目录
1.任务调度
2.Elastic Job
3.springboot集成Elastic Job
1.任务调度
什么是任务调度?
任务调度就是指系统为了自动地完成特定任务,在指定的时刻去执行任务的过程,其目的是为了让系统自动且精确地完成任务从而解放人力资源。
如:电商平台在指定地时刻开启抢购活动,而不是需要人力开启;系统在指定的时刻自动发送短信提醒客户;系统在每月的某个时刻进行订单、财务数据等相关数据的整理。
那什么是分布式任务调度?
分布式是一种系统架构,指同一个系统下的不同子服务,分布于不同的机器上,服务之间通过网络交互完成整个系统的业务处理。
分布式调度就是在分布式系统架构下,一个服务往往会拥有多个实例,在这种分布式架构下的任务调度过程。
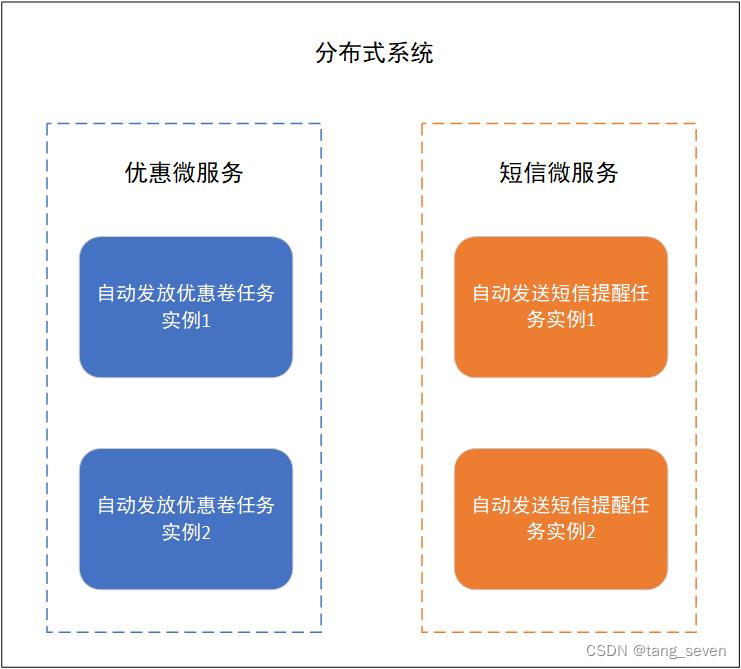
如上图所示,同一个分布式架构系统下由不同的微服务构成,每一个微服务都拥有多个实例,在此情况下共同完成任务调度。
分布式任务调度的目的就是并向地进行任务调度,提高任务的调度处理能力;有效地分配资源,实现任务处理能力随资源配备弹性伸缩;保证任务的高可用。多个实例共同完成任务调度,即使一个实例挂了,还能由其他实例继续完成;通过zookeeper选举leader的方式,避免任务重复执行。
2.Elastic Job
Elastic Job 基于 Quartz 和 Curator 开发,是面向互联网生态和海量任务的分布式调度解决方案,由两个相互独立的子项目 ElasticJob-Lite 和 ElasticJob-Cloud 组成。
它通过弹性调度、资源管控、以及作业治理的功能,打造一个适用于互联网场景的分布式调度解决方案,并通过开放的架构设计,提供多元化的作业生态。 它的各个产品使用统一的作业 API,开发者仅需一次开发,即可随意部署。
其中,ElasticJob-Lite 架构如下:

APP即应用程序,内部包含了执行业务逻辑和Elastic-job-lite组件。
Elastic-job-lite:定位为轻量级的无中心化解决方案,负责任务的调度以及产生日志和任务调度记录。无中心化即没有调度中心,各作业节点都是平等的,通过zookeeper分布式协调。
Registery:注册中心,以zookeeper作为Elastic-job-lite的注册中心组件,通过执行任务实例选举的方式保证任务不重复执行。
Console:运维平台,可以查看日志文件等相关信息。
简单来说,就是我们在实例中编写好任务执行逻辑,在指定的时刻告诉elastic job框架,elastic job框架通过配置好的作业分片信息,进行任务调度;elastic job框架通过zookeeper找到该任务对应的命名空间等信息,通过选举leader的形式,选择执行的实例,最后让实例执行自动任务。
我们可以通过 Elastic Job 实现分布式的任务调度,有效地分配资源,达到提高任务执行效率,避免任务重复执行等目的。
3.springboot集成Elastic Job
使用elastic job环境要求如下:

在springboot项目中导入依赖:
<dependencies>
<!--springboot相关依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<!--elastic-job-lite-->
<dependency>
<groupId>com.dangdang</groupId>
<artifactId>elastic-job-lite-spring</artifactId>
<version>2.1.5</version>
</dependency>
<!--zookeeper curator-->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>2.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>2.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-client</artifactId>
<version>2.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.5</version>
</dependency>
<!--mysql-druid-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.37</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
<!-- mybatis-plus启动器-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.1</version>
</dependency>
</dependencies>(1)配置注册中心:
import com.dangdang.ddframe.job.reg.base.CoordinatorRegistryCenter;
import com.dangdang.ddframe.job.reg.zookeeper.ZookeeperConfiguration;
import com.dangdang.ddframe.job.reg.zookeeper.ZookeeperRegistryCenter;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class JobRegistryCenterConfig {
//zookeeper端口
private static final int ZOOKEEPER_PORT = 2181;
private static final String JOB_NAMESPACE = "elastic-job-example-java";
@Bean(initMethod = "init")
public CoordinatorRegistryCenter setupRegistryCenter(){
//zk配置
ZookeeperConfiguration zookeeper = new ZookeeperConfiguration("localhost:" + ZOOKEEPER_PORT, JOB_NAMESPACE);
zookeeper.setSessionTimeoutMilliseconds(100);
//创建注册中心
return new ZookeeperRegistryCenter(zookeeper);
}
}(2)然后,我们准备一些数据:
@TableName(value ="FileCustom")
@Data
@AllArgsConstructor
@NoArgsConstructor
public class FileCustom implements Serializable {
@TableId
private Integer id;
private String name;
private String type;
private String content;
private boolean backup;
@TableField(exist = false)
private static final long serialVersionUID = 1L;
} 
业务类(基于mybatis plus实现):主要实现业务,根据文件类型查询所有未备份文件
@Service
public class FileCustomServiceImpl extends ServiceImpl<FileCustomMapper, FileCustom>
implements FileCustomService {
@Resource
private FileCustomMapper filecustomMapper;
@Override
public List<FileCustom> getFileList(String fileType, int size) {
//分页参数
Page<FileCustom> page = Page.of(1,size);
QueryWrapper<FileCustom> queryWrapper = new QueryWrapper<FileCustom>()
.eq("type", fileType)
.eq("backup",false);
filecustomMapper.selectPage(page,queryWrapper);
return page.getRecords();
}
}关于为什么是根据文件类型查询:
系统分布式地部署在两台服务器上,各有一个实例执行文件自动备份任务。那么可以将作业分为2片,每台服务器上的实例执行两片,每一片作业分别处理text、image类型的文件。
所以,对任务合理地分片化(一般分片项设置大于服务器的数量,最好是服务器数量的倍数)可以最大限度地提升执行作业的吞吐量。
(3)编写elastic job任务执行逻辑:
SimpleJob形式:简单实现,未经过任何封装。
import com.dangdang.ddframe.job.api.ShardingContext;
import com.dangdang.ddframe.job.api.simple.SimpleJob;
import com.seven.scheduler.entities.FileCustom;
import com.seven.scheduler.service.FileCustomService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.util.List;
/**
* 文件备份任务
*/
@Slf4j
@Component
public class FileBackupJob implements SimpleJob {
@Resource
private FileCustomService filecustomService;
//每次任务执行备份文件数量
private final int FETCH_SIZE = 1;
@Override
public void execute(ShardingContext shardingContext) {
//获取分片参数
//此处分片参数为文件类型,根据类型对任务进行分片
//"0=txt,1=jpg"
String jobParameter = shardingContext.getShardingParameter();
log.info("作业编号:"+shardingContext.getShardingItem()+",处理"+jobParameter+"类型数据");
//获取文件
List<FileCustom> list = filecustomService.getFileList(jobParameter,FETCH_SIZE);
//备份文件
backupFiles(list);
}
//文件备份
public void backupFiles(List<FileCustom> list){
list.forEach(fileCustom -> {
fileCustom.setBackup(true);
filecustomService.updateById(fileCustom);
log.info(fileCustom.getName()+"进行备份");
});
}
}DataflowJob形式,用于处理数据流。
可通过DataflowJobConfiguration配置是否流式处理:流式处理数据只有fetchData方法的返回值为null或集合长度为空时,作业才停止抓取,否则作业将一直运行下去; 非流式处理数据则只会在每次作业执行过程中执行一次fetchData方法和processData方法,随即完成本次作业。
import com.dangdang.ddframe.job.api.ShardingContext;
import com.dangdang.ddframe.job.api.dataflow.DataflowJob;
import com.seven.scheduler.entities.FileCustom;
import com.seven.scheduler.service.FileCustomService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.util.List;
@Slf4j
@Component
public class FileBackupDataFlowJob implements DataflowJob<FileCustom> {
@Resource
private FileCustomService fileCustomService;
//抓取数据
@Override
public List<FileCustom> fetchData(ShardingContext shardingContext) {
//获取分片参数
//此处分片参数为文件类型,根据类型对任务进行分片
//"0=txt,1=jpg,2=png,3=video"
String jobParameter = shardingContext.getShardingParameter();
log.info("作业编号:"+shardingContext.getShardingItem()+",处理"+jobParameter+"类型数据");
//获取文件
return fileCustomService.getFileList(jobParameter,1);
}
//处理数据
@Override
public void processData(ShardingContext shardingContext, List<FileCustom> data) {
backupFiles(data);
}
//文件备份
public void backupFiles(List<FileCustom> list){
list.forEach(fileCustom -> {
fileCustom.setBackup(true);
fileCustomService.updateById(fileCustom);
log.info(fileCustom.getName()+"进行备份");
});
}
}从以上两种方式中选取一种类型进行业务代码(都是获取数据,处理数据)的编写。
(4)定义任务调度类,配置作业分片等信息:
import com.dangdang.ddframe.job.api.ElasticJob;
import com.dangdang.ddframe.job.config.JobCoreConfiguration;
import com.dangdang.ddframe.job.config.simple.SimpleJobConfiguration;
import com.dangdang.ddframe.job.lite.config.LiteJobConfiguration;
import com.dangdang.ddframe.job.lite.spring.api.SpringJobScheduler;
import com.dangdang.ddframe.job.reg.base.CoordinatorRegistryCenter;
import com.seven.scheduler.job.FileBackupDataFlowJob;
import com.seven.scheduler.job.FileBackupJob;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.annotation.Resource;
@Configuration
@Slf4j
public class ElasticJobConfig {
@Resource
private FileBackupJob fileBackupJob;
@Resource
private FileBackupDataFlowJob fileBackupDataFlowJob;
@Resource
private CoordinatorRegistryCenter registryCenter;
//数据库数据源
@Resource
private DataSource dataSource;
@Bean(initMethod = "init")
public SpringJobScheduler initSimpleElasticJob(){
//生成日志表
JobEventRdbConfiguration jobEventRdbConfiguration = new JobEventRdbConfiguration(dataSource);
return new SpringJobScheduler(fileBackupJob,registryCenter,
createJobConfiguration(fileBackupJob.getClass(),"0 20 17 * * ?",
2,"0=txt,1=jpg"),jobEventRdbConfiguration);
}
private LiteJobConfiguration createJobConfiguration(final Class<? extends ElasticJob> jobClass,
final String cron, final int shardingTotalCount,
final String shardingItemParameters){
JobCoreConfiguration.Builder builder = JobCoreConfiguration.newBuilder(jobClass.getName(), cron, shardingTotalCount);
if (!StringUtils.isEmpty(shardingItemParameters)){
builder.shardingItemParameters(shardingItemParameters);
}
JobCoreConfiguration jobCoreConfiguration = builder.build();
//simpleJob形式
SimpleJobConfiguration simpleJobConfiguration = new SimpleJobConfiguration(jobCoreConfiguration,jobClass.getCanonicalName());
return LiteJobConfiguration.newBuilder(simpleJobConfiguration).overwrite(true).build();
//DataflowJob形式,最后的参数true即为开启流式抓取
// DataflowJobConfiguration dataflowJobConfiguration =
// new DataflowJobConfiguration(jobCoreConfiguration, jobClass.getCanonicalName(), true);
// return LiteJobConfiguration.newBuilder(dataflowJobConfiguration).overwrite(true).build();
}
}上述代码中,把任务分为了两片,0号作业负责备份txt类型数据,1号作业负责备份jpg类型数据;该任务在每天的17:20执行(具体参考cron表达式)
(选用DataflowJob形式则把 fileBackupJob 都换成fileBackupDataFlowJob, simpleJobConfiguration换为DataflowJobConfiguration即可。)
(5)我们就可以执行了,分贝启动两个进程,对数据进行处理,执行效果如下:


可以看到,17:20自动执行了任务。
作业0处理了txt文件,作业1处理了jpg文件;两个进程分别处理了各自的文件,实现了资源的合理分配,同时避免了对数据的重复处理。