1 二叉搜索树概念
二叉搜索树又称二叉排序树,它或者是一棵空树 ,或者是具有以下性质的二叉树 :
- 若它的左子树不为空,则左子树上所有节点的值都小于根节点的值
- 若它的右子树不为空,则右子树上所有节点的值都大于根节点的值
- 它的左右子树也分别为二叉搜索树
2 二叉搜索树操作
最频繁的几个操作分别是:寻找,插入,删除。
查找与插入根据二叉搜索树的性质很容易实现,关键是删除如何操作?
这里就先不详细介绍了,在下面会给出详细解释。
3 二叉搜索树的代码实现
3.1 查询
非递归版本:
bool Find(const K& key)
{
Node* cur = _root;
while (cur)
{
if (cur->_key > key)
cur = cur->_left;
else if (cur->_key < key)
cur = cur->_right;
else return true;
}
return false;
}递归版本:
为了方便使用,写了个子函数:
bool _FindR(Node* root, const K& key)
{
if (root == nullptr)
return false;
if (root->_key > key)
return _FindR(root->_left, key);
else if (root->_key < key)
return _FindR(root->_right, key);
else return true;
}
bool FindR(const K& key)
{
return _FindR(_root, key);
}3.2 插入
非递归版本:
bool Insert(const K& key)
{
if (_root == nullptr)
{
_root = new Node(key);
return true;
}
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else
{
return false;
}
}
if (parent->_key > key)
{
parent->_left = new Node(key);
}
else
{
parent->_right = new Node(key);
}
}代码总的来说并不难,关键是记录好父亲结点正确链接即可。
递归版本:
bool _InsertR(Node*& root, const K& key)
{
if (root == nullptr)
{
root = new Node(key);
return true;
}
if (root->_key < key)
return _InsertR(root->_right, key);
else if (root->_key > key)
return _InsertR(root->_left, key);
else
return false;
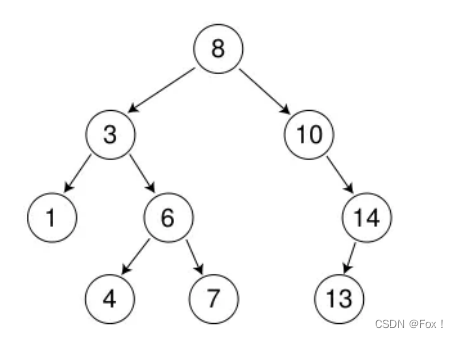
}递归版本巧妙之处在于用了结点指针的引用,我们来看一张图:
假如我们想插入16,走读代码:此时root->right也就是14的右结点恰好是新插入结点的别名,当直接使用root赋值时父节点的与子节点链接关系已经完毕,并不需要像写迭代版本那样判断是父亲的左还是右,直接链接即可。但是一般我们很少写递归版本的,栈容易爆。
3.3 删除
二叉搜索树的删除主要分成下面这几种情况:
- a. 要删除的结点无孩子结点
- b. 要删除的结点只有左孩子结点
- c. 要删除的结点只有右孩子结点
- d. 要删除的结点有左、右孩子结点
看起来有待删除节点有4中情况,实际情况a可以用情况b或者c处理,因此真正的删除过程只有3种情况,我们一个一个来看:
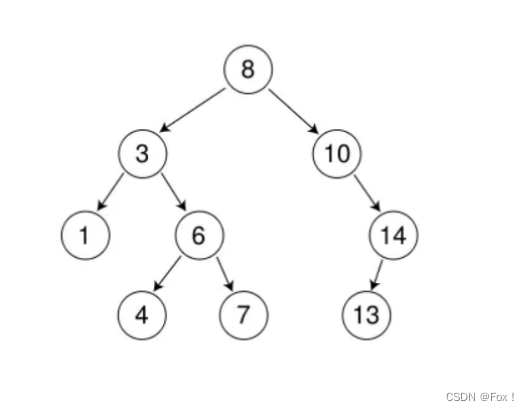
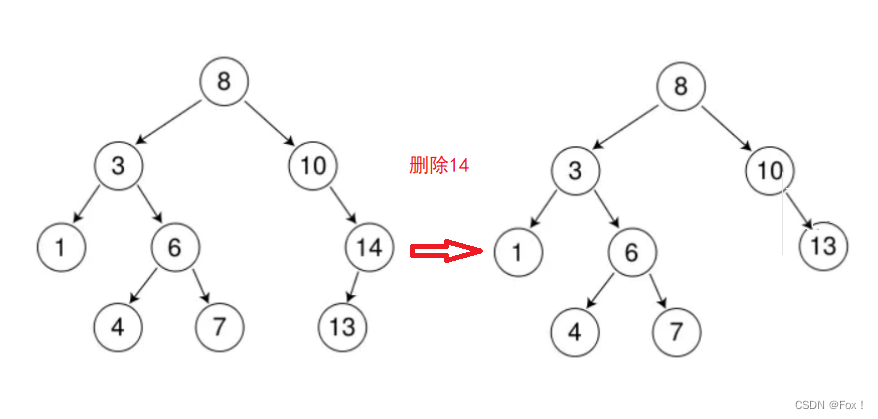
要删除的结点只有右孩子结点 ,比如删除10,我们可以采用托孤来处理:
也就是将10的右子树交给10的父亲领养:

同理,要删除的结点只有左孩子结点,比如删除14,一样可以用托孤处理:
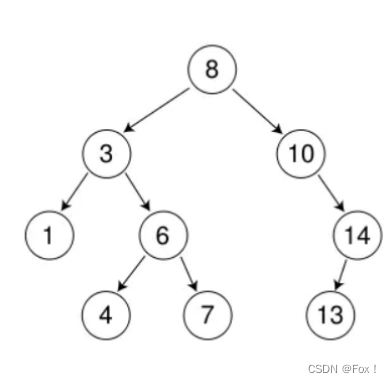
现在关键是如何删除有两个孩子的结点,这时候托孤就不太行了,两个孩子父亲肯定是不能够领养的,所以便有了宁外一种方式:替换法删除。
比如删除8,我们应该找到哪一个结点替换才是比较合理的,通过观察,发现用7或者10来替换删除是比较合理的,也就是找到删除结点的左子树最大节点或者右子树最小结点替换删除是比较合理的。有了理论后便可以开始写代码了:
非递归版本:
bool Erase(const K& key)
{
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else
{
//找到了,准备删除
//第一种情况:删除节点没有左孩子
if (cur->_left == nullptr)
{
//这里还得考虑parent为空的情况,也就是删除节点为根节点的时候
if (parent == nullptr)
{
_root = cur->_right;
}
else
{
if (parent->_left == cur)
parent->_left = cur->_right;
else
parent->_right = cur->_right;
}
delete cur;
}
//第二种情况:删除节点没有右孩子
else if (cur->_right == nullptr)
{
//这里还得考虑parent为空的情况,也就是删除节点为根节点的时候
if (parent == nullptr)
{
_root = cur->_left;
}
else
{
if (parent->_left == cur)
parent->_left = cur->_left;
else
parent->_right = cur->_left;
}
delete cur;
}
//第三种情况:删除节点既有左孩子又有右孩子(替换法删除)
//有两种替换的方法,一种是找到删除节点左子树中最大值替换
//另外一种是找到删除节点右子树中最小值替换
else
{
//找到删除节点左子树中最大值替换
Node* maxParent = cur;
Node* max = cur->_left;
while (max->_right)
{
maxParent = max;
max = max->_right;
}
cur->_key = max->_key;
if (maxParent->_left == max)
maxParent->_left = max->_left;
else
maxParent->_right = max->_left;
delete max;
}
return true;
}
}
}这里面注意的细节有:
- 1 当删除结点的孩子只有一个时,要先判断父亲是否为空(是否删除的是根节点)
2 当我们用替换法删除时,maxParent给的是cur,而不是nullptr,这是为了假如删除结点为根节点时由于没有进入循环而导致maxParent为空造成了空指针解引用的问题。
但是这样处理后会有其他变换,我们看下面这个图,假如我们想删除8:
通过代码找左子树的最大结点我们找到了max=7,maxParent=6,由于7不可能有右子树,并且找到的7不可能在maxParent的左边(因为是一直往右找的),所以很多人直接会写出
maxParent->_right=max->_left 这样的代码,但是我们看看下面这个图:
我们还是删除8,此时max=3,maxParent=8,但是是maxParent->_right=max->_left吗?
显然不是,此时是maxParent->_left=max->_left ,所以需要我们判断处理。
- 3 同理用右子树的最小值替换删除也会有这样的问题。

递归版本:
bool _EraseR(Node*& root, const K& key)
{
if (root == nullptr)
return false;
if (root->_key > key)
return _EraseR(root->_left, key);
else if (root->_key < key)
return _EraseR(root->_right, key);
else
{
Node* del = root;
if (root->_left == nullptr)
root = root->_right;//巧用了引用,root实际上是上一级的parent的孩子
else if (root->_right == nullptr)
root = root->_left;
else
{
Node* max = root->_left;//找左子树最大值
while (max->_right)
max = max->_right;
swap(max->_key, root->_key);
//递归到左子树去删除
_EraseR(root->_left, key);
}
delete del;
return true;
}
}递归版本同样是分成了3种情况,这里面同样是巧用了引用。但是其中要注意的一点是我们递归到左子树去删除时用的是root->_left,而不是max->_left,想想为什么?
我们是交换的max的_key与root的_key,由于max不可能有右节点,所以转换成子问题后删除肯定会是前面删除结点只有一个孩子的情况,所以我们必须通过root的_left来进行子问题转化而不能用max->_left,因为这样才能找到max的父亲将节点正确链接,这点一定要注意。
3.4 拷贝构造 && 赋值运算符重载 && 析构
void destroy(Node* root)
{
if (root == nullptr)
return;
destroy(root->_left);
destroy(root->_right);
delete root;
}
Node* copy(Node* root)
{
if (root == nullptr)
return nullptr;
Node* newNode = new Node(root->_key);
newNode->_left = copy(root->_left);
newNode->_right = copy(root->_right);
return newNode;
}
BSTree()
:_root(nullptr)
{}
BSTree(const BSTree<K>& bs)
{
_root=copy(bs._root);
}
BSTree<K>& operator=(BSTree<K> bs)
{
swap(_root, bs._root);
return *this;
}
~BSTree()
{
destroy(_root);
_root = nullptr;
}这个很简单,就不再多说了。
3.5 二叉搜索树的应用
1. K 模型: K 模型即只有 key 作为关键码,结构中只需要存储 Key 即可,关键码即为需要搜索到的值 。比如: 给一个单词 word ,判断该单词是否拼写正确 ,具体方式如下:以词库中所有单词集合中的每个单词作为 key ,构建一棵二叉搜索树在二叉搜索树中检索该单词是否存在,存在则拼写正确,不存在则拼写错误。2. KV 模型:每一个关键码 key ,都有与之对应的值 Value ,即 <Key, Value> 的键值对 。该种方式在现实生活中非常常见:比如 英汉词典就是英文与中文的对应关系 ,通过英文可以快速找到与其对应的中文,英文单词与其对应的中文 <word, chinese> 就构成一种键值对;再比如 统计单词次数 ,统计成功后,给定单词就可快速找到其出现的次数, 单词与其出现次数就是 <word, count> 就构成一种键值对 。
上面的代码我们可以改造成KV模型结构。