说明:本系列文章若无特别说明,则在技术上将 Continual Learning(连续学习)等同于 Incremental Learning(增量学习)、Lifelong Learning(终身学习),关于 Continual Learning、Incremental Learning 和 Lifelong Learning 更细节的区别参见 VALSE Seminar【20211215 - 深度连续学习】
本文内容:
- 介绍连续学习的三种场景
- Task-Incremental Learning
- Domain-Incremental Learning
- Class-Incremental Learning
- 对比三种场景的区别
文章目录
- 连续学习场景
- 1. Task-IL
- 2. Domain-IL
- 3. Class-IL
连续学习模型按照一定顺序对连续、非独立同分布的流数据进行学习,从而对模型进行增量式更新。在学习过程中,模型学完一个任务(A)后,接着学习下一个任务(B)且不再使用前一个任务(A)的数据。连续学习算法旨在高效地转化和利用已学习的知识(A)来完成新任务(B)的学习,并最大程度地降低灾难性遗忘旧任务(A)的问题。同时,在学习新旧任务(A & B)后,模型应能够对来自任何任务(A / B)的数据进行有效预测。
以最熟悉的手写数字数据集 MNIST 来看连续学习的学习过程:
MNIST 数据集包含 0 ~ 9 共 10 个数字,我们可以把它分成 5 个独立的 Task(这样划分的数据集叫 Split MNIST),每个 Task 包含两个数字。
- 第一次训练,连续学习模型只能看到训练数据 {0, 1},此时模型应该学会数字 0 和 1 的分类;
- 第二次训练,连续学习模型只能看到训练数据 {2, 3}(注意这时 {0, 1} 不可见了!),此时模型应该学会数字 2 和 3 的分类,同时还能分类 0 和 1。
- 第三次训练,…(以此类推)。
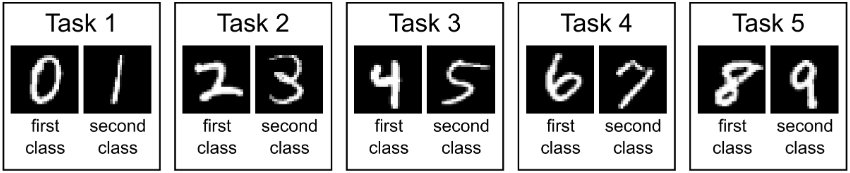
上面这个例子应该是刚接触连续学习时,最直接能想到的一种连续学习方式,这种连续学习实际上属于 class-incremental learning,是最接近人类、也是最难的连续学习类型。还有两种连续学习类型,分别是 task-incremental learning 和 domain-incremental learning。下面详细介绍这三种连续学习类型。
连续学习场景
Three scenarios for continual learning 将连续学习分为三个场景:
(code:https://github.com/GMvandeVen/continual-learning)
| 学习场景 | 测试要求 |
|---|---|
| Task-Incremental Learning (Task-IL) | 提供task-ID |
| Domain-Incremental Learning (Domain-IL) | 不提供task-ID |
| Class-Incremental Learning (Class-IL) | 不提供task-ID且要求推断task-ID |
1. Task-IL
任务增量学习(task-incremental learning, Task-IL):
在 Task-IL 场景下,每个任务都有自己的 task-ID number。在模型训练和测试时始终提供 task-ID,因此模型能够知道当前的输入数据来自哪一个任务,是最简单的连续学习场景。
以 Split MNIST 为例:
Split MNIST 包含 5 个 task,task-ID 及 task 分别为 ID=1 {0,1},ID=2 {2,3},ID=3 {4,5},ID=4 {6,7},ID=5 {8,9}。给出 0 ~ 9 中的任意一个样本 x,首先需要给出 task-ID 向模型指明现在的预测任务是什么(比如给出 task-ID=3),那么模型会从 ID=3 {4,5} 这个任务中对样本 x 进行预测。
针对 Task-IL 场景的连续学习模型能够为每个任务都训练一个专门的预测模块,典型架构就是 multi-headed 输出层。在 multi-headed 输出层每个任务都有专属自己的 output head,而网络较浅层(一般是特征提取层)通常是任务间共享的。
2. Domain-IL
域增量学习(domain-incremental learning, Domain-IL):
Domain-IL 不向模型提供 task-ID,模型直接对待预测样本做出预测,此场景下模型不知道、也不需要知道当前任务是什么。
Domain-IL 场景下的任务通常都具有相同的结构,但有着不同的输入分布(i.e. 任务目标始终相同,但输入数据的分布在改变)。比如一个智能体它需要学会在不同的环境中生存,而不需要明确地识别它所面临的环境,也就是在任何环境(输入)下的学习目标都是生存。Domain-IL 比较典型的实验是用 MNIST 与 Permuted MNIST 作为不同的任务(但任务目标都是分辨10个数字)考察模型的连续学习能力。
以 Permuted MNIST 为例:
MNIST 和 Permuted MNIST 包含 0 ~ 9 所有数字。使用 MNIST 作为第一个任务,预测目标为 0 ~ 9;对 MNIST 进行 permutation,得到 Permuted MNIST 作为第二个任务,预测目标仍为 0 ~ 9;第三、第四 … 任务均基于 MNIST 进行不同的 permutation,这些任务的输入分布不同,但学习目标都是对样本 x 进行 0~9 的预测。
以 Split MNIST 为例:
Split MNIST 将数字 0 ~ 9 划分为 5 个任务,分别为 {0,1},{2,3},{4,5},{6,7},{8,9}。给出 0 ~ 9 中的任意一个样本 x,模型只需要预测样本 x 是”第一类“还是”第二类“,不需要预测出 x 是数字几(预测出是数字几实际上就是要推断样本 x 来自哪一个 task,这是 Class-IL 需要解决的问题)。
3. Class-IL
类增量学习(class-incremental learning, Class-IL):
Class-IL 要求模型推断出待预测样本 x 所属的任务是什么,并对 x 做出预测。类增量学习是3个场景中最复杂、也是最接近现实的学习场景,它和人类的学习方式最相近,需要不断学习新的类别,并进行识别。Class-IL 模型通常使用 single-headed 结构,即所有任务的预测都使用同一个 output layer。
以 Split MNIST 为例:
Split MNIST 将数字 0 ~ 9 划分为 5 个任务,分别为 {0,1},{2,3},{4,5},{6,7},{8,9}。给出 0 ~ 9 中的任意一个样本 x,模型需要预测出这是“数字几”。预测“数字几”这个目标其实包含了两部分,模型要预测出现在是哪个任务(推断 task-ID)并在该任务中做出样本的正确分类。