前言
在分布式系统中,最耗费性能的地方就是数据库,而对于数据库的操作基本上就是添加,修改,删除和查询,对于前3者来说,基本上不会出现性能瓶颈。最耗费性能的地方就是查询了,对于查询有join、where、group by 、order by、 like等操作。并且绝大部分的系统都是读多写少。
分布式系统中,因为需要系统之间的调用,一般采用远程调用,那么这个网络耗时也会导致整体性能下降,为了挽救这样的性能开销,一般对于非实时业务,都需要采用缓存机制。
而缓存的身影无处不在,比如从用户角度来说,客户端、网关、CDN、Web容器、框架、ORM框架、本地缓存、分布式缓存、数据库、操作系统、网络等都有缓存的身影,所以合理的应用缓存提升性能已经是互联网必备的技术选型手段。
缓存更新模式
Cache Aside更新模式(旁路缓存模式)
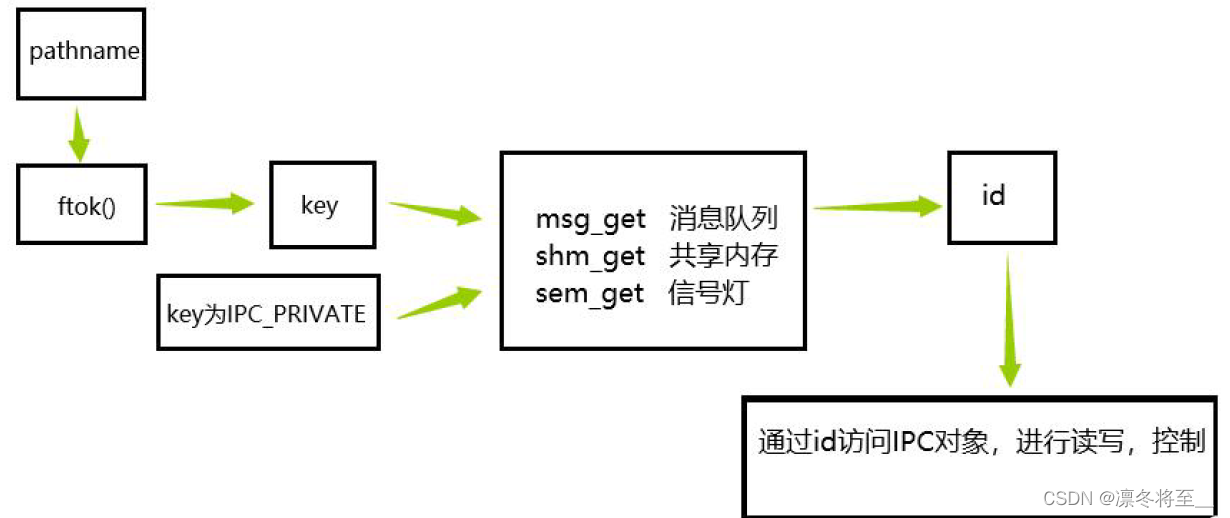
- 失效:应用程序先从cache中读取,没有的话,从数据库中读取,将数据保存到cache中
- 命中:应用程序可以从cache中直接读取到缓存
- 更新:应用程序更新数据,先更新数据库,成功后,将缓存置为失效。

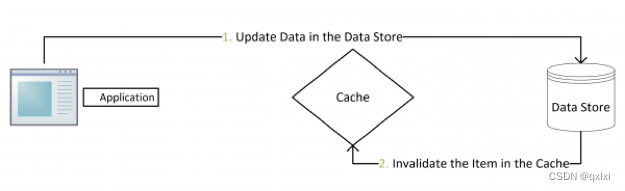
旁路缓存的核心在于,更新数据的时候,另缓存失效。只有在查询缓存不在的时候,从DB中查询数据到缓存中。
那么这种模式就没有并发安全问题嘛,也就是在一瞬间有一个读操作没有命中缓存,会从数据库中读到数据A,但是同一时间存在一个写请求,将数据A修改成B,缓存就失效了,就可能出现一瞬间的数据不一致。
虽然上述问题出现的概率非常低, 所以针对这种模式,需要考虑具体的业务场景,如果是必须强一致性,需要使用锁、分布式锁进行解决。或者通过2PC或Paxos协议。
Read/Write Through更新模式(读写穿透)
与第一个相比 需要维护缓存和数据库两个数据源,而Read Write Through是把更新数据库的操作有缓存自己代理,对应用来说其实就是一个单一的缓存操作。
一般来说,我们很少见这种方式,主要是缓存中间件一般不提供数据同步到DB的功能
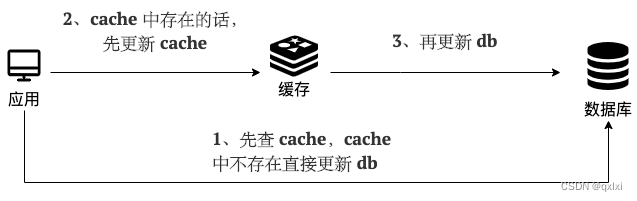
写(Write Through)
- 先查缓存,缓存没有的话,直接更新DB
- 缓存中存在,更新缓存,缓存进行异步的更新数据到DB中
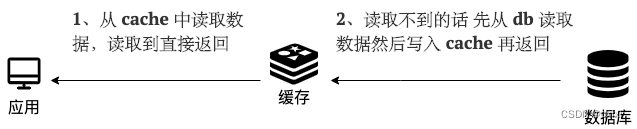
读 (Read Through)
- 从缓存中读取数据,读到直接返回
- 读取不到,从DB中加载,写入cache中返回。
Read-write Through模式来说,旁路缓存如果数据从缓存中查询不到,需要自己从DB中查询写入到缓存中,但是对于前者来说,这个过程由缓存来操作,对于客户端来说是一种透明的方式。
Write Behind Caching更新模式 (异步缓存写入)
相对于这种模式来说,和上述中Read/Write Through更新模式,都是由缓存服务来进行更新缓存和DB的。唯一的不同点是,前者是异步方式更新,后者是同步方式。
显然这种方式对于数据一致性带来了更大的挑战。
应用场景:消息队列中消息的异步写入磁盘、MySQL的InnoDB buffer pool的机制都是这种策略,主要适用于对数据强一致性不高的场景。
所以在软件设计中,不可能设计出一个完美的设计方案,有时候强一致性和高性能、高可用是有冲突的,软件设计从来都是trade-off.
缓存设计的重点
目前在分布式缓存主流使用的是Redis,而一般不建议在服务的Local cache,一个是如果服务进行负载均衡,那么服务是有状态不利于横行扩容。而是一般机器内存都不大。
- 分布式下数据切片,集群、可用性搭建
- 缓存的命中率
- 缓存是通过牺牲强一致性来提高性能的。
- 缓存周期的设置
- 缓存淘汰策略,一般LRU。
需要从以上角度进行设计缓存。
小结
本篇主要介绍了缓存更新的三大策略、分别是旁路缓存、读写穿透、异步缓存写入,目前主流还是使用的第一种比较多。缓存主要是牺牲数据强一致性来提升系统的性能。



![Hadoop[3.3.x]-1本地环境搭建](https://img-blog.csdnimg.cn/9324caa369d6435399fad7c0c56cd6f4.png)