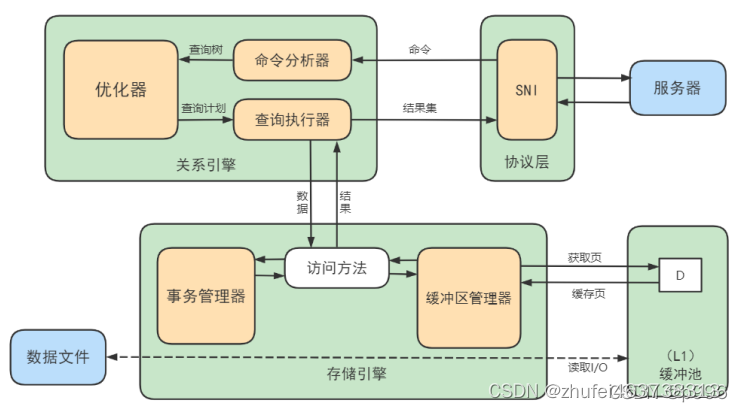
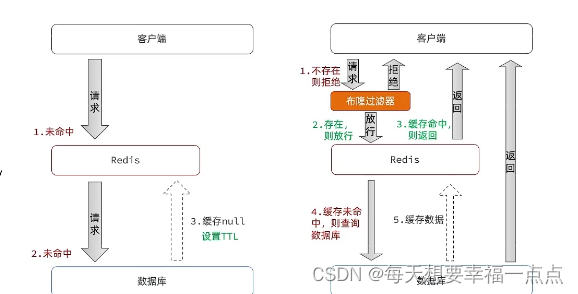
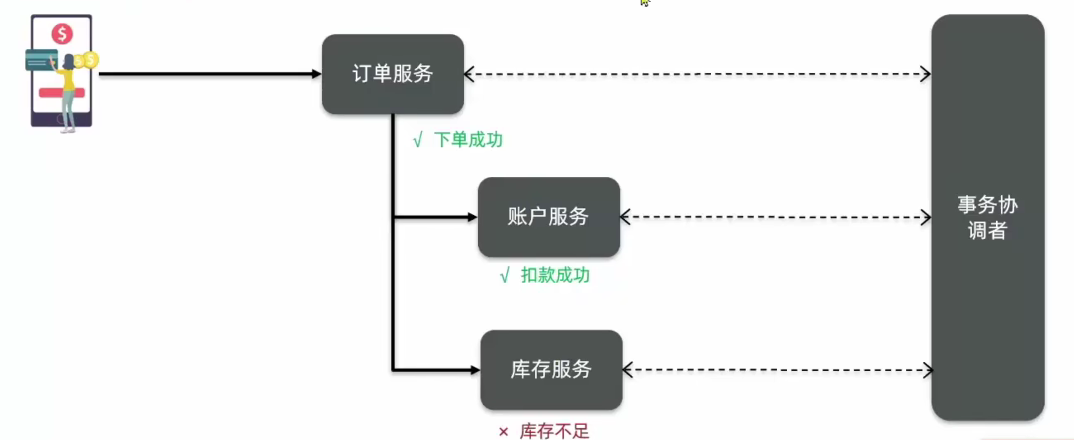
文章目录
- 题目1: "双十一"活动的电商GMV分析
- 题目2: 网站访问量分析
- 题目3: 用户购物信息统计
- 题目4: 连续售出的商品
- 题目5: 奇偶互换位置
- 题目6: 商品销量同环比
- 题目7: 文本记录连接
- 题目8: 行列互换
- 题目9: 寻找符合要求的订单
- 题目10: 优惠券使用分析
- 题目11: 员工绩效考核
- 题目12: 找出游戏中最活跃的用户
题目1: "双十一"活动的电商GMV分析
拓展: 商品交易总额(Gross Merchandise Volume,简称GMV)是成交总额(一定时间段内)的意思。多用于电商行业,一般包含拍下未支付订单金额。
现有一张电商的 GMV 数据表 easy_gmv_info,该表记录了某商家在“双十一”活动前后的GMV数据信息,easy_gmv_info 表的数据如下表所示:
mysql> SELECT * FROM easy_gmv_info;
# date(日期): DATE mall_gmv(GMV): INT
+------------+----------+
| date | mall_gmv |
+------------+----------+
| 2020-11-04 | 12325 |
| 2020-11-05 | 15497 |
| 2020-11-06 | 13216 |
| 2020-11-07 | 16548 |
| 2020-11-08 | 17367 |
| 2020-11-09 | 20124 |
| 2020-11-10 | 37325 |
| 2020-11-11 | 134367 |
| 2020-11-12 | 54331 |
| 2020-11-13 | 22212 |
| 2020-11-14 | 16312 |
| 2020-11-15 | 14384 |
| 2020-11-16 | 12314 |
| 2020-11-17 | 13146 |
+------------+----------+
14 rows in set (0.00 sec)
【题目1】查询2020年11月11日起的一周时间内,相比7天前GMV的变化率。输出内容包括:date(日期)、ratio(GMV变化率),结果样例如下图所示:
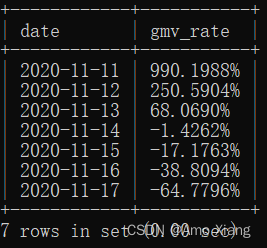
【题目1解析】使用LAG()函数构造偏移7天的数据,并通过做差得到差异gmv_diff,进而得到差异率gmv_rate,然后使用CONCAT()函数拼接%号,并且将结果限定在2020年11月11日到2020年11月17日,从而得到最终结果。 涉及知识点:子查询、窗口函数、分组聚合。参考代码如下:
SELECT `date`
, CONCAT(gmv_rate, '%') AS ratio
FROM (
SELECT `date`
, mall_gmv
# , (mall_gmv - LAG(mall_gmv, 7) OVER (ORDER BY `date`)) AS gmv_diff
, (mall_gmv - LAG(mall_gmv, 7) OVER (ORDER BY `date`))
/ LAG(mall_gmv, 7) OVER (ORDER BY `date`) * 100 AS gmv_rate
FROM easy_gmv_info
) t
WHERE `date` BETWEEN '2020-11-11' AND '2020-11-17';
题目2: 网站访问量分析
现有一张网站访问量情况表 easy_website_visit,该表记录了网站每日的访问量,easy_website_visit 表的数据如下表所示:
mysql> SELECT * FROM easy_website_visit;
-- data_content(日期访问量): VARCHAR 该字段的前8位为日期,后4位为访问量。
-- 例如: 201812011241 表示2018年12月01日的网站访问量为1241
+--------------+
| data_content |
+--------------+
| 201812011241 |
| 201812022493 |
| 201812030845 |
| 201812041230 |
| 201912012317 |
| 201912022520 |
| 201912031945 |
| 201912042031 |
| 202012013015 |
| 202012022914 |
| 202012032319 |
| 202012043143 |
+--------------+
12 rows in set (0.00 sec)
【题目2】查询每年最大网站访问量(不需要输出对应的日期)。输出内容包括:visit_year(访问年份)、max_visit(最大访问量),结果样例如下图所示:
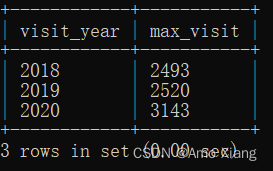
【题目2解析】通过SUBSTR()函数将数据中的年份和访问量截取出来,并分别命名为 visit_year和max_visit,然后使用RANK()函数根据年份进行分组降序排名,在子查询外部将排名为1的结果取出,即为每年的最大访问量数据。 涉及知识点:字符串处理函数、窗口函数、子查询。参考代码如下:
-- 写法①
mysql> SELECT visit_year
-> , max_visit
-> FROM (
-> SELECT SUBSTR(data_content, 1, 4) AS visit_year
-> , SUBSTR(data_content, -4, 4) AS max_visit
-> , RANK() OVER (PARTITION BY SUBSTR(data_content, 1, 4) ORDER
-> BY SUBSTR(data_content, -4, 4) DESC) AS ranking
-> FROM easy_website_visit
-> # ORDER BY data_content
-> ) a
-> WHERE a.ranking = 1;
-- 写法②
SELECT b.visit_year, b.visit_num AS 'max_visit'
FROM (
SELECT *, DENSE_RANK() OVER (PARTITION BY a.visit_year ORDER BY a.visit_num DESC ) AS visit_num_rank
FROM (SELECT LEFT(data_content, 4) AS visit_year, RIGHT(data_content, 4) AS visit_num
FROM easy_website_visit) a) b
WHERE b.visit_num_rank = 1;
题目3: 用户购物信息统计
现有两张表,第一张表为用户在购物网站的注册信息表 easy_user_register_info,该表记录了用户在购物网站的注册信息,easy_user_register_info 表的数据如下表所示:
mysql> SELECT * from easy_user_register_info;
-- user_id(用户ID):VARCHAR register_date(用户注册日期):DATE
+---------+---------------+
| user_id | register_date |
+---------+---------------+
| a001 | 2020-10-15 |
| a002 | 2020-11-20 |
| a003 | 2020-12-13 |
| a004 | 2021-01-18 |
+---------+---------------+
4 rows in set (0.00 sec)
另一张表为用户订单信息表 easy_user_order_info,easy_user_order_info 表的数据如下所示:
mysql> SELECT * FROM easy_user_order_info;
-- user_id(用户ID):VARCHAR order_id(订单ID):VARCHAR order_date(订单日期):DATE commodity_id(商品ID):VARCHAR
+---------+----------+------------+--------------+
| user_id | order_id | order_date | commodity_id |
+---------+----------+------------+--------------+
| a001 | o001 | 2020-11-12 | c005 |
| a002 | o002 | 2020-12-27 | c003 |
| a002 | o003 | 2021-01-12 | c003 |
| a003 | o004 | 2021-02-25 | c001 |
| a004 | o005 | 2021-03-12 | c004 |
| a004 | o006 | 2021-03-14 | c005 |
+---------+----------+------------+--------------+
6 rows in set (0.00 sec)
【题目3】查询每个用户的注册日期及其在2021年的订单总数。输出内容包括:user_id(用户ID)、reg_date(注册日期)、orders_2021(在2021年的订单总数),结果样例如下图所示:
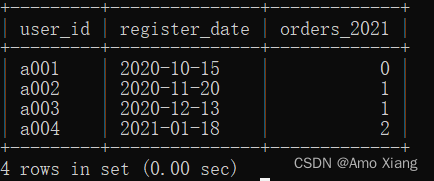
【题目3解析】将用户订单信息表和注册信息表进行LEFT JOIN,即可得到所有订单信息(包括用户注册日期),然后筛选出再2021年有购物订单的用户,并分组统计其在2021年的订单总数。涉及知识点:子查询、窗口函数。参考代码如下:
mysql> SELECT aa.user_id
-> , aa.register_date
-> , IFNULL(bb.order_2021, 0) AS orders_2021
-> FROM easy_user_register_info aa
-> LEFT JOIN
-> (
-> SELECT b.user_id
-> , b.register_date
-> , COUNT(order_id) AS order_2021
-> FROM easy_user_order_info a
-> LEFT JOIN easy_user_register_info b
-> ON a.user_id = b.user_id
-> WHERE YEAR(order_date) = 2021
-> GROUP BY b.user_id
-> , b.register_date
-> ) bb
-> ON aa.user_id = bb.user_id;
题目4: 连续售出的商品
现有一张用户在电商网站的购物订单部分信息表 easy_sold_succession,该表中的信息是按照时间顺序排列的,easy_sold_succession 表的数据如下所示:
mysql> SELECT * FROM easy_sold_succession;
-- order_id(订单ID):INT commodity_id(购买的商品ID):VARCHAR
+----------+--------------+
| order_id | commodity_id |
+----------+--------------+
| 1 | c_001 |
| 2 | c_001 |
| 3 | c_002 |
| 4 | c_002 |
| 5 | c_002 |
| 6 | c_001 |
| 7 | c_003 |
| 8 | c_003 |
| 9 | c_003 |
| 10 | c_003 |
| 11 | c_001 |
+----------+--------------+
11 rows in set (0.00 sec)
【题目4】找出连续下单大于或等于3次的商品ID。输出内容包括:commodity_id(购买的商品ID),结果样例如下所示:
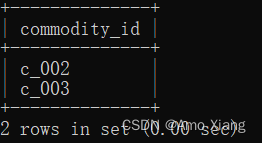
【题目4解析】使用窗口函数LAG(order_id,2),根据商品ID进行分组,并按照订单顺序默认升序延后两行展示。涉及知识点:子查询、窗口函数、DISTINCT。本题的SQL代码如下:
mysql> SELECT DISTINCT commodity_id
-> FROM
-> (
-> SELECT commodity_id
-> ,order_id
-> ,LAG(order_id,2) OVER (PARTITION BY commodity_id ORDER BY
-> order_id) AS temp
-> FROM easy_sold_succession
-> )a
-> WHERE order_id = temp + 2;
题目5: 奇偶互换位置
现有一张学生信息表 easy_student_info,easy_student_info 表的数据如下所示:
-- student_id(学生学号):INT student_name(学生姓名):VARCHAR
mysql> SELECT * FROM easy_student_info;
+------------+--------------+
| student_id | student_name |
+------------+--------------+
| 1 | 李明 |
| 2 | 王猛 |
| 3 | 吴丽丽 |
| 4 | 张飞 |
| 5 | 赵涛 |
+------------+--------------+
5 rows in set (0.00 sec)
【题目5】将奇数学号和偶数学号的相邻学生调换学号。若最后一个是奇数学号,则该学号不参与调换,最终结果按照最新学号升序排列,输出内容包括:student_id(调换后的学生学号)、student_name(学生姓名),结果样例如下图所示:
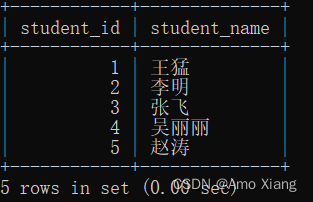
【题目5解析】使用MOD()函数将学号除以2,然后通过余数判断学号的奇偶性,并结合CASE WHEN语句,当学号为奇数时,将当前学号加1得到该学生的新学号;当学号为偶数时,将当前学号减1得到该学生的新学号。特殊情况:当前学号为数据条数且为奇数时,不对学号进行操作。涉及知识点:子查询、CASE WHEN、分组聚合、数学运算函数。本题的SQL代码如下:
mysql> SELECT CASE
-> WHEN MOD(student_id, 2) != 0 AND student_id != (SELECT COUNT(*) FROM easy_student_info)
-> THEN student_id + 1
-> WHEN MOD(student_id, 2) = 0 THEN student_id - 1
-> ELSE student_id
-> END AS student_id,
-> student_name
-> FROM easy_student_info
-> ORDER BY student_id ASC;
题目6: 商品销量同环比
现有一张商品销量表 easy_comparative_analysis,该表记录了商品每月销量信息,easy_comparative_analysis 表数据如下所示:
mysql> SELECT * FROM easy_comparative_analysis;
-- month(月份)VARCHAR sales_volume(销量)INT
+---------+--------------+
| month | sales_volume |
+---------+--------------+
| 2020-05 | 834 |
| 2020-06 | 604 |
| 2020-07 | 715 |
| 2020-08 | 984 |
| 2020-09 | 1024 |
| 2020-10 | 893 |
| 2020-11 | 485 |
| 2020-12 | 890 |
| 2021-01 | 563 |
| 2021-02 | 301 |
| 2021-03 | 1145 |
| 2021-04 | 1804 |
| 2021-05 | 1493 |
+---------+--------------+
13 rows in set (0.00 sec)
【题目6】统计2021年5月销量的同环比情况。输出内容包括:sales_volume(2021年5月销量)、year_ratio(2021年5月同比销量)、month_ratio(2021年5月环比销量),结果样例如下图所示:
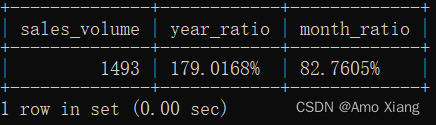
【题目6解析】使用LAG()函数分别获取2020年5月和2021年4月的销量情况作为同环比基准,计算同环比,通过WHERE筛选将2021年5月的同环比结果输出即可。涉及知识点:子查询、窗口函数。本题的SQL代码如下:
mysql> SELECT sales_volume
-> , CONCAT((sales_volume / year_on_year) * 100, '%') AS year_ratio
-> -- 环比=(本期统计周期数据/上期统计周期数据)×100%
-> , CONCAT((sales_volume / month_on_month) * 100, '%') AS month_ratio
-> FROM (SELECT `month`
-> , sales_volume
-> , LAG(sales_volume, 1) OVER (ORDER BY `month`) AS month_on_month
-> , LAG(sales_volume, 12) OVER (ORDER BY `month`) AS year_on_year
-> FROM easy_comparative_analysis
-> ) a
-> WHERE `month` = '2021-05';
题目7: 文本记录连接
现有一张待转换表 easy_convert_table,easy_convert_table 表的数据如下表所示:
mysql> SELECT * FROM easy_convert_table;
-- text_id(文本ID):VARCHAR text_content(文本内容):VARCHAR
+---------+--------------+
| text_id | text_content |
+---------+--------------+
| t001 | a |
| t002 | b |
| t001 | c |
| t002 | d |
| t002 | e |
| t003 | f |
+---------+--------------+
6 rows in set (0.00 sec)
【题目7】将表格结构转换为下图所示的形式,即将相同的text_id的text_content部分通过&符号拼接。输出内容包括:text_id(文本ID)、new_text(处理后的文本),结果样例如下图所示:
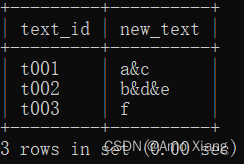
【题目7解析】使用GROUP_CONCAT()函数将文本连接到一起,指定连接符号为&,使用分组聚合将文本ID相同的记录连接到一起,以得到结果。涉及知识点:文本处理函数、分组聚合。本题的SQL代码如下:
mysql> SELECT text_id, GROUP_CONCAT(text_content SEPARATOR '&') AS 'new_text'
-> FROM easy_convert_table
-> GROUP BY text_id
-> ORDER BY text_id;
题目8: 行列互换
现有一张不同季度的商品进货量信息表 easy_purchase_quantity,easy_purchase_quantity 表的数据如下所示:
mysql> SELECT * FROM easy_purchase_quantity;
-- year(年份):VARCHAR quarter(季度):VARCHAR amount(进货量):INT
+------+---------+--------+
| year | quarter | amount |
+------+---------+--------+
| 2019 | 1 | 1200 |
| 2019 | 2 | 1000 |
| 2019 | 3 | 800 |
| 2019 | 4 | 1300 |
| 2020 | 1 | 1100 |
| 2020 | 2 | 950 |
| 2020 | 3 | 700 |
| 2020 | 4 | 1050 |
+------+---------+--------+
8 rows in set (0.00 sec)
【题目8】将以上表格结构转换为下图所示的形式。输出的内容包括:year(年份)、一季度、二季度、三季度、四季度的商品进货量。
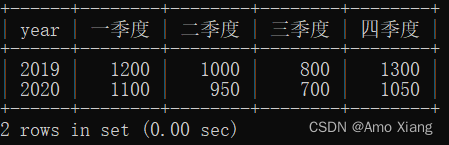
【题目8解析】本题是典型的行列互换题目,主要考察CASE WHEN的操作。通过CASE WHEN语句分别生成一季度到四季度的新字段,按照年份分组聚合即可得到结果。涉及知识点:CASE WHEN,分组聚合。本题的SQL代码如下:
mysql> SELECT year,
-> SUM(CASE WHEN quarter = 1 THEN amount ELSE 0 END) AS '一季度',
-> SUM(CASE WHEN quarter = 2 THEN amount ELSE 0 END) AS '二季度',
-> SUM(CASE WHEN quarter = 3 THEN amount ELSE 0 END) AS '三季度',
-> SUM(CASE WHEN quarter = 4 THEN amount ELSE 0 END) AS '四季度'
-> FROM easy_purchase_quantity
-> GROUP BY year;
题目9: 寻找符合要求的订单
现有一张用户消费的订单表 easy_consumer_order,easy_consumer_order 表的数据如下表所示:
mysql> SELECT * FROM easy_consumer_order;
-- order_id(订单ID):VARCHAR money(订单金额):INT
+----------+-------+
| order_id | money |
+----------+-------+
| a001 | 2000 |
| a002 | 4000 |
| a003 | 6000 |
| a004 | 2000 |
| a005 | 4000 |
| a006 | 3000 |
| a007 | 2000 |
| a008 | 4000 |
| a009 | 5000 |
+----------+-------+
9 rows in set (0.00 sec)
【题目9】按订单ID的顺序依次累加money,获取累计值与20000相差最小时对应的订单ID和最小差值,如果有多个符合条件的订单ID,则取出最小差值所对应的一个订单ID和最小差值 。输出的内容包括:order_id(订单ID)、diff(最小差值)。结果样例如下图所示:
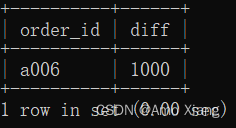
【题目9解析】使用窗口函数计算20000与当前累计money值的差的绝对值并将其作为新的一列,通过对该列升序排列后使用LIMIT获取第一项以得到结果。涉及知识点:窗口函数。本题的SQL代码如下:
mysql> SELECT order_id, ABS(SUM(money) OVER (ORDER BY order_id) - 20000) AS 'diff'
-> FROM easy_consumer_order
-> ORDER BY diff ASC
-> LIMIT 1;
题目10: 优惠券使用分析
现有一张电商优惠券领取表 easy_coupon_collection,该表记录了用户领取优惠券的信息,easy_coupon_collection 表的数据如下表所示:
mysql> SELECT * FROM easy_coupon_collection;
-- user_id(用户ID):VARCHAR collection_date(领取优惠券日期):DATE
+---------+-----------------+
| user_id | collection_date |
+---------+-----------------+
| u001 | 2021-05-01 |
| u002 | 2021-05-01 |
| u003 | 2021-05-02 |
| u004 | 2021-05-02 |
| u005 | 2021-05-03 |
+---------+-----------------+
5 rows in set (0.00 sec)
还有一张电商消费情况表 easy_consumption_info,easy_consumption_info 表的数据如下表所示:
mysql> SELECT * FROM easy_consumption_info;
-- user_id(用户ID):VARCHAR consumption_date(消费日期):DATE
+---------+------------------+
| user_id | consumption_date |
+---------+------------------+
| u002 | 2021-04-28 |
| u001 | 2021-04-29 |
| u001 | 2021-05-03 |
| u003 | 2021-05-05 |
| u005 | 2021-05-06 |
| u001 | 2021-05-08 |
| u004 | 2021-05-09 |
| u006 | 2021-05-09 |
| u003 | 2021-05-10 |
| u002 | 2021-05-10 |
+---------+------------------+
10 rows in set (0.00 sec)
【题目10】用户领取的优惠券在次日生效,并在之后的7天内购物时自动生效,使用次数不限。要求获取成功使用消费券消费的用户及其对应的消费次数。输出的内容包括:user_id(成功使用优惠券消费的用户)、num(消费次数)。结果样例如下图所示:
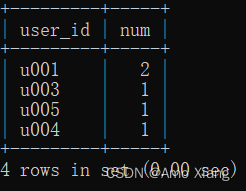
【题目10解析】将两张表使用INNER JOIN进行连接,连接条件为用户ID相同,然后使用DATE_DIFF()函数筛选出符合优惠券使用的日期,并将筛选出的结果分组计数,即可得到结果。涉及知识点:分组聚合、日期/时间处理函数。本题的SQL代码如下:
mysql> -- 第①种写法
mysql> SELECT e1.user_id, COUNT(e2.consumption_date) AS num
-> FROM easy_coupon_collection e1
-> INNER JOIN easy_consumption_info e2 ON e1.user_id = e2.user_id
-> WHERE DATEDIFF(e2.consumption_date, e1.collection_date) BETWEEN 1 AND 7
-> GROUP BY e1.user_id;
+---------+-----+
| user_id | num |
+---------+-----+
| u001 | 2 |
| u003 | 1 |
| u005 | 1 |
| u004 | 1 |
+---------+-----+
4 rows in set (0.00 sec)
mysql> -- 第②种写法
mysql> SELECT e1.user_id, COUNT(e2.consumption_date) AS num
-> FROM easy_coupon_collection e1
-> INNER JOIN easy_consumption_info e2 ON e1.user_id = e2.user_id
AND e2.consumption_date BETWEEN DATE_ADD(e1.collection_date, INTERVAL 1 DAY) AND DATE_ADD(e1.collection_date, INTERVAL 7 DAY)
-> GROUP BY e1.user_id;
+---------+-----+
| user_id | num |
+---------+-----+
| u001 | 2 |
| u003 | 1 |
| u005 | 1 |
| u004 | 1 |
+---------+-----+
4 rows in set (0.00 sec)
题目11: 员工绩效考核
现有一张员工表现打分表 easy_employee_performance,easy_employee_performance 表的数据如下所示:
-- employee_id(员工ID):VARCHAR target_a(A指标)得分:INT target_b(B指标)得分:INT
-- target_c(C指标)得分:INT target_d(D指标)得分:INT target_e(E指标)得分:INT
mysql> SELECT * FROM easy_employee_performance;
+-------------+----------+----------+----------+----------+----------+
| employee_id | target_a | target_b | target_c | target_d | target_e |
+-------------+----------+----------+----------+----------+----------+
| u001 | 9 | 7 | 9 | 10 | 6 |
| u002 | 8 | 8 | 8 | 9 | 10 |
| u003 | 10 | 10 | 10 | 9 | 9 |
| u004 | 5 | 7 | 9 | 8 | 8 |
| u005 | 7 | 7 | 5 | 4 | 6 |
| u006 | 10 | 9 | 10 | 7 | 8 |
| u007 | 8 | 7 | 8 | 9 | 6 |
| u008 | 8 | 9 | 10 | 10 | 6 |
| u009 | 5 | 5 | 6 | 7 | 6 |
| u010 | 10 | 10 | 10 | 8 | 7 |
+-------------+----------+----------+----------+----------+----------+
10 rows in set (0.00 sec)
【题目11】在考核员工绩效时,可以根据员工5个指标的得分情况评选优秀员工。优秀员工的要求是至少有4个指标分数大于等于8分。查询优秀员工的ID和总分,并且按照总分降序排列,如果总分相同,则按照员工ID升序排列。输出的内容包括:employee_id(员工ID)、total_score(总分)。结果样例如下图所示:
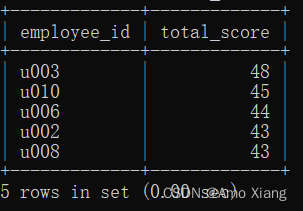
【题目11解析】使用CASE WHEN统计5个指标是否大于或等于8分,将满足条件的记为1(保留原始分数),将不满足条件的记为0。然后对统计的结果求和,如果求和结果大于或等于4(32)(说明符合优秀员工条件),则将结果通过WHERE筛选出来,同时构造一列用于为5个指标分数求和,并按照题目要求排序,即可得到结果。本题的SQL代码如下:
mysql> SELECT employee_id, total_score
-> FROM (SELECT employee_id,
-> CASE WHEN target_a >= 8 THEN target_a ELSE 0 END AS a,
-> CASE WHEN target_b >= 8 THEN target_b ELSE 0 END AS b,
-> CASE WHEN target_c >= 8 THEN target_c ELSE 0 END AS c,
-> CASE WHEN target_d >= 8 THEN target_d ELSE 0 END AS d,
-> CASE WHEN target_e >= 8 THEN target_e ELSE 0 END AS e,
-> target_a + target_b + target_c + target_d + target_e AS 'total_score'
-> FROM easy_employee_performance) temp_table
-> WHERE (a + b + c + d + e) >= 32
-> ORDER BY total_score DESC, employee_id ASC;
题目12: 找出游戏中最活跃的用户
现有一张游戏用户对战信息表 easy_pk_info,该表记录了用户对战等信息,easy_pk_info 表的数据如下表所示:
mysql> SELECT * from easy_pk_info;
-- request_id(发起对战用户ID)VARCHAR accept_id(接受对战用户ID):VARCHAR accept_date(接受对战日期):DATE
+------------+-----------+-------------+
| request_id | accept_id | accept_date |
+------------+-----------+-------------+
| a001 | a002 | 2021-03-01 |
| a001 | a003 | 2021-03-01 |
| a001 | a004 | 2021-03-02 |
| a002 | a003 | 2021-03-02 |
| a005 | a003 | 2021-03-03 |
| a006 | a001 | 2021-03-04 |
| a004 | a003 | 2021-03-05 |
+------------+-----------+-------------+
7 rows in set (0.00 sec)
【题目12】用户的对战次数可以反映出用户的游戏活跃度,要求统计对战次数最多的用户ID及其对战的次数(只需要返回一条结果)。输出的内容包括:user_id(用户ID)、cnt(对战次数)。结果样例如下图所示:
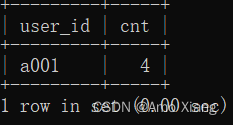
【题目12解析】在统计用户信息时,需要统计发起对战和接受对战的用户信息,并使用UNION ALL进行连接,使用GROUP BY进行分组计数后按照数量倒序排列,获取第一条记录(即对战次数最多的用户信息)。本题的SQL代码如下:
mysql> SELECT user_id
-> , COUNT(*) AS cnt
-> FROM (
-> SELECT request_id AS user_id
-> FROM easy_pk_info
-> UNION ALL
-> SELECT accept_id AS user_id
-> FROM easy_pk_info
-> ) a
-> GROUP BY user_id
-> ORDER BY cnt DESC
-> LIMIT 1;
-- 返回多条
SELECT user_id, cnt
FROM (SELECT user_id, cnt, DENSE_RANK() OVER (ORDER BY cnt DESC) AS cnt_rank
FROM (SELECT user_id, COUNT(user_id) AS 'cnt'
FROM (SELECT request_id AS 'user_id'
FROM easy_pk_info
UNION ALL
SELECT accept_id
FROM easy_pk_info) a
GROUP BY a.user_id) b) c
WHERE c.cnt_rank = 1;
至此今天的学习就到此结束了,笔者在这里声明,笔者写文章只是为了学习交流,以及让更多学习数据库的读者少走一些弯路,节省时间,并不用做其他用途,如有侵权,联系博主删除即可。感谢您阅读本篇博文,希望本文能成为您编程路上的领航者。祝您阅读愉快!

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请点赞、评论、收藏一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
编码不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!