文章目录
- (零)前言
- (一)潜变量成对(Latent Couple)
- (1.1)可自组LoRA(Composable LoRA)
- (二)分区扩散(Multi Diffusion)
- (2.1)区域提示控制(Region Prompt Control)
- (三)分区域提示词(Regional Prompter)
- (3.1)蒙版分割+提示词分割
- (四)总结
(零)前言
本篇主要提到几个插件,可以让一张图中包含多个人物,我也企图包含多个LoRA模型人物,但目前并不完美。
更多不断丰富的内容参考:🔗《继续Stable-Diffusion WEBUI方方面面研究(内容索引)》
(一)潜变量成对(Latent Couple)
参考:https://github.com/ashen-sensored/stable-diffusion-webui-two-shot
可以从WEBUI中直接安装。
其实它的仓库名字是“双人特写”,用法参考官网。
也可以看看这位同学的 Bilibili的教程视频,我觉得写得很详细了。
简单说大概是用参数:
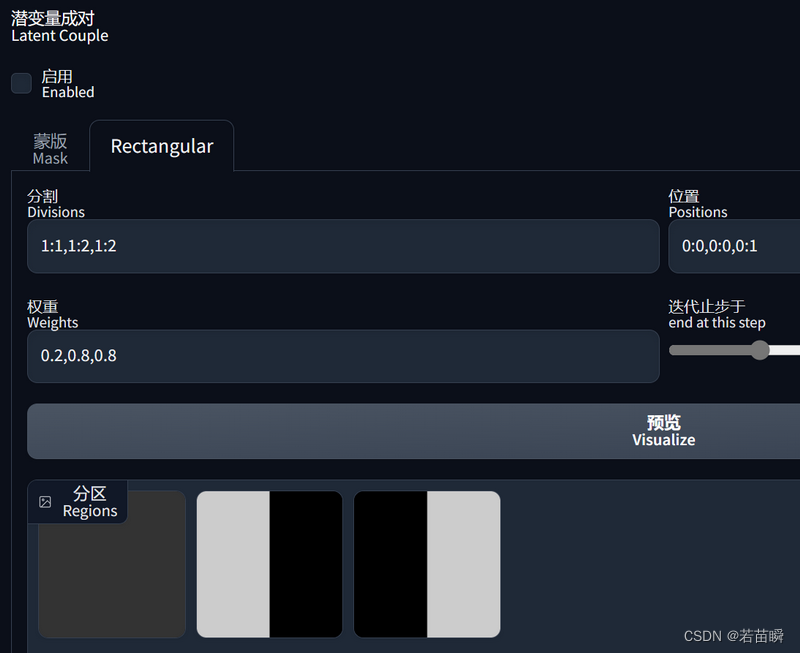
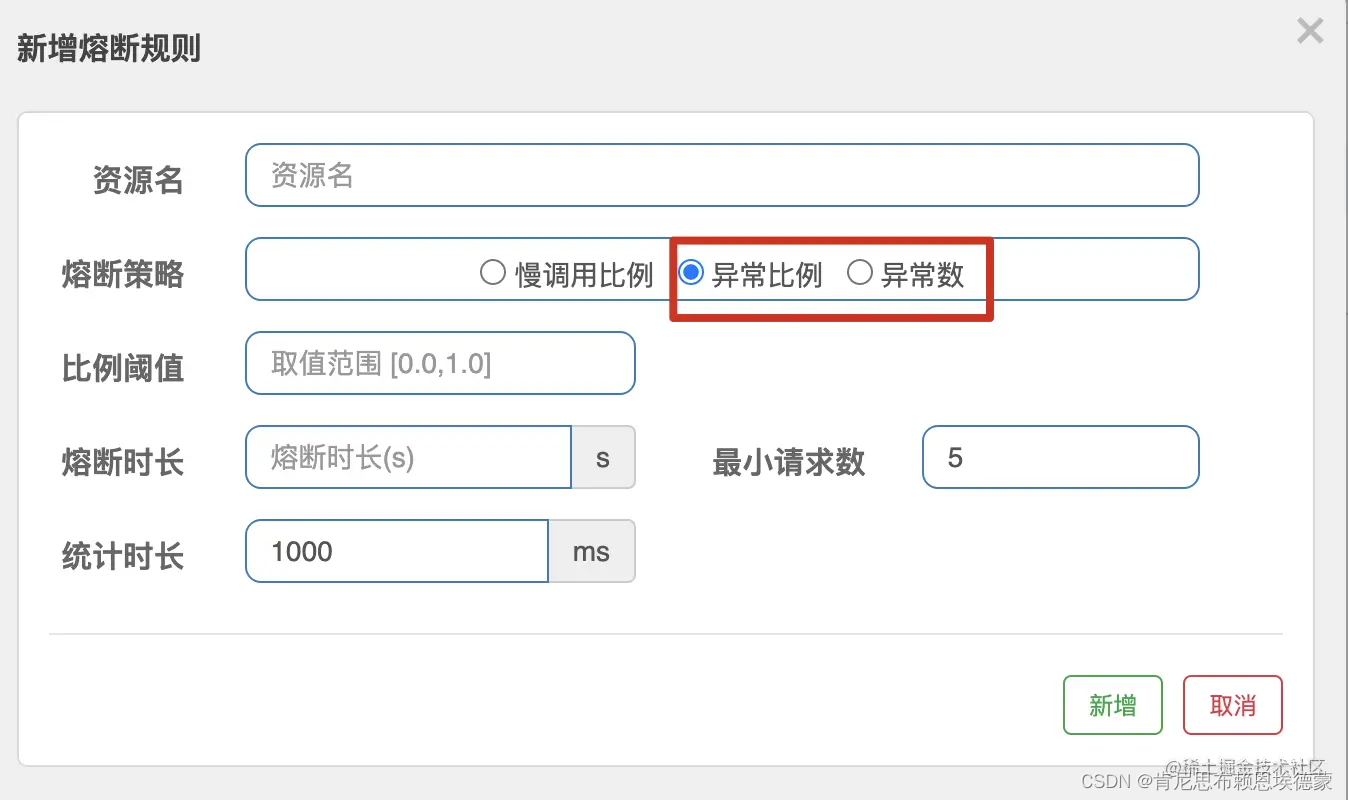
- 分割(Divisions),比如:
1:1,1:2,1:2,意思:整体区域,一半区域,一半区域。 - 位置(Positions),比如:
0:0,0:0,0:1,各个区域(这里3个区域)的起始位置坐标x:y。 - 权重(Weights),比如:
0.2,0.8,0.8,各个区域提示词的权重。 - 迭代止步于(end at this step),分区迭代多少步数。
哦,对了,它可以把你写的参数转换为区域的预览图(方便检查是否正确):
再配合提示词写为{全局提示词} AND {区域1提示词} AND {区域2提示词}来配对上面的区域划分。比如:
2girls, upper body, outdoors, blurry background
AND 2girls, upper body, outdoors, blurry background, <lora:FBB_v1.0:0.7>
AND 2girls, upper body, outdoors, blurry background, <lora:XYJY_v1.0:0.7>
再配合下面的【可自组LoRA】插件,画出了下面的2者都不像图片😓,嗯?:
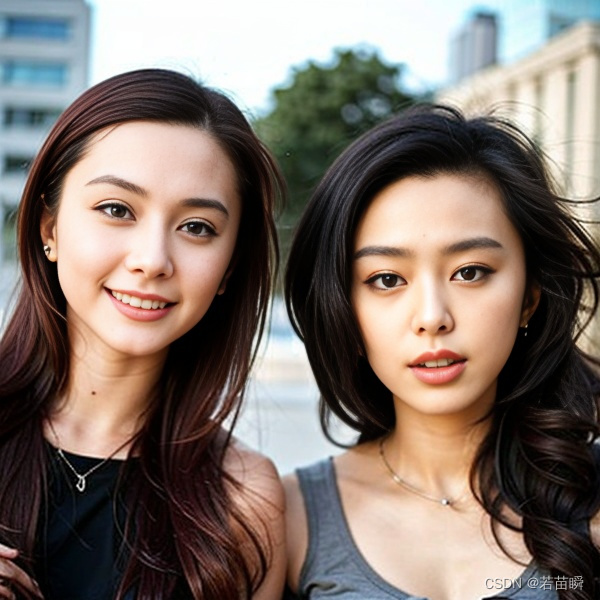
(1.1)可自组LoRA(Composable LoRA)
参考:https://github.com/opparco/stable-diffusion-webui-composable-lora
可以从WEBUI中直接安装。
不装这个插件的话【潜变量成对】也能用,但是不能处理LoRA模型。
装了它以后,虽然看别人的二次元动漫很完美,可是真人LoRA画出来就是不像。
选项就启动第一个,不需要截图了吧。
(二)分区扩散(Multi Diffusion)
参考:https://gitcode.net/ranting8323/multidiffusion-upscaler-for-automatic1111
可以从WEBUI中直接安装。
参考官网,它的功能其实不只是分区域的提示词,主要功能包括:
- 生成大型图像(以及放大图像)
- 极大降低VAE编解码大图所需的显存开销
- 区域提示控制
(2.1)区域提示控制(Region Prompt Control)
其他部分功能参考官网吧,这里不提了。
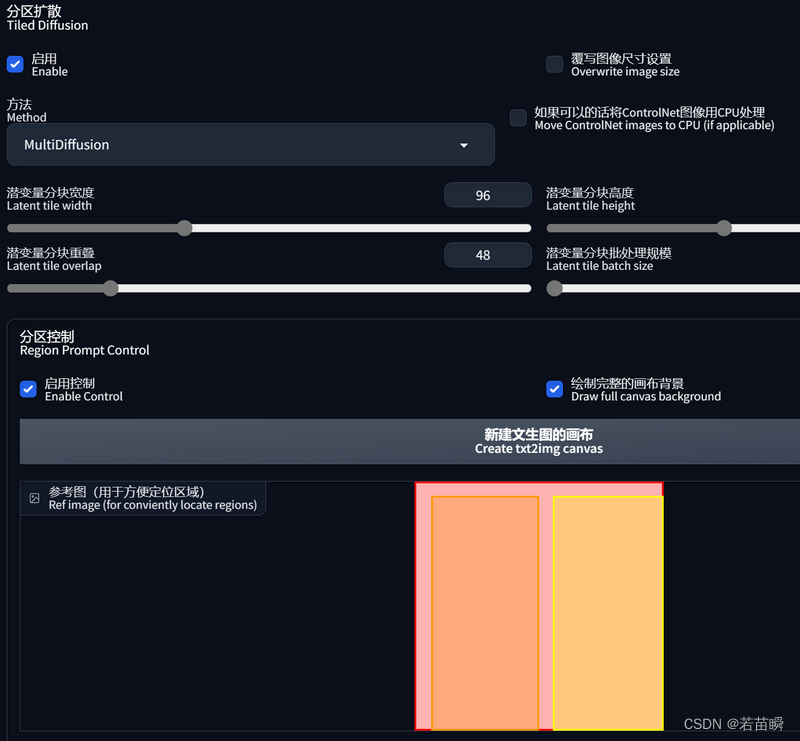
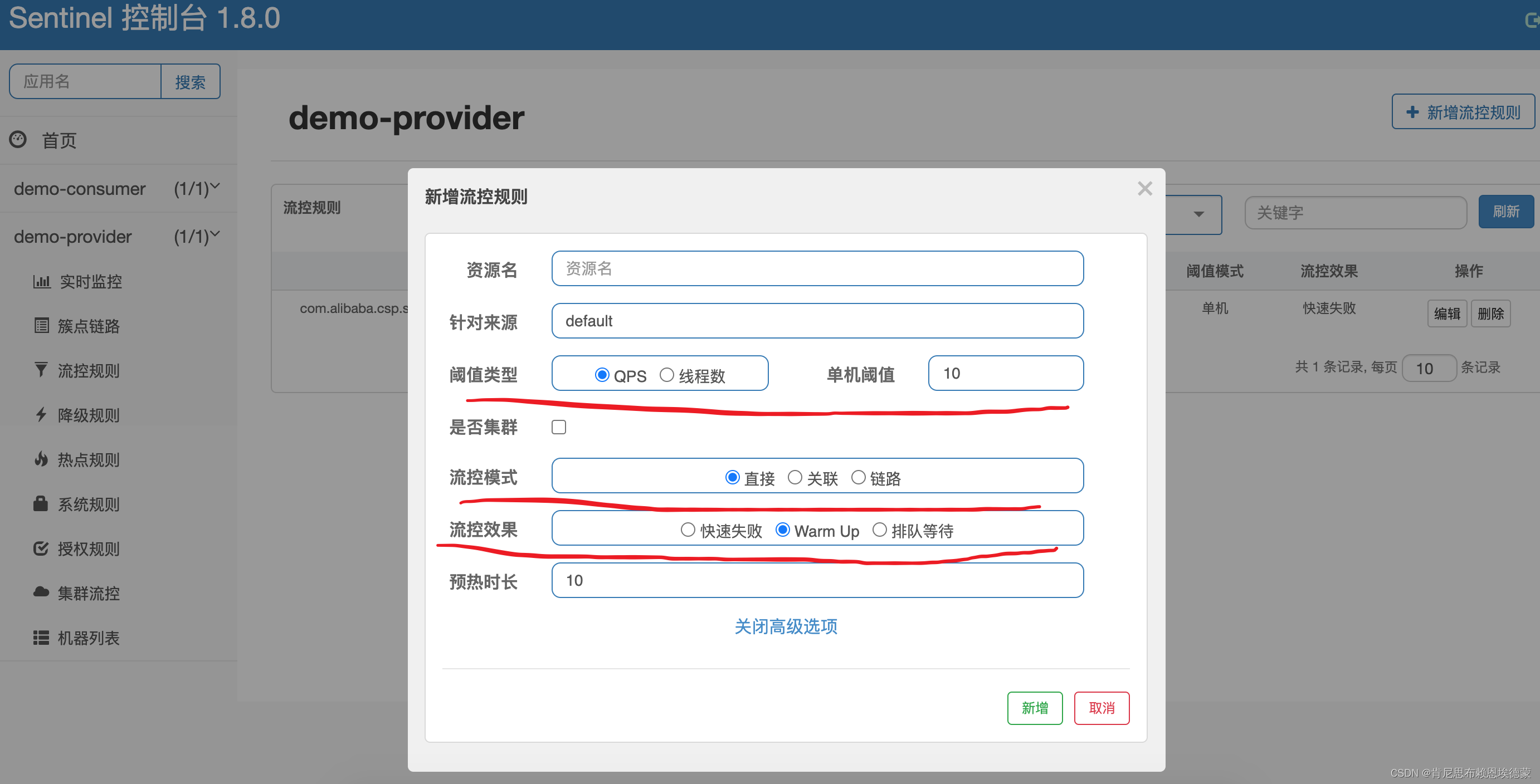
这个区域提示控制部分的特点是,你可以画区域,而不是写参数,所以非常直观,如下图:
第一个区域设置为背景(红框)
第二个区域设置为前景(橙框)
第三个区域设置为前景(黄框)
提示词和前面一样,只是需要分别写入你激活区域对应地方就OK。生成结果如下:
人物甚至背景总是分得很开(依然不像)。

(三)分区域提示词(Regional Prompter)
参考:https://github.com/hako-mikan/sd-webui-regional-prompter
可以从WEBUI中直接安装。
用法稍微复杂一点点,之前也是用参数控制区域,分横竖方向和进阶的网格区域。
官方的例子详细解释了怎么分区的。
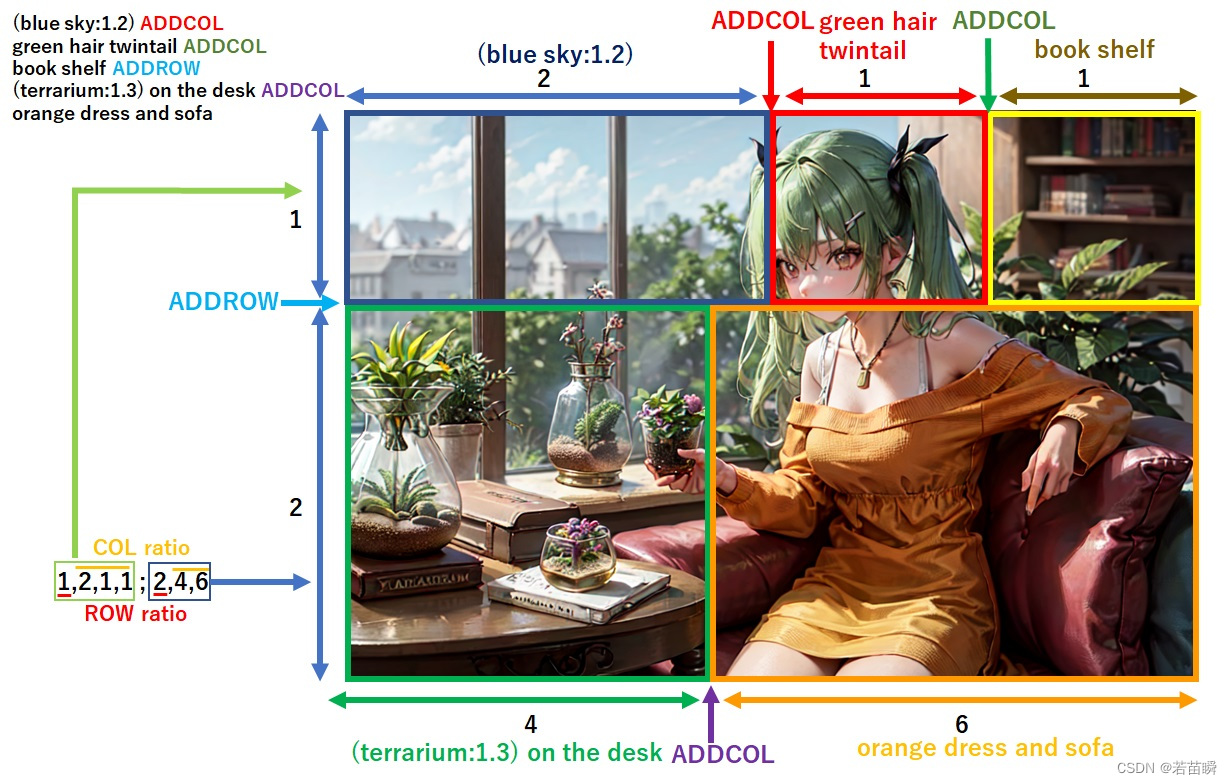
提示词:
(blue sky:1.2) ADDCOL
green hair twintail ADDCOL
(aquarium:1.3) ADDROW
(messy desk:1.2) ADDCOL
orange dress and sofa
分区参数:
Divide mode : Horizontal
Divide Ratio : 1,2,1,1;2,4,6
得到这样的结果:
那个分割比例设置稍显复杂,好在也是可以预览的。
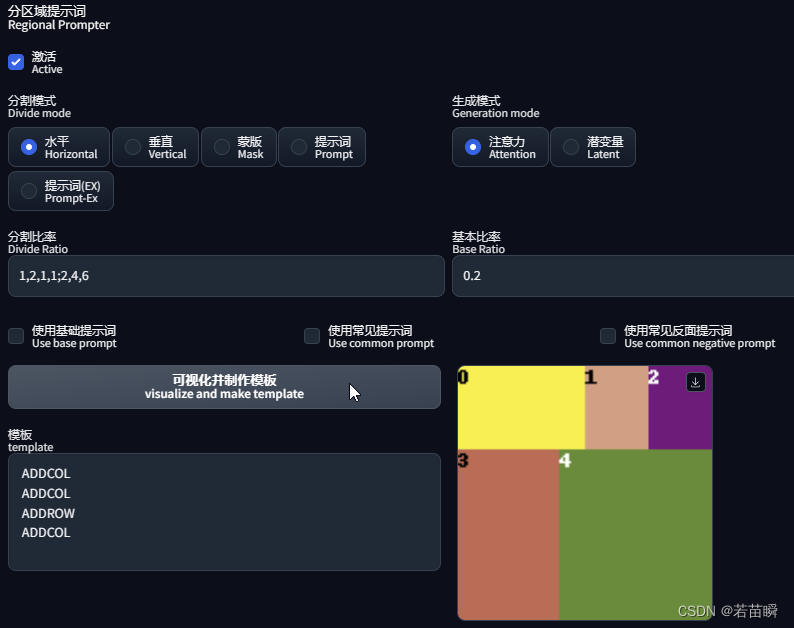
回到前面的例子,正常左右1比1分割。
几乎和前面一样的提示词(必须修改一点,2个左右区域至少要个ADDCOL),
生成了下面简单的例子(依然不像):

(3.1)蒙版分割+提示词分割
我正在写呢,突然发现它更新了,可以用蒙版和提示词来分割(而不是难以理解的数字)。
蒙版分割可以参考官网。提示词分割很有意思(也可以参考官网),虽然是实验性质的。
如果我想在外套上画草莓,常规的方式根本不画,如果太强调画草莓,则可能凭空出现真实的草莓(很诡异)。
这时候用提示词分割就很有效,比如:
左图常规方式,完全没画出衣服上的草莓,但又不敢加强草莓提示:
1girl, ......, turtleneck sweater, strawberry printed overcoat, outdoors on street, blurry background, ......
右图启用了提示词分割😄:
1girl, ......, turtleneck sweater, overcoat, outdoors on street, blurry background, ......, BREAK
(strawberry printed:1.5) overcoat

还有个提示词(EX)模式:
在提示词模式中,重复的区域被添加。
而提示词(EX)模式中,重复的区域是按顺序覆盖的。由于它们是按顺序处理的,所以先设置一个大面积的目标,使小面积的效果更容易保持不被削弱。
虽然没看懂,但应该是字面的意思没错啦,哈哈。
像上面简单的草莓外套的例子,因为没有重复和覆盖的问题,所以两个提示词模式生成的图片一样。
这部分和画双人无关。
但是看得出分区域提示词(Regional Prompter)的改进还是很大的。
(四)总结
从直观感觉上,不像的原因是LoRA的特点似乎在相互侵蚀(污染)并没有真的分别被控制在不同的区域中。
有时出图很离谱,需要多调节参数,但无论怎么调也只能让图很自然,就是不像。
PS:你能猜到上面是哪两位LoRA么……
如果去掉LoRA则多试几次基本就能得到描述的样子,比如:
2girls, upper body, outdoors, blurry background, open mouth, crying sad, eyes closed, sky blue hair, long hair, white shirt, ADDCOL
2girls, upper body, outdoors, blurry background, closed mouth, light smile, red hair, short hair, Asian, blue overcoat,
得到了:

不过很多人的例子里二次元动漫,明明有LoRA。
为什么看上去还是那么完美呢,真是不明白。
当然分区控制不仅是为了画2个人,也可以上有蓝天右边太阳,下有草地左边池塘,这种用法。
所以这篇相当于没有写(吧?)。
🤪 to be continued…




![C嘎嘎~~ [类 下篇之运算符重载]](https://img-blog.csdnimg.cn/7a2a80049044454e9edb8de6c6241cea.png)





![[ 云计算 | Azure ] Chapter 06 | 计算服务之虚拟机、虚拟机规模集、Azure 容器、Azure App 与 Azure Functions](https://img-blog.csdnimg.cn/6c9f18d7b640421985dfe70215dad0dc.png)
