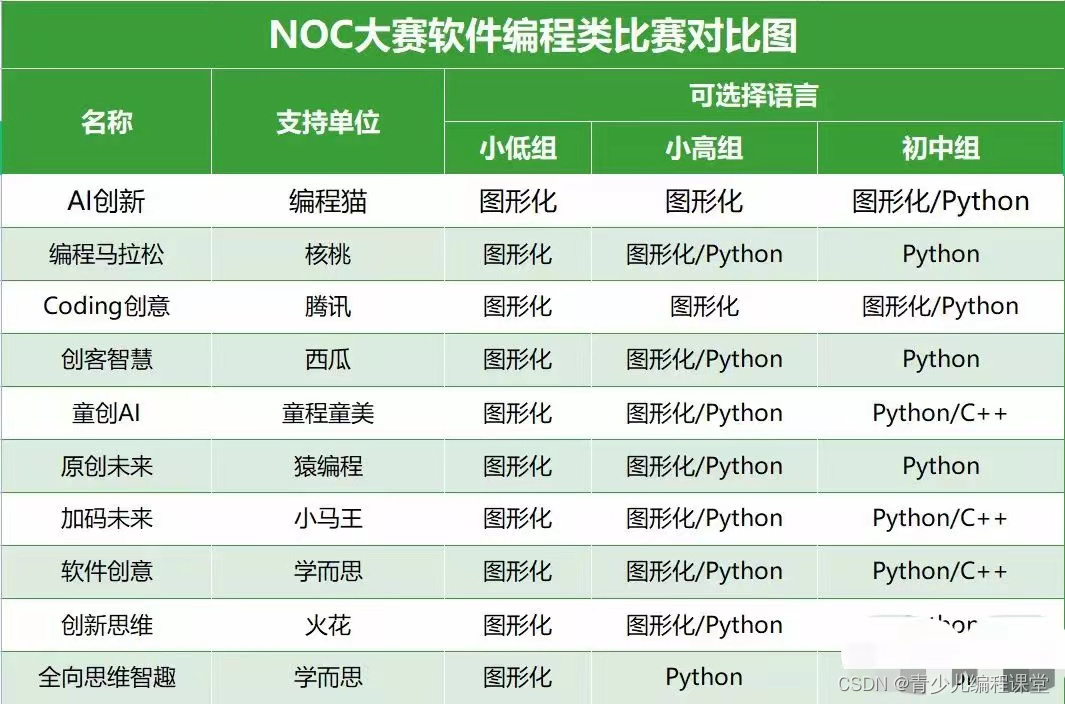
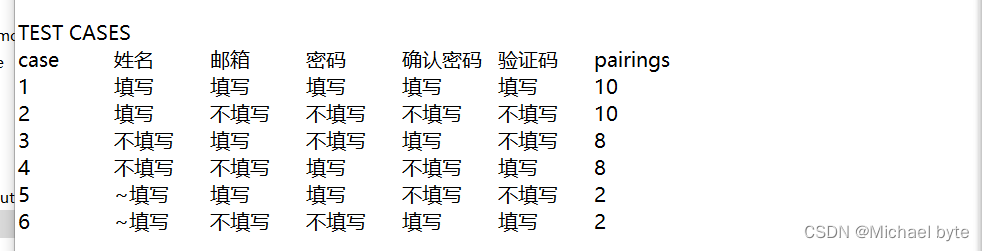
目录
What is RL? (Three steps in ML)
Policy Gradient
Actor-Critic
Reward Shaping
No Reward: Learning from Demonstration
It is challenging to label data in some tasks. 例如下围棋时,下一步下在哪个位置最好是不太好确定的,此时可以考虑使用RL。
What is RL? (Three steps in ML)
machine learning ≈ looking for a function
RL作为机器学习的一种,它也在找一个function:Actor

下面会用space invader这个小游戏和围棋对RL的整体流程进行举例说明:

Example 1: playing video game

Example 2: learning to play Go

下面介绍RL和机器学习的framework之间的关系:
machine learning有三个步骤:

RL也是和machine learning一模一样的三个步骤:
Step 1: Function with Unknown. 如下图绿框,在多数RL应用里面,都是采取sample,而不是取得分最大的那个值。采取sample可以加入一些随机性,对很多游戏来说,这种随机性是重要的。

Step 2: Define “Loss”

Step 3: Optimization. RL在这一步,困难的是,它要解的不是一个一般的optimization的问题。这里存在很多问题导致它和一般的network training不太一样。
第一个问题是Actor的输出具有随机性,下图中的ai是随机产生的。
第二个问题是environment和reward不是network,environment是一个黑盒子,而reward是一个规则。并且environment和reward往往也是具有随机性的。

所以RL真正的难点:怎么解optimization的问题。
Policy Gradient
——做RL的optimization常用的一个演算法
How to control actor:
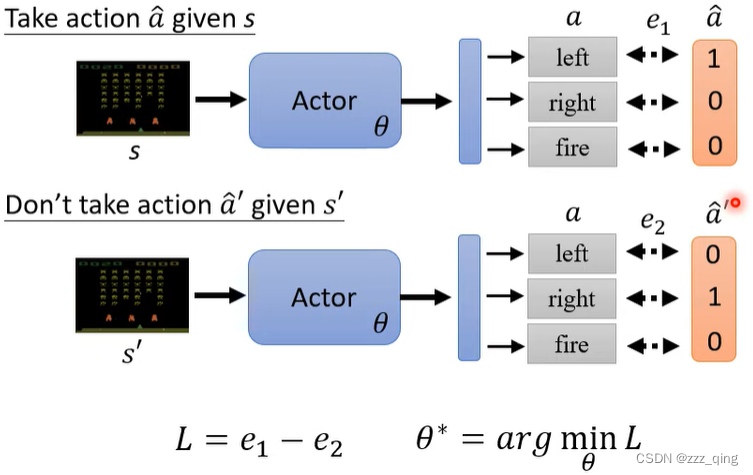

如何收集训练资料s和a的pair:用一个actor去跟环境做互动,就可以收集到s和a的pair

接下来是关于如何去定义A,有几个不同的版本(不同rl的方法,其实就是对A做文章,有不同的定义A的方法):
version 0: (一个短视的版本)

An action affects the subsequent observations and thus subsequent rewards.
Reward delay: Actor has to sacrifice immediate reward to gain more ng-term reward.
In space invader, only “fire” yields positive reward, so vision 0 will learn an actor that always “fire”.
version 1:
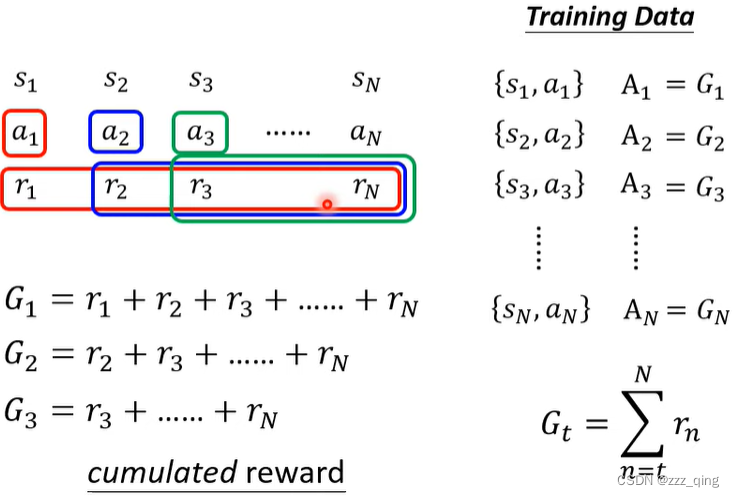
version 2:

version 3: (在version 2的基础上对A做标准化)

上面介绍的是大的概念,下面介绍policy gradient实际上是怎么操作的:
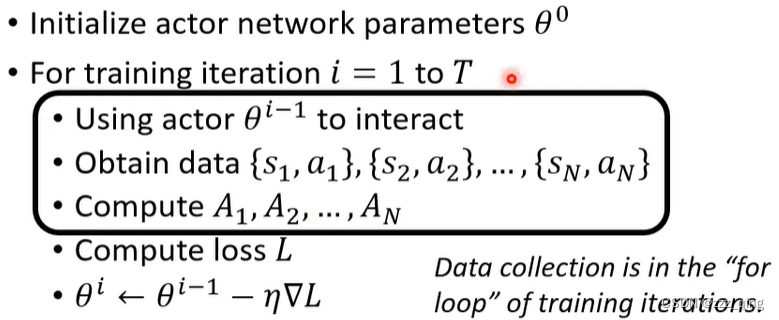

The actor to train and the actor for interacting is the same. → On-policy
Can the actor to train and the actor for interacting be different? → Off-policy
Off-policy → Proxima Policy Optimization(PPO): The actor to train has to know its difference from the actor to interact.
On-policy vs.Off-policy
对于Off-policy,不需要update一次就收集一次data:

另一个重要的概念是exploration:actor在采取行为的时候,具有一些随机性。这个随机性非常重要,很多时候如果随机性不够,会train不起来。

Actor-Critic
Critic的工作是去评估一个actor的好坏。
Critic: Given actor θ, how good it is when observing s (and taking action α)
下面介绍value function这个critic:

discounted cumulated reward是指G':
![]()
下面介绍critic是怎么被训练出来的,有两种常用的训练方法:
① Monte-Carlo(MC) based approach
The critic watches actor θ to interact with the environment.
需要玩完整场游戏去得到训练资料。

② Temporal-difference (TD) approach

同样的问题,用MC和TD分别去计算,算出来的value function很有可能是不同的。举例如下:

下面介绍critic怎么被用在训练actor上面:
对于version 3中b的值如何计算,在version 4中给出了答案:


训练Actor-Critic的小技巧:The parameters of actor and critic can beshared.
Actor和Critic都是network。Actor这个network的输入是一个游戏画面,输出是每一个action的分数。Critic这个network的输入也是一个游戏画面,输出是一个scalar,代表接下来会得到的cumulative的reward。这两个network的输入是一样的东西,所以这两个network有部分参数可以共用:
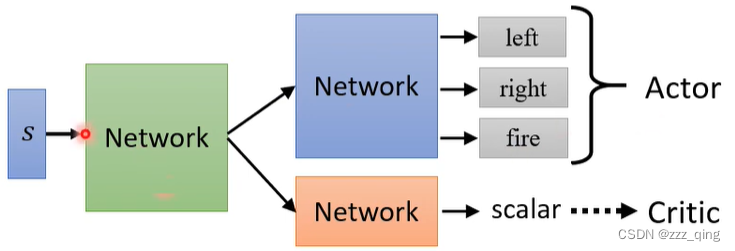
Reward Shaping
Sparse Reward:

Reward shaping在VizDoom这个游戏上的实例如下:

Reward shaping有个特别知名的做法,叫做curiosity based的reward shaping:Obtaining extra reward when the agent sees something new (but meaningful).
No Reward: Learning from Demonstration
有时候在RL里面,会有没有reward的情况,原因有两点:
- Even define reward can be challenging in some tasks
- Hand-crafted rewards can lead to uncontrolled behavior
在没有reward的情况下,如何训练一个actor去和环境互动:
方法一:Imitation Learning
有expert的示范,此时这是一个supervised learning,也叫做behavior cloning。

例如self-driving:

让机器去复制expert的行为,可能带来的一个问题是,expert和机器,他们可能可以观察到的s是不一样的。还是以self-driving为例,机器和人类expert学习开自驾车,人类expert在转弯的时候,都能顺利通过弯道,所以对机器来说,它从来没有看过转弯失败的情况,那机器就不知道当车子转弯失败快要撞墙的时候如何处理。
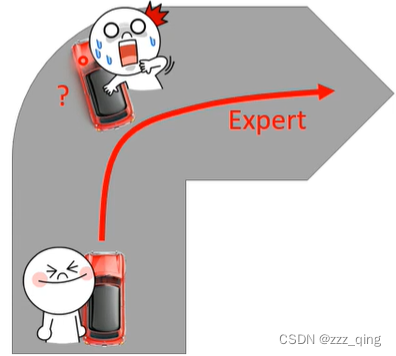
第二个可能遇到的问题是,人类expert在开车的时候可能很厉害,但也许不是每一个行为机器都需要去完全模仿。假设expert有一部分行为是机器要去学习的,另一部分机器学习了没什么作用,但是机器无法分辨它要学哪些行为,只能全部进行学习。更惨的情况是机器学习能力有限,但它恰好学到的是没什么意义的那些行为。
方法二:Inverse Reinforcement Learning
Reinforcement Learning:

Inverse Reinforcement Learning:


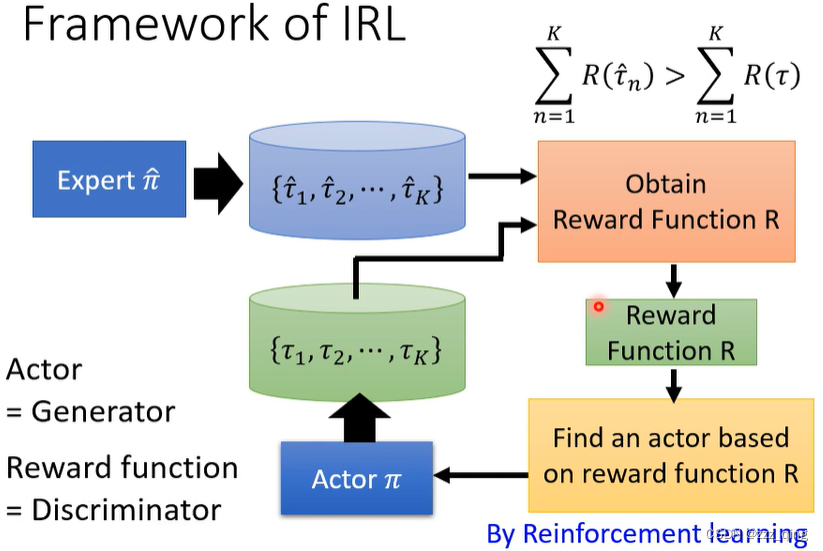
下面是图像化的方法介绍IRL的framework:
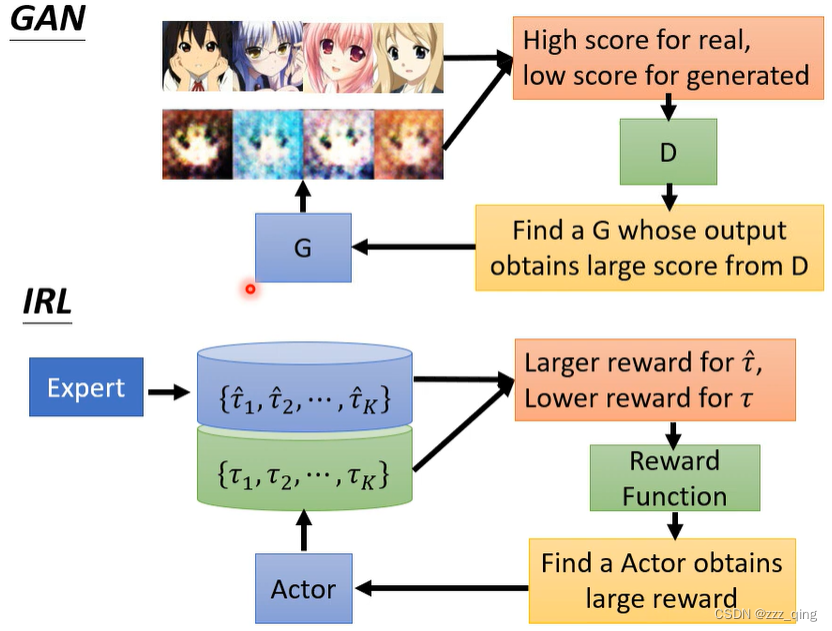
GAN v.s. IRL: 它们可以理解为同一个framework,用不同的方法、不同的角度去描述
IRL这种方法,常常被用来训练机器手臂。未来我们可能可以用demonstrate的方法教机器事情。也可以给机器一个画面,让机器去做画面中的行为。








![C嘎嘎~~ [类 下篇之运算符重载]](https://img-blog.csdnimg.cn/7a2a80049044454e9edb8de6c6241cea.png)