服务器重启后nfs运行问题导致服务不能正常重启
解决办法
- 在每个节点下使用如下命令进行查看nfs是否正常启动
systemctl status nfs
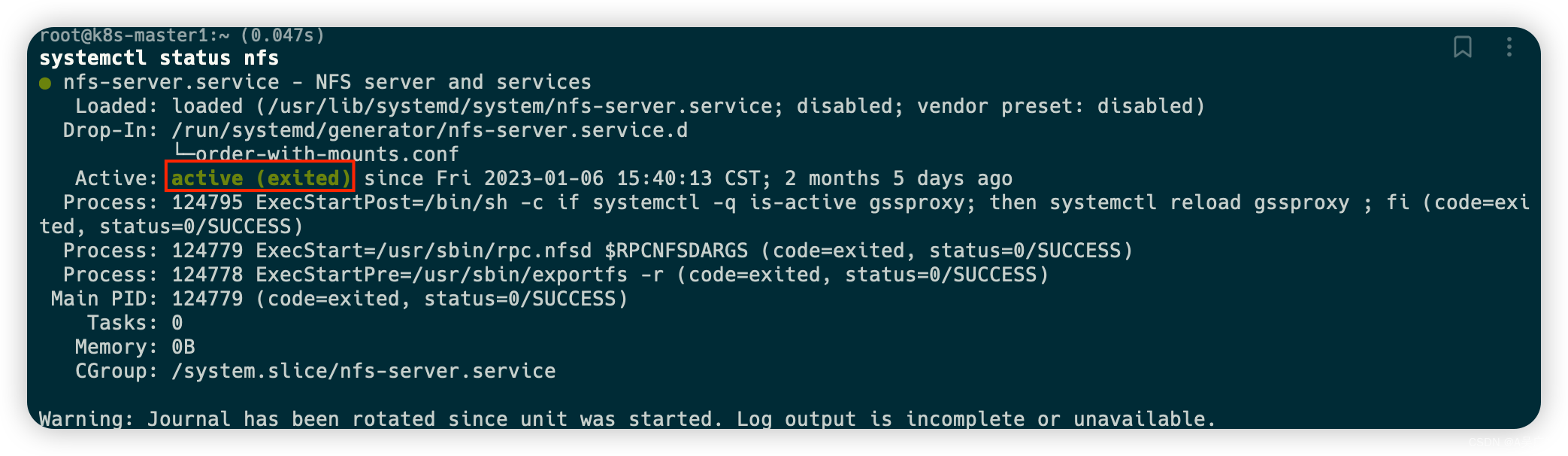
- 如果没有启动,则使用如下命令启动,保证三个节点下的nfs都正常启动
systemctl start nfs
- 再次查看nfs是否正常启动
systemctl status nfs
etcd没有正常启动
- 查看etcd是否正常启动
systemctl status etcd
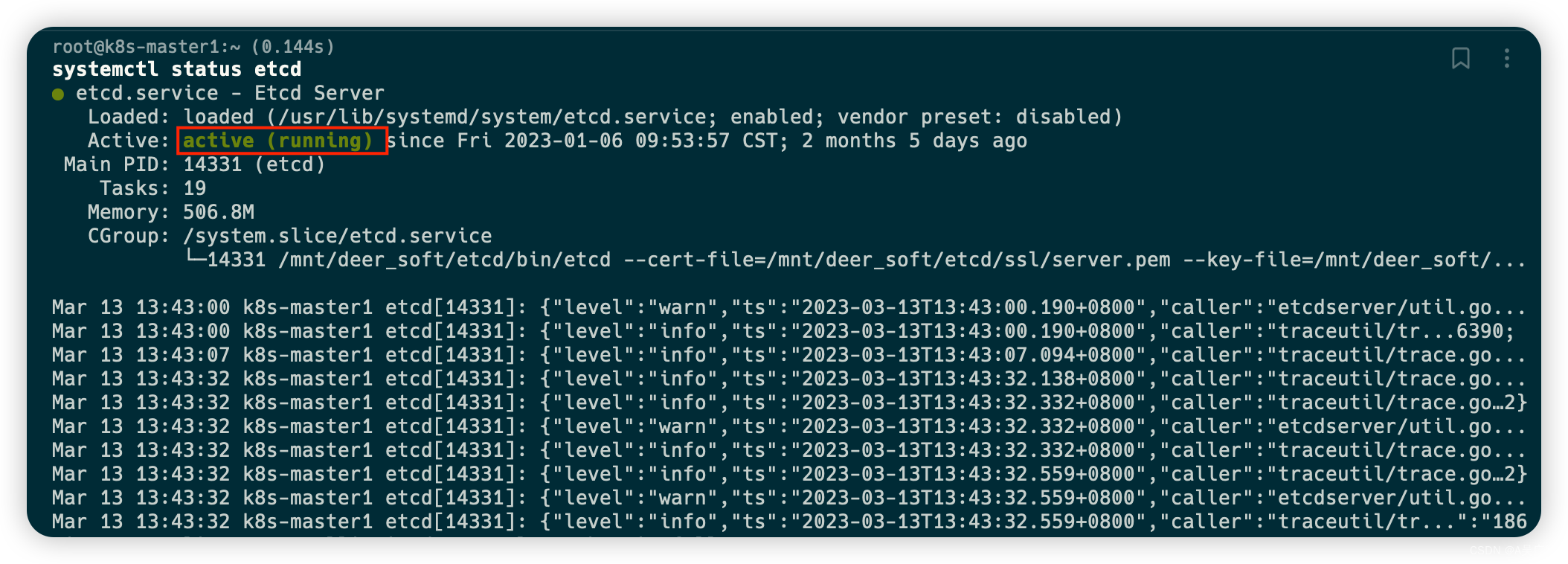
- 如果没有启动,使用如下命令进行启动,保证三个节点都要正常启动etcd
systemctl start etcd
- 再次查看etcd
systemctl status etcd
calico网络问题
在虚拟主机ping不通pod的ip;pod之间也访问不到,连接阿里去数据库也连接失败,进入容器内部ping不通外部网络
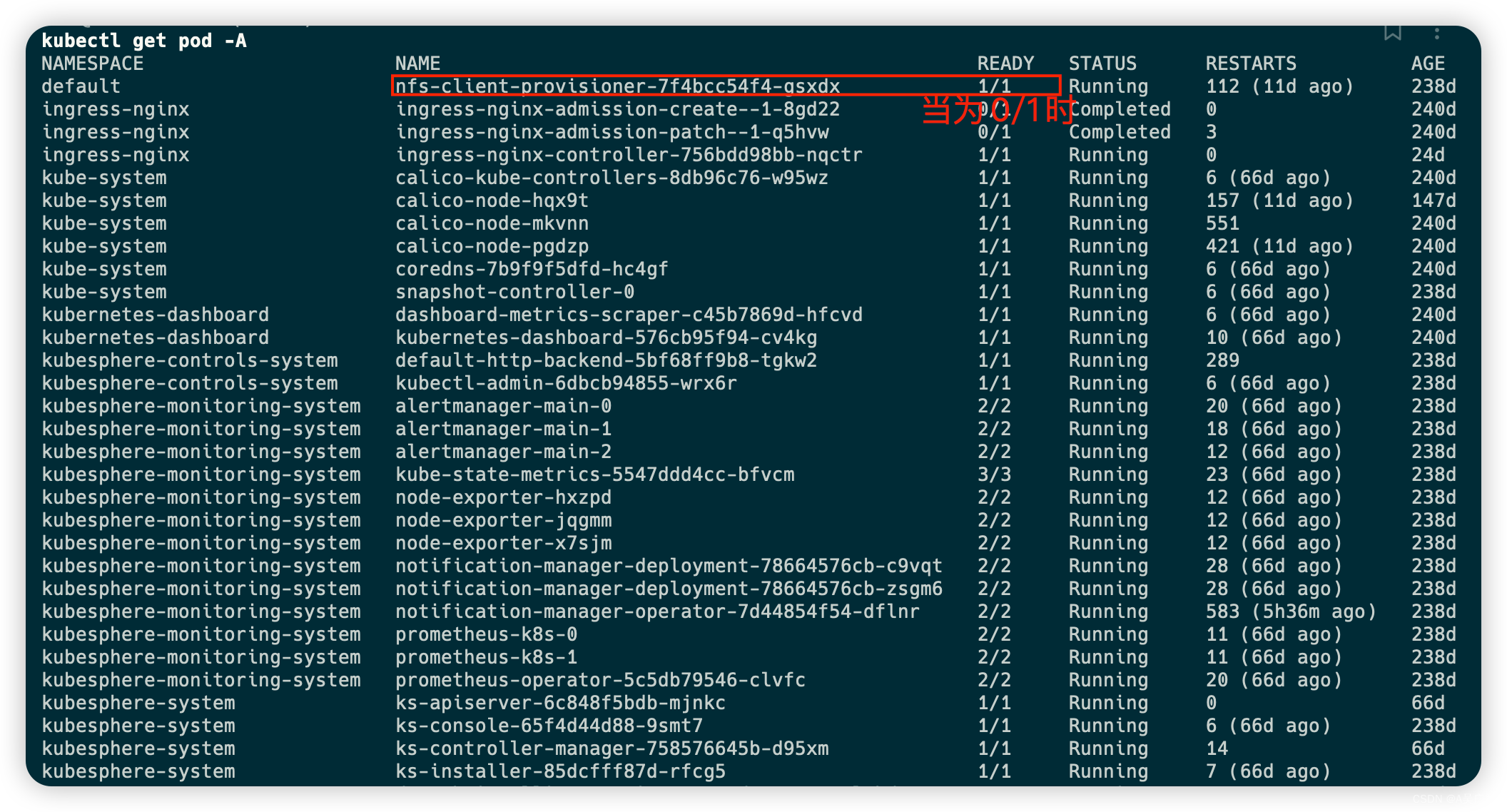
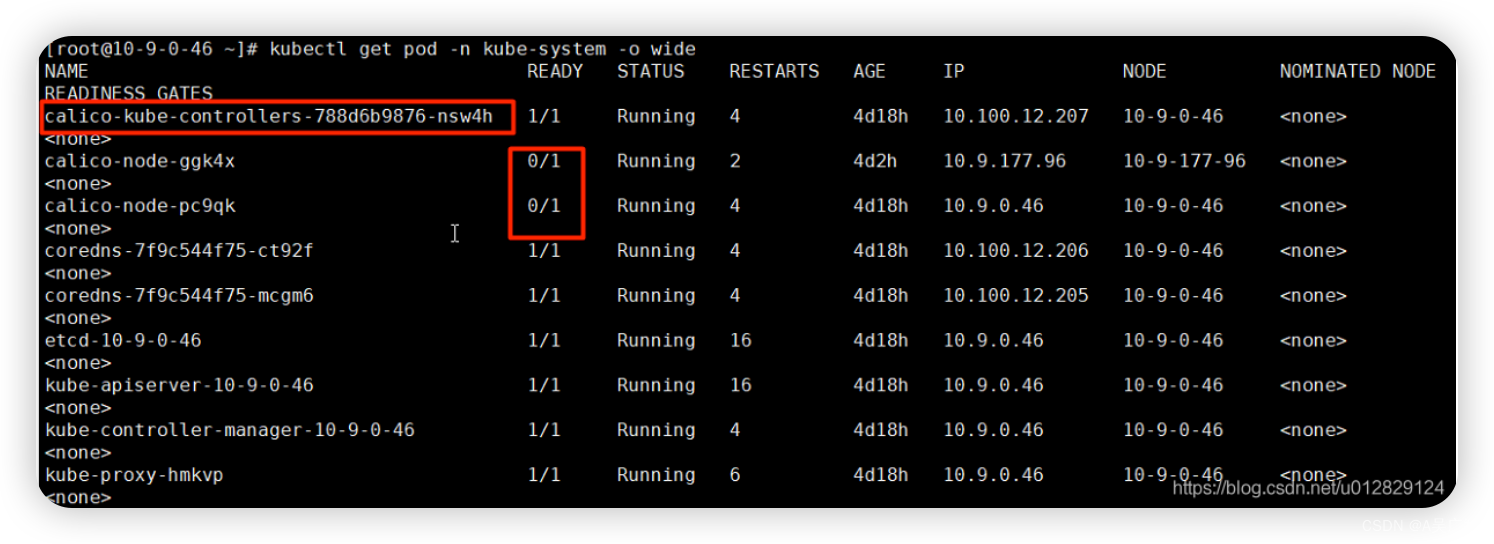
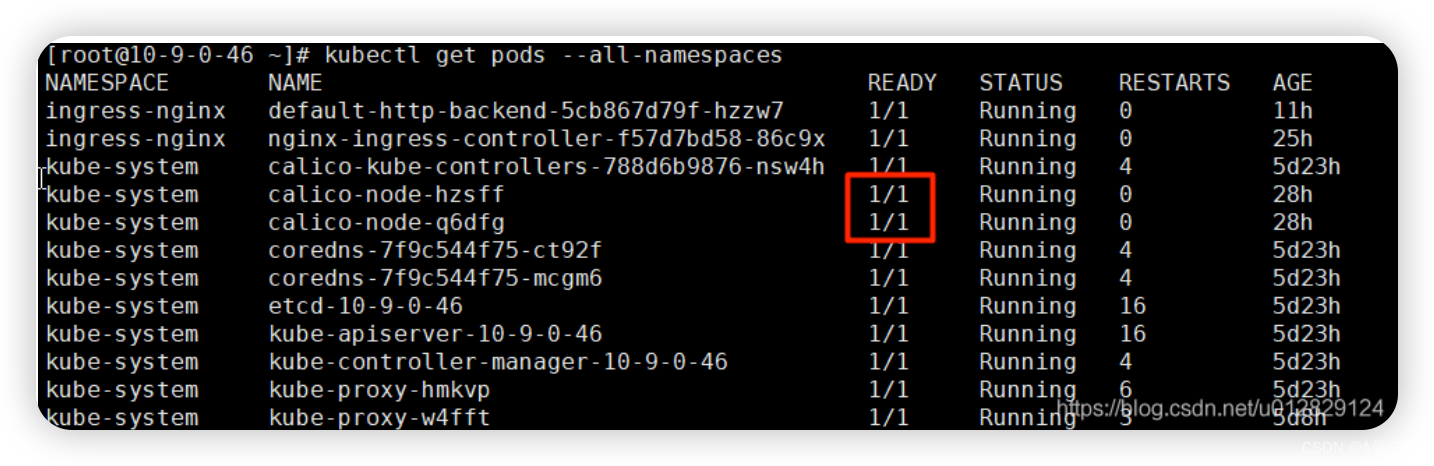
查看pod的运行情况(其中calico模块 Ready状态为0/1说明有问题)
kubectl get pod -n kube-system -o wide
查看calico模块日志
kubectl describe pods calico-node-hzsff -n kube-system
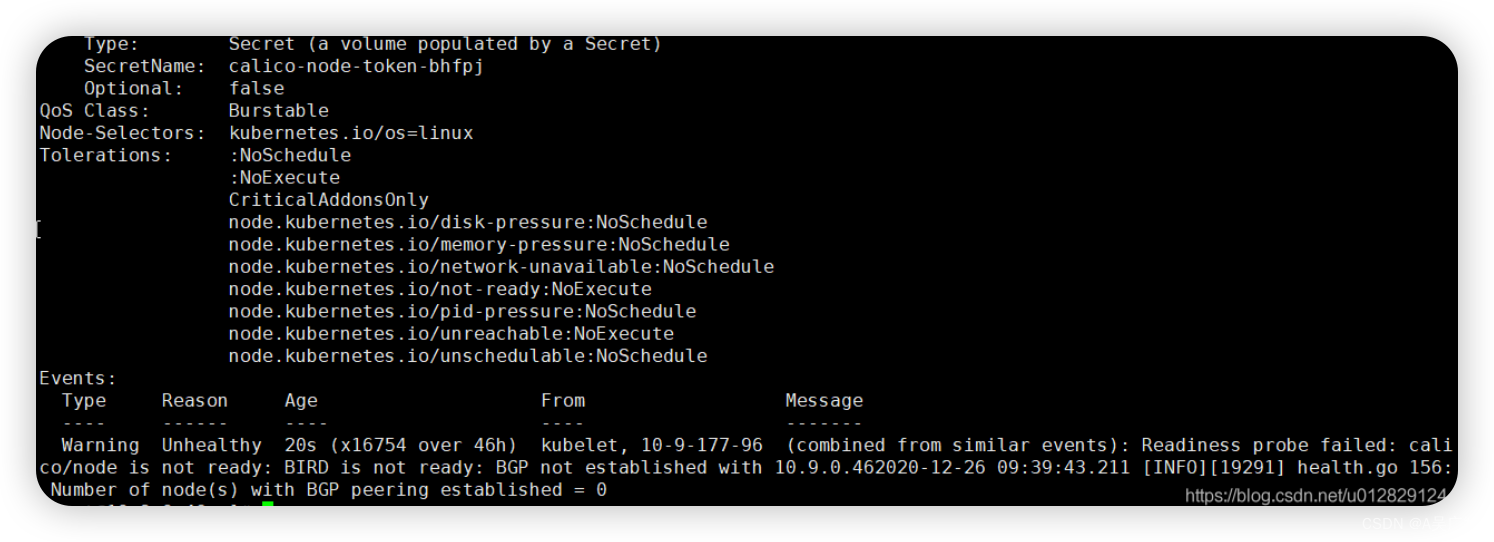
错误日志BIRD is not ready: BGP not established查找相关解决方案
查看网卡
ip a
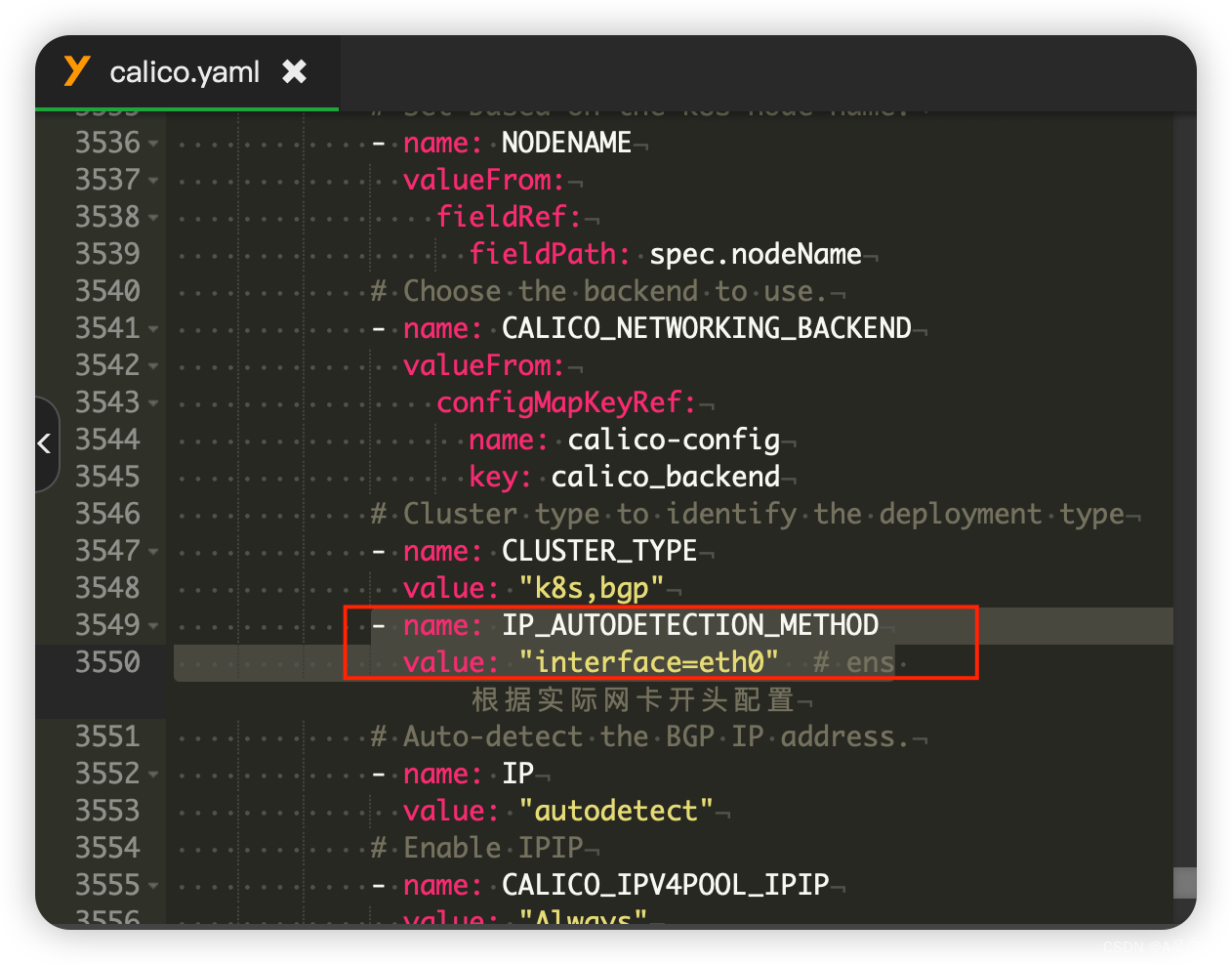
进入/mnt/tmp/k8s查找calico.yaml文件,添加
- name: IP_AUTODETECTION_METHOD
value: "interface=eth0" # ens
再次执行如下命令
# 进入目录
cd /mnt/tmp/k8s
# 重新执行命令
kubectl apply -f calico.yaml
# 或者强制执行yaml文件重启
kubectl replace --force -f calico.yaml
再次查看pod,是否正常
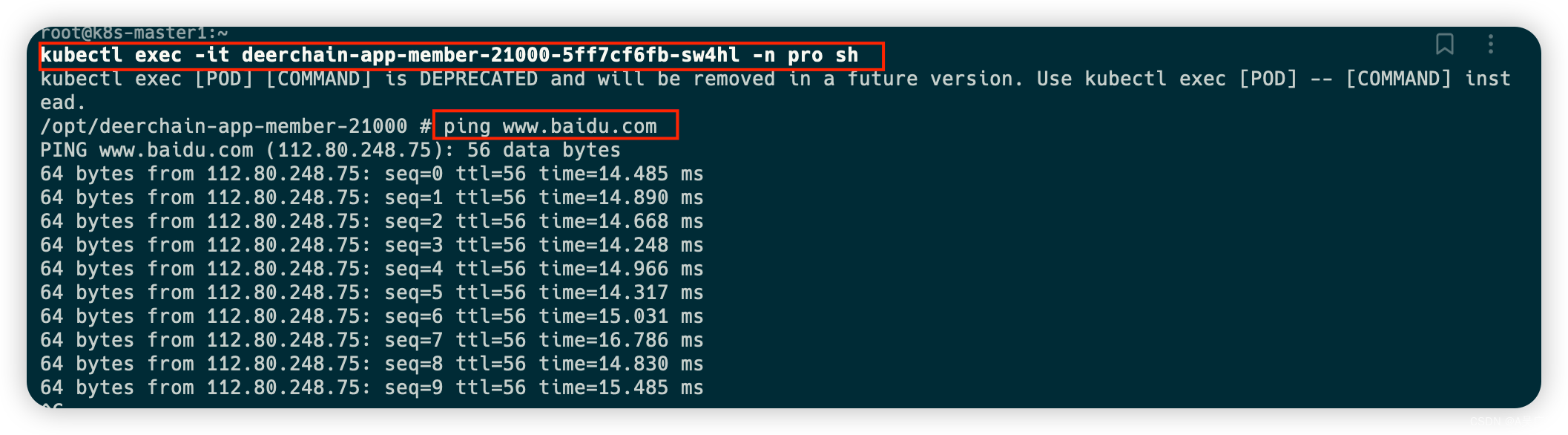
可以再次进入项目容器内部,进行ping外部网络是否可以ping通
# 进入容器内
kubectl exec -it deerchain-XXX -n pro sh
# 执行ping
ping www.baidu.com