------------------------------------------------------+
1 row in set (0.00 sec)(2)匹配所有空白符
mysql> select regexp_replace('Unicode, 字符,属性!','\\p{Z}','');
+-----------------------------------------------------------+
| regexp_replace('Unicode, 字符,属性!','\\p{Z}','') |
+-----------------------------------------------------------+
| Unicode,字符,属性! |
+-----------------------------------------------------------+
1 row in set (0.00 sec)(3)匹配所有非标点字符
mysql> -- 不匹配空白符
mysql> select regexp_replace('Unicode, 字符,属性!','\\p{L}','');
+-----------------------------------------------------------+
| regexp_replace('Unicode, 字符,属性!','\\p{L}','') |
+-----------------------------------------------------------+
| , ,! |
+-----------------------------------------------------------+
1 row in set (0.01 sec)
mysql> -- 匹配空白符
mysql> select regexp_replace('Unicode, 字符,属性!','\\P{P}','');
+-----------------------------------------------------------+
| regexp_replace('Unicode, 字符,属性!','\\P{P}','') |
+-----------------------------------------------------------+
| ,,! |
+-----------------------------------------------------------+
1 row in set (0.01 sec)2. Unicode Block
不同于 Unicoe Property,Unicode Block 按照编码区间划分 Unicode 字符,各个区间彼此联系但互不相交,所以每个 Unicode 编码中的每个字符都有唯一归属的 Unicode Block。
在 Unicode 编码表中,同一种语言的字符通常落在同一区间的,所以 Unicode Block 也可以粗略表示某类语言的字符,比如 \p{InHebrew} 表示希伯莱语字符,\p{InCJK_Unified_Ideographs} 表示兼容 CJK(中文、日文、韩文)统一表意字符。Unicode Block 的名字都有 In(Java风格)或者 Is(.NET风格)前缀,所以它对应的还是“落在某个区间的 Unicode 字符”。
(1)匹配CJK(中文、日文、韩文)字符
mysql> select regexp_replace('Unicode, 字符,属性!','\\p{InCJK_Unified_Ideographs}','');
+----------------------------------------------------------------------------------+
| regexp_replace('Unicode, 字符,属性!','\\p{InCJK_Unified_Ideographs}','') |
+----------------------------------------------------------------------------------+
| Unicode, ,! |
+----------------------------------------------------------------------------------+
1 row in set (0.00 sec)(2)匹配CJK(中文、日文、韩文)标点
另外值得一用的是 \p{InCJK_Symbols_and_Punctuation},从命名上来看,它覆盖了中文、日文、韩文中的大部分常见标点,但事实并非如此。比如全角逗号和叹号不匹配此属性,而全角句号就匹配。不过,所有标点都在 \p{P} 这个 Unicode Property 中。
mysql> select regexp_replace('Unicode, 字符,属性!。','\\p{InCJK_Symbols_and_Punctuation}','') a,
-> regexp_replace('Unicode, 字符,属性!','\\p{P}','') b\G
*************************** 1. row ***************************
a: Unicode, 字符,属性!
b: Unicode 字符属性
1 row in set (0.00 sec)3. Unicode Script
Unicode Script 按照字符所属的书写系统来划分 Unicode 字符,比如 \p{Greek} 表示希腊语字符,\p{Han} 表示汉语(中文字符)。它的写法类似 Unicode Block,只是名字的开头没有 Is 或者 In。可以很方便地用 \p{Han} 来匹配中文字符。
mysql> -- 匹配所有非汉语(包括空白符、标点等)字符
mysql> select regexp_replace('Unicode, 字符,属性!','\\P{Han}','');
+-------------------------------------------------------------+
| regexp_replace('Unicode, 字符,属性!','\\P{Han}','') |
+-------------------------------------------------------------+
| 字符属性 |
+-------------------------------------------------------------+
1 row in set (0.01 sec)四、匹配控制字符
很少会在文本中查找控制字符,但知道如何做也不是件坏事。在正则表达式中,可以像这样来指定一个控制字符:\cx ,其中 x 就是想匹配的控制字符。
-- 匹配空字符
select char(0) regexp '\\c@';
select char(0) regexp '\0';
-- 匹配报警字符
select char(7) regexp '\\cG';
select char(7) regexp '\\a';
-- 匹配转义符
select char(27) regexp '\\c[';
select char(27) regexp '\\e';
-- 匹配退格符
select char(8) regexp '\\cH';
select char(8) regexp '[\b]';如果没有括号,\b 会被认为是单词边界。括号改变了正则表达式处理器对 \b 的理解方式。
下表列出了本篇中匹配字符的方法。
| 代码 | 描述 |
| \uxxxx | Unicode(四位) |
| \xxx | Unicode(两位) |
| \x{xxxx} | Unicode(四位) |
| \x{xx} | Unicode(两位) |
| \ooo | 八进制(基数为8) |
| \cx | 控制字符 |
| \0 | 空字符 |
| \a | 报警符 |
| \e | 转义符 |
| [\b] | 退格符 |