Domain shift: Training and testing data have different distributions.
Transfer learning:在A任务上学到的技能,可以被用在B任务上
Domain Adaptation的技术,可以看作是Transfer learning的一种

Domain Adaptation:

第一种情况,有少量带有标注的target domain的资料

第二种情况,在target domain上有大量的没有标注的资料

在第二种情况下,最原始的做法如下:
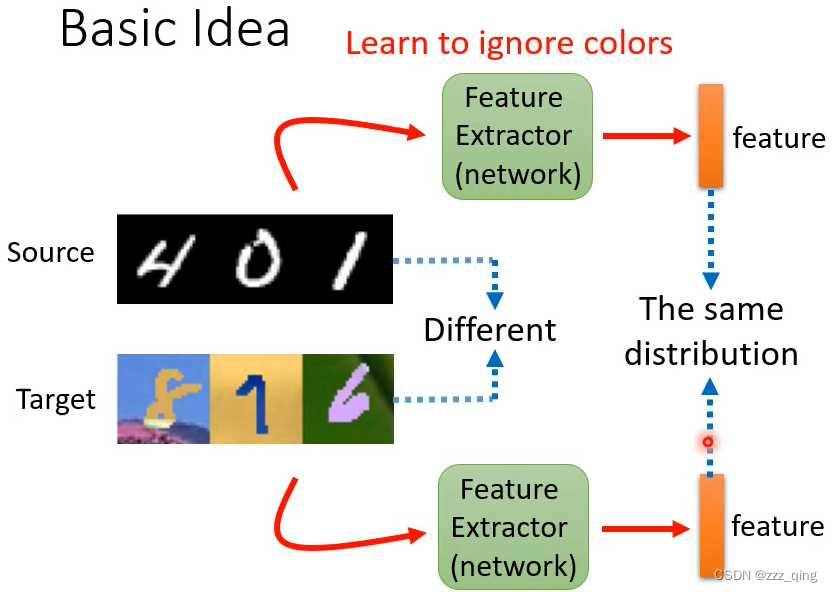
我们希望source domain的资料经过feature extractor后的output(feature extractor的output),和target domain的资料经过feature extractor后的output,它们分不出差别,即下图中红色和蓝色的点分不出差别:
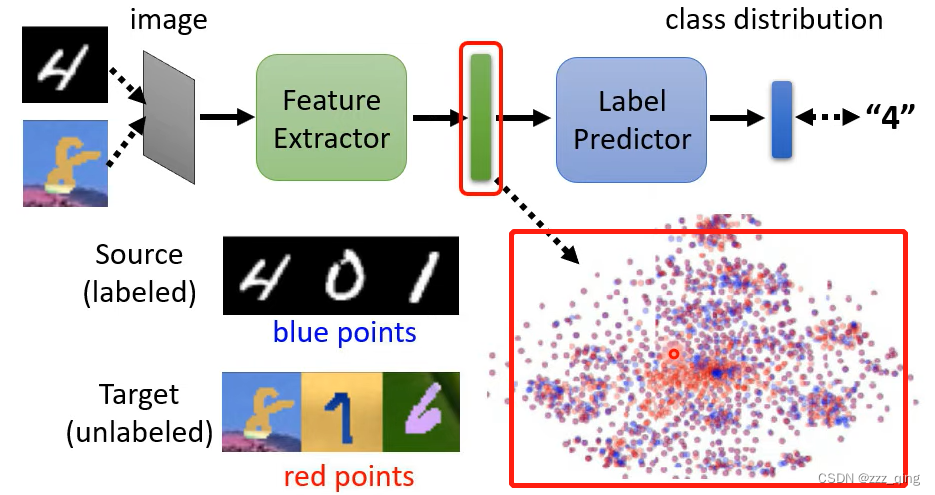
如何让红色和蓝色的点分不出差别——Domain Adversarial Training。
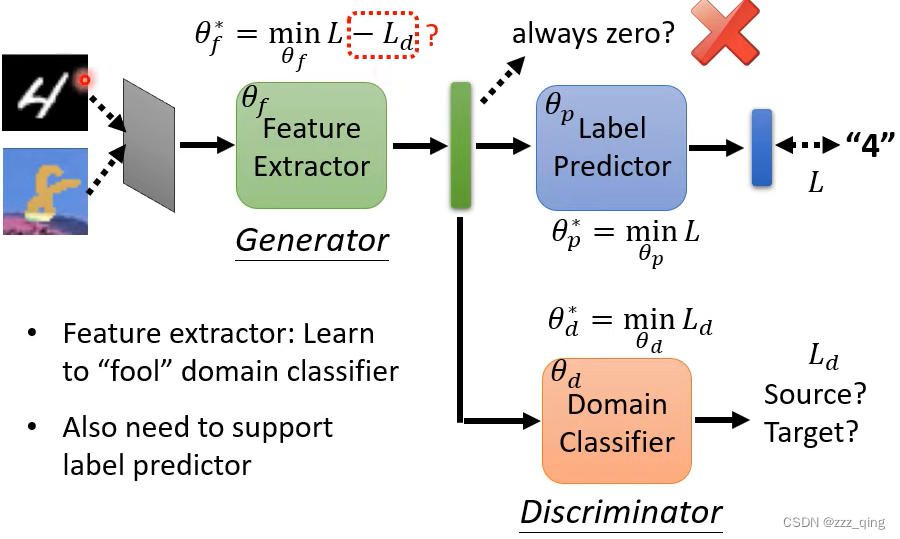
feature extractor的输出不会总是为zero,去骗过domain classifier,因为它的输出还要去minimize label predictor的loss。
feature extractor的loss有下图中红色框圈出的-Ld这一项,但这不是很好的loss公式,因为当domain classifier把source domain的资料分类为target domain、把target domain的资料分类为source domain的时候,-Ld的值很小,满足minimize feature extractor loss的要求,但此时domain classifier实际上还是能把source domain和target domain的资料分开。
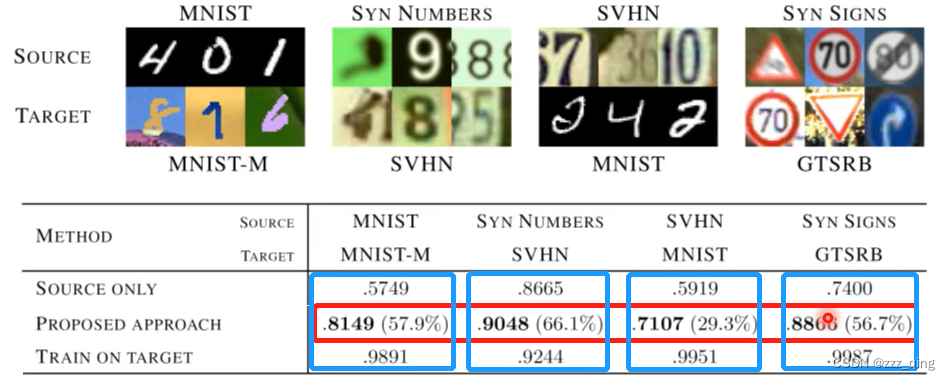
Domain Adversarial Training最原始的paper的结果如下:
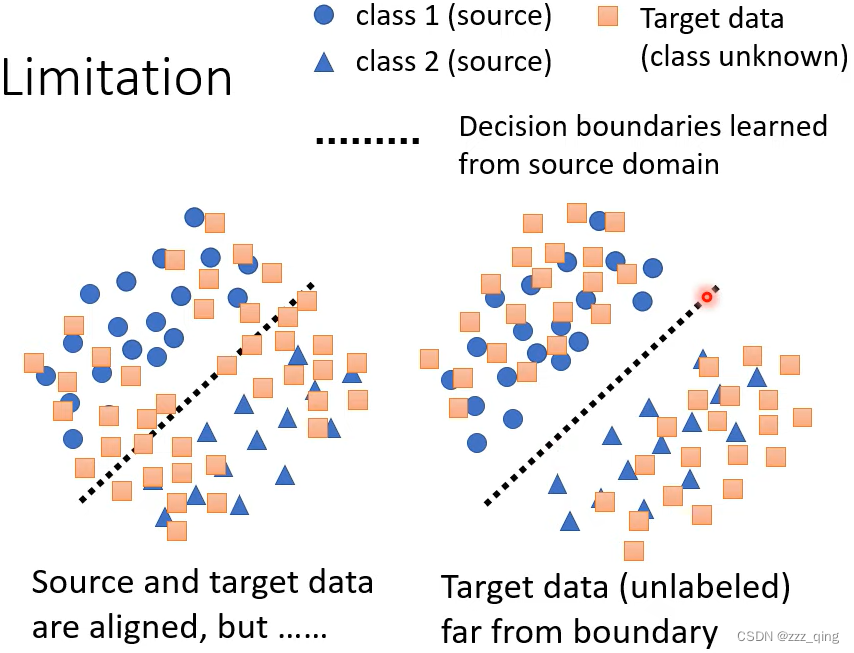
对于target data,我们希望它的分布接近下图右边的状况,考虑decision boundary:

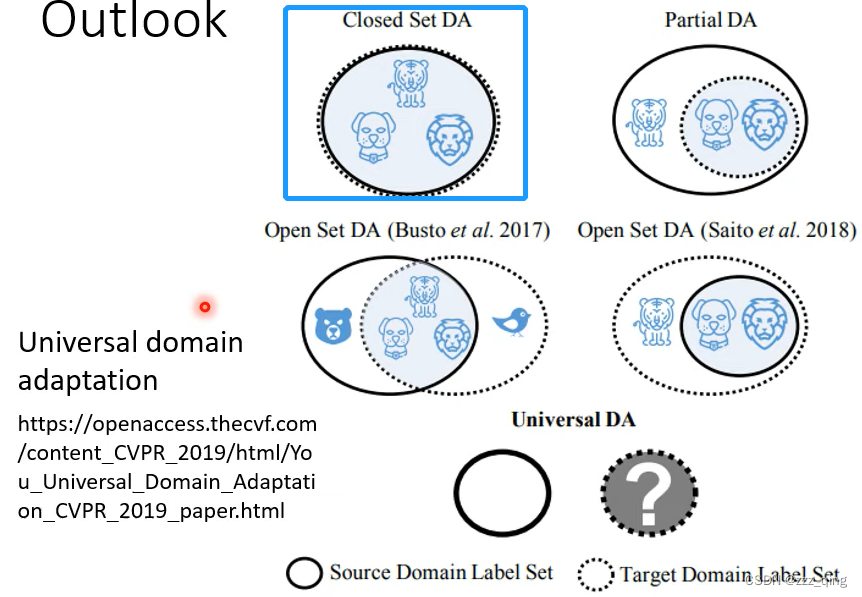
在Domain Adversarial Training中,我们默认source domain和target domain的类别都是一样的,但实际情况中它们的类别可能不一样。这是一个需要解决的问题,解决方法参见论文universal domain adaptation:
第三种情况,target domain只有很少的unlabeled的data。解决方法参见论文Testing Time Training。
第四种情况,对target domain一无所知。这时候不叫domain adaptation,而叫做domain generalization。domain generalization分成两种状况。
一种状况是训练资料非常丰富,有多个domain,期待model能够根据有多个domain的训练资料,学到如何弭平domain间的差异。
另一种状况是训练资料只有一个domain,而测试资料有多种不同的domain。 解决办法:用data augmentation的方法去产生多个domain的资料,接下来的做法同上面的状况。










![[数据库系统] 一、外键约束 (educoder)](https://img-blog.csdnimg.cn/6c7e65a18cfe4bf4a3fda4506bfca48e.png)