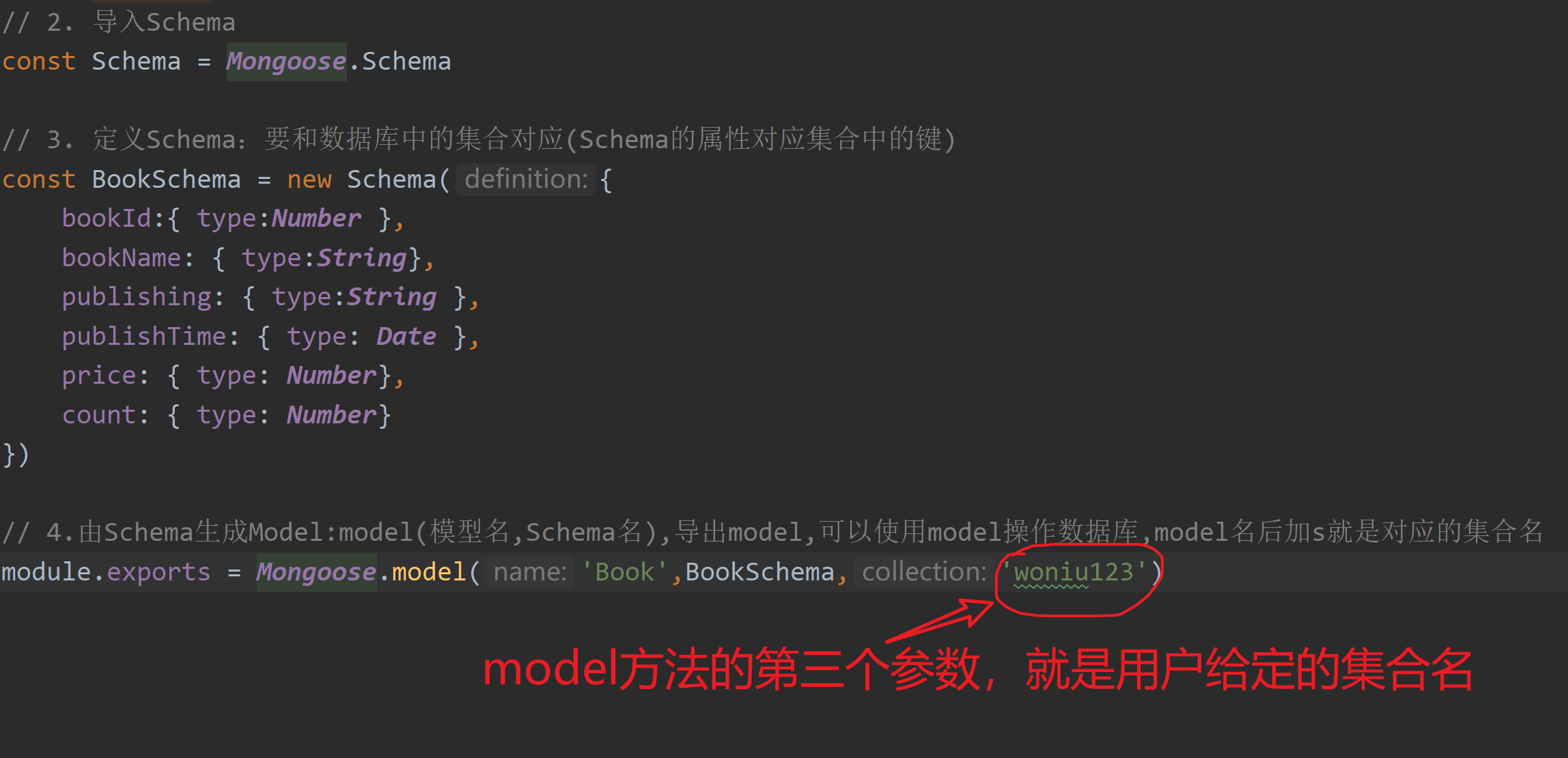
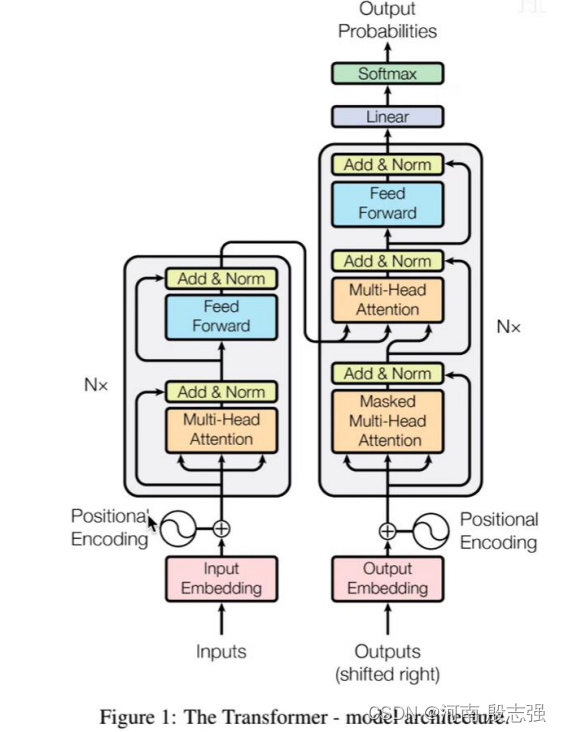
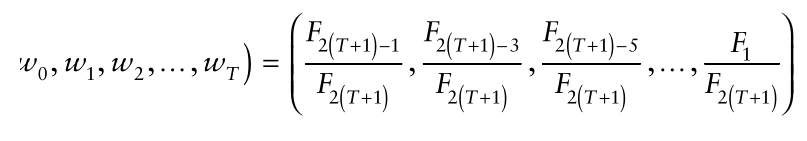1. 结构
从宏观的视角开始
首先将这个模型看成是一个黑箱操作。在机器翻译中,就是输入一种语言,输出另一种语言。

那么拆开这个黑箱,我们可以看到它是由编码组件、解码组件和它们之间的连接组成。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zODxxPb8-1669790754903)(en-resource://database/607:1)]](https://img-blog.csdnimg.cn/4ac5b56c242d4b36a51b959d17932b60.png)
编码组件部分由一堆编码器(encoder)构成(论文中是将6个编码器叠在一起——数字6没有什么神奇之处,也可以尝试其他数字)。解码组件部分也是由相同数量(与编码器对应)的解码器(decoder)组成的。
所有的编码器在结构上都是相同的,但它们没有共享参数。每个解码器都可以分解成两个子层。
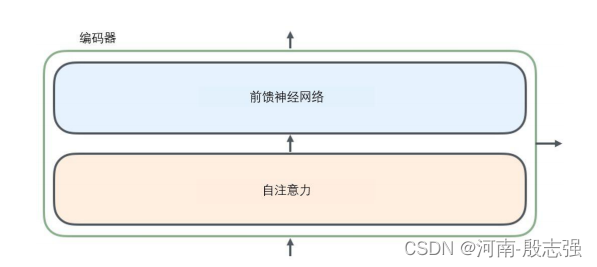
从编码器输入的句子首先会经过一个自注意力(self-attention)层,这层帮助编码器在对每个单词编码时关注输入句子的其他单词,(如何自注意力关注的,下文有讲解)
自注意力层的输出会传递到前馈(feed-forward)神经网络中。每个位置的单词对应的前馈神经网络都完全一样(译注:另一种解读就是一层窗口为一个单词的一维卷积神经网络)
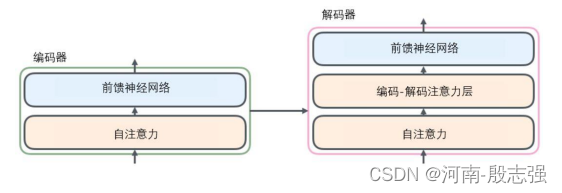
解码器中也有编码器的自注意力(self-attention)层和前馈(feed-forward)层。除此之外,这两个层之间还有一个注意力层,用来关注输入句子的相关部分(和seq2seq模型的注意力作用相似)。
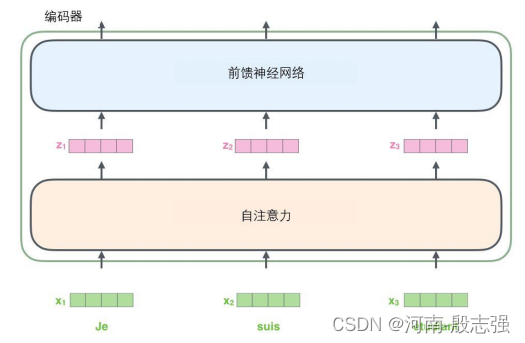
将张量引入图景
我们已经了解了模型的主要部分,接下来看一下各种向量或张量(译注:张量概念是矢量概念的推广,可以简单理解矢量是一阶张量、矩阵是二阶张量。)是怎样在模型的不同部分中,将输入转化为输出的。
像大部分NLP应用一样,首先将每个输入单词通过词嵌入算法转换为词向量词嵌入。

每个单词都被嵌入为512维的向量,用这些简单的方框来表示这些向量。
词嵌入过程只发生在最底层的编码器中。所有的编码器都有一个相同的特点,即它们接收一个向量列表,列表中的每个向量大小为512维。在底层(最开始)编码器中它就是词向量,但是在其他编码器中,它就是下一层编码器的输出(也是一个向量列表)。向量列表大小是我们可以设置的超参数——一般是我们训练集中最长句子的长度。
将输入序列进行词嵌入之后,每个单词都会流经编码器中的两个子层。
接下来关注Transformer的一个核心特性,在这里输入序列中每个位置的单词都有自己独特的路径流入编码器。在自注意力层中,这些路径之间存在依赖关系。而前馈(feed-forward)层没有这些依赖关系。因此在前馈(feed-forward)层时可以并行执行各种路径。
以一个更短的句子为例,看看编码器的每个子层中发生了什么。
如何进行“编码”
如上述已经提到的,一个编码器接收向量列表作为输入,接着将向量列表中的向量传递到自注意力层进行处理,然后传递到前馈神经网络层中,将输出结果传递到下一个编码器中
输入序列的每个单词都经过自编码过程。然后,他们各自通过前向传播神经网络——完全相同的网络,而每个向量都分别通过它
从宏观视角看自注意力机制
看下它的工作原理。
例如,下列句子是想要翻译的输入句子:
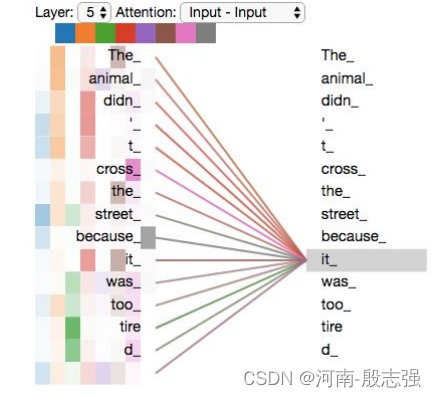
The animal didn’t cross the street because it was too tired
这个“it”在这个句子是指什么呢?它指的是street还是这个animal呢?这对于人类来说是一个简单的问题,但是对于算法则不是。
当模型处理这个单词“it”的时候,自注意力机制会允许“it”与“animal”建立联系。
随着模型处理输入序列的每个单词,自注意力会关注整个输入序列的所有单词,帮助模型对本单词更好地进行编码。且自注意力机制会将所有相关单词的理解融入到我们正在处理的单词中。
当我们在编码器(栈中最上层编码器)中编码“it”这个单词的时,注意力机制的部分会去关注“The Animal”,将它的表示的一部分编入“it”的编码中。
从微观视角看自注意力机制
首先我们了解一下如何使用向量来计算自注意力,然后来看它实怎样用矩阵来实现
计算自注意力的第一步就是从每个编码器的输入向量(每个单词的词向量)中生成三个向量。也就是说对于每个单词,我们创造一个查询向量、一个键向量和一个值向量。这三个向量是通过词嵌入与三个权重矩阵后相乘创建的
可以发现这些新向量在维度上比词嵌入向量更低。他们的维度是64,而词嵌入和编码器的输入/输出向量的维度是512. 但实际上不强求维度更小,这只是一种基于架构上的选择,它可以使多头注意力(multiheaded attention)的大部分计算保持不变
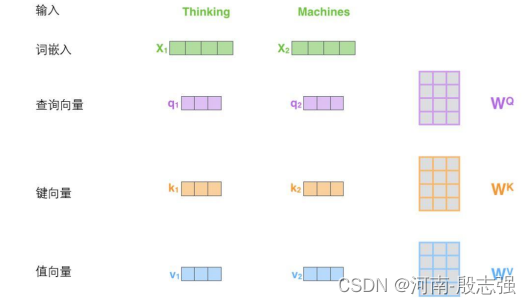
X1与WQ权重矩阵相乘得到q1, 就是与这个单词相关的查询向量。最终使得输入序列的每个单词的创建一个查询向量、一个键向量和一个值向量
什么是查询向量、键向量和值向量向量?
它们都是有助于计算和理解注意力机制的抽象概念。
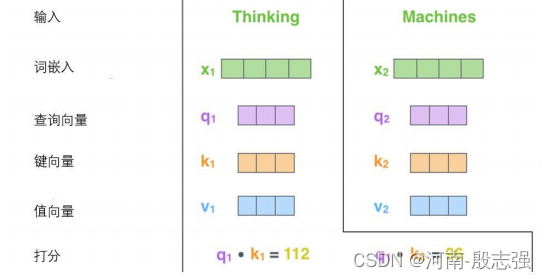
计算自注意力的第二步是计算得分。假设这个例子中,为第一个词“Thinking”计算自注意力向量,就需要拿输入句子中的每个单词对“Thinking”打分。这些分数决定了在编码单词“Thinking”的过程中有多重视句子的其它部分。
这些分数是通过打分单词(所有输入句子的单词)的键向量与“Thinking”的查询向量相点积来计算的。所以如果我们是处理位置最靠前的词的自注意力的话,第一个分数是q1和k1的点积,第二个分数是q1和k2的点积。
第三步和第四步是将分数除以8(8是论文中使用的键向量的维数64的平方根,这会让梯度更稳定。这里也可以使用其它值,8只是默认值),然后通过softmax传递结果。softmax的作用是使所有单词的分数归一化,得到的分数都是正值且和为1。
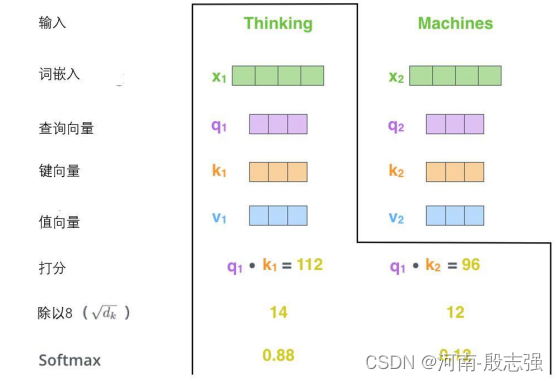
这个softmax分数决定了每个单词对编码当下位置(“Thinking”)的贡献。显然,已经在这个位置上的单词将获得最高的softmax分数,但有时关注另一个与当前单词相关的单词也会有帮助。
第五步是将每个值向量乘以softmax分数(这是为了准备之后将它们求和)。这里的直觉是希望关注语义上相关的单词,并弱化不相关的单词(例如,让它们乘以0.001这样的小数)。
第六步是对加权值向量求和(译注:自注意力的另一种解释就是在编码某个单词时,就是将所有单词的表示(值向量)进行加权求和,而权重是通过该词的表示(键向量)与被编码词表示(查询向量)的点积并通过softmax得到。),然后即得到自注意力层在该位置的输出(在我们的例子中是对于第一个单词)。
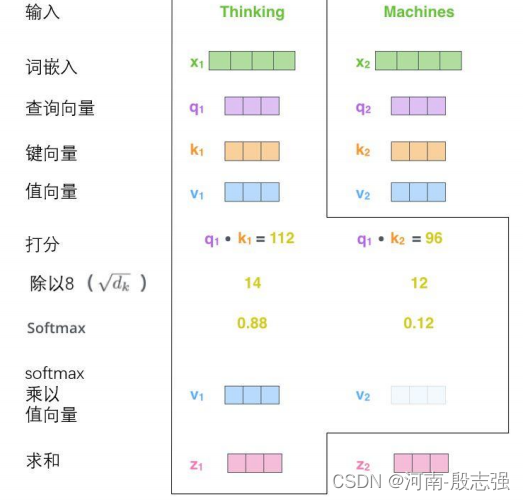
这样自注意力的计算就完成了。得到的向量就可以传给前馈神经网络(
前馈神经网络则相当容易。隐藏层用于增加非线性并改变数据的表示,以便更好地泛化函数。)。然而实际中,这些计算是以矩阵形式完成的,以便算得更快。所以如何用矩阵实现呢?
通过矩阵运算实现自注意力机制
第一步是计算查询矩阵、键矩阵和值矩阵。为此,需要将输入句子的词嵌入装进矩阵X中,将其乘以我们训练的权重矩阵(WQ,WK,WV)。
x矩阵中的每一行对应于输入句子中的一个单词。我们再次看到词嵌入向量 (512,或图中的4个格子)和q/k/v向量(64,或图中的3个格子)的大小差异。
最后,由于我们处理的是矩阵,我们可以将步骤2到步骤6合并为一个公式来计算自注意力层的输出。
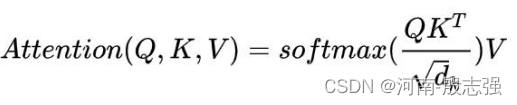
“大战多头怪”
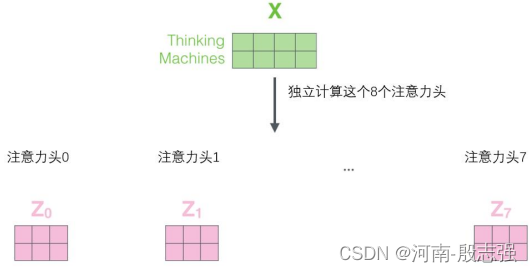
通过增加一种叫做“多头”注意力(“multi-headed” attention)的机制,论文进一步完善了自注意力层,并在两方面提高了注意力层的性能:
1.它扩展了模型专注于不同位置的能力。在上面的例子中,虽然每个编码都在z1中有或多或少的体现,但是它可能被实际的单词本身所支配。如果我们翻译一个句子,比如“The animal didn’t cross the street because it was too tired”,我们会想知道“it”指的是哪个词,这时模型的“多头”注意机制会起到作用。
2.它给出了注意力层的多个“表示子空间”(representation subspaces)。对于“多头”注意机制,有多个查询/键/值权重矩阵集(Transformer使用八个注意力头,因此每个编码器/解码器有八个矩阵集合)。这些集合中的每一个都是随机初始化的,在训练之后,每个集合都被用来将输入词嵌入(或来自较低编码器/解码器的向量)投影到不同的表示子空间中。
在“多头”注意机制下,每个头保持独立的查询/键/值权重矩阵,从而产生不同的查询/键/值矩阵。和之前一样,我们拿X乘以WQ/WK/WV矩阵来产生查询/键/值矩阵。
如果与上述相同的自注意力计算,只需八次不同的权重矩阵运算,就会得到八个不同的Z矩阵。
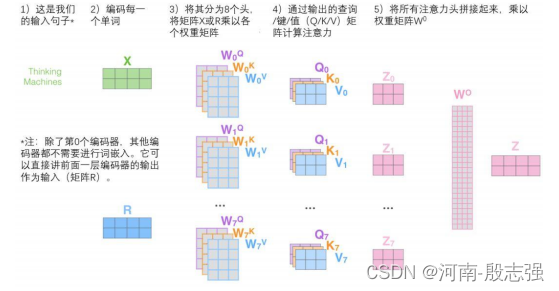
前馈层不需要8个矩阵,它只需要一个矩阵(由每一个单词的表示向量组成)。所以需要一种方法把这八个矩阵压缩成一个矩阵。那该怎么做?其实可以直接把这些矩阵拼接在一起,然后用一个附加的权重矩阵WO与它们相乘。

这几乎就是多头自注意力的全部。这确实有好多矩阵,所以试着把它们集中在一个图片中,这样可以一眼看清。
既然已经清楚了注意力机制的这么多“头”,在例句中编码“it”一词时,不同的注意力“头”集中在哪里:
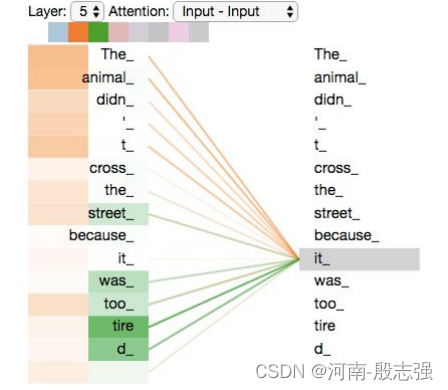
当我们编码“it”一词时,一个注意力头集中在“animal”上,而另一个则集中在“tired”上,从某种意义上说,模型对“it”一词的表达在某种程度上是“animal”和“tired”的代表
然而,如果把所有的attention都加到图示里,事情就更难解释了:
使用位置编码表示序列的顺序
什么是位置编码?
位置编码(Positional encoding)可以告诉Transformers模型一个实体/单词在序列中的位置或位置,这样就为每个位置分配一个唯一的表示。虽然最简单的方法是使用索引值来表示位置,但这对于长序列来说,索引值会变得很大,这样就会产生很多的问题。位置编码将每个位置/索引都映射到一个向量。所以位置编码层的输出是一个矩阵,其中矩阵中的每一行是序列中的编码字与其位置信息的和。
到目前为止,对模型的描述缺少了一种理解输入单词顺序的方法。
为了解决这个问题,Transformer为每个输入的词嵌入添加了一个向量。这些向量遵循模型学习到的特定模式,这有助于确定每个单词的位置,或序列中不同单词之间的距离。这里的直觉是,将位置向量添加到词嵌入中使得它们在接下来的运算中,能够更好地表达的词与词之间的距离。
如何理解单词顺序
为了让模型理解单词的顺序,需要添加了位置编码向量,这些向量的值遵循特定的模式。
如果我们假设词嵌入的维数为4,则实际的位置编码如下:
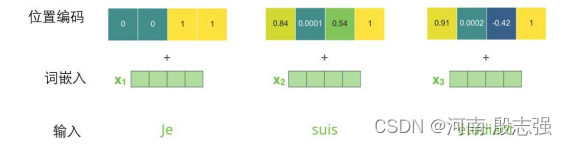
尺寸为4的迷你词嵌入位置编码实例
这个模式会是什么样子?
在下图中,每一行对应一个词向量的位置编码,所以第一行对应着输入序列的第一个词。每行包含512个值,每个值介于1和-1之间。我们已经对它们进行了颜色编码,所以图案是可见的。
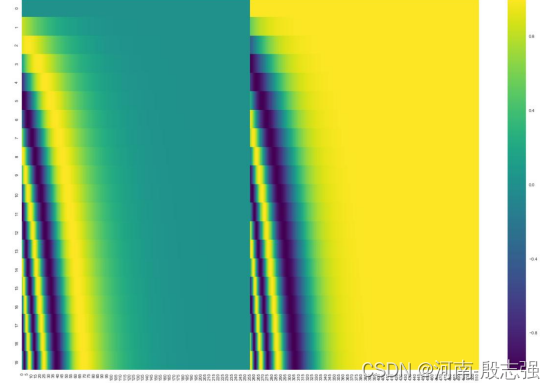
20字(行)的位置编码实例,词嵌入大小为512(列)。你可以看到它从中间分裂成两半。这是因为左半部分的值由一个函数(使用正弦)生成,而右半部分由另一个函数(使用余弦)生成。然后将它们拼在一起而得到每一个位置编码向量(这不是唯一可能的位置编码方法。然而,它的优点是能够扩展到未知的序列长度)
残差模块
在继续进行下去之前,需要提到一个编码器架构中的细节:在每个编码器中的每个子层(自注意力、前馈网络)的周围都有一个残差连接,并且都跟随着一个“层-归一化”步骤。
层归一化方式:

层-归一化步骤:

如果我们去可视化这些向量以及这个和自注意力相关联的层-归一化操作,那么看起来就像下面这张图描述一样:
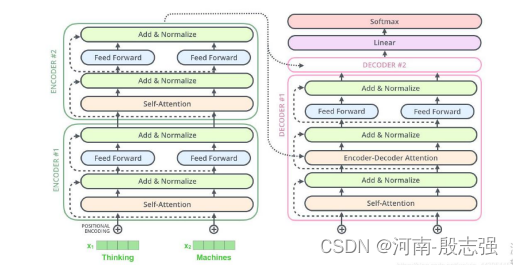
解码组件
解码器的细节是什么呢?
编码器通过处理输入序列开启工作。顶端编码器的输出之后会转变为一个包含向量K(键向量)和V(值向量)的注意力向量集 。这些向量将被每个解码器用于自身的“编码-解码注意力层”,而这些层可以帮助解码器关注输入序列哪些位置合适:
在完成编码阶段后,则开始解码阶段。解码阶段的每个步骤都会输出一个输出序列(在这个例子里,是英语翻译的句子)的元素
接下来的步骤重复了这个过程,直到到达一个特殊的终止符号,它表示transformer的解码器已经完成了它的输出。每个步骤的输出在下一个时间步被提供给底端解码器,并且就像编码器之前做的那样,这些解码器会输出它们的解码结果 。另外,就像我们对编码器的输入所做的那样,我们会嵌入并添加位置编码给那些解码器,来表示每个单词的位置。
而那些解码器中的自注意力层表现的模式与编码器不同:在解码器中,自注意力层只被允许处理输出序列中更靠前的那些位置。在softmax步骤前,它会把后面的位置给隐去(把它们设为-inf)。
这个“编码-解码注意力层”工作方式基本就像多头自注意力层一样,只不过它是通过在它下面的层来创造查询矩阵,并且从编码器的输出中取得键/值矩阵。
最终的线性变换和Softmax层
解码组件最后会输出一个实数向量。但是如何把浮点数变成一个单词?这便是线性变换层要做的工作,它之后就是Softmax层。
线性变换层是一个简单的全连接神经网络,它可以把解码组件产生的向量投射到一个比它大得多的、被称作对数几率(logits)的向量里。
不妨假设我们的模型从训练集中学习一万个不同的英语单词(我们模型的“输出词表”)。因此对数几率向量为一万个单元格长度的向量——每个单元格对应某一个单词的分数。
接下来的Softmax 层便会把那些分数变成概率(都为正数、上限1.0)。概率最高的单元格被选中,并且它对应的单词被作为这个时间步的输出。

这张图片从底部以解码器组件产生的输出向量开始。之后它会转化出一个输出单词。
训练部分总结
既然已经过了一遍完整的transformer的前向传播过程,那我们就可以直观感受一下它的训练过程。
在训练过程中,一个未经训练的模型会通过一个完全一样的前向传播。但因为我们用有标记的训练集来训练它,所以我们可以用它的与真实的输出做比较。
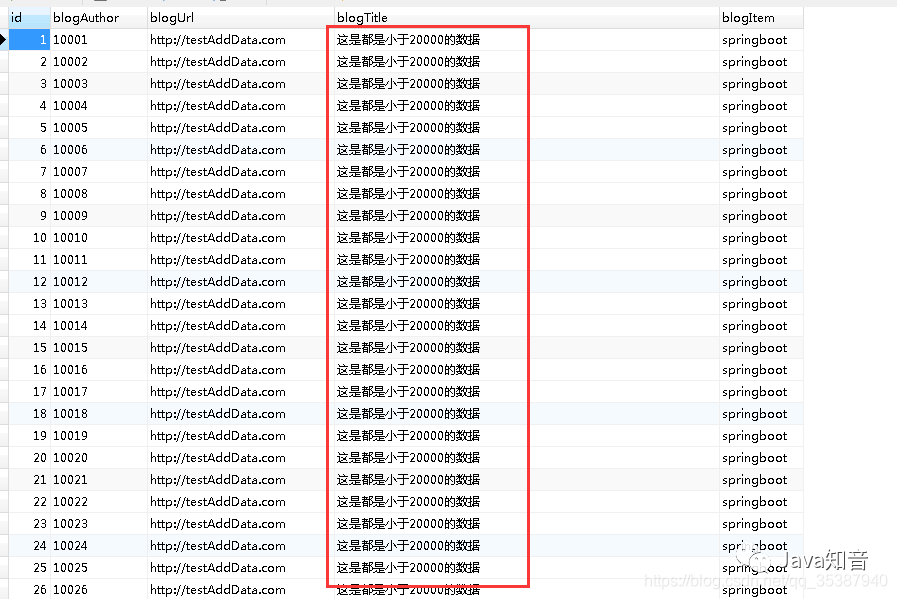
为了把这个流程可视化,不妨假设我们的输出词汇仅仅包含六个单词:“a”, “am”, “i”, “thanks”, “student”以及 “”(end of sentence的缩写形式)。
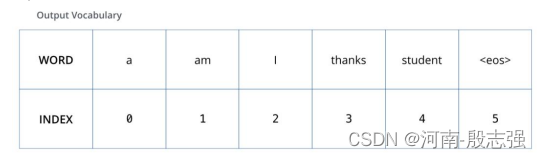
模型的输出词表在训练之前的预处理流程中就被设定好。
一旦我们定义了我们的输出词表,我们可以使用一个相同宽度的向量来表示我们词汇表中的每一个单词。这也被认为是一个one-hot 编码。所以,我们可以用下面这个向量来表示单词“am”:
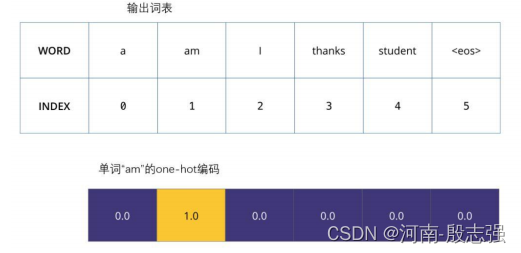
例子:对我们输出词表的one-hot 编码
接下来我们讨论模型的损失函数——这是我们用来在训练过程中优化的标准。通过它可以训练得到一个结果尽量准确的模型。
损失函数
比如说我们正在训练模型,现在是第一步,一个简单的例子——把“merci”翻译为“thanks”。
这意味着我们想要一个表示单词“thanks”概率分布的输出。但是因为这个模型还没被训练好,所以不太可能现在就出现这个结果。
因为模型的参数(权重)都被随机的生成,(未经训练的)模型产生的概率分布在每个单元格/单词里都赋予了随机的数值。我们可以用真实的输出来比较它,然后用反向传播算法来略微调整所有模型的权重,生成更接近结果的输出。
你会如何比较两个概率分布呢?我们可以简单地用其中一个减去另一个。更多细节请参考交叉熵和KL散度。
交叉熵:https://colah.github.io/posts/2015-09-Visual-Information/
KL散度:https://www.countbayesie.com/blog/2017/5/9/kullback-leibler-divergence-explained
但注意到这是一个过于简化的例子。更现实的情况是处理一个句子。例如,输入“je suis étudiant”并期望输出是“i am a student”。那我们就希望我们的模型能够成功地在这些情况下输出概率分布:
每个概率分布被一个以词表大小(我们的例子里是6,但现实情况通常是3000或10000)为宽度的向量所代表。
第一个概率分布在与“i”关联的单元格有最高的概率
第二个概率分布在与“am”关联的单元格有最高的概率
以此类推,第五个输出的分布表示“”关联的单元格有最高的概率
依据例子训练模型得到的目标概率分布
在一个足够大的数据集上充分训练后,我们希望模型输出的概率分布看起来像这个样子:
我们期望训练过后,模型会输出正确的翻译。当然如果这段话完全来自训练集,它并不是一个很好的评估指标(参考:交叉验证,链接https://www.youtube.com/watch?v=TIgfjmp-4BA)。注意到每个位置(词)都得到了一点概率,即使它不太可能成为那个时间步的输出——这是softmax的一个很有用的性质,它可以帮助模型训练。
因为这个模型一次只产生一个输出,不妨假设这个模型只选择概率最高的单词,并把剩下的词抛弃。这是其中一种方法(叫贪心解码)。另一个完成这个任务的方法是留住概率最靠高的两个单词(例如I和a),那么在下一步里,跑模型两次:其中一次假设第一个位置输出是单词“I”,而另一次假设第一个位置输出是单词“me”,并且无论哪个版本产生更少的误差,都保留概率最高的两个翻译结果。然后我们为第二和第三个位置重复这一步骤。这个方法被称作集束搜索(beam search)。在我们的例子中,集束宽度是2(因为保留了2个集束的结果,如第一和第二个位置),并且最终也返回两个集束的结果(top_beams也是2)。这些都是可以提前设定的参数。
2. 如何在不同行业中进行应用?
Transformer在视觉行业对应的不同变种
1) ViT
Vision TransformerVision Transformer(ViT)将纯Transformer架构直接应用到一系列图像块上进行分类任务,可以取得优异的结果。它在许多图像分类任务上也优于最先进的卷积网络,同时所需的预训练计算资源大大减少(至少减少了4倍)。
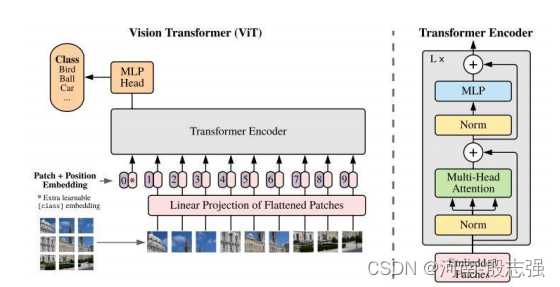
ViT将输入图片分为多个patch(16x16),再将每个patch投影为固定长度的向量送入Transformer,后续encoder的操作和原始Transformer中完全相同。但是因为对图片分类,因此在输入序列中加入一个特殊的token,该token对应的输出即为最后的类别预测
图像序列patches
它们是如何将图像分割成固定大小的小块,然后将这些小块的线性投影连同它们的图像位置一起输入变压器的。然后剩下的步骤就是一个干净的和标准的Transformer编码器和解码器。在图像patch的嵌入中加入位置嵌入,通过不同的策略在全局范围内保留空间/位置信息。在本文中,他们尝试了不同的空间信息编码方法,包括无位置信息编码、1D/2D位置嵌入编码和相对位置嵌入编码。

不同位置编码策略的对比一个有趣的发现是,与一维位置嵌入相比,二维位置嵌入并没有带来显著的性能提升。
数据集
该模型是从多个大型数据集上删除了重复数据预训练得到的,以支持微调(较小数据集)下游任务。
- ILSVRC-2012 ImageNet数据集有1k类和130万图像
- ImageNet-21k具有21k类和1400万图像
- JFT拥有18k类和3.03亿高分辨率图像
模型的变体
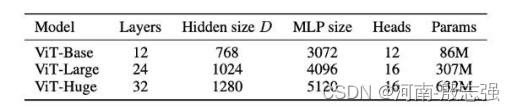
像其他流行的Transformer 模型(GPT、BERT、RoBERTa)一样,ViT(vision transformer)也有不同的模型尺寸(基础型、大型和巨大型)和不同数量的transformer层和heads。例如,ViT-L/16可以被解释为一个大的(24层)ViT模型,具有16×16的输入图像patch大小。
注意,输入的patch尺寸越小,计算模型就越大,这是因为输入的patch数目N = HW/P*P,其中(H,W)为原始图像的分辨率,P为patch图像的分辨率。这意味着14 x 14的patch比16 x 16的图像patch在计算上更昂贵。
Benchmark结果
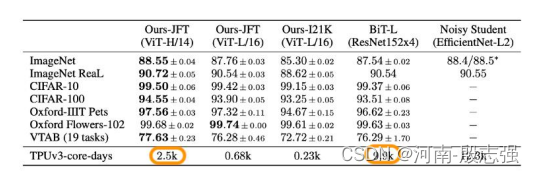
图像分类的Benchmark
以上结果表明,该模型在多个流行的基准数据集上优于已有的SOTA模型。
在JFT-300M数据集上预训练的vision transformer(ViT-H/14, ViT-L/16)优于所有测试数据集上的ResNet模型(ResNet152x4,在相同的JFT-300M数据集上预训练),同时在预训练期间占用的计算资源(TPUv3 core days)大大减少。即使是在ImageNet-21K上预训练的ViT也比基线表现更好。
模型性能 vs 数据集大小
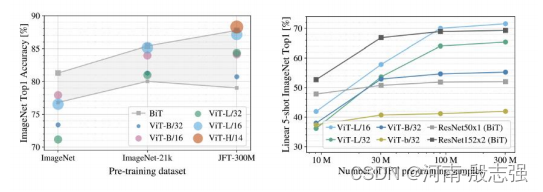
预训练数据集大小VS模型性能
上图显示了数据集大小对模型性能的影响。当预训练数据集的大小较小时,ViT的表现并不好,当训练数据充足时,它的表现优于以前的SOTA。
哪种结构更高效?
如一开始所提到的,使用transformer进行计算机视觉的架构设计也有不同,有的用Transformer完全取代CNNs (ViT),有的部分取代,有的将CNNs与transformer结合(DETR)。下面的结果显示了在相同的计算预算下各个模型结构的性能。
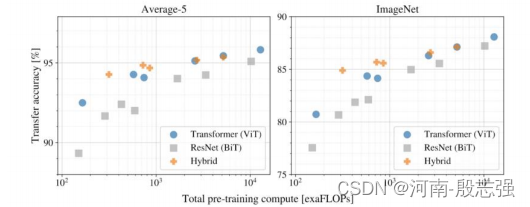
不同模型架构的性能与计算成本
以上实验表明:
- 纯Transformer架构(ViT)在大小和计算规模上都比传统的CNNs (ResNet BiT)更具效率和可扩展性
- 混合架构(CNNs + Transformer)在较小的模型尺寸下性能优于纯Transformer,当模型尺寸较大时性能非常接近
ViT (vision transformer)的重点
- 使用Transformer架构(纯或混合)
- 输入图像由多个patch平铺开来
- 在多个图像识别基准上击败了SOTA
- 在大数据集上预训练更便宜
- 更具可扩展性和计算效率
2) DETR
DETR是第一个成功地将Transformer作为pipeline中的主要构建块的目标检测框架。它与以前的SOTA方法(高度优化的Faster R-CNN)的性能匹配,具有更简单和更灵活的pipeline。
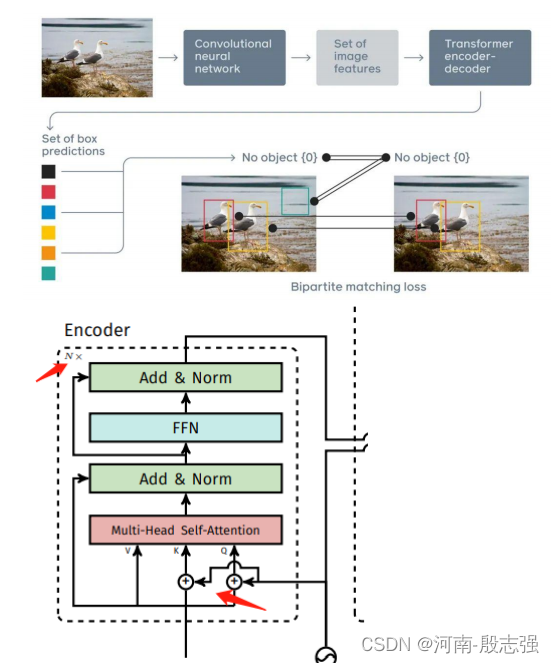
DETR提出了一个编码器-解码器架构,它为图像中的每个对象顺序生成成对的二进制掩码和分类标签。通过连接所有 ConvLSTM 层的侧输出并应用每通道最大池化操作以获得隐藏表示,该表示将作为两个全连接层的输入,预测分类标签和停止概率,并且一个一个得到分割掩码。通过匈牙利算法来进行预测结果和 ground-truth 之间的一一匹配用于计算损失。
DETR结合CNN和Transformer的pipeline的目标检测上图为DETR,一种以CNN和Transformer为主要构建块的混合pipeline。以下是流程:
- CNN被用来学习图像的二维表示并提取特征
- CNN的输出是扁平化的,并辅以位置编码,以馈入标准Transformer的编码器
- Transformer的解码器通过输出嵌入到前馈网络(FNN)来预测类别和包围框
更简单的Pipeline
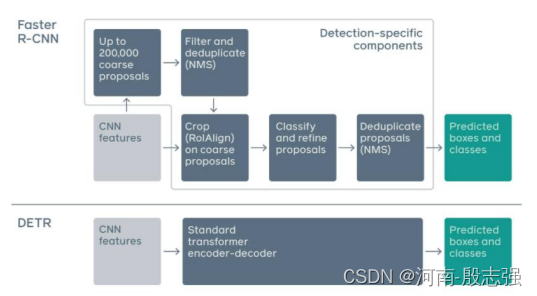
传统目标检测pipeline和DETR的对比
传统的目标检测方法,如Faster R-CNN,有多个步骤进行锚的生成和NMS。DETR放弃了这些手工设计的组件,显著地简化了物体检测pipeline。
当扩展到全景分割时,惊人的结果
在这篇论文中,他们进一步扩展了DETR的pipeline用于全景分割任务,这是一个最近流行和具有挑战性的像素级识别任务。为了简单解释全景分割的任务,它统一了2个不同的任务,一个是传统的语义分割(为每个像素分配类标签),另一个是实例分割(检测并分割每个对象的实例)。使用一个模型架构来解决两个任务(分类和分割)是非常聪明的想法。
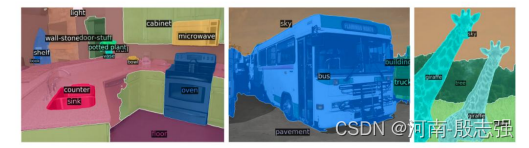
像素级别的全景分割上图显示了全景分割的一个例子。通过DETR的统一pipeline,它超越了非常有竞争力的基线。注意力可视化下图显示了Transformer解码器对预测的注意力。不同物体的注意力分数用不同的颜色表示。通过观察颜色/注意力,你会惊讶于模型的能力,通过自注意在全局范围内理解图像,解决重叠的包围框的问题。尤其是斑马腿上的橙色,尽管它们与蓝色和绿色局部重叠,但还是可以很好的分类

预测物体的解码器注意力可视化
DETR的要点
- 使用Transformer得到更简单和灵活的pipeline
- 在目标检测任务上可以匹配SOTA
- 并行的更有效的直接输出最终的预测集
- 统一的目标检测和分割架构
- 大目标的检测性能显著提高,但小目标检测性能下降
Image GPT
Image GPT是一个在像素序列上用图像补全训练的GPT-2 transformer 模型。就像一般的预训练的语言模型,它被设计用来学习高质量的无监督图像表示。它可以在不知道输入图像二维结构的情况下自回归预测下一个像素。
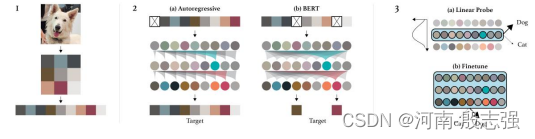
作者直接利用GPT-2 的模型结构,忽略图像的二维结构信息,直接将图像转化为一维序列作为输入,通过这这种方式地无监督生成式训练,GPT-2在图像上也能学到很好的表达,预训练得到的模型在后续任务上不弱于甚至超过有监督学习得到的模型。
作者其实只是把二维图像直接reshape成一维作为输入。对于数据train、val、test划分以及数据增强部分作者采用采用的是最常用的方式,需要强调的是,由于图像分类一般输入为384 * 384 * 3 或 224 * 224 3,这对于gpt 来直接reshape成一维长度过大,所以作者对图像进行了降采样,采样到 32 32 × 3, 48 * 48 × 3, 或者64 * 64 × 3(继续降采样效果就会明显恶化了)。更进一步的减输入,作者利用了聚类。作者通过使用k = 512的k-means对(R,G,B)像素值进行聚类来创建9位调色板(9-bit color palette),将输入较少到三分之一,而几乎没有颜色损失。
方法介绍
作者仍然沿用了先pretrain而后finetune的路线。pretrain方式和finetune作者均设计了两种不同的实验方式,分别给出了对比结果。两种pretrain 目标函数(这里模型输入以及预测值都是图像的像素值):
BERT objectives:一种是BERT MLM方式,其目标函数的表达式为:
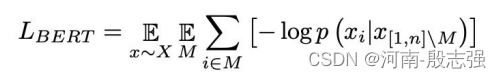
这里说下两个目标的函数区别(即BERT 和 GPT pretain 的区别):Bert MLM pretrain:采用的方式是随机mask掉部分输入,利用其余输入来预测mask掉的的部分,此时bert接收到的输入是双向的GPT pretrain:用前面的输入预测后面的数据,所以是单向的同时,利用分类任务的finetune 来评价pretrain 模型的优劣作者也选用了两种方式:Fine-tuning:在目标数据上端到端的fintune模型,所有参数都更新;Linear Probing:将pretrain model作为特征提取器,后面用一个线性分类器进行分类,只有线性分类器的参数会更新。
来自预训练的图像GPT的特征在一些分类基准上取得了最先进的性能,并在ImageNet上接近最先进的无监督精度。
下图显示了由人工提供的半张图像作为输入生成的补全模型,随后是来自模型的创造性补全。

来自Image GPT的图像补全
Image GPT的要点:
- 使用与NLP中的GPT-2相同的transformer架构
- 无监督学习,无需人工标记
- 需要更多的计算来生成有竞争力的表示
- 学习到的特征在低分辨率数据集的分类基准上实现了SOTA性能
3. 芯片厂商如何定制Transformer开发
谷歌用 AI 在六小时内自动完成芯片布局设计的最新方案
近日,谷歌大脑团队联合斯坦福大学的研究者对这一基于 AI 的芯片设计方法进行了改进,并将其应用于不久前 Google I/O 2021 大会上正式发布的、下一代张量处理单元(TPU v4)加速器的产品中。谷歌此前表示,TPUv4 可以在目标检测、图像分类、自然语言处理、机器翻译和推荐基准等工作负载上优于上一代 TPU 产品。相关论文研究已经在 Nature 上发表,Jeff Dean 为核心作者之一。据介绍,在不到六小时的时间内,谷歌 AI 芯片设计方法自动生成的芯片布局在功耗、性能和芯片面积等所有关键指标上都优于或媲美人类,而工程师需要耗费数月的艰苦努力才能达到类似效果。这项基于强化学习的快速芯片设计方法对于资金紧张的初创企业大有裨益,如果谷歌公开相关技术的话,这些初创企业可以开发自己的 AI 和其他专用芯片。并且,这种方法有助于缩短芯片设计周期,从而使得硬件可以更好地适应快速发展的技术研究。
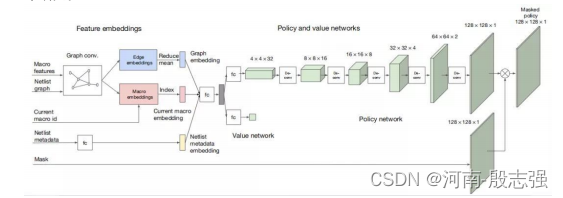
策略网络和价值网络体系架构。

训练方法和训练方案。
推荐:缩短芯片设计周期,生成的芯片布局在功耗、性能和芯片面积等所有关键指标上都优于或媲美人类。
![[附源码]Python计算机毕业设计SSM辽宁科技大学二手车交易平台(程序+LW)](https://img-blog.csdnimg.cn/05f51247fafc41f7b459d329a0613e80.png)