前言
最近我在研究YOLOv5的改进,一个模型的好坏、改进后效果如何都是需要一系列指标来判断的。这篇就是我将这几天学到的内容做一下总结。
友情提醒:本篇干货较多,建议先 再慢慢看噢!
再慢慢看噢!

 🍀本人YOLOv5源码详解系列:
🍀本人YOLOv5源码详解系列:
YOLOv5源码逐行超详细注释与解读(1)——项目目录结构解析
YOLOv5源码逐行超详细注释与解读(2)——推理部分detect.py
YOLOv5源码逐行超详细注释与解读(3)——训练部分train.py
YOLOv5源码逐行超详细注释与解读(4)——验证部分val(test).py
YOLOv5源码逐行超详细注释与解读(5)——配置文件yolov5s.yaml
YOLOv5源码逐行超详细注释与解读(6)——网络结构(1)yolo.py
YOLOv5源码逐行超详细注释与解读(7)——网络结构(2)common.py
🍀本人YOLOv5入门实践系列:
YOLOv5入门实践(1)——手把手带你环境配置搭建
YOLOv5入门实践(2)——手把手教你利用labelimg标注数据集
YOLOv5入门实践(3)——手把手教你划分自己的数据集
YOLOv5入门实践(4)——手把手教你训练自己的数据集
YOLOv5入门实践(5)——从零开始,手把手教你训练自己的目标检测模型(包含pyqt5界面)
目录
前言
🌟一、性能指标
1.1 混淆矩阵
1.2 Accuracy :准确率(正确率)
1.3 Precision :精确率(查准率)
1.4 Recall :召回率(查全率)
1.5 PR曲线
1.6 AP (Average Precision): 平均精度
1.7 mAP(mean Average Precision):均值平均精度
1.8 F1-score与 F值(F-Measure)
🌟二、训练结果分析
2.1 weights :权重
2.2 confusion_matrix.png : 混淆矩阵
2.3 F1_curve.png :F1曲线
2.4 events.out.tfevents:可视化文件
2.5 hyp.yaml和opt.yaml:超参数
2.6 P_curve.png:准确率和置信度的关系图
2.7 R_curve.png :召回率和置信度的关系图
2.8 PR_curve.png :精确率和召回率的关系图
2.9 results.png :可视化训练结果解析
2.10 results.txt:检测结果文本
2.11 test_batchx :用于测试模型性能的文件夹
2.12 val_batchx_labels:验证集第x轮的实际标签

🌟一、性能指标
1.1 混淆矩阵
混淆矩阵(Confusion Matrix),对分类问题预测结果的总结。使用计数值汇总正确和不正确预测的数量,并按每个类进行细分,显示了分类模型进行预测时会对哪一部分产生混淆。顾名思义,真的很容易混淆╮( ̄﹏ ̄)╭
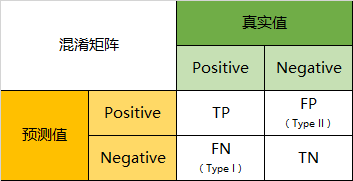
- T(True):最终预测结果正确。
- F(False):最后预测结果错误。
- P(Positive):模型预测其是正样本(目标本身是狗,模型也预测它是狗)。
- N(Negative):模型预测其是负样本(目标本身是狗,但模型预测它是个猫)。
- TP:样本的真实类别是正样本(P),并且模型预测的结果也是正样本(P),预测正确(T)(目标本身是狗,模型也预测它是狗,预测正确)。
- TN:样本的真实类别是负样本(N),并且模型将其预测成为负样本(N),预测正确(T)(目标本身不是狗,模型预测它不是狗,是个其他的东西,预测正确)。
- FP:样本的真实类别是负样本(N),但是模型将其预测成为正样本(P),预测错误(F)(目标本身不是狗,模型预测它是狗,预测错误)。
- FN:样本的真实类别是正样本(P),但是模型将其预测成为负样本(N),预测错误(F)(目标本身是狗,模型预测它不是狗,是个其他的东西,预测错误)。
1.2 Accuracy :准确率(正确率)
含义:所有预测中正确的百分比
公式:
举个栗子:现有100只动物,分别是30只猫、50只狗和20只猪。经过模型检测之后预测正确的是20只猫、30只狗和10只猪,那么准确率(Accuracy)=(20+30+10)/100 = 66%。
注:通常来说正确率越高,模型越好。
1.3 Precision :精确率(查准率)
含义:指模型识别出的正确正样本数占所有被识别为正样本的样本数的比例
公式:
举个栗子:现有100只动物,分别是30只猫、50只狗和20只猪。经过模型检测之后结果表示有35只猫,但它认为的35只猫里面有2只狗和3只猪,所以猫预测对的只有30只,那么精确率Precision(猫)= 30/35 = 85.7%
1.4 Recall :召回率(查全率)
含义:指模型识别出的正样本数占真实正样本数的比例
公式:
举个栗子:现有100只动物,分别是30只猫、50只狗和20只猪。经过模型检测之后结果表示只有25只猫,或许它把另外5只猫错认成狗和猪了吧,,那么召回率Recall(猫)= 25/30 = 83%
注:召回率越高,实际为正样本(P)被预测出来的概率越高,类似于“宁可错杀一千,绝不放过一个”。
在检测过程中,我们当然希望检索结果Precision越高越好,同时Recall也越高越好,但事实上这两者是矛盾的。
举个栗子:还是看上面的动物,比如极端情况下,模型只检测出一只猫,且是正确的,那么Precision就是100%,但是Recall就很低;但是如果我们为了找全猫猫把所有结果都返回,那么Recall是100%,但是Precision当然就会很低。因此在不同的场合中需要判断希望Precision比较高或是Recall比较高。如果是做实验研究,可以绘制Precision-Recall曲线来帮助分析。
1.5 PR曲线
含义:P代表的是precision(精准率),R代表的是recall(召回率),其代表的是精准率与召回率的关系,一般情况下,将recall设置为横坐标,precision设置为纵坐标。
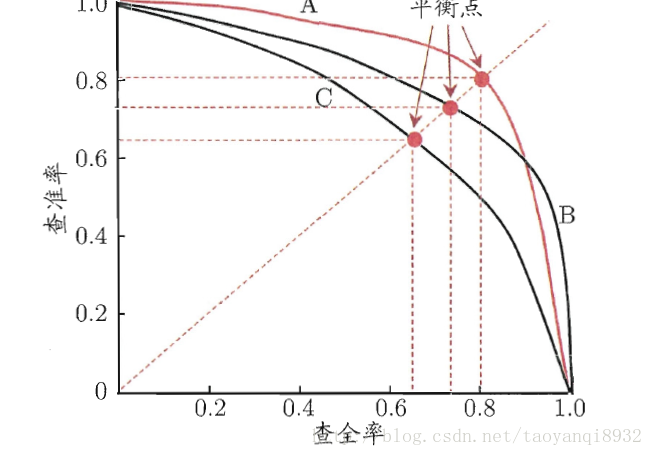
在众多模型对数据进行学习后,如果其中一个模型的PR曲线A完全包住另一个模型B的PR曲线,则可断言A的性能优于B。
但是A和B发生交叉,那性能该如何判断呢?
我们可以根据曲线下方的面积大小来进行比较,但更常用的是平衡点F1。平衡点(BEP)是P=R时的取值(斜率为1),F1值越大,我们可以认为该学习器的性能较好。F1的计算如下所示:
F1 = 2 * P * R /( P + R )
1.6 AP (Average Precision): 平均精度
含义:PR曲线下面的面积,通常来说一个越好的模型,AP值越高
1.7 mAP(mean Average Precision):均值平均精度
含义:即各个类别AP的平均值
用于表达多类标签预测的性能,如AP一样,mAP越高,性能越好。
- mAP@.5
- 当IoU为0.5时的mAP。
- mAP@.5 : .95
- 当IoU为range(0.5 : 0.95 : 0.05)时的mAP的平均数。
1.8 F1-score与 F值(F-Measure)
F1-score含义:是分类问题的一个衡量指标。一些多分类问题的机器学习竞赛,常常将F1-score作为最终测评的方法。它是精确率和召回率的调和平均数,最大为1,最小为0。
公式:
F值(F-Measure)含义:有时候我们对精确率和召回率并不是一视同仁,比如在医疗领域,我们不希望遗漏掉任何一位患者,所以应该更加重视召回率。我们用一个参数β来度量两者之间的关系,得到以下式子,是对P和R加权调和均值(不一定是平均),即F值(F-Measure)或称Fβ值:
公式: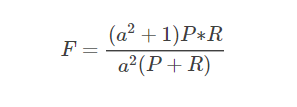
🌟二、训练结果分析
我们每次训练后,在runs/train文件夹下出现的一系列文件,如下图所示:
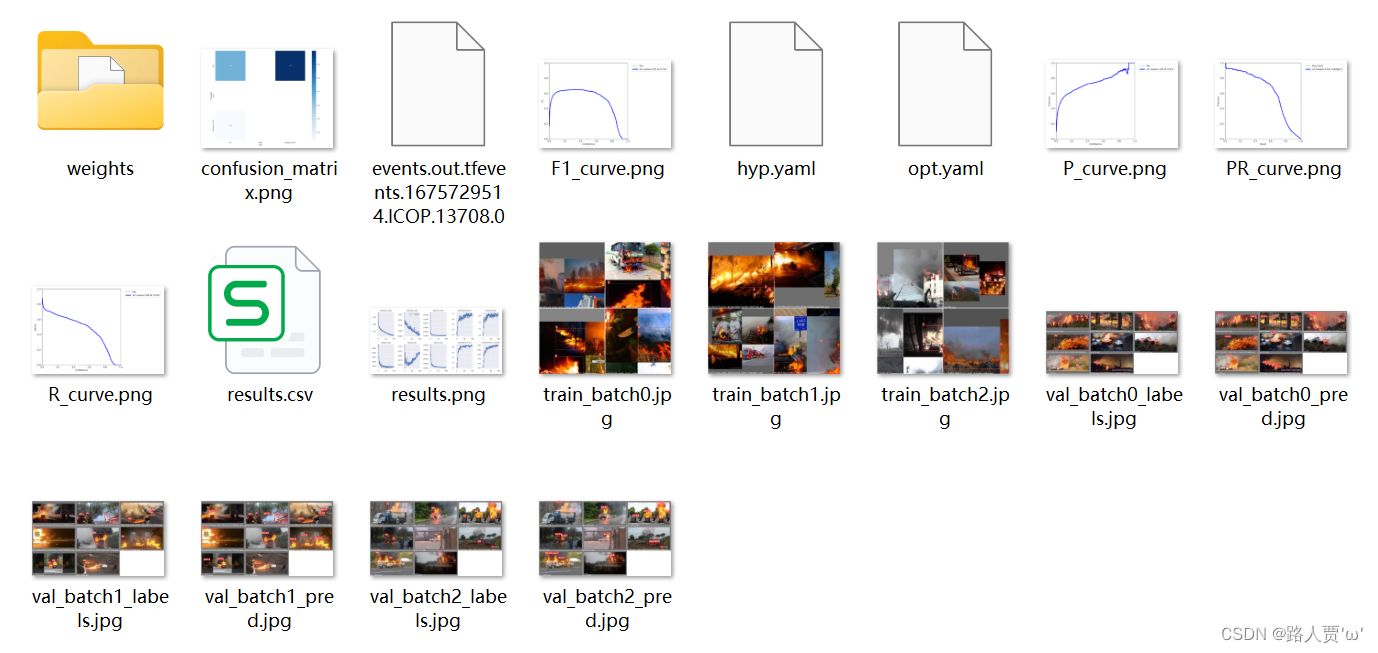
下面我们就逐一分析一下它们到底是干什么用的吧~
(涉及到理论知识的,大家往上滑动鼠标既可~)
2.1 weights :权重

这里存放的就是我们训练好的权重:
- best.pt:保存的是训练过程中在验证集上表现最好的模型权重。在训练过程中,每个epoch结束后都会对验证集进行一次评估,并记录下表现最好的模型的权重。这个文件通常用于推理和部署阶段。
- last.pt:保存的是最后一次训练迭代结束后的模型权重。这个文件通常用于继续训练模型,因为它包含了最后一次训练迭代结束时的模型权重,可以继续从上一次训练结束的地方继续训练模型。
使用上的区别是:当需要在之前的训练基础上继续训练时,应该使用last.pt作为起点进行训练;当需要使用训练后的模型进行推理和部署时,应该使用best.pt。
2.2 confusion_matrix.png : 混淆矩阵
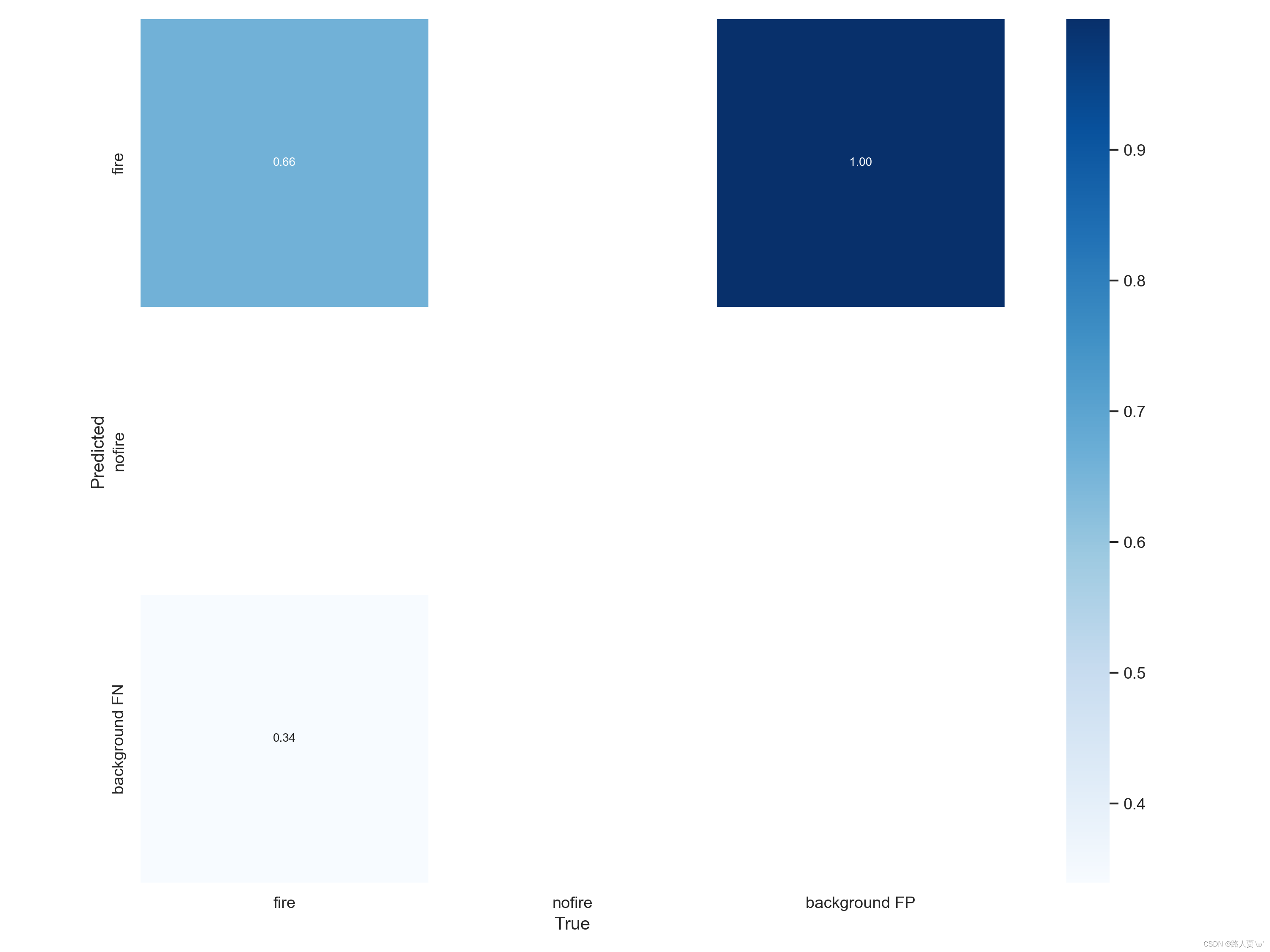
在YOLOv5的训练结果中,confusion_matrix.png文件是一个混淆矩阵的可视化图像,用于展示模型在不同类别上的分类效果(我这个就是一个fire的单类,所以看得不明显)。
混淆矩阵是一个n×n的矩阵,其中n为分类数目,矩阵的每一行代表一个真实类别,每一列代表一个预测类别,矩阵中的每一个元素表示真实类别为行对应的类别,而预测类别为列对应的类别的样本数。
2.3 F1_curve.png :F1曲线
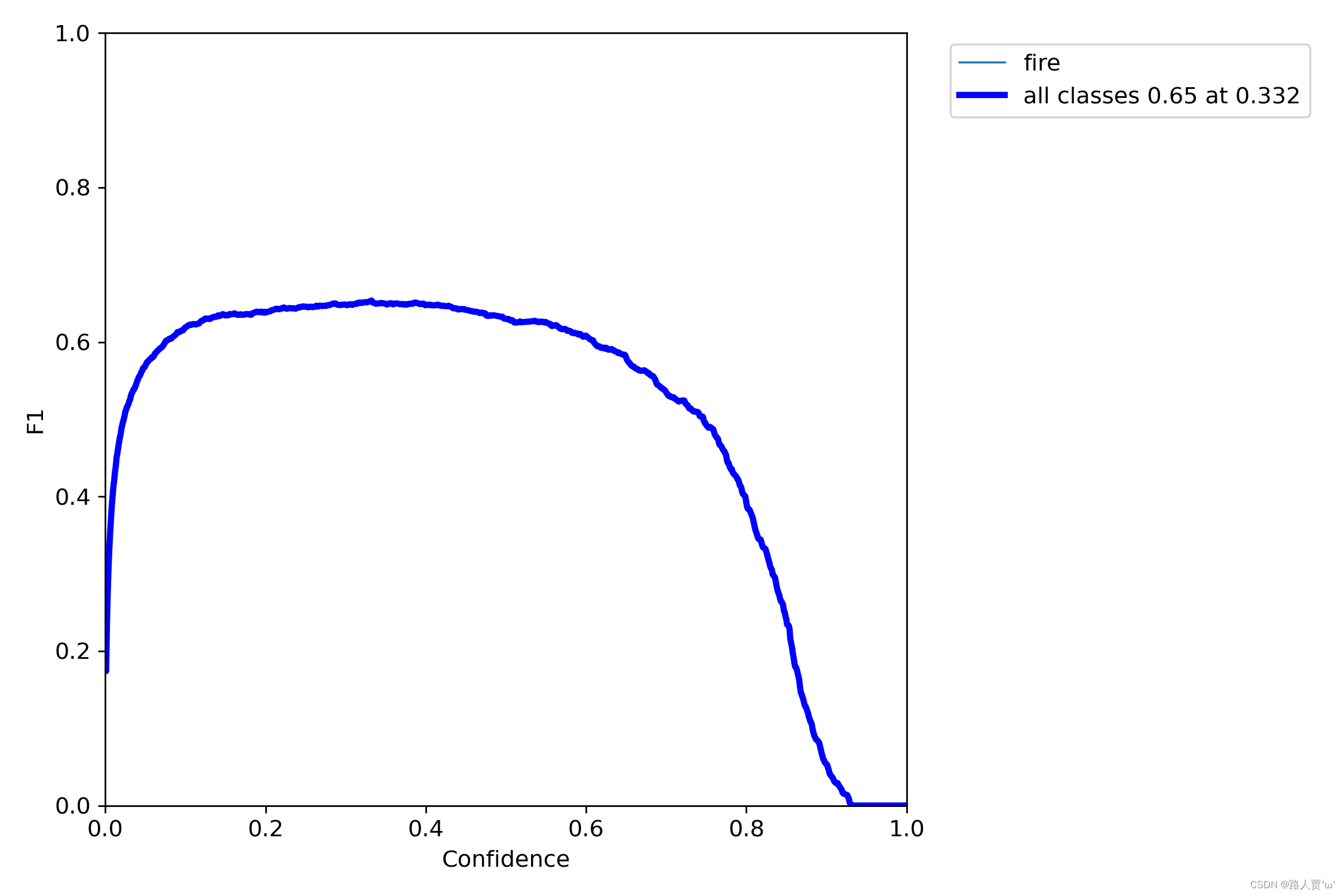
F1_curve是F1-score与置信度之间的关系:F1-score是分类问题的一个衡量指标,可以用于评估模型在检测出所有目标的情况下的精确性和完整性,是精确率precision和召回率recall的调和平均数,介于0,1之间,1是最好,0是最差。
在 YOLOv5 的训练过程中,每个训练轮次结束后,会计算出模型在验证集上的 F1-score 值,并将这些值记录下来。F1_curve.png 就是将这些 F1-score 值绘制成的折线图,横轴表示置信度,纵轴表示 F1-score 值。通过观察 F1_curve.png,可以了解模型在训练过程中 F1-score 值的变化情况,以及模型的训练效果。
2.4 events.out.tfevents:可视化文件
events.out.tfevents:主要是保存训练阶段和评估阶段得loss值的,不需要这次训练信息的话可以删
(其实这个我也不太清楚,也没找到讲解,以上是@-FIONASENIOR!!PEI这位大佬以及其评论区的解读,如有不对请指正!)
2.5 hyp.yaml和opt.yaml:超参数
- hyp.yaml文件
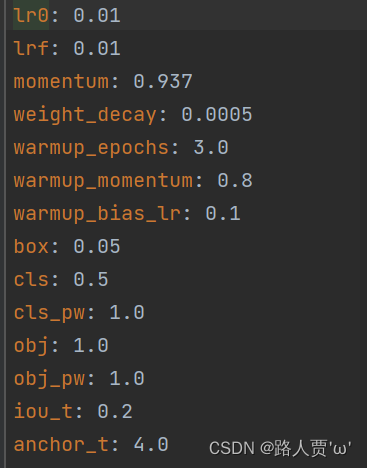
包含了训练超参数的设置,包括学习率、动量、权重衰减系数、数据增强等参数。这些超参数的设置直接影响着模型的训练效果,通过对hyp.yaml文件进行调整,可以优化模型的性能。
- opt.yaml文件
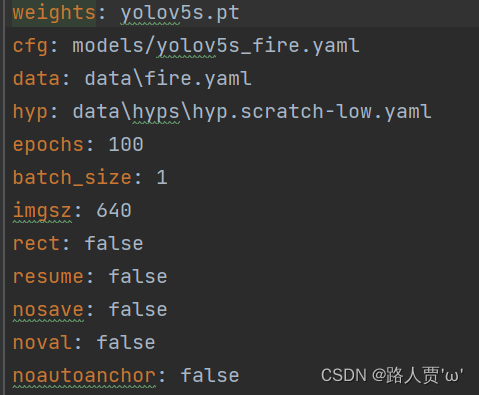
包含了train.py中间的参数的设置,如权重选择、配置文件选择、模型保存路径、训练轮次、批次大小等。这些设置会影响训练的整个流程,通过对opt.yaml文件进行调整,可以更好地控制训练过程。
在训练过程中,YOLOv5会读取hyp.yaml和opt.yaml文件中的设置,并根据这些设置进行训练。在训练完成后,这些文件也可以被用于模型的测试和部署。
2.6 P_curve.png:准确率和置信度的关系图
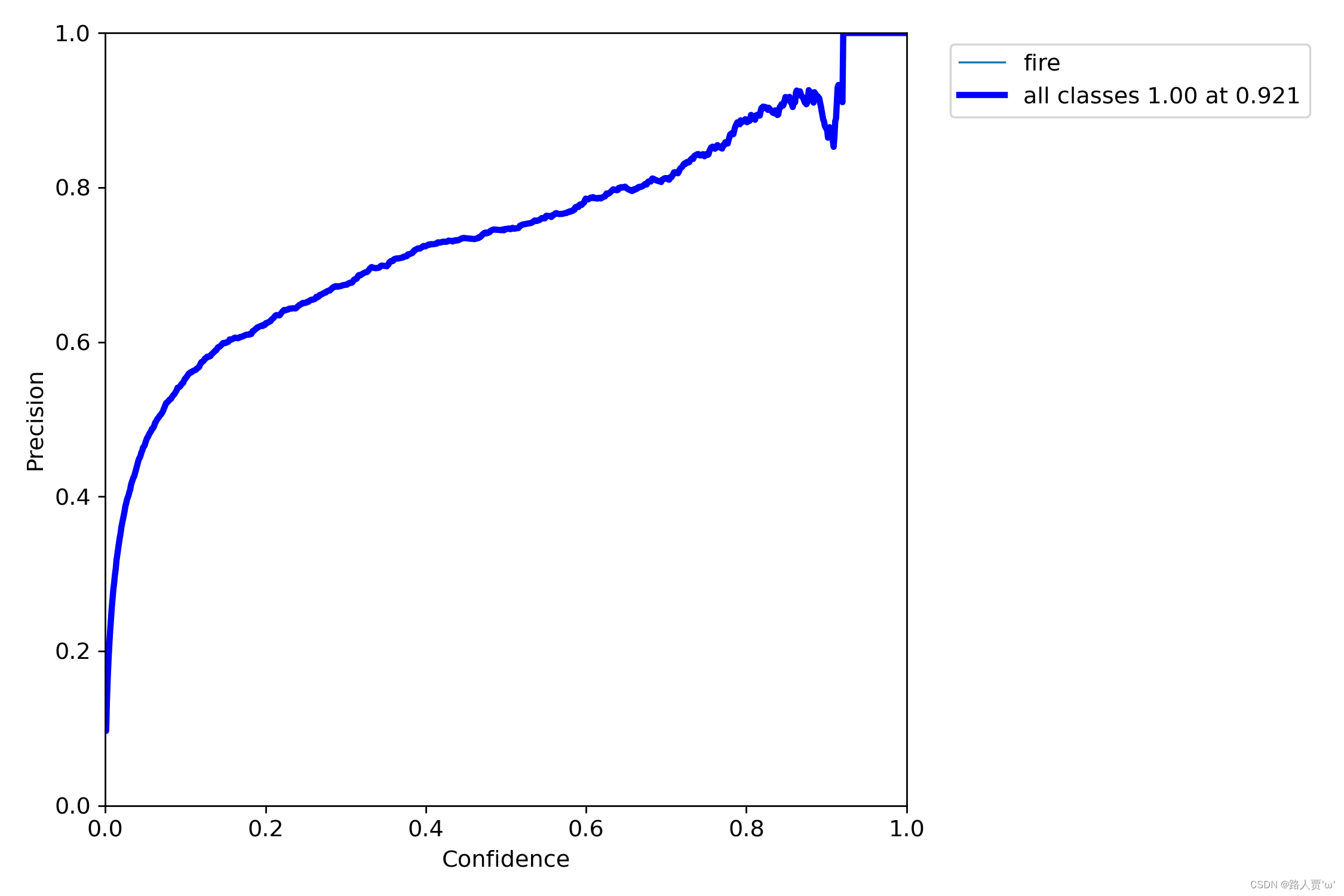
P_curve.png描述随着置信度阈值的增加,P值的变化;置信度设为某一数值的时候,各个类别识别的准确率。
在目标检测中,置信度是指检测器对于每个检测框预测目标存在的概率。在YOLOv5的训练过程中,每个检测框的置信度都会被计算出来。P_curve.png将检测框的置信度从小到大排序,然后计算出不同置信度下的精度(Precision)值,最后将这些值绘制成一条曲线。
2.7 R_curve.png :召回率和置信度的关系图
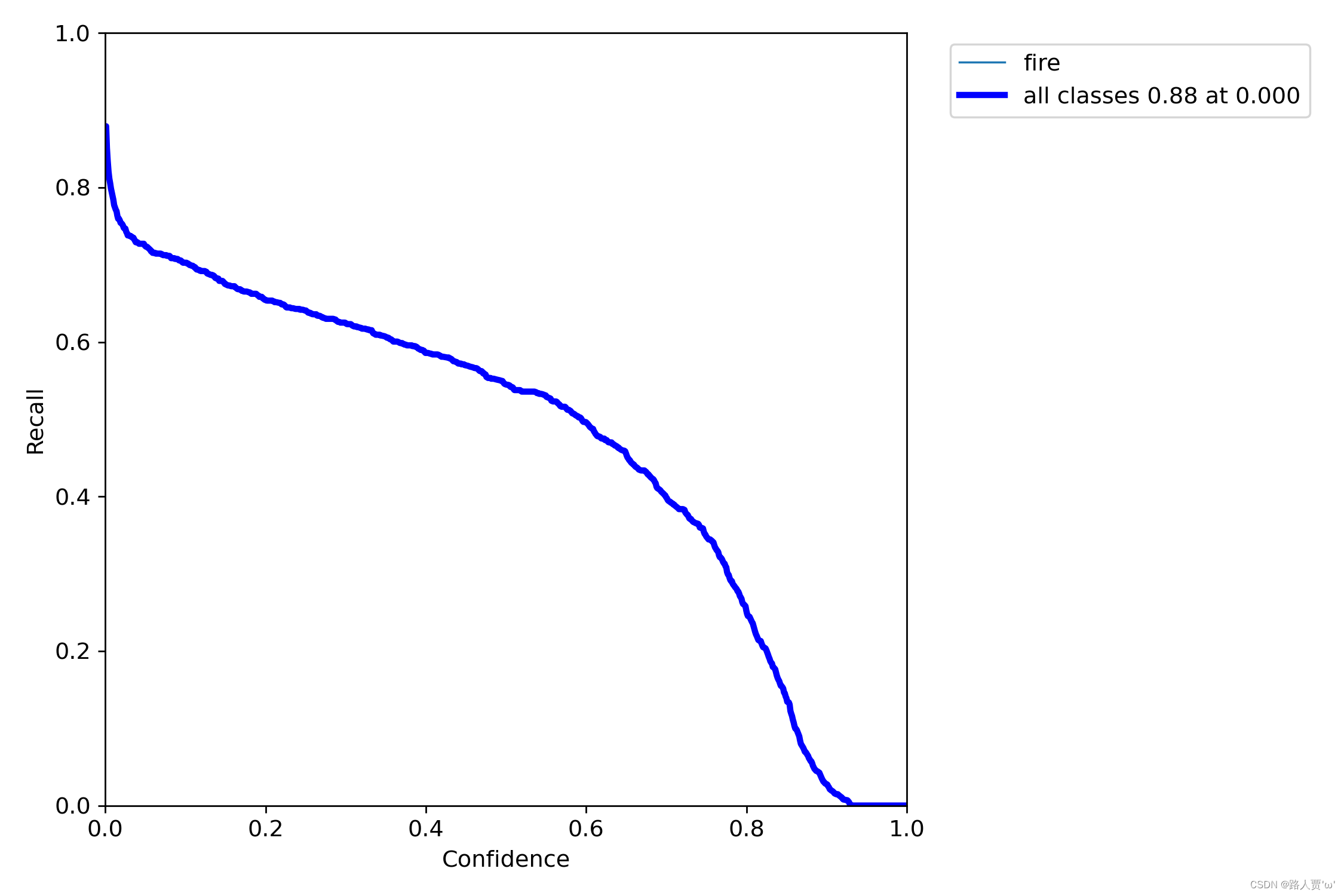
R_curve.png是用于衡量模型在不同召回率下的精确度表现。在该图表中,X轴表示召回率,范围从0到1,Y轴表示精确度,范围也是从0到1。
在目标检测中,召回率指的是模型正确检测出目标的检测框数与所有目标的数量的比值。在YOLOv7的训练过程中,每个检测框的置信度都会被计算出来。R_curve.png将检测框的置信度从小到大排序,然后计算出不同置信度下的召回率值,最后将这些值绘制成一条曲线。
2.8 PR_curve.png :精确率和召回率的关系图
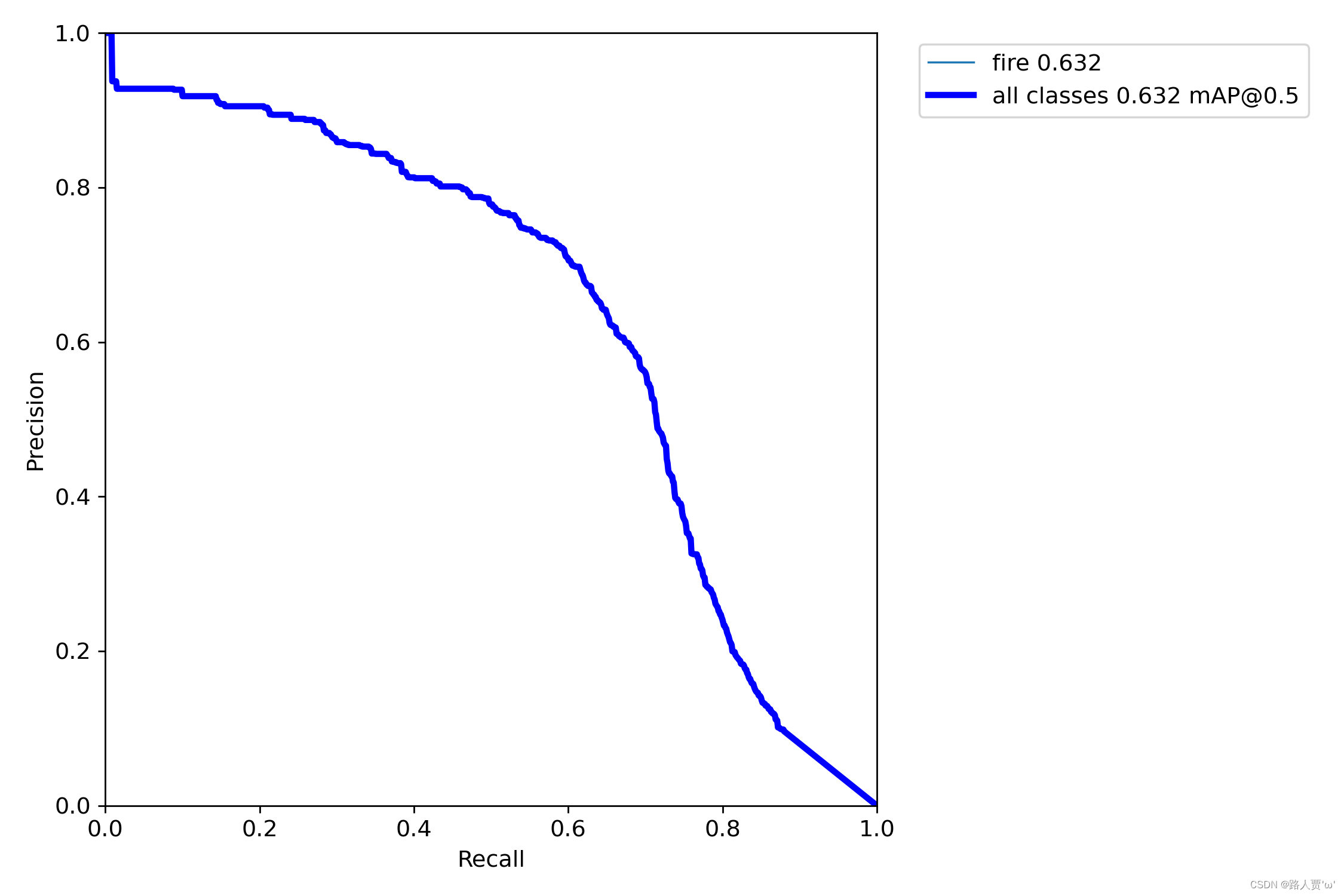
PR_curve.png是描述精度和召回率的关系图。精度越高,召回率越低,理想情况是(1,1)点,即在准确度很高的情况下,尽可能检测到全部的类别。二者围成的面积就是mAP值,mAP面积越接近于1,效果越好。
在目标检测中,精确率指的是模型正确检测出目标的检测框数与所有检测框数的比值,而召回率指的是模型正确检测出目标的检测框数与所有目标的数量的比值。在YOLOv5的训练过程中,每个检测框的置信度都会被计算出来。PR_curve.png将检测框的置信度从小到大排序,然后计算出不同置信度下的精确率和召回率值,最后将这些值绘制成一条曲线。
2.9 results.png :可视化训练结果解析
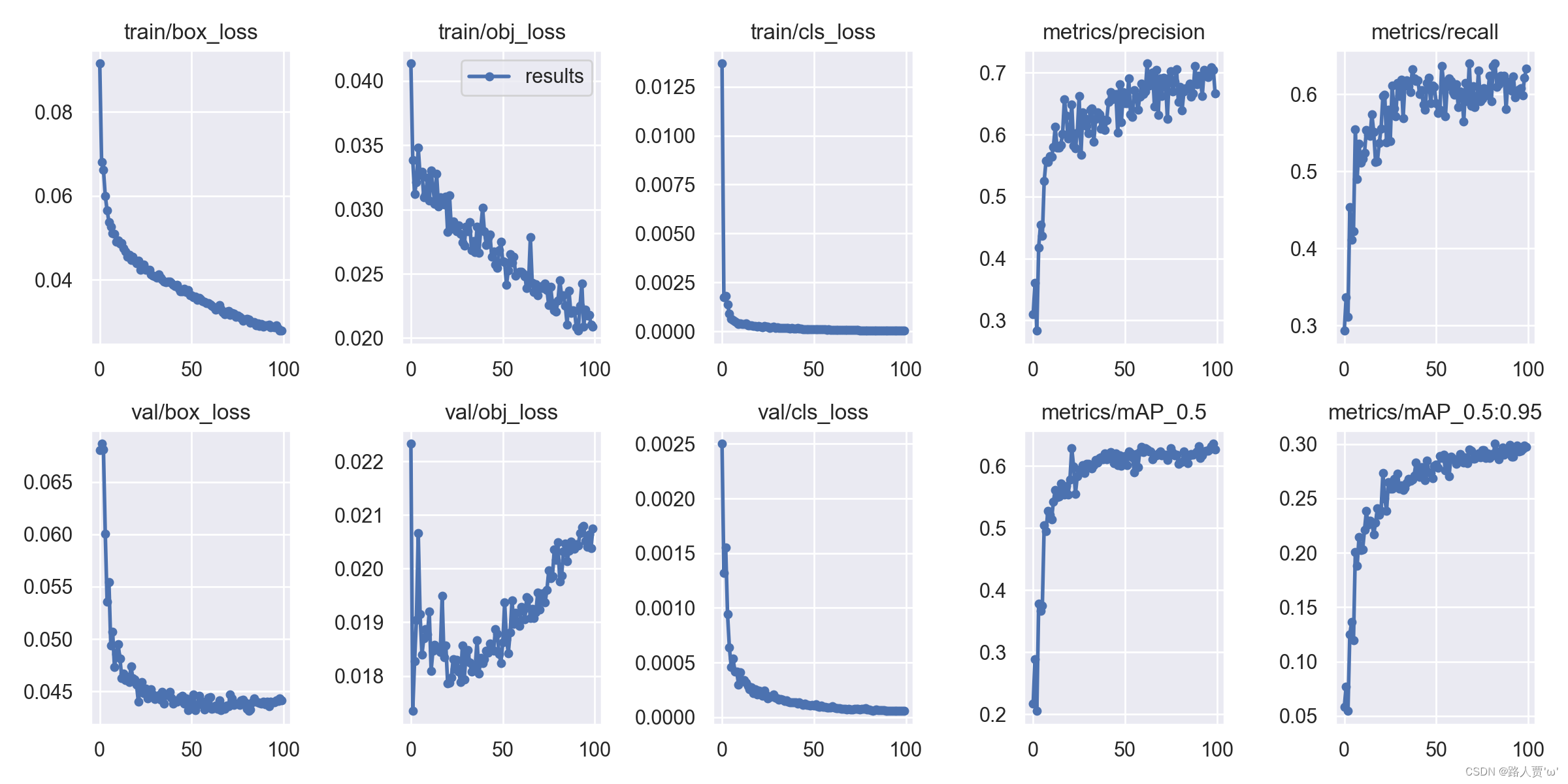
- 定位损失box_loss:YOLO V5使用 GIOU Loss作为bounding box的损失,Box推测为GIoU损失函数均值,越小方框越准
- 置信度损失obj_loss:推测为目标检测loss均值,越小目标检测越准
- 分类损失cls_loss:推测为分类loss均值,越小分类越准
- val/box_loss: 验证集bounding box损失
- val/obj_loss:验证集目标检测loss均值
- val/cls_loss:验证集分类loss均值,我这个项目只有fire这一类,所以为0
- mAP@0.5:0.95:表示在不同的IOU阈值(从0.5到0.95,步长为0.05)(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均mAP
- mAP@0.5:表示阈值大于0.5的平均mAP
一般训练结果主要观察精度和召回率波动情况(波动不是很大则训练效果较好),然后观察mAP@0.5 & mAP@0.5:0.95 评价训练结果。
2.10 results.txt:检测结果文本
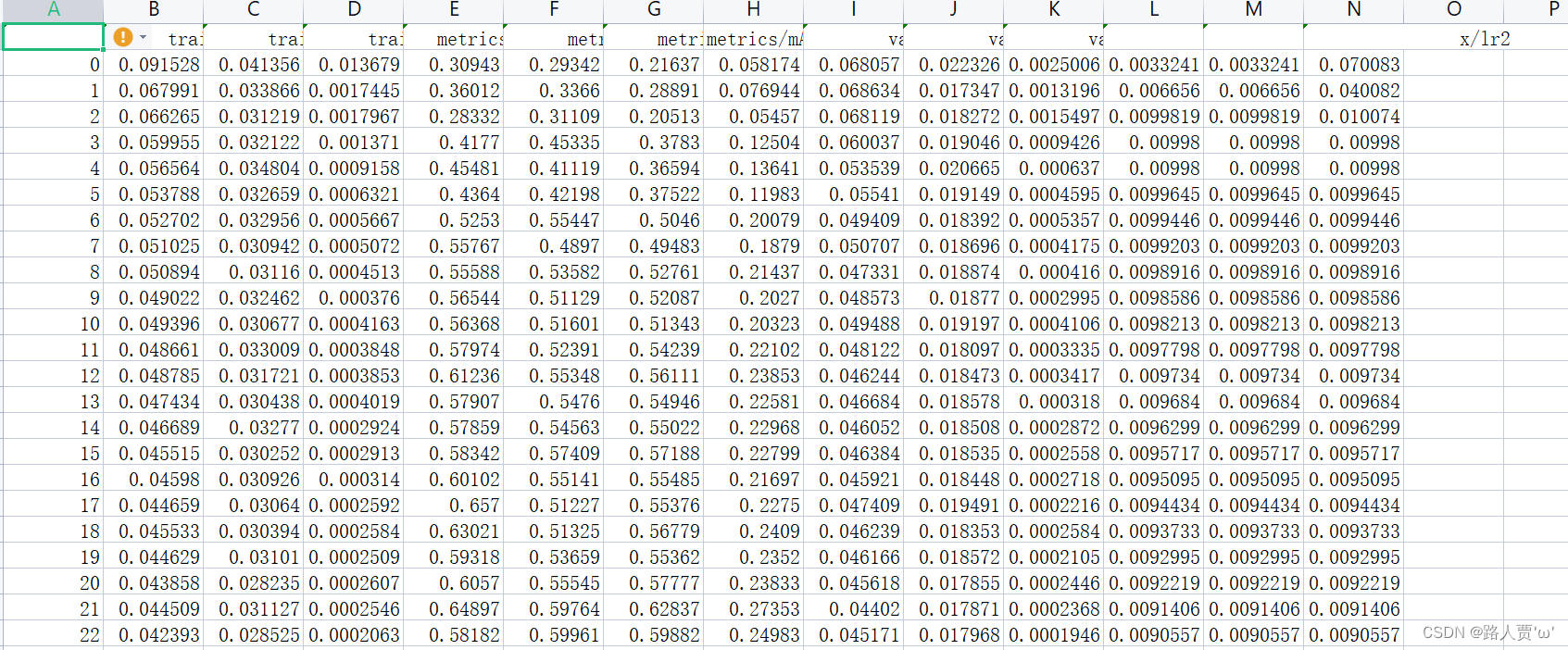
results.txt是YOLOv5模型在测试集上的检测结果文本文件。
在目标检测任务中,我们需要对测试集中的图像进行目标检测,并将检测结果输出。results.txt就是将模型在测试集上的检测结果保存在文本文件中得到的文件。对于每张测试图像,results.txt会记录检测出的目标框的位置坐标、目标类别、以及置信度分数等信息。
每行含义分别是:训练次数、GPU消耗、训练集边界框损失、训练集目标检测损失、训练集分类损失、训练集总损失、targets目标、输入图片大小、Precision、Recall、mAP@.5、mAP@.5:.95、验证集边界框损失、验证集目标检测损失、验证机分类损失
2.11 test_batchx :用于测试模型性能的文件夹

test_batchx是YOLOv5模型用于保存测试集中的图像和标签信息的文件夹,其中x表示测试集的批次编号。
在test_batchx文件夹中,每个图像都有一个对应的标签文件,用于描述图像中目标的位置和类别信息。测试时,将test_batchx文件夹中的图像输入到模型中进行目标检测,然后将检测结果与标签进行比较,计算模型的性能。
2.12 val_batchx_labels:验证集第x轮的实际标签

val_batchx_labels 是指测试集中一个 batch 的真实标签和框的信息,其中 x 为 batch 的编号。这些信息通常包括每个样本的分类标签和相应的边界框坐标(bounding box coordinates)。
具体来说,val_batchx_labels 是一个列表(list)对象,其元素个数等于 batch size。每个元素是一个元组(tuple),长度为 2。第 1 个元素是大小为 N 的 tensor,表示该 batch 中 N 个目标的分类标签;第 2 个元素也是大小为 N 的 tensor,表示该 batch 中 N 个目标的 bounding box 坐标。
完结~撒花✿✿ヽ(°▽°)ノ✿
本文参考(感谢大佬!):
YOLOv5训练结果性能分析__tt丫的博客-CSDN博客
yolov7模型训练结果分析以及如何评估yolov7模型训练的效果_把爱留给SCI的博客-CSDN博客