文章目录
- 运行cmd终端后直接输入
- 安装成功
- scrapy框架安装成功
- 为什么使用此命令
- 安装scrapy框架成功后创建scrapy项目
- 建议在pycharm终端创建项目
- 打开项目
- 用scrapy框架实现案例——从新浪网爬取热点并把数据输入到excel表中
- 编辑setting.py文件
- 创建脚本、写入脚本
- 在终端运行脚本文件并输出到指定文件中
- 运行成功
- 使用excel打开文件
运行cmd终端后直接输入
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy

安装成功

scrapy框架安装成功
使用scrapy命令测试,下面的命令代表已经安装,可以使用其他命令来操作
scrapy
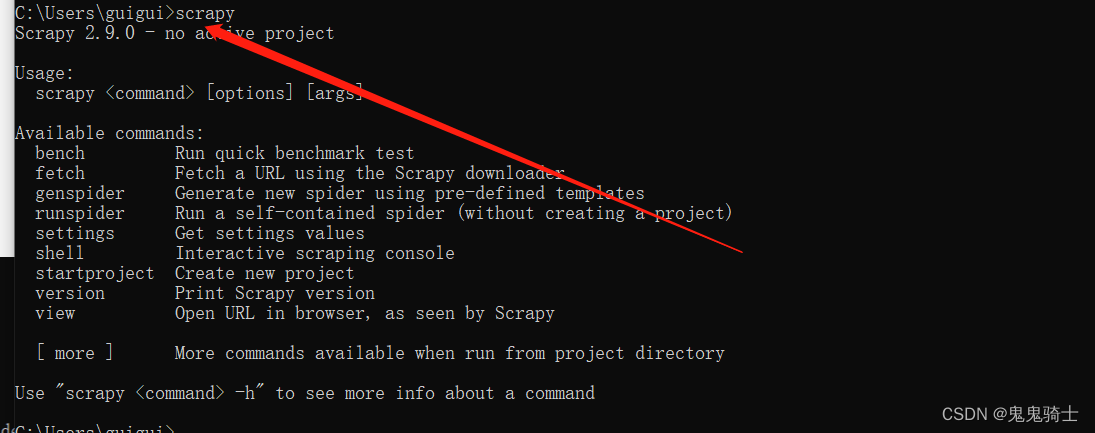
为什么使用此命令

安装scrapy框架成功后创建scrapy项目
建议在pycharm终端创建项目
进入terminal
注意当前文件夹,如果不合适自己调整下

# 回到上一目录
cd ..
# 进入下一目录
cd 文件夹名

创建项目
scrapy startproject [项目名]
# 例如
scrapy startproject ITest
项目创建成功,并提示我们可以cd在终端进入项目

打开项目
成功
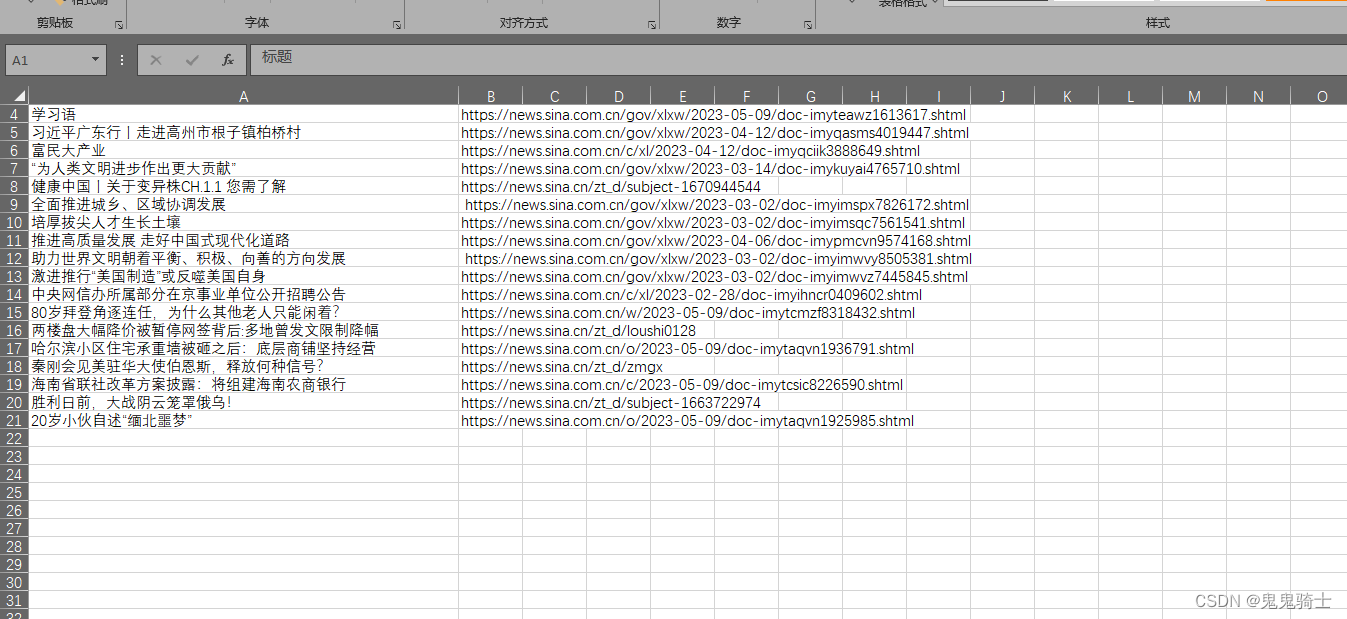
用scrapy框架实现案例——从新浪网爬取热点并把数据输入到excel表中
编辑setting.py文件
协议允许
编码改为gpk国码,目的是在excel中正确读取数据,根据情况改变


创建脚本、写入脚本

from abc import ABC
import scrapy
class SinaspiderSpider(scrapy.Spider, ABC):
name = 'sinaSpider'
allowed_domains = ['www.sina.com.cn']
start_urls = ['http://www.sina.com.cn/']
def parse(self, response):
data_list = []
lis = response.xpath("//div[@class='top_newslist']/ul[@class='list-a news_top']")
for li in lis:
titles = li.xpath(".//a/text()")
linkes = li.xpath(".//a/@href")
for title,link in zip(titles,linkes):
data_dict = {'标题':title.extract(),'链接':link.extract()}
data_list.append(data_dict)
return data_list
在终端运行脚本文件并输出到指定文件中
scrapy crawl sinaSpider -o sinaNews.csv

运行成功

使用excel打开文件