基于redis中的list类型实现分页思路:
list数据类型的应用场景:
1)对数据量大的集合做删减,比如说百度首页的热点新闻的列表,有一个换一换的功能,我们正是利用了list集合中的分页功能,使用lrange的命令,列表数据的显示,关注列表,粉丝留言,留言评价等搜使用到了list,在博客系统中,每篇博文的评论也可以单独的存放到list集合里面
2)任务队列:list通常用于实现一个消息队列,并且可以保证先后顺序,不必像MYSQL那样通过orderby来指定先后顺序
案例1:热点新闻列表,来进行获取最新的5条热点新闻
1)查询5条列表新闻,并具备分页功能
2)后台管理员可以置顶指定新闻
@RequestMapping("/GetMessage") @ResponseBody public List<String> GetMessage(){ //1.初始化操作先进行向redis中存入热点新闻 String key="baidu:topMessage:5"; if(!template.hasKey(key)){ template.opsForList().leftPush(key,"李佳伟拿到了offer"); template.opsForList().leftPush(key,"我是好人呃"); template.opsForList().leftPush(key,"好好学习天天向上"); template.opsForList().leftPush(key,"学习新思想争做新青年"); template.opsForList().leftPush(key,"我是中国人我爱我的祖国"); } //2.获取到所有热点新闻 List<String> list=template.opsForList().range(key,0,4); return list; } @RequestMapping("/InsertMessage") @ResponseBody public String InsertMessage(String message){ String key="baidu:topMessage:5"; template.opsForList().leftPush(key,message); return "热点新闻添加成功"; }案例二:生成物流信息
@RequestMapping("/productMessage") @ResponseBody public String productMessage(int cardID){ //1.生成要保存的物流信息的key String key="products:queue:execute"+cardID; if(!template.hasKey(key)) { //2.将各个时期的物流信息存放到redis里面 template.opsForList().leftPush(key, "1商家发货,快递小哥上门取货"); template.opsForList().leftPush(key, "2北京市到赤峰市"); template.opsForList().leftPush(key, "3赤峰市到乌兰察布市"); template.opsForList().leftPush(key, "4乌兰察布市到呼和浩特市"); template.opsForList().leftPush(key, "已签收"); } return "生成物流信息成功"; } //2.更新物流进度 @RequestMapping("/productYes") @ResponseBody public String productSuccess(int cardID) { String key="products:queue:execute"+cardID; String successkey="products:queue:success"+cardID; return template.opsForList().rightPopAndLeftPush(key,successkey); } //3.商家或者物流公司,这个快递还有多少项任务没有完成? @RequestMapping("/post") @ResponseBody public List<String> get(int cardID){ String key="products:queue:execute"+cardID; return template.opsForList().range(key,0,-1); } //4.卖家现在商品到哪里了? @RequestMapping("get") @ResponseBody public List<String> post(int cardID){ String key="products:queue:success"+cardID; return template.opsForList().range(key,0,-1); }set集合的应用场景:
常常用于针对两个集合之间的数据做运算,进行差集,并集,补集的运算
1)利用集合操作可以取出不同圈子之间的交集,以便于非常方便的实现比如说共同关注,共同喜好,二度好友等功能,对上面的所有集合操作,你还可以使用不同的命令选择将结果返回给客户端还是存储到一个新的集合里面
2)利用set集合的唯一性,可以统计网站中的所有独立IP,存储或者获取当天中的所有用户活跃列表

缓存的更新策略:
一)内存淘汰:不需要程序员自己来进行维护,是利用redis的内存淘汰策略,当内存不足的时候redis会自动淘汰掉部分数据,下次查询的时候会自动进行更新,可以自己进行配置,就可以清空一部分空间从而去存储新的数据了,程序员就不需要自己去考虑redis空间不足的问题
1.1)是否可以保证数据一致性呢?在一定程度上是可以的,当内存不足的时候redis一部分的数据给进行淘汰掉了,那么这一部分的数据在redis中不存在了,这个时候如果用户来查询这一部分的数据,因为redis中原有的数据已经被剔除,所以会自动查询数据库,并将数据库中的数据重新写入到redis里面?但是可控性非常差,因为我们不知道redis到底是淘汰掉的哪一部分的数据,甚至在内存充足的时候都不会淘汰
1.2)但是维护成本比较低,不需要程序原来自己进行维护
二)超时剔除:给缓存数据添加TTL时间,到期之后会自动删除缓存,下一次进行查询的时候会自动查询数据库
2.1)一致性:一般
2.2)维护性:一般
三)主动更新:编写业务逻辑,再修改数据库的同时进行更新缓存
2.1)一致性:不错
2.2)维护成本:高
低一致性请求:使用内存淘汰机制,长久不需要进行变化的元素
高一致性请求:使用超时剔除机制,需要进行频繁变动的元素
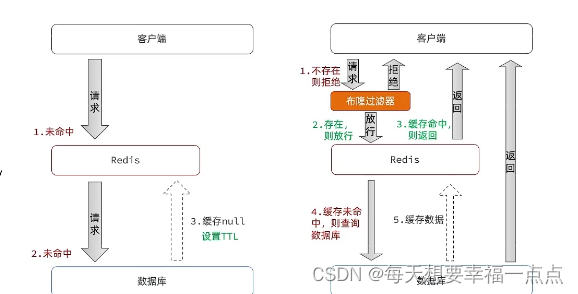
缓存穿透:缓存穿透是指客户端请求的数据在缓存中和数据库都不存在,那么这样的缓存永远也不会生效,那么最终导致这些请求都会被打到数据库里面
例如说根据userID来进行查询对应的用户信息,但是这个userID对应的用户在redis和数据库中都不存在(这个userID就是这个兄弟瞎编的),一旦这个哥们使用多线程循环传入不存在的userID很用可能造成服务大量访问数据库把服务器弄挂了;
解决方案:
1)直接向redis中存储一个空对象,一旦用户传入一个不存在的userID,redis直接存储一个空对象,下次这个哥们再带着这个无效的userID来进行访问,服务器直接返回一个null即可
优点:实现简单方便
缺点:
1.1)当用户传入100个不存在的userID,结果redis把他们都存放到数据库里面,那么会增加内存的开销,缓存了很多的垃圾数据,但是我们可以设置一个TTL来进行解决,来防止用户恶意攻击
1.2)可能会造成短期的不一致问题:比如说A用户传递一个userID=5,但是这个userID在redis和数据库中都不存在,redis直接保存了一个空对象,设置过期时间是10min,但是在10min内B用户进行注册userID恰好是5,但是访问服务redis会直接返回一个null,但是通过控制TTL的时间来进行控制,只要TTL的时间设置的足够段就可以,或者在每一次用户更新数据的时候直接进行更新缓存就可以;
2)使用布隆过滤器:
优点:
1)相比于上面缓存空对象来说,内存占用非常少,不要存储多余的key
2)实现复杂,布隆过滤器实现复杂
3)存在误判的可能











![[前端]深浅拷贝](https://img-blog.csdnimg.cn/img_convert/defc4b61d28b320a8aaf08b189bed257.png)