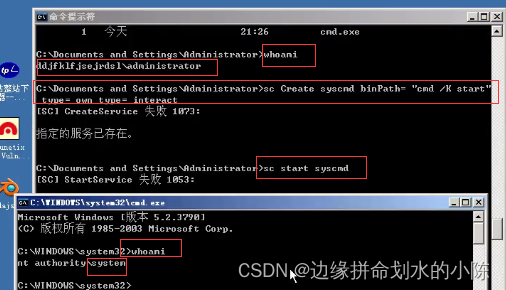
Wikidata 数据分析与处理
需求:Wikidata 数据描述了很多实体,以及实体属性。比如某一个公司/组织/机构名称是:阿里巴巴,对数据内该组织的相关属性进行观察、分析、治理、抽取等,最后用图数据库进行存储和展示其关系,只要将这份数据以人更容易理解查看的方式进行描述即可。或者是观察分析数据的内容,抽取实体,对其画像的过程
1. 下载数据包
官网下载地址:https://www.wikidata.org/wiki/Wikidata:Database_download
自行决定下载全量(all)或部分(按日期)的。
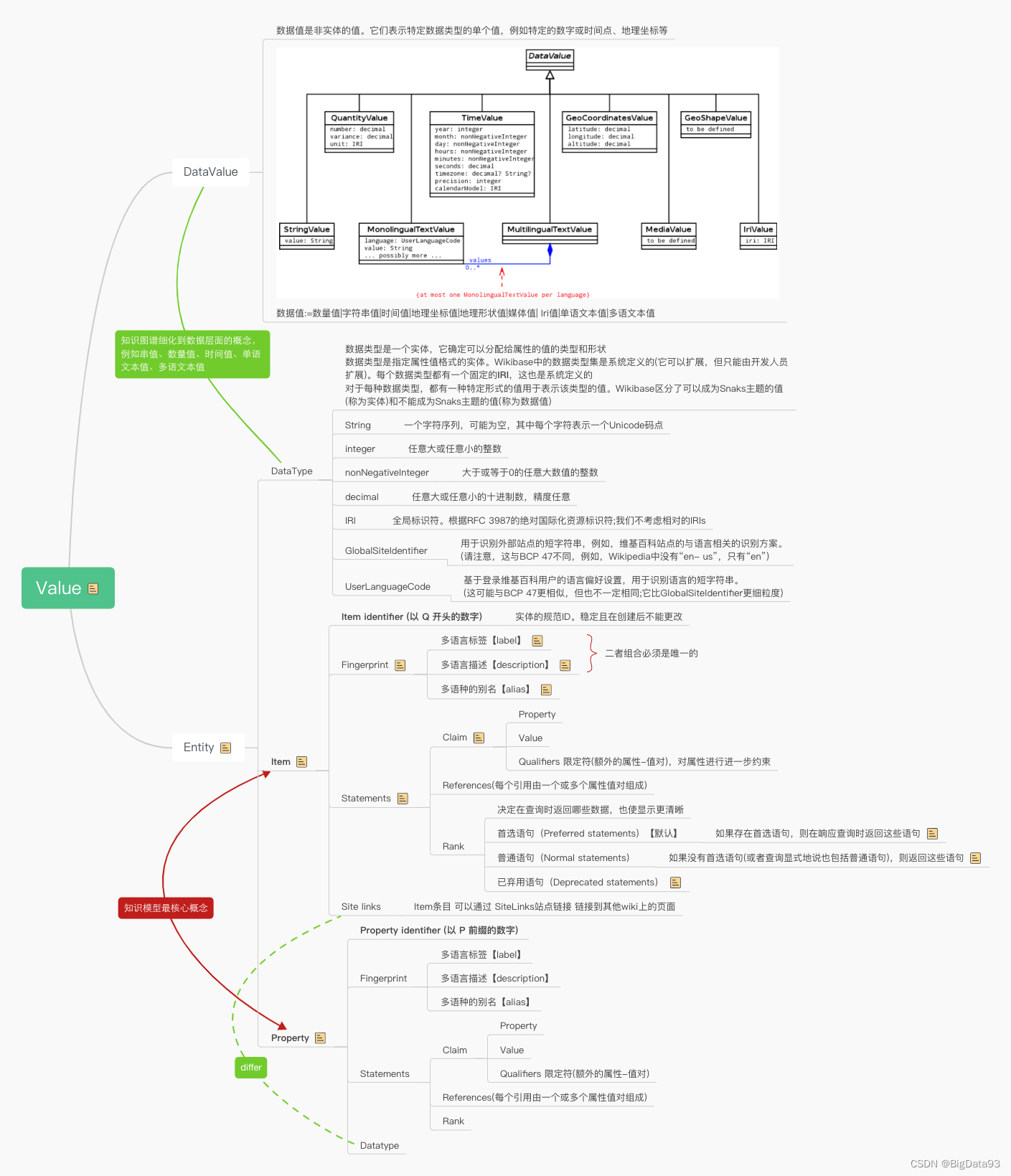
2. Wikidata 数据模型
官网参考:https://www.mediawiki.org/wiki/Wikibase/DataModel
结合官网文档,自行整理模型如下:
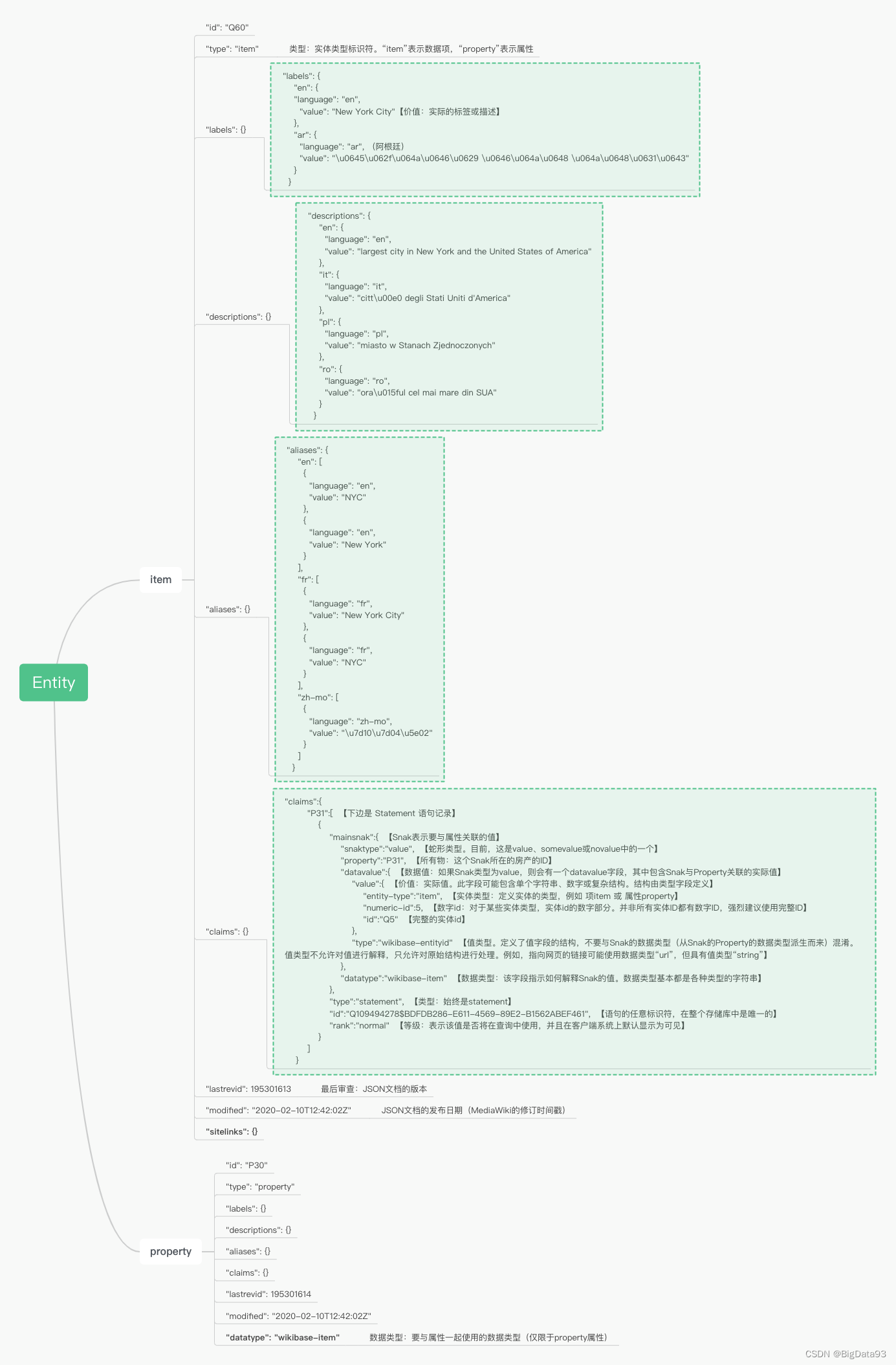
3. 解析 JSON 数据
参考 Wikidata 官网对于 JSON 数据字段含义:https://doc.wikimedia.org/Wikibase/master/php/docs_topics_json.html
数据包下载后,截取1条数据格式化JSON:
https://www.json.cn/#
解析如下:
{
"type":"item",
类型:实体类型标识符。“item”表示数据项,“property”表示属性
"id":"Q109494278",
id:实体的规范ID
"labels":{
标签:标签、描述和别名由相同的基本数据结构表示。对于每种语言,都有一个使用以下字段的记录
"ru":{
"language":"ru",
语言:语言代码
"value":"\u041a\u043e\u0437\u043b\u043e\u0432, \u041a\u0438\u0440\u0438\u043b\u043b \u0421\u0435\u0440\u0433\u0435\u0435\u0432\u0438\u0447"
价值:实际的标签或描述(俄文,翻译为:基里尔·科兹洛夫)
}
},
"descriptions":{
描述:包含不同语言的描述,请参阅标签、描述和别名
},
"aliases":{
别名:包含不同语言的别名,请参阅标签、说明和别名
},
"claims":{
声称:包含任意数量的语句,按属性分组。注意:WikibaseMediaInfo使用的是“statements”键。请参阅声明
"P31":[ 下边是 Statement 语句记录
{
"mainsnak":{
Snak表示要与属性关联的值。请参阅下面的Snaks。主Snak中指定的属性必须与语句关联的属性相同
"snaktype":"value",
蛇形:陷阱的类型。目前,这是value、somevalue或novalue中的一个
"property":"P31",
所有物:这个Snak所在的房产的ID
"datavalue":{
数据值:如果Snak类型为value,则会有一个datavalue字段,其中包含Snak与Property关联的实际值
"value":{
价值:实际值。此字段可能包含单个字符串、数字或复杂结构。结构由类型字段定义
"entity-type":"item",
实体类型:定义实体的类型,例如 项item 或 属性property
"numeric-id":5,
数字id:对于某些实体类型,实体id的数字部分。并非所有实体ID都有数字ID,强烈建议使用完整ID
"id":"Q5"
id:完整的实体id
},
"type":"wikibase-entityid"
类型:值类型。这定义了值字段的结构,不要与Snak的数据类型(从Snak的Property的数据类型派生而来)混淆。值类型不允许对值进行解释,只允许对原始结构进行处理。例如,指向网页的链接可能使用数据类型“url”,但具有值类型“string”
},
"datatype":"wikibase-item"
数据类型:该字段指示如何解释Snak的值。数据类型可以是【https://www.wikidata.org/wiki/Special:ListDatatypes】列出的任何其他数据类型(基本都是各种类型的字符串)
},
"type":"statement",
类型:始终是statement声明。(从历史上看,这里的claim曾经是另一个有效值。
"id":"Q109494278$BDFDB286-E611-4569-89E2-B1562ABEF461",
id:语句的任意标识符,在整个存储库中是唯一的。不能也不应该对标识符的结构做出任何假设,也不能保证格式保持不变
"rank":"normal"
等级:表示该值是否将在查询中使用,并且在客户端系统上默认显示为可见。该值是首选值(either preferred)、普通值(normal) 或不推荐使用的值(deprecated)
}
]
},
"sitelinks":{
网站链接:包含指向不同网站上描述项目的页面的网站链接,请参阅[sitelinks](仅限项目)
"ruwiki":{
"site":"ruwiki",
地点:站点全局ID
"title":"\u041a\u043e\u0437\u043b\u043e\u0432, \u041a\u0438\u0440\u0438\u043b\u043b \u0421\u0435\u0440\u0433\u0435\u0435\u0432\u0438\u0447",
标题:页面标题(俄文,翻译为:基里尔·科兹洛夫)
"badges":[
徽章:与页面相关联的任何“徽章”(如“专题文章”)。徽章以物品ID列表的形式提供
]
}
},
"lastrevid":1524708662
最后审查:JSON文档的版本(这是一个MediaWiki修订ID)
}
其他字段:
第1层:
1. datatype 数据类型:要与属性一起使用的数据类型(仅限于property属性)
2. modified 被改进的:JSON文档的发布日期(这是MediaWiki的修订时间戳)
第2层:
1. sitelinks
url 网址:可选地,可以包括页面的完整URL
2. Statement 语句记录("P31")
qualifiers 限定符:为主要值提供上下文,例如测量的时间点。限定符以陷阱列表的形式给出,每个陷阱都与一个属性相关联
references 参考文献:记录了主Snak和限定符中数据的出处信息。它们是作为参考记录列表提供的;请参阅以下参考文献
说明:在别名的情况下,每种语言都与此类记录的列表相关联,而对于标签和描述,记录则直接与该语言相关联
结构化展示:
4. 模型建立与预处理
下图是简单的整理与设计:
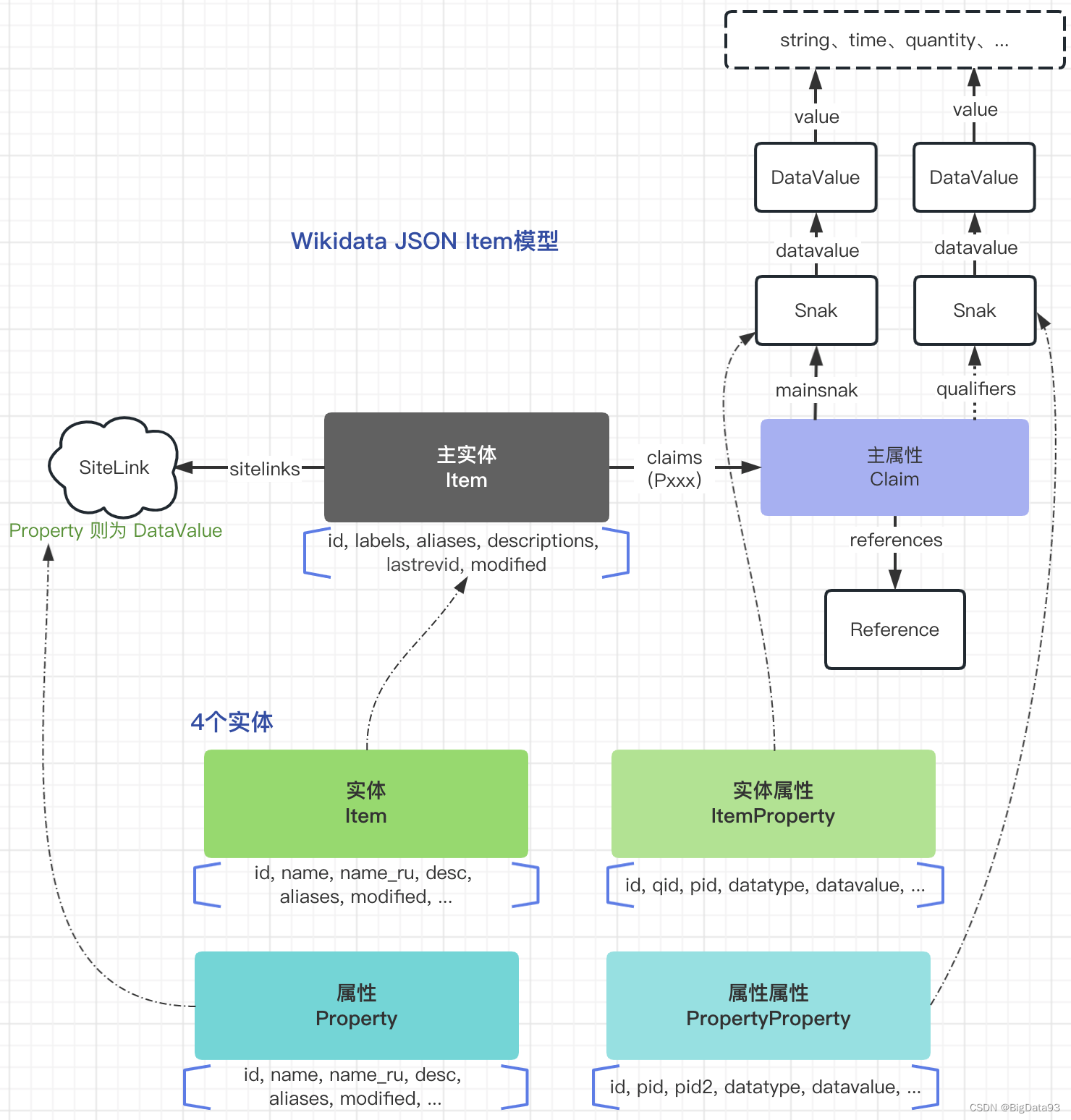
按照上图下半部分的抽取demo,就可以选择 olap 进行建表,并写 MR/Spark 等程序的方式解析 JSON,分层抽取需要的数据导入到数据库中做查询或数仓分层建设了。
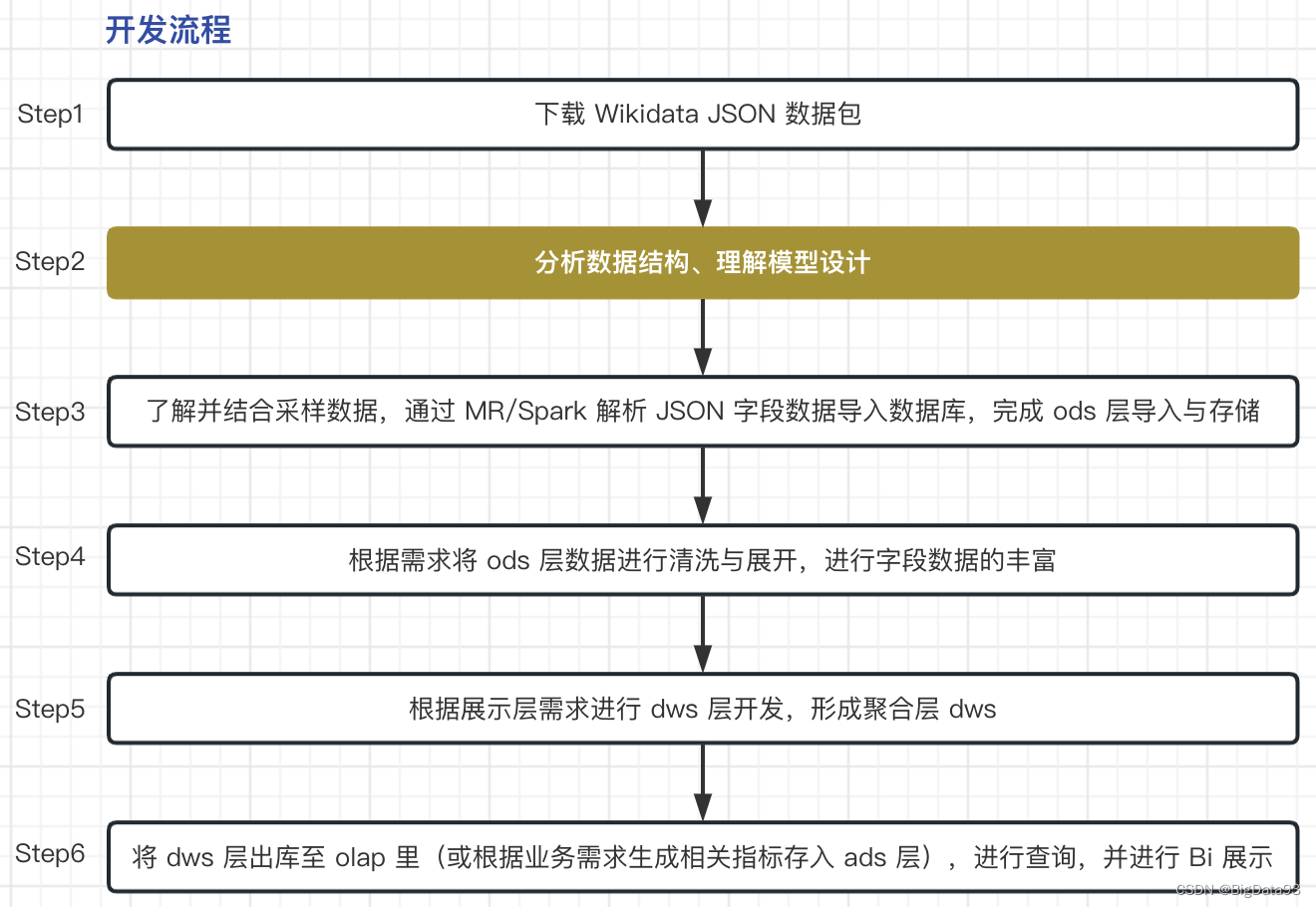
5. 开发流程
以下只是一份开发流程的样例,仅供参考,具体以实际需求为准:
Tip:官网数据模型介绍
官网:https://www.mediawiki.org/wiki/Wikibase/DataModel/Primer
Wikibase/DataModel/Primer
这是Wikibase数据模型的入门。要了解更多的技术规范,请查看数据模型规范。
This is a primer to the Wikibase data model. For a more technical specification please check the data model specification.
数据模型的摘要 Summary of the data model
维基知识库的内容可以概括如下:
Wikibase knowledge base content can be summarized as follows:
维基数据库知识库是实体的集合。
A Wikibase knowledge base is a collection of Entities.
实体是知识库的基本元素,可以使用Wikibase数据模型对其进行描述和引用。
Entities are the basic elements of the knowledge base, which can be described and referenced using the Wikibase data model.
有两种预定义的实体类型:项和属性。
There are two predefined kinds of Entities: Items and Properties.
维基基础可以扩展以支持其他类型的实体。
Wikibase may be extended to support additional types of Entities.
项目和属性的描述结构如下。
The description of Items and Properties are structured as follows.
-
项 Item
-
项目标识符(以Q开头的数字) Item identifier (number prefixed with Q)
-
指纹,包括: Fingerprint, consisting of:
-
多语言标签* Multilingual label*
-
多语言描述* Multilingual description*
-
多语种的别名 Multilingual aliases
-
-
语句,每个语句由: Statements, each consisting of:
-
索赔,包括: Claim, consisting of:
-
财产 Property
-
价值 Value
-
限定符(额外的属性-值对) Qualifiers (additional property-value pairs)
-
-
引用(每个引用由一个或多个属性值对组成)
References (each consisting of one or more property-value pairs) -
排名 Rank
-
-
网站的链接 Site links
-
-
财产 Property
-
属性标识符(以P前缀的数字) Property identifier (number prefixed with P)
-
指纹,包括: Fingerprint, consisting of:
-
多语言标签* Multilingual label*
-
多语言描述* Multilingual description*
-
多语种的别名 Multilingual aliases
-
-
语句,每个语句由: Statements, each consisting of:
-
索赔,包括: Claim, consisting of:
-
财产 Property
-
价值 Value
-
限定符(额外的属性-值对) Qualifiers (additional property-value pairs)
-
-
引用(每个引用由一个或多个属性值对组成)
References (each consisting of one or more property-value pairs) -
排名 Rank
-
-
数据类型 Datatype
-
*)除非实体的标签 和/或 描述不是空的,在实体类型范围内,实体的某种语言的标签和描述的组合必须是唯一的。
*) Unless label and/or description of an entity are not empty, within the scope of an entity type, an entity’s combination of label and description in a certain language must be unique.
项目 Items
维基百科的一个页面描述一个项目。
One page in Wikibase describes one item.
条目是Wikibase指的任何感兴趣的东西,通常是维基百科文章的内容。
Items are the way Wikibase refers to anything of interest, and usually are the things that Wikipedia articles are about.
在维基百科中,我们会有一个关于柏林的条目,这个条目的意思是不同语言中与这个条目相关的维基百科文章的主题。
So in Wikibase we will have an item for Berlin, and what we mean with this item is the topic of the Wikipedia articles linked to this item in the different languages.
维基百科的文章可以确定条目的含义。
The Wikipedia articles identify the meaning of an item.
每个项目都有一个标签(一个名称)和一个描述,在维基基础的每种语言。
Every item has a label (a name) and a description in each language of Wikibase.
仅仅是标签是不够的,因为它可能是模棱两可的:柏林可以指德国首都,美国十几个城市之一,一张Lou Reed的专辑,一个美国新浪潮乐队,或者许多其他东西。
Just the label would not be enough as it may be ambiguous: Berlin could refer to the capital of Germany, one of more than a dozen cities in the US, a Lou Reed album, an American new wave band, or many other things.
标签和描述应该一起识别项目的含义,例如,标签“柏林”和描述“德国的一个城市”应该在每种语言中都是唯一的。
The label and the description together should identify the meaning of an item, e.g. the label “Berlin” and the description “A city in Germany” should be uniquely identifying in each language.
除了标签之外,项还可以有别名,别名为要查找的项提供替代名称。
In addition to labels, items can have aliases which provide alternative names for an item to be found.
“George H. W. Bush”也可能出现在“George Bush”下面,他的儿子也可能出现在“George Bush”下面。
“George H. W. Bush” might also be found under “George Bush”, and so might his son.
别名旨在为用户提供搜索便利,就像维基百科上的重定向一样,因此即使是流行的拼写错误也可以用作别名。
Aliases are meant to offer the user search convenience, much like redirects on Wikipedia, and thus even popular misspellings may be used as aliases.
符号接地问题 The symbol grounding problem
如果你仔细阅读,你会注意到维基百科的链接和标签加描述都能识别条目的含义。
If you are following carefully you will notice that both the Wikipedia links and label plus description identify the meaning of an item.
不仅如此:他们在所有语言中都这样做!
And not only that: they do that in all languages!
因此,这些标识符可能会不同步:德文维基百科链接可能指向肯塔基州的柏林,而英文描述可能是“德国首都”。
It can thus happen that these identifiers get out of sync: the German Wikipedia link might point to Berlin, Kentucky and the English description might say “Capital of Germany”.
这是真的,并且在系统中没有实现任何东西来防止它:没有语言和标识机制具有优先级。
This is true, and there is nothing implemented in the system to prevent it: no language and no identifying mechanism has precedence over the other.
这里我们遇到了符号接地问题。
Here we are running into the symbol grounding problem.
我们在维基基础上解决这个问题的方法是有意地提供多种方法来识别条目的含义,并相信维基基础的编辑们会想出一种社会技术机制来很好地解决这个问题。
The path we are taking in Wikibase to address this problem is by deliberatively providing multiple ways to identify the meaning of an item and trust that Wikibase editors will come up with a socio-technical mechanism to solve it well enough for the Wikibase use cases.
语句 Statements

其中一项要求是,“维基百科不是关于真相,而是关于陈述及其引用。”
One of the requirements is that “Wikibase will not be about the truth, but about statements and their references.”
这意味着在Wikibase中,我们实际上并不对条目本身建模,而是对它们的陈述建模。
This means that in Wikibase we do not actually model the items themselves, but statements about them.
我们不是说柏林有350万人口,而是说根据德国统计局的数据,2011年柏林的人口是350万。
We do not say that Berlin has a population of 3,5 M, we say that there is this statement about Berlin’s population being 3,5 M as of 2011 according to the German statistical office.
语句可以由以下内容组成
A statement may consist of
- 一个属性(在本例中为“population”)
one property (in the example, “population”) - 一个值(3,5 M)
one value (3,5 M) - 可以选择一个或多个限定符(在本例中,“截至2011”是其中一个限定符)
optionally one or more qualifiers (in this example, “as of 2011” is one of the qualifiers) - 可选的一个或多个参考资料(德国统计局)
optionally one or more references (the German statistical office)
属性、值和限定符一起也称为声明,它们与任何源引用一起构成语句。
The property, value, and qualifiers together are also called the claim, which together with any source references forms a statement.
对于同一个属性可以有多个陈述:人们可以有几个孩子,一本书可能有几个作者。
There can be several statements about the same property: people can have several children, books might have several authors.
此外,对于一个城市的人口,可能会有不同的观点——例如,官方数据和联合国的估计。
Also, there might be diverging points of view on the population of a city – official numbers and UN estimates, for example.
或者可能存在带有不同限定符的值,比如时间点或测量方法。
Or there might be values with different qualifiers, like points in time or measurement methods.
下面是一些例子。
For a few examples, see below.
属性在Wikibase中它们自己的wiki页面上进行描述。
Properties are described on their own wiki pages in Wikibase.
属性也有标签和描述,除此之外,它们还具有与之关联的数据类型,可能还有其他属性。
Properties also have labels and descriptions, and additionally to that they also have a data type associated with them and perhaps additional properties.
数据类型定义与此属性一起使用的值的类型。
The data type defines the type of the value used with this property.
这组属性由Wikibase编辑创建和维护。
The set of properties is created and maintained by the Wikibase editors.
值本身可以是非常简单的(如另一个项目或字符串),也可以是非常复杂的(如地理形状、具有单位和精度的测量或时间段)。
Values themselves can be either very simple – another item or just a string – or quite complex beasts, like a geographic shape, a measurement with a unit and an accuracy, or a time period.
我们将在以后的页面中更详细地描述这些值。
We will describe values in more detail in their own page in the future.
数据类型集(大部分)是预定义的。
The set of data types is (mostly) predefined.
有两个特殊的值,基本上与它们的数据类型无关:none和unknown。
There are two special values, mostly regardless of their data type: none and unknown.
None意味着我们知道给定的财产没有价值,例如,英国的伊丽莎白一世没有配偶。
None means that we know that the given property has no value, e.g., Elizabeth I of England had no spouse.
Unknown表示该属性有一个值,但不知道是哪个值——例如,Pope Linus的出生年份是确定的,但我们不知道。
Unknown means that the property has a value, but it is unknown which one – e.g., Pope Linus certainly had a year of birth, but it is unknown to us.
这不应该与不知道某项是否具有特定属性的值的概念混淆,例如,如果一个人有孩子。
This should not be mixed up with the notion that it is unknown whether an item has a value for a specific property, e.g., if a person had children.
none和unknown也不要与各自的字符串混淆:名称“unknown”不同于名称未知(这再次不同于实体是否有名称未知)。
Both none and unknown are also not to be confused with the respective string: having the name “unknown” is different from having an unknown name (which is again different from it being unknown whether the entity has a name).
参考文献提供了支持给定主张的来源。
References offer a source that supports the given claim.
一个语句可以有多个引用。
There can be several references given for a statement.
我们仍在研究如何进一步构建参考文献,但一般来说,它们会指向一个来源(这将是一个维基基础项目本身的权利:一本书,一个网站,等等),并有进一步的信息,比如支持该声明的页面。
We are still working on how to further structure a reference, but in general they will point to a source (which would be a Wikibase item in its own right: a book, a website, etc.) and have further information, like the page where the claim is supported.
没有参考的主张不一定是错误的,有参考的主张也不一定是正确的。
A claim without references is not necessarily wrong, nor is a claim with references true.
是否相信这种说法,仍然取决于该声明的读者。
It is still up to the reader of the statement to decide if they want to trust the claim.
我们将在以后的页面中更详细地描述参考文献。
We will describe references in more detail in their own page in the future.
限定符 Qualifiers
限定符用于进一步描述或优化语句中给定的属性的值。
Qualifiers are used to further describe or refine the value of a property given in a statement.
它们由属性和值组成,这与语句相同。
They consist of a property and a value, which are the same as for statements.
如果我们可以用简单的属性-值对来表示维基数据库用例所需的所有数据,这将是很方便的,但不幸的是,情况并非如此。
While it would be convenient if we could express all the data we need for the use cases of Wikibase with simple property-value pairs, this is unfortunately not the case.
许多语句需要进一步的限定符才能表示。
Many statements require further qualifiers in order to be expressed.
为了将属性的数量减少到可管理的大小,可以使用限定符以某种方式进一步指定语句。
In order to reduce the number of properties to a manageable size, qualifiers are used to further specify the statement in some way.
限定符可以以多种方式使用,如下面的示例所示。
Qualifiers can be used in a number of ways, as shown by the following examples.
限定符可以修改条目的含义(“法国:面积213010平方英里-不包括阿德利辽阔的土地”)、属性(“柏林:人口350万-方法估计”)、约束值的有效性(“德国:人口8000万-截至2011年”),或提供进一步的细节(“奥地利:宗教天主教徒-百分比64,8%”或“金手指:演员肖恩·康纳利-角色詹姆斯·邦德”),等等。
A qualifier can modify what the item means (“France: Area 213,010 sq mi - excluding Adélie Land”), the property (“Berlin: Population 3,500,000 - method Estimation”), constrain the validity of the value (“Germany: Population 80,000,000 - as of 2011”), or offer further details (“Austria: Religion Catholic - Percentage 64,8%” or “Goldfinger: Actor Sean Connery - Role James Bond”), etc.
一个包罗万象的限定符应该是“注解”或类似的东西。
A catch-all qualifier is expected to be “annotation” or something similar.
它向维基数据库社区开放,以一种对他们和他们的用例有意义的方式维护和使用限定符。
It is open to the Wikibase community to maintain and use qualifiers in a way that makes sense to them and for their use cases.
限定词是语句的一个组成部分:去掉限定词,语句的意义就改变了。
The qualifier is an integral part of the statement: take away the qualifier, and the meaning of the statement is changed.
对于参考文献来说,这一点就不那么正确了。
This is far less true for the references.
排名 Ranks
由于给定的项目和属性可能有许多不同的语句,因此我们需要在询问维基数据库时选择返回哪些语句。
As there are potentially many different statements for a given item and property, we need to select which ones to return when Wikibase gets asked.
为了方便起见,引入了三层语句。
In order to facilitate this, three ranks of statements are introduced.
每个等级中可以有任意数量的语句,但是在每个等级中,它们的顺序是不重要的。
There can be any number of statements in each rank, but within each rank, their order is not significant.
-
首选语句:如果存在首选语句,则在响应查询时返回这些语句。例如,对于一个人口来说,只要它被认为足够可靠,它们就会包含最近的数据。维基数据库编辑可能会决定将几个语句标记为首选:这可能用于表示不同意,反映对该问题的知识多样性,也可能用于表达实际上具有多个值的概念(例如“children”属性)。
Preferred statements: if preferred statements exist, these statements are returned in response to a query.They would, e.g. for a population contain the most recent one as long as it is regarded as sufficiently reliable. Wikibase editors might decide to mark several statements as preferred: this may be used to indicate disagreement, reflecting the knowledge diversity on the issue, or it may be used to express the notion of actually having multiple values (in case of properties like “children”). -
普通语句:如果没有首选语句(或者查询显式地说也包括普通语句),则返回这些语句。历史价值,如一个国家过去的人口,可能在这里,以及不太具有代表性的来源,但仍然被认为是相关的。
Normal statements: if there are no preferred statements (or the query explicitly says to include normal statements too), these statements are returned. Historical values, like the population of a country in the past, might be here, as well as less representative sources which are still considered relevant. -
已弃用语句:用于正在讨论的语句,或已知错误的语句,但为了完成或为了防止不断添加和删除它们而仍然列出。弃用语句只有在显式添加或根据其来源选择时才会出现在搜索结果中。脚注限定符通常应该与其他顺序的语句一起使用。
Deprecated statements: for statements that are being discussed, or known to be erroneous, but still listed for the sake of completion or in order to prevent them being constantly added and removed. Deprecated statements only appear in search results if they are explicitly added or if they are selected based on their source. A footnote qualifier should usually accompany other-ranked statements.
在Wikibase中,排名也用于使显示更清晰。
Within Wikibase, the ranks are also used to make the display cleaner.
默认情况下,只显示首选语句,读者必须点击“更多值”这样的链接才能看到正常排名的语句。
Only the preferred statements are displayed by default, and the reader has to click on a link like “more values” in order to see the normal-ranked statements.