STL——适配器篇
- 1、List
- STL list 容器介绍
- list使用
- 2、适配器介绍
- 3、Deque容器
- Stack、Queue适配器实现
1、List
STL list 容器介绍
STL list 容器,又称双向链表容器,即该容器的底层是以双向链表的形式实现的。这意味着,list 容器中的元素可以分散存储在内存空间里,而不是必须存储在一整块连续的内存空间中。
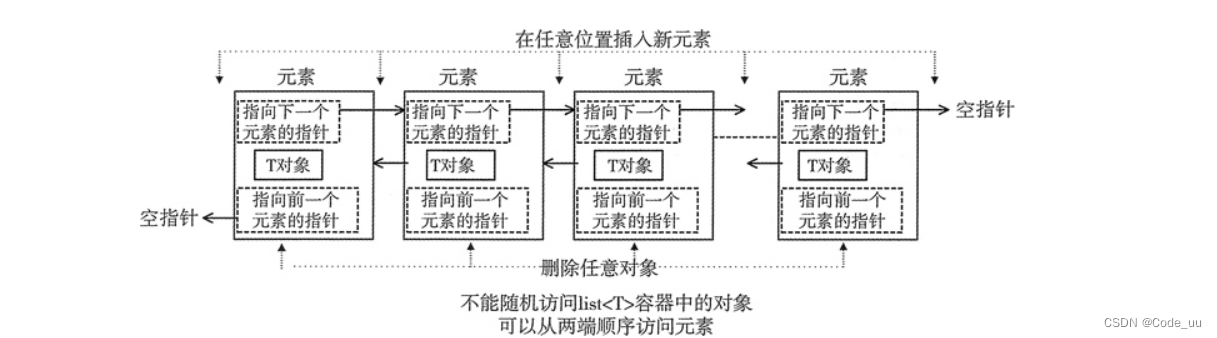
可以看到,list 容器中各个元素的前后顺序是靠指针来维系的,每个元素都配备了 2 个指针,分别指向它的前一个元素和后一个元素。其中第一个元素的前向指针总为 null,因为它前面没有元素;同样,尾部元素的后向指针也总为 null。
基于这样的存储结构,list 容器具有一些其它容器(array、vector 和 deque)所不具备的优势,即它可以在序列已知的任何位置快速插入或删除元素(时间复杂度为O(1))。并且在 list 容器中移动元素,也比其它容器的效率高。
使用 list 容器的缺点是,它不能像 array 和 vector 那样,通过位置直接访问元素。
list使用
1、list构造
| 构造函数 | 接口介绍 |
|---|---|
| list (size_type n, const value_type& val = value_type()) | 构造的list中包含n个值为val的元素 |
| list() | 构造空的list |
| list (const list& x) | 拷贝构造函数 |
| list (InputIterator first, InputIterator last) | 用[first, last)区间中的元素构造list |
list<int> l1; // 构造空的l1
list<int> l2(4, 100); // l2中放4个值为100的元素
list<int> l3(l2.begin(), l2.end()); // 用l2的[begin(), end())左闭右开的区间构造l3
list<int> l4(l3); // 用l3拷贝构造l4
2、list迭代器
| begin + end | 返回第一个元素的迭代器+返回最后一个元素下一个位置的迭代器 |
|---|---|
| rbegin + rend | 返回第一个元素的reverse_iterator,即end位置,返回最后一个元素下个位置的reverse_iterator,即begin位置 |
void PrintList(const list<int>& l)
{
// 注意这里调用的是list的 begin() const,返回list的const_iterator对象
for (list<int>::const_iterator it = l.begin(); it != l.end(); ++it)
{
cout << *it << " ";
}
cout << endl;
}
void TestList2()
{
int array[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 0 };
list<int> l(array, array + sizeof(array) / sizeof(array[0]));
// 使用正向迭代器正向list中的元素
// list<int>::iterator it = l.begin(); // C++98中语法
auto it = l.begin(); // C++11之后推荐写法
while (it != l.end())
{
cout << *it << " ";
++it;
}
cout << endl;
// 使用反向迭代器逆向打印list中的元素
// list<int>::reverse_iterator rit = l.rbegin();
auto rit = l.rbegin();
while (rit != l.rend())
{
cout << *rit << " ";
++rit;
}
cout << endl;
}
3、增删查改
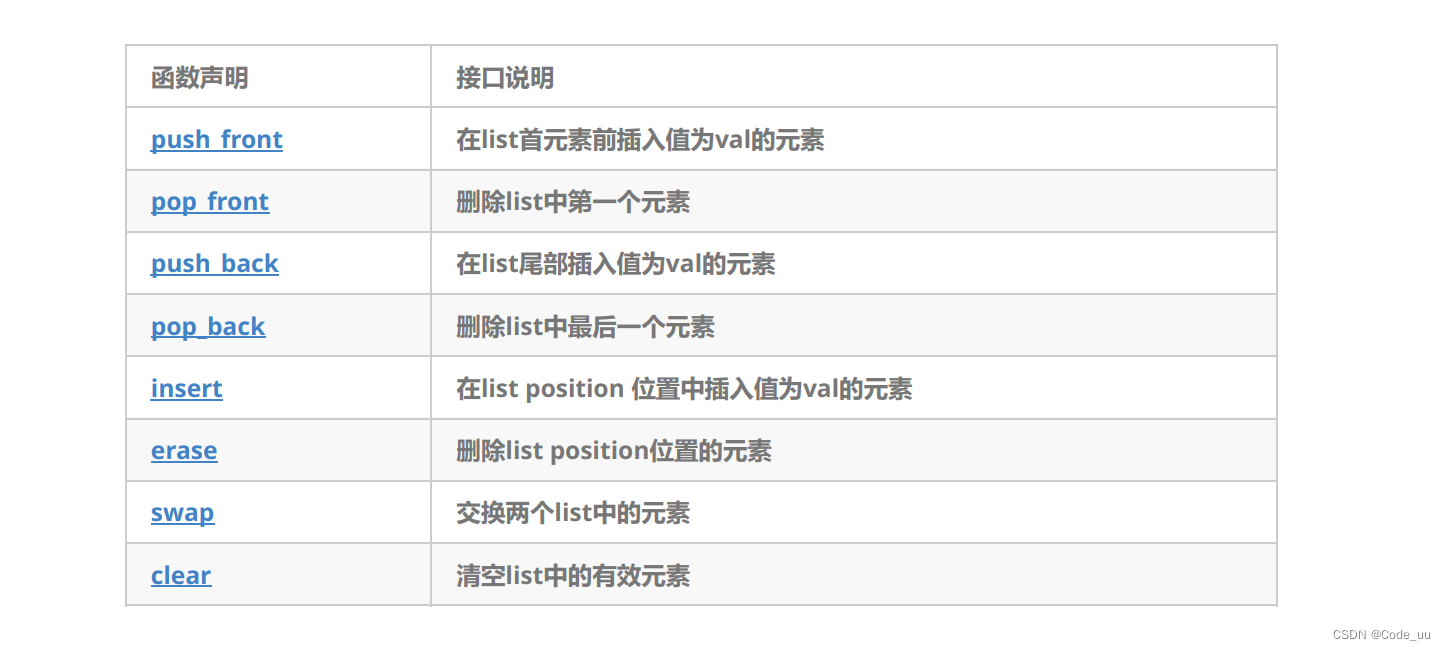
int main()
{
int arr[] = {0 };
int n = sizeof(arr) / sizeof(arr[0]);
list<int> lt(arr, arr + n);
list<int> list(10,1);//使用10个1初始化list
lt.push_front(2);
PrintList(lt);
lt.push_back(1);
PrintList(lt);
lt.pop_back();
PrintList(lt);
lt.pop_front();
PrintList(lt);
lt.insert(lt.begin()++, 2);
PrintList(lt);
lt.erase(lt.begin());
PrintList(lt);
lt.swap(list);
PrintList(lt);
lt.clear();
PrintList(lt);
return 0;
}
运行结果参考:

2、适配器介绍
适配器就是接口,对容器、迭代器、算法进行包装,但其实质还是容器、迭代器和算法,只是不依赖于具体的标准容器、迭代器和算法类型。概念源于设计模式中的适配器模式:将一个类的接口转化为另一个类的接口,使原本不兼容而不能合作的类,可以一起运作。
容器适配器可以理解为容器的模板,迭代器适配器可理解为迭代器的模板,算法适配器可理解为算法的模板。
在数据结构中就有着对于栈、队列的结构实现,有物理结构连续的(数组结构),不连续的(链表结构)。底层结构就决定了效率问题。对于OPP语言就有些许不方便使用。
3、Deque容器
特定的库可能以不同的方式实现deque,通常是某种形式的动态数组。但在任何情况下,它们都允许通过随机访问迭代器直接访问单个元素,并根据需要通过扩展和收缩容器来自动处理存储。因此,它们提供了类似于vector的功能,但在序列的开始部分,而不仅仅是在序列的末尾,都可以有效地插入和删除元素。但是,与vector不同,deque不能保证将其所有元素存储在连续的存储位置:通过偏移指向另一个元素的指针来访问deque中的元素会导致未定义的行为。vector和deque都提供了非常相似的接口,可以用于类似的目的,但两者在内部的工作方式却大不相同:vector使用单个数组,偶尔需要为增长重新分配,而deque的元素可以分散在不同的存储块中,容器内部保留必要的信息,以便在恒定时间内使用统一的顺序接口(通过迭代器)直接访问其任何元素。因此,deque在内部比vector更复杂,但这使得它们在某些情况下更有效地增长,特别是对于非常长的序列,重新分配变得更加昂贵。对于涉及频繁插入或删除除开始或结束位置以外的元素的操作,deque的性能更差,迭代器和引用的一致性也不如列表和前向列表。
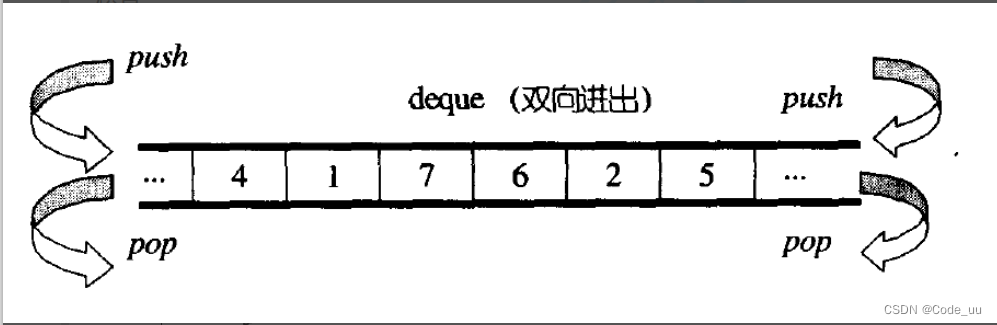
deque并不是真正连续的空间,而是由一段段连续的小空间拼接而成的,实际deque类似于一个动态的二维数组
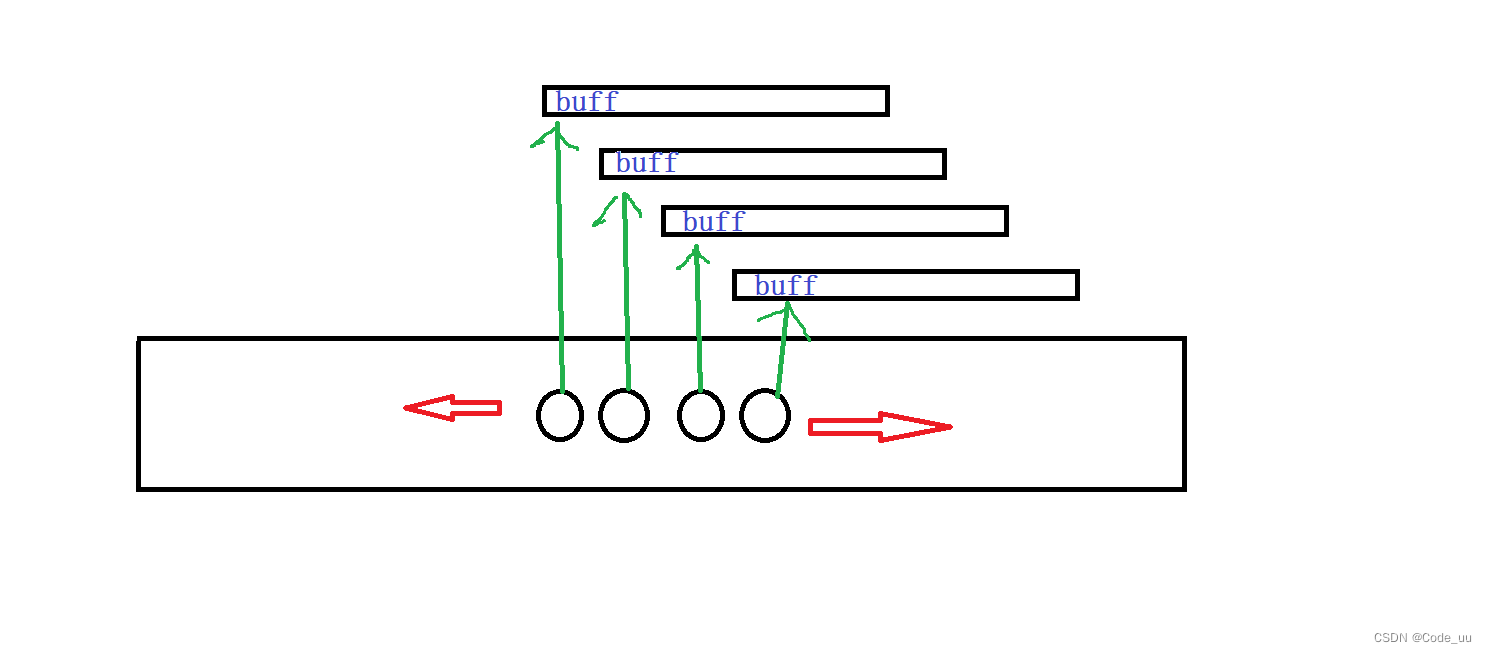
与vector比较,deque的优势是:头部插入和删除时,不需要搬移元素,效率特别高,而且在扩容时,也不需要搬移大量的元素,因此其效率是必vector高的。
与list比较,其底层是连续空间,空间利用率比较高,不需要存储额外字段。
但是,deque有一个致命缺陷:不适合遍历,因为在遍历时,deque的迭代器要频繁的去检测其是否移动到某段小空间的边界,导致效率低下,而序列式场景中,可能需要经常遍历,因此在实际中,需要线性结构时,大多数情况下优先考虑vector和list,deque的应用并不多,而目前能看到的一个应用就是,STL用其作为stack和queue的底层数据结构。
Stack、Queue适配器实现
namespace uu
{
#include<deque>
//第一个模板参数是类型,第二个是容器类型
template<class T, class Con = deque<T>>
class stack
{
public:
stack()
{
}
void push(const T& x)
{
_c.push_back(x);
}
void pop()
{
_c.pop_back();
}
T& top()
{
return _c.back();
}
const T& top()const
{
return _c.back();
}
size_t size()const
{
return _c.size();
}
bool empty()const
{
return _c.empty();
}
private:
Con _c;
};
template<class T, class Con = deque<T>>
class queue
{
public:
queue()
{
}
void push(const T& x)
{
_c.push_back(x);
}
void pop()
{
_c.pop_front();
}
T& back()
{
return _c.back();
}
const T& back()const
{
return _c.back();
}
T& front()
{
return _c.front();
}
const T& front()const
{
return _c.front();
}
size_t size()const
{
return _c.size();
}
bool empty()const
{
return _c.empty();
}
private:
Con _c;
};
void test_queue()
{
queue<int> q;
q.push(1);
q.push(2);
q.push(3);
q.push(4);
while (!q.empty())
{
cout << q.front() << " ";
q.pop();
}
cout << endl;
}
void test_stack()
{
stack<int> st;
st.push(1);
st.push(2);
st.push(3);
st.push(4);
st.push(5);
cout << st.size() << endl;
while (!st.empty())
{
cout << st.top() << " ";
st.pop();
}
cout << endl;
}
};
运行结果:

为什么选择deque作为stack和queue的底层默认容器
stack是一种后进先出的特殊线性数据结构,因此只要具有push_back()和pop_back()操作的线性结构,都可以作为stack的底层容器,比如vector和list都可以;queue是先进先出的特殊线性数据结构,只要具有push_back和pop_front操作的线性结构,都可以作为queue的底层容器,比如list。但是STL中对stack和queue默认选择deque作为其底层容器,主要是因为:
- stack和queue不需要遍历(因此stack和queue没有迭代器),只需要在固定的一端或者两端进行操作。
- 在stack中元素增长时,deque比vector的效率高(扩容时不需要搬移大量数据);queue中的元素增长时,deque不仅效率高,而且内存使用率高。
结合了deque的优点,而完美的避开了其缺陷。










![[数据库系统] 一、外键约束 (educoder)](https://img-blog.csdnimg.cn/6c7e65a18cfe4bf4a3fda4506bfca48e.png)