Presto
Presto基本介绍
前言
Presto是一款Facebook开源的MPP架构的OLAP查询引擎,可针对不同数据源执行大容量数据集的一款分布式SQL执行引擎。因为工作中接触到Presto,研究它对理解SQL Parser、常见算子的实现(如SQL中table scan,join,aggregation)、资源管理与调度、查询优化(如向量化执行、动态代码生成)、大数据下各个组件为何适用不同场景等等都有帮助。我希望通过这个系列可以了解一条SQL在大数据场景下该如何高效执行。233酱准备不定时持续更新这个系列,本文主要从Presto的使用举例,Presto的应用场景、Presto的基本概念三个部分来初步介绍Presto。
Presto的使用举例
比如说,你想对存储在不同数据源中的数据,如HDFS、Mysql、HBase等通过一个SQL做查询分析,那么只需要把每一个数据源当成是Presto的Connector,对应实现Presto SPI暴露出的Connector API就可以了。

hbase 和 es 的Join查询举例
Presto官方版和Presto社区版已经支持了很多Connector,社区版吕胜一筹。至于两者有何区别,吃瓜群众可以前往文末参考资料。简而言之,都主要由Facebook那帮大佬核心维护。社区版更新更为频繁,但高版本需要JDK11才能支持;官方版JDK8就行,官方版的Star数是社区版的10倍左右,选哪个就一目了然了吧。
Presto的应用场景
Presto是为了处理TB/PB级别的数据查询和分析,它是OLAP(Online Analytical Processing)领域的一个计算引擎。参考资料[1]提到了Presto在Facebook中的使用场景有:
报表和大盘查询
做过报表和大盘的小伙伴应该对这个场景下复杂的SQL有所了解。这个场景下的使用用户是Facebook内部或外部人员,通常要求:高QPS,低时延(<1s)。
Adhoc分析
Ad hoc是拉丁文「for this purpose」的意思,Adhoc query的查询特点是海量、实时、灵活。数据量如PB级别以上,时延秒-分钟级别,灵活性举例子如下:
var adhoclQuery = "SELECT * FROM table WHERE id = " + myId;
var sqlQuery = "SELECT * FROM table WHERE id = 1";
adhoclQuery的结果取决于参数“myId”的值,它的结果不能被预计算。sqlQuery的结果每次执行可认为都一样,它的结果可以被预计算。
典型应用场景如:用户趋势分析,产品市场洞察等。主要用户是内部数据分析人员。
批处理
批处理通常是指更大数据量的一个分析,可容忍高时延(小时-天级别)。Presto是为了低时延而设计的,它属于内存型的MPP架构。并不适合类似Spark那样的长时间离线跑批。参考资料[1]的视频中分析了两者架构的区别,Presto跑批的限制。这里我截几张PPT帮助大家理解:
两者的架构区别:

Presto跑批的限制原因:

Presto跑批的条件:
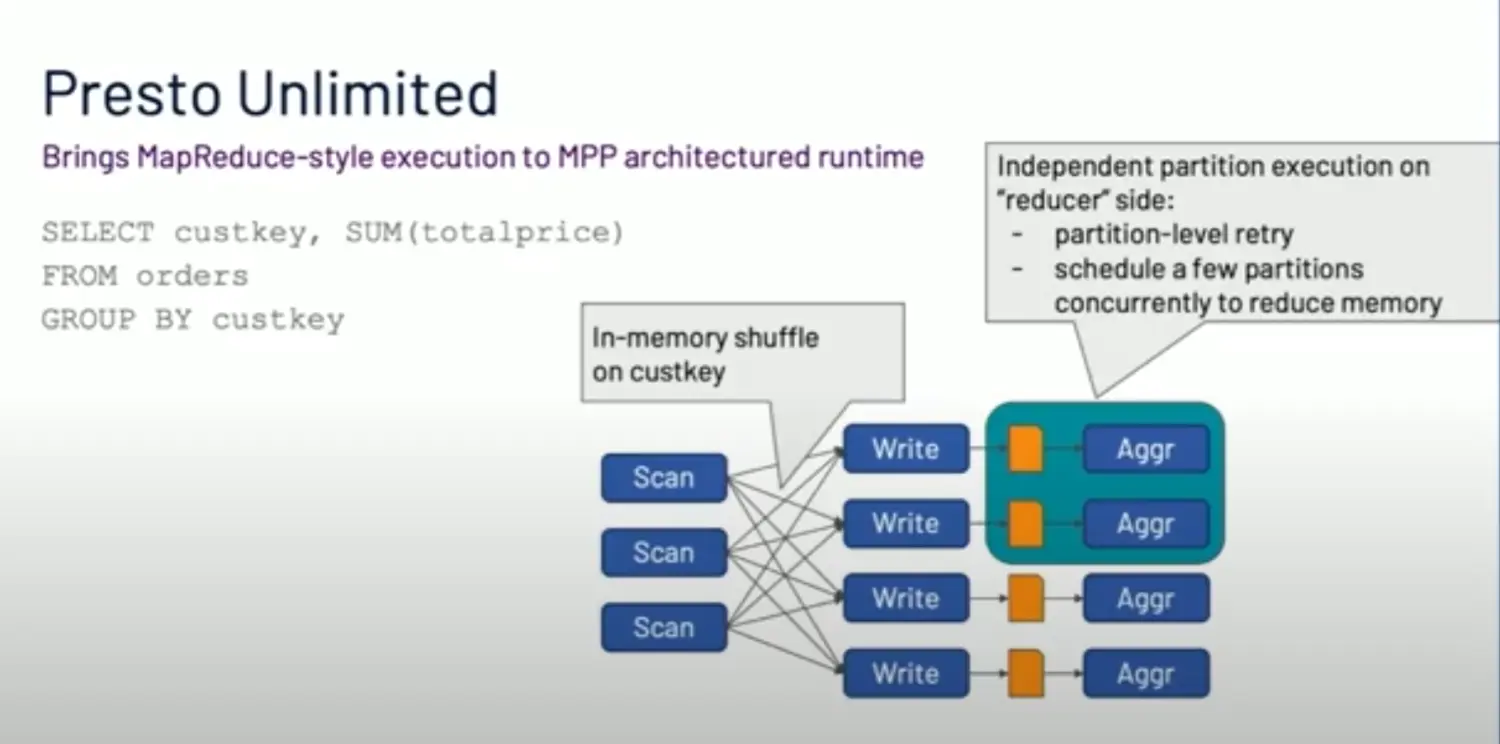
所以他们提供了Presto on Spark方案,这样做的好处是可以统一用户使用的SQL方言差异,UDF差异。

当然,业界除了Facebook还有公司把Presto跑在Spark上来跑批吗?我没有搜到相关信息。
Presto的基本概念
前面主要谈了Presto的使用场景,下面简要从 Presto的架构和基本术语上介绍Presto。
Presto架构
Presto的架构图如下:
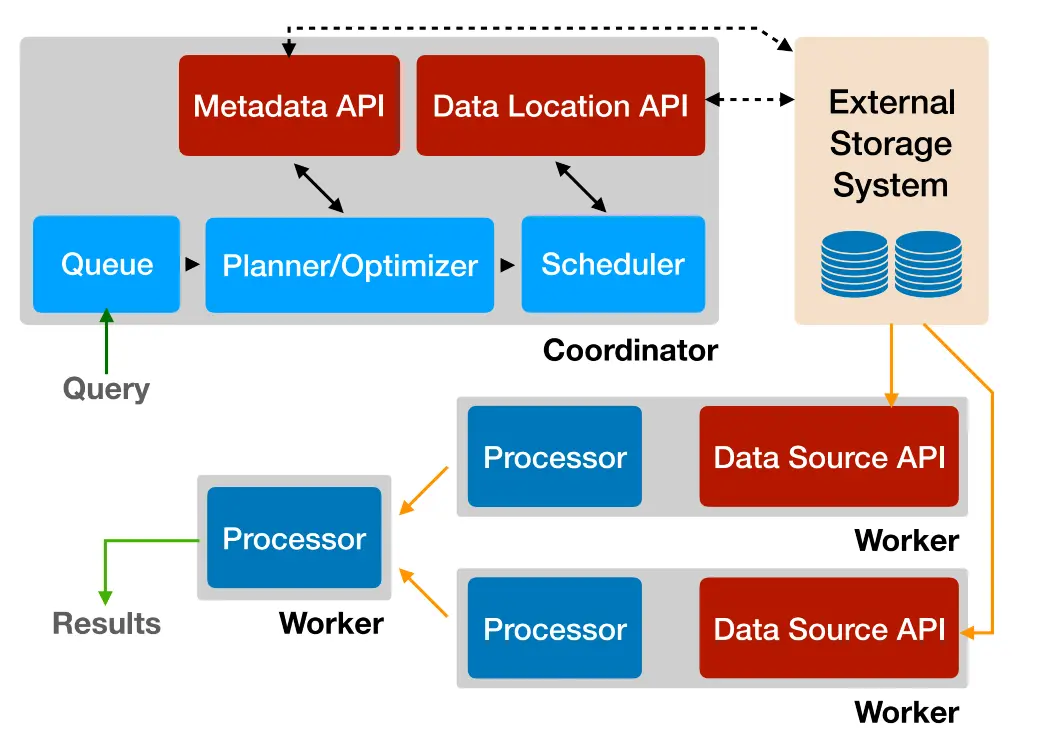
Presto集群包含1个Coordinator节点和1-多个Worker节点。
Coordinator节点 负责接受客户端请求、解析SQL语句、生成并优化分布式逻辑执行计划、将计划中的任务调度到Worker节点上,并跟踪Worker节点和任务的执行状态。
Worker节点 负责任务的执行,接受Coordinator节点的调度。
从中我们可以粗略看出一条SQL在Presto中的执行过程为:
1).Client发送一个SQL语句到Coordinator节点
2).Coordinator节点把请求放到队列中,解析和分析其中的SQL语句;生成并且优化分布式逻辑执行计划。
3).Coordinator节点会把这个Plan分解为任务,由多个Worker分布式执行。
要想了解具体的SQL执行过程,我们得先介绍下Presto的基本概念,也为下篇介绍「Presto为什么是OLAP领域的实时计算引擎」的文章作准备>_<
基本术语
我们很容易知道 *statements* 和 queries* 的意思。作为一个使用者我们也应该熟悉 stages、 splits* 这些概念使Presto尽可能高效执行queries;作为一个Presto管理员,应该理解 stages* 是如何映射为tasks***的,包含 *drivers* 集合 的 *task* 是如何处理数据的。以下将从一般到具体介绍Presto的基本术语。
Server Types
Presto包含两种类型的服务端节点:coordinators 和 workers。
Coordinator
Presto中的Coordinator节点负责解析SQL语句,生成并优化物理执行计划,管理Presto worker节点。它是Presto运行的“大脑”。它也是客户端提交SQL语句的节点。每个运行的Presto集群包含1个Coordinator节点和1-多个Worker节点。一个服务示例可同时担任这两种节点角色。
Coordinator节点一直跟踪每个Worker节点的状态和协调查询计划的执行。Coordinator生成一个物理执行计划模型,它包含一系列的stages,而stages会转化为一系列的任务跑在workers节点上。
Coordinator通过REST API和workers 、 clients通信。
Worker
Worker节点负责执行tasks,处理数据。它从connectors中捞取数据,并且Worker节点之间可交换中间数据。coordinator节点负责合并workers的结果,并且返回结果给Client。
当一个Worker节点开始工作后,它会把自己注册到coordinator的注册服务上,从而使Coordinator节点可将task调度到自己执行。
Workers和其他Workers、coordinators之间都是通过REST API通信。
Data Sources
诸如connector, catalog, schema, and table这些术语,都是和Presto的模型中:一种特定的数据源有关。
Connector
connector是Presto中的一个数据源,可以是Hive、Mysql、Elasticsearch、HBase等。你可以把connector认为是一种数据库驱动,只要实现Presto SPI 中暴露的相关接口,就可以接入一种Connector。
Presto自带一些connectors:如JMX,System connector用来获取system tables的,Hive connector,TPCH connector 用来性能测试用的,等等。
每一个catalog和一个特定的connector关联。每一个catalog配置文件中有一个connector.name属性,它是被catalog manager用来为一个给定的catalog创建一个connector。一个catalog可以使用相同的connector获取类似数据库的两个实例。
Catalog
Presto catalog包含schemas和通过Connector持有的数据源引用。比如:你可以配置一个ES catalog,就可以通过ES Connector提供从ES中获取数据。
#elasticsearch.properties
connector.name=elasticsearch
elasticsearch.host=es host
elasticsearch.port=9200
elasticsearch.default-schema-name=es
当你在Presto上执行SQL时,你就在运行1-多个catalogs.在Presto上定位一张表,是通过一个catalog的全限定名确定的,如hive.test_data.test代表在hive catalog,test_data schema 下的一张test table.
Catalogs属性文件是存储在Presto配置目录的,默认是Presto主安装文件下的etc目录下。
Schema
Schemas是一种组织tables的方式。一个catalog和一个catalog定义了一个可被查询的table集合。对于MySQL这种关系型数据库,Presto的schema是和MySQL中的schema相同的概念。对于其他类型的connector,如ES, Presto的schema是用来组织一些表到特定的schema中,从而使底层的数据源能够在Presto层面说得通。
Table
table是一组无序的Row集合,Row是一组有类型的column集合。和关系型数据库中的概念一样,table的映射是由connector中定义的。
Query Execution Model
Presto执行SQL语句,并且转化为执行计划,在由coordinator 和 workers组成的分布式集群上运行。
Statement
Presto执行兼容ANSI标准的SQL。这些SQL statements包含子句,表达式,条件。
Presto把Statement 和 Query区分开是因为:在Presto中,statements是指Client提交上来的SQL语句,如:
SELECT * FROM table WHERE id = 1
query是指Presto执行statement时,生成的一个物理执行计划,并且之后分布式的在一系列workers上执行它。
Query
当Presto解析一个statement时,它会把statement转化为一个query,并且创建一个分布式的执行计划,然后转化为一系列的有关联性的stages运行在Presto workers上。当你在Presto获取一个query的信息时,得到的是每个参与执行的组件的一个当前结果快照。
statement可认为是Client提交上来的SQL语句,query指的是执行一个statement有关的配置和组件实例信息。query围绕者stages, tasks, splits, connectors,其他组件和数据源一起工作,以产生最终结果。
Stage
当Presto执行一个query时,它会把执行分为一个有层次结构关系的stages.比如SQL语句:

会先转化为逻辑执行计划:
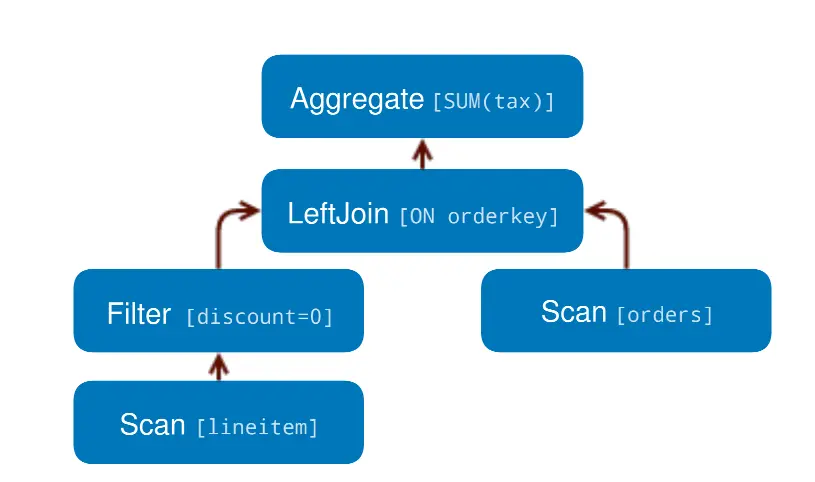
然后会转化为实现这个分布式逻辑执行计划的一个层次结构的stage:
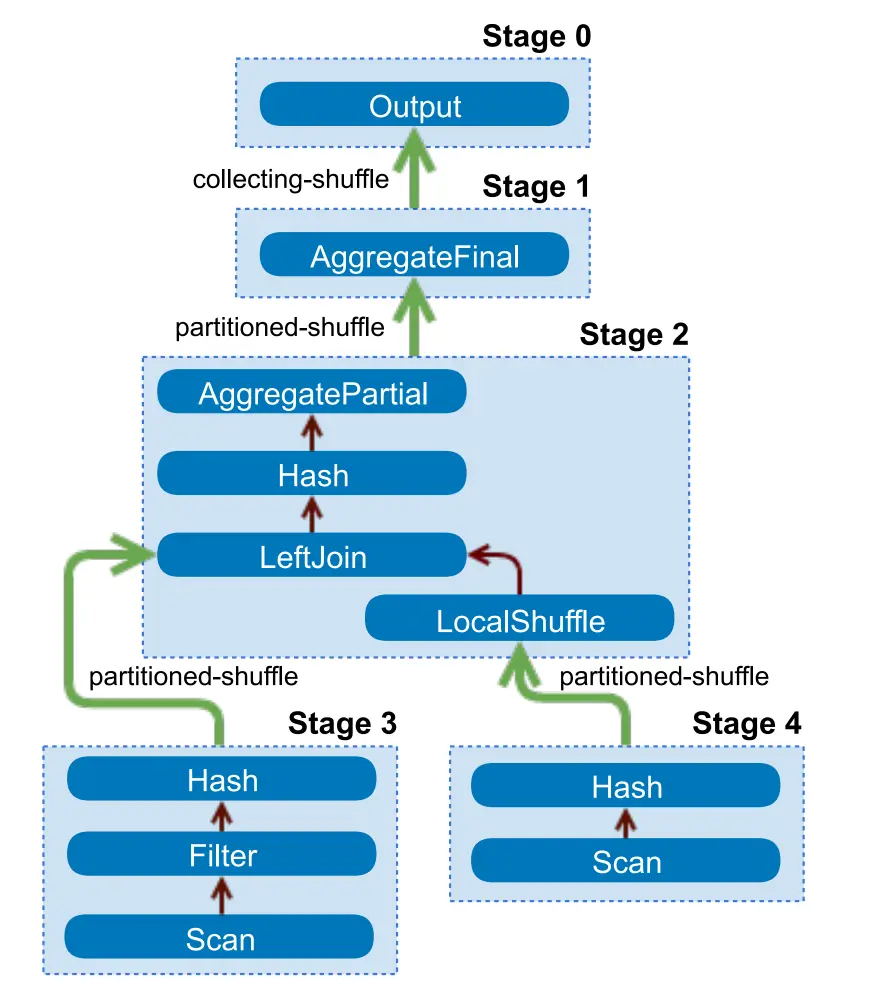
这个层次结构的stages可以理解为一个一个树。每个query都有一个root stage负责其他stages的输出结果聚合。stages是coordinator节点用来生成一个分布式查询计划的模型,但是stages它们自己并不跑在Presto workers节点上。
Task
一个stage是由一系列的tasks分布式运行在Presto workers上。
在Presto架构中,task是“work horse”。因为分布式查询计划被分解为一系列stage,然后被转换为task,这些task随后执行或被进一步split。一个task有输入和输出,就像一个stage可以有一系列的tasks并行执行一样,一个task可以由一系列的drivers并行执行。
Split
Split是较大数据集的一个分片。分布式查询计划的最低级别的stage(如上图中的Stage3/Stage4)通过来自connectors得到的splits集合获取输入数据,更高级别的中间Stage(如上图中的Stage2/Stage1)从下一层stage中获取输入数据。
当Presto调度一个query时,coordinator节点会查询连接器的SPI接口获得一个表可用的所有split集合。coordinator跟踪哪些机器正在运行哪些task,以及哪些任务正在处理哪些split。
Driver
Task包含一个或多个并行的driver。driver对数据进行操作,并结合operators产生输出,然后结果由一个task聚合,然后传递到另一个stage的另一个task。driver是一系列operators实例,或者您可以将driver看作内存中的operator的物理集合。它是Presto体系结构中并行的最低级别。一个driver有一个输入和一个输出。
Operator
一个operator消费、转换和生产数据。例如,一个table scan operator从一个connector中获取数据并生产出可由其他operator消费的数据,一个filter operator通过对输入数据应用谓词(过滤条件)并生成一个子集。
Exchange
Exchanges为一个query的不同stage在Presto节点之间传递数据。task使用一个exchange client,生产数据到一个output buffer中,并且消费其他task产生的数据。
Presto安装部署
1.版本选型
hadoop-3.3.5
hive-3.1.3
presto-280
2.Presto 简介
2.1 Presto 优势
多数据源,支持SQL,自定义扩展Connector
混合计算(同一种数据源的不同库 or表;将多个数据源的数据进行合并)
低延迟,高并发,纯内存计算引擎,高性能
2.2 Presto 架构
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LAT5uzKN-1683615865004)(img/jiagou.png)]
# presto提供插件化的connector来支持外部数据查询,原生支持hive、cassandra、elasticsearch、kafka、kudu、mongodb、mysql、redis等众多外部数据源;
1.coordinator(master):负责meta管理,worker管理;接收查询请求,解析SQL生成执行计划
2.worker:执行任务的节点,负责计算和读写
3.connector:连接器(Hadoop相关组件的连接器,RDBMS连接器)
4.discovery service:内嵌在coordinator节点中,也可以单独部署,用于节点心跳;worker节点启动后向discovery service服务注册,coordinator通过discovery service获取注册的worker节点
2.3 Presto数据模型
presto采取三层表结构:
catalog 对应某一类数据源,例如hive的数据,或mysql的数据
schema 对应mysql中的数据库
table 对应mysql中的表
2.4 Presto 执行过程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Yx8vcBm8-1683615865005)(img/zhixingguocheng.png)]
1、coordinator接到SQL后,通过SQL语法解析器把SQL语法解析变成一个抽象的语法树AST(描述最原始的用户需求),只是进行语法解析如果有错误此环节暴露
2、语法符合SQL语法,会经过一个逻辑查询计划器组件,通过connector 查询metadata中schema 列名 列类型等,将之与抽象语法数对应起来,生成一个物理的语法树节点 如果有类型错误会在此步报错
3、如果通过,会得到一个逻辑的查询计划,将其分发到分布式的逻辑计划器里,进行分布式解析,最后转化为一个个task
4、在每个task里面,会将位置信息解析出来,交给执行的plan,由plan将task分给worker执行
3.Presto 安装
3.1 安装
#server
tar -zxvf /opt/soft/presto-server-0.280.tar.gz
mv /opt/soft/presto-server-0.280/ /opt/soft/presto-server
#1.把 presto-cli-0.280.jar 复制到 /opt/soft/presto-server/bin 目录下
cp /opt/soft/presto-cli-0.280-executable.jar /opt/soft/presto-server/bin
#2.presto-cli-0.280.jar 重命名 presto-cli
mv /opt/soft/presto-server/bin/presto-cli-0.280.jar /opt/soft/presto-server/bin/presto-cli
#3.增加 presto 的执行权限
chmod +x /opt/soft/presto-server/bin/presto-cli
3.2 配置 Presto
1.配置数据目录
#最好安装在 presto server 安装目录外
mkdir /opt/soft/presto-server/data
2.创建配置文件
#1.在 presto server 安装目录 /opt/soft/presto 创建 etc 文件夹
mkdir /opt/soft/presto-server/etc
#2.在 /opt/soft/presto/etc 下创建 config.properties,jvm.properties,node.properties,log.properties 文件
vim config.properties
coordinator=true #work节点需要填写false
node-scheduler.include-coordinator=true #是否允许在coordinator上调度节点只负责调度时node-scheduler.include-coordinator设置为false,调度节点也作为worker时node-scheduler.include-coordinator设置为true
http-server.http.port=8085
query.max-memory=1GB
query.max-memory-per-node=512MB
query.max-total-memory-per-node=512MB
discovery-server.enabled=true #Presto 通过Discovery 服务来找到集群中所有的节点,每一个Presto实例都会在启动的时候将自己注册到discovery服务; 注意:worker 节点不需要配 discovery-server.enabled
discovery.uri=http://spark03:8085 #Discovery server的URI。由于启用了Presto coordinator内嵌的Discovery 服务,因此这个uri就是Presto coordinator的uri
# (Presto集群coordinator和worker的JVM配置是一致的)
vim jvm.config
-server
-Xmx2G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
vim node.properties
node.environment=production
node.id=ffffffff-ffff-ffff-ffff-ffffffffffff01 #每个节点需要不同
node.data-dir=/opt/soft/presto-server/data
vim log.properties
com.facebook.presto=DEBUG
3.3 配置 connector
#1.在 /opt/soft/presto-server/etc 创建 catalog 目录
mkdir /opt/soft/presto-server/etc/catalog
#2.在 catalog 目录下 创建 hive connector
vim hive.properties
connector.name=hive-hadoop2 #注意 connector.name 只能是 hive-hadoop2
hive.metastore.uri=thrift://spark03:9083
hive.config.resources=/opt/soft/hadoop3/etc/hadoop/core-site.xml,/opt/soft/hadoop3/etc/hadoop/hdfs-site.xml
#3.在 catalog 目录下 创建 mysql connector
vim mysql.properties
connector.name=mysql
connection-url=jdbc:mysql://spark03:3306
connection-user=root
connection-password=Lihaozhe!!@@1122
3.4 配置环境变量
vim /etc/profile
export PRESTO_HOME=/opt/soft/presto-server
export PATH=$PATH:$PRESTO_HOME/bin
source /etc/profile
4.启动 presto
注意:Presto requires Java 8u151+,需要jdk 1.8.151 以上,否则 PrestoServer 进程会自动死亡
#后台启动 (日志在 数据目录 /opt/soft/presto/data/var/log)
/opt/soft/presto-server/bin/launcher start
#调试启动
/opt/soft/presto-server/bin/launcher --verbose run
# 主要在CentOS8操作系统中需要单独安装python3
yum -y install python3
python3 /opt/soft/presto-server/bin/launcher.py start
python3 /opt/soft/presto-server/bin/launcher.py --verbose run
4.1 访问 presto webui http://saprk03:8085
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-A1GvuybD-1683615865005)(img/image-20211114173714641.png)]
5.测试
5.1 启动 presto cli
#在 presto server 安装目录下执行
./bin/presto-cli --server spark03:8085
java -jar presto-cli --server spark03:8085
# 查看连接的数据源
show catalogs;
presto-cli --server spark03:8085 --catalog hive --schema lihaozhe;
show tables;
#查看 mysql 中的库
show schemas from mysql;
Presto4Py
# pip3 install pyhive[presto]
from pyhive import presto
if __name__ == 'main':
cursor = presto.connect(host="saprk03",port="8085",catalog="hive",schema="default").cursor()
cursor = execute("select * from person limit 10")
println(cursor.fetchall())
from sqlalchemy import *
from sqlalchemy.engine import create_engine
from sqlalchemy.schema import *
if __name__ == 'main':
engine = create_engine("presto://spark03:8085/hive/lihaozhe")
table = Table('person',MetaData(bind=engine),autoload=True)
num = select([func.count(*)],from_obj=table).calar()
println("row count = {}".format(num))