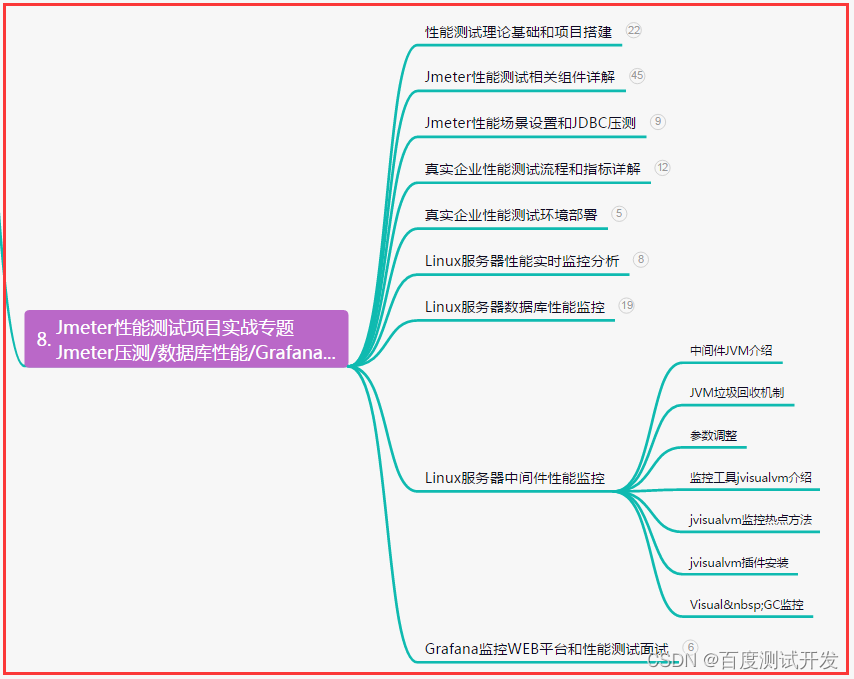
1.它其实就是一个数据读取或者写入的一个缓冲区
2.基本的操作步骤:
- 向buffer写入数据,例如调用channel.read(buffer)
- 调用flip()切换至读模式
- 从buffer读取数据,例如调用buffer.get()
- 调用clear()或者compact()切换至写模式
- 重复以上步骤
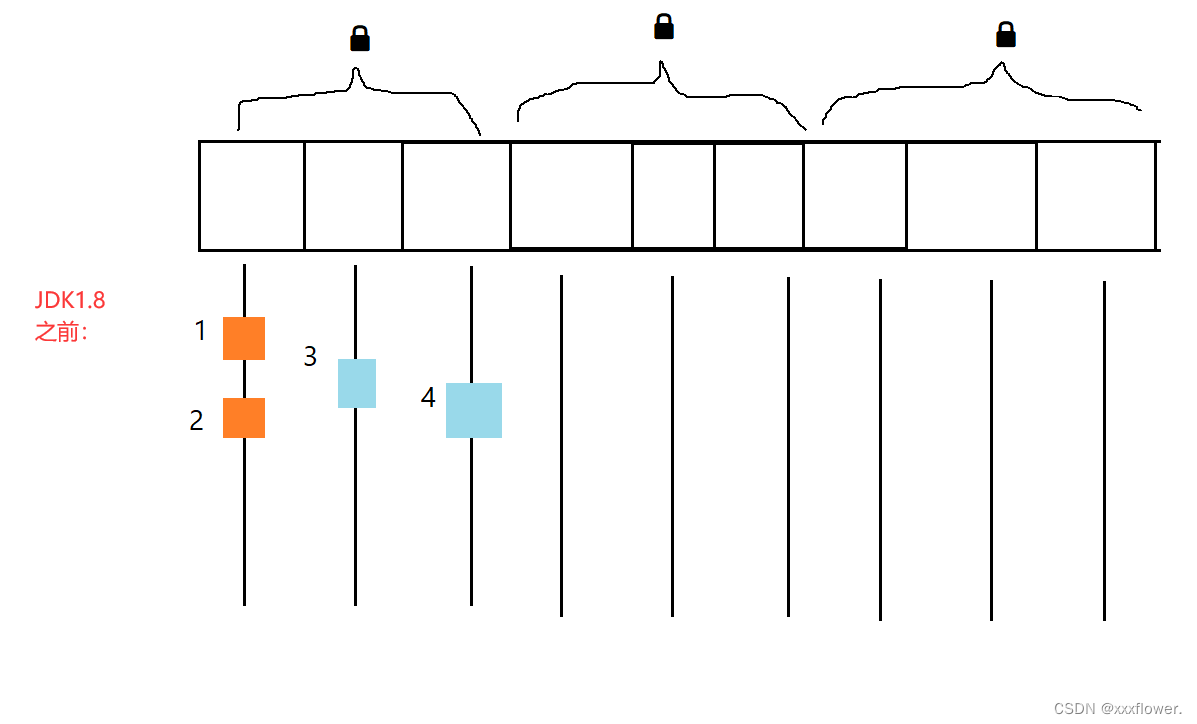
3.内部结构
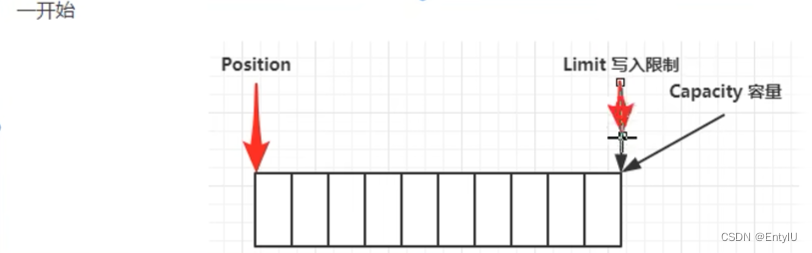
写模式下:每写一次,position就会往右移动一次
读模式下:limit会立马指向最后一个数据的下标位置,每读一次,position向后移动一位
4.ByteBuffer有两种不同的类型:
ByteBuffer.allocate(1).getClass()//这种方式获取的buffer是基于堆内存的,因为会受到gc垃圾回收的影响,重新移动位置后,会出现一个拷贝的步骤,这样也就会出现一个性能损耗,读写效率低一些
ByteBuffer.allocateDirect(1).getClass()//这种方式是直接基于系统内存的,读写效率较高,但是因为基于系统内存,分配时,需要调用一些系统方法去分配,所以分配效率较低,这样一来的话,也就很容易出现一个内存泄露的问题,使用后必须及时释放掉
4.常用方法:
- 向buffer中写入数据,使用channel的read方法或者buffer自己的put方法
- 从buffer中读取数据,使用channel的write方法或者是buffer自己的get方法
- 如果读取后希望重新读,可以使用rewind,可以将position移动到下标0的位置,或者是get(i),这样读取的话,就不会出现position往后移动的过程了
- 如果希望做一个标记,然后过一会需要的时候再回到标记处继续读,可以使用mark做一个标记,然后继续往下读,哪怕position位置发生了变化,只要再调用一个reset方法,就可以让position的位置回到下标0处
5.字符串类型和buffer的相互转换
(一)字符串转buffer:
//1.使用buffer的put方法
ByteBuffer s=ByteBuffer.allocate(11);
s.put("hello".getBytes());
//2.使用charset,可以把字符串转换为buffer并且,把buffer的模式变为读模式
ByteBuffer hello = StandardCharsets.UTF_8.encode("hello");
//3.wrap,可以把字符串转换为buffer并且,把buffer的模式变为读模式
ByteBuffer buffer=ByteBuffer.wrap("hell".getBytes());(二)buffer转buffer
String s1 = StandardCharsets.UTF_8.decode(buffer).toString();
//注意,这里转换的buffer必须已经设置为了读取模式,否则什么也读不到




![[蓝帽杯 2022 初赛]之Misc篇(NSSCTF)刷题记录(复现)⑨](https://img-blog.csdnimg.cn/0400354708144ba7b95f3d7560635eb8.png)