作者:bytebeats
模块化背后的原则概述

“如果说SOLID原则告诉我们如何将砖块排列成墙和房间, 那么组件原则则告诉我们如何将房间排列成建筑.” ~ Robert C. Martin, Clean Architecture
你应该分层打包还是分特性打包?还有其他方法吗?
如何提高项目的编译时间?
你的工程师如何在跨职能的团队中独立工作?
目录
组件内聚原则
组件耦合原则
封装设计解决方案
封装
主组件
简介
SOLID原则可以验证和检测类或接口的代码缺陷, 而组件原则可以验证和检测组件的代码缺陷.
什么是组件?
组件是一组文件(类, 接口, 函数文件, Android资源等), 使用以下策略之一进行分组:
- 源代码级别(单体结构):在Java/Kotlin中, 我们使用包
- 二进制/部署层面:在Java/Kotlin中, 我们使用生成"jars"或 "aars"的模块
- 服务层面:这将是一个服务或一个微服务, 通信通过网络数据包进行.
通常情况下, 你不会只使用一种策略. 你根据你的需要混合这些策略.
*由于我们在Android中没有服务, 这篇文章将专注于Java/Kotlin模块. *
什么是 “好的模块化”?
一个"好的模块化"是一个组件的结构, 其中的模块是高内聚和低耦合的.
我们怎么说模块是高内聚的呢? 我们又怎么说模块是低耦合的呢?
当模块遵守组件内聚的原则时, 它们就是高内聚的.
当模块遵守组件耦合原则时, 它们就是低耦合的.
组件内聚原则
SOLID原则是清洁架构的基础, 可以在模块层面进行调整, 从而形成一套新的原则(REP, CCP和CRP).
通用闭合原则(CCP)
"将那些因相同原因和相同时间发生变化的类聚集到组件中.
将那些在不同时间和不同原因发生变化的类分离成不同的组件". - 其余所有引文由罗伯特-C-马丁(Robert C. Martin)撰写, Clean Architecture
CCP是 SRP 在模块层面的演变, 正如我在之前的文章中解释的那样.
*一个类不应该因为不同的原因而改变 -> 一个组件不应该因为不同的原因而改变. *
因相同原因而改变的类应该被归入一个组件, 而因不同原因而改变的类应该被移出组件.
可维护性比可重用性更重要:每当你做一个新的功能, 或者有一个需求变化时, 你宁可只碰一个模块, 也不碰许多模块.
当我们只需要改变一个模块时, 我们就不太可能影响到其他团队成员, 而且我们需要重新编译, 重新验证和重新部署的组件也比较少.
总是把所有可能的改变都归入一个模块是不现实的(除非你在工作中使用单片机😈), 所以这个原则的目标是尽量减少需要改变的模块的数量.
- 优点:对维护来说是最理想的, 因为变化的影响最小.
- 缺点:开发和维护模块的最佳方法可能不是向图书馆用户发布模块的最佳方法. 另外, 模块往往会比较大, 以隔离需要改变的模块数量.
通用重复使用原则(CRP)
“不要强迫组件的用户依赖他们不需要的东西”.
CRP是 ISP 在模块层面的演变, 我在之前的文章中解释过.
*当接口很小的时候, 你不会依赖你不需要的方法—当模块很小的时候, 你不会依赖你不需要的文件. *
类很少被孤立地重复使用. 更典型的是, 可重用的类与其他属于可重用的抽象的类合作. CRP指出, 这些类属于同一个组件中.
它还指出, 不被一起重用的类不应该被放在同一个组件中.
通过这样做, 对这些类的更新不会触发对不使用它们的模块的重新编译, 重新部署或发布.
- 优点:较小的模块, 作为一个模块用户, 你不太可能被你不关心的变化所影响.
- 缺点:更多的模块需要在开发过程中进行处理.
重用/发布等价原则(REP)
“重复使用的颗粒就是发布的颗粒”.
你愿意重用的最小的东西就是你愿意释放的最小的东西.
这对库的开发者来说是一个非常重要的原则.
每当你想把一个组件提供给别人时, 你就需要有一个发布过程, 为了使你的组件在一段时间内不破坏你的库用户的代码, 你需要有发布号.
这样做, 库用户就不会有破坏性的变化, 除非他们升级到较新的库版本.
因为你的模块中的所有类都有相同的发布号, 一个单一的类的更新将需要同一模块下的所有类的新发布.
有时, 库是以单个库的形式出现的, 有时是以一组库的形式出现的(因此你可以决定导入什么, 排除什么).
当使用一组库时, 你可能会想到, 由于所有这些模块都被重复使用, 它们都应该有相同的发布号以确保兼容性.
拥有相同的版本号意味着当你需要更新一个模块时, 你也需要用更新的版本号发布所有其他的模块(即使这些模块没有变化).
让我们以Retrofit为例.
implementation 'com.squareup.retrofit2:retrofit:2.9.0'
implementation 'com.squareup.retrofit2:converter-moshi:2.9.0'
当Retrofit开发者为Retrofit主库添加新的功能时, 他们很可能也需要使支持的转换器库与这些新的集成相兼容, 从而提升所有库模块的版本名称.
*这不一定是最好的方法, 特别是当同一组库的模块不是很有凝聚力的时候. *
现在让我们以 Firebase 为例.
Firebase库在过去有匹配的发布号.
Firebase的问题是, 他们的库组非常不连贯. 想想远程配置库和存储库:这两个库是完全独立的, 可能由不同的开发团队负责.
两者之一的新集成不应该要求Firebase团队发布另一个库的新版本而不进行修改.
Firebase团队最后做了什么?
他们利用Gradle 5.0对Maven BoM 的支持, 允许将不同库的版本作为一个单一版本来管理.
这样一来, 他们不是为每一个库发布一个新版本, 而是发布一个新版本的BoM.
// BoM
implementation platform('com.google.firebase:firebase-bom:$version')
// modules import without version
implementation 'com.google.firebase:firebase-core'
implementation 'com.google.firebase:firebase-config'
implementation 'com.google.firebase:firebase-storage'
如果不是因为BoM, 他们会使用 Google Play Services的方法, 也就是一个无尽的库版本表(最不方便用户使用).
- 优点:对重用性来说是最理想的, 你的模块对其他团队是可用的, 而且版本控制使新的更新更容易管理.
- 缺点:维护代码库更加复杂, 因为现在你需要考虑模块的发布过程.
模块会趋于大型化, 因为这样做可以减少需要发布的模块的数量.
组件耦合张力三角

组件耦合张力图
该图显示了当你放弃一个原则而支持另外两个原则时会发生什么.
如果还不清楚的话, 组件凝聚原则与SOLID原则不同, 它们并不能相互补充, 需要你选择对你的项目更重要的东西.
虽然使类易于维护和重用是很容易的, 但对模块来说就不一样了.
CCP和REP是包容性原则;它们倾向于使模块更大, 而CRP是排他性原则, 因为它倾向于使模块更小.
CRP和REP是侧重于重用的原则. 它们倾向于为使用它们的人优化模块, 而CCP则侧重于维护, 因为它倾向于为开发它们的人优化模块.
你不太可能兼顾这三者, 所以你应该准备放弃或减少对其中一个的关注.
通常情况下, 一个项目属于以下类别之一:
- 应用程序:当你正在构建一个应用程序时, 你的主要目标是快速构建东西, 并拥有一个快速编译的项目, 将不需要的重新编译降到最低. 如果你属于这个类别, 你应该始终关注CCP和CRP.
- 库:当你在构建一个库时, 你的目标不会是静态的. 相反, 它将随着时间的推移而改变. 当你开始开发图书馆时, 你的主要关注点应该是快速建立库. 然后, 随着时间的推移, 你的关注点应该转移到库的可重用性上, 并对其维护进行妥协. 如果你属于这种情况, 在你的项目成熟之前, 你应该把注意力放在三角形的右边, 然后随着时间的推移, 你应该转移到左边, 因为现在你会对你的库的用户越来越负责任. 大多数项目的模块化失败是因为工程师对项目的性质优先考虑了错误的原则.
其他项目的模块化失败是因为组件结构是静态的, 而不是随着需求的变化而发展的.
参考文献
- Clean Architecture, 第13章(组件耦合)
组件耦合原则
我们讨论了关于模块应该如何按照耦合原则的理论.
现在我们需要讨论这些模块之间的关系应该是怎样的.
非循环依赖原则(ADP)
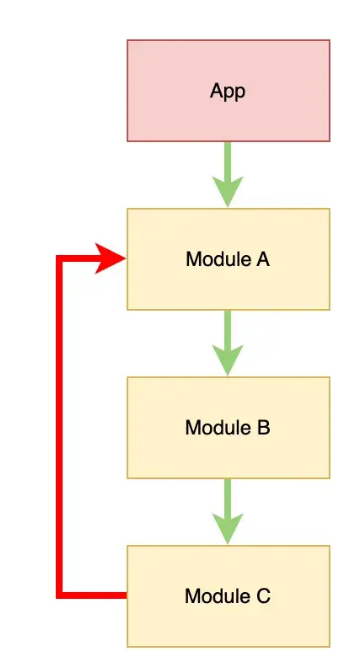
“在组件的依赖关系图中不允许有任何循环”.
如果A依赖于B, 那么B就不应该依赖于A.
这不仅适用于依赖关系, 也适用于传递性依赖关系: 如果A依赖于B, B依赖于C, 那么C也不应该依赖于A.
有些编译器允许模块中出现循环, 有些编译器则试图确保这不会发生.
无论使用哪种编译器或语言, 作为开发者, 你需要知道如何在发现依赖性循环后立即打破它.
依赖性循环可以通过两种方式打破:
- 提取类在新模块中重新使用.
- 使用依赖反转原则(DIP, 是的, 又是SOLID 😈)来"反转"依赖关系.
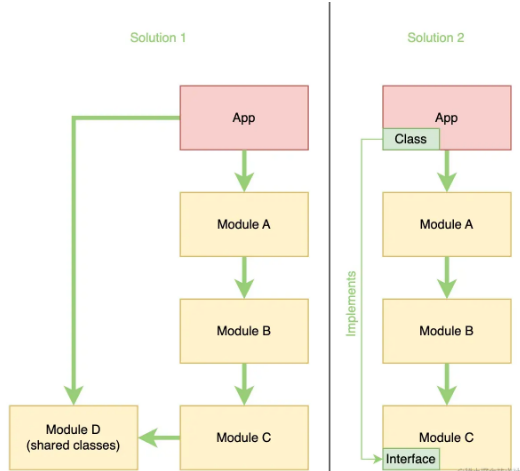
当许多模块需要共享逻辑, 并且有很多东西需要共享时, 解决方案1是理想的.
当只有一个模块需要共享逻辑, 并且没有多少东西需要共享时, 解决方案2是理想的.
稳定依赖原则(SDP)
“在稳定的方向上依赖”.
你会让你的模块更依赖什么?
一个经常变化的模块还是一个从不变化的模块?
我们希望我们的模块能够依赖那些永不改变的模块.
每当我们的模块中的依赖关系发生变化时, 我们的模块需要重新编译, 我们可能不得不处理破坏性的变化.
哪些模块是稳定的?
稳定的模块是那些难以改变的模块.
想想Kotlin的String类, Kotlin团队有多大可能改变这样一个类?如果他们真的改变了它, 那么他们在整个Kotlin语言中会有多少破坏性的改变?这是一个没有头脑正常的开发者会改变的类.
对你来说, 最理想的情况是你的模块依赖于像这样稳定的东西.
不幸的是, 我们生活在现实世界中, 而不是理想世界.
我们使用的大多数模块都不是100%稳定的, 这不一定是坏事.
一个不能改变的模块也不可能永远改进.
不仅如此, 如果模块完全不能改变, 我们就永远无法增加新的功能, 因为我们无法改变代码.
那么, 我们该如何重新定义稳定性?
一个模块什么时候才够稳定?
当一个模块的几乎不依赖别的模块, 而依赖于它的模块很多, 从而使它成为一个负责任的模块时, 它就是稳定的.
如果你看一下你的组件依赖关系图, 你应该看到在底部是比较稳定的(负责任的)模块, 在顶部是比较不稳定的(依赖的)模块.
因为在你的项目中, 你最终会有稳定的和不稳定的模块, 所以黄金法则是, 一个模块应该依赖比自己更稳定的模块.
稳定抽象原则(SAP)
“一个组件应该像它的抽象性一样稳定”.
SDP定义了稳定的模块是很难"改变"的.
这意味着向稳定的模块添加新的功能是很难的, 因为你不能轻易修改现有的代码…
但是"扩展"呢?我可以扩展稳定的模块吗?
开封原则 (OCP, 是的, 又是SOLID 😈)给我们提供了对扩展开放, 对修改封闭的类.
我如何在模块层面上移植这种可扩展性?
*当一个模块是抽象的时候, 它就很容易被扩展. 因此, 它主要由接口和抽象类组成. *
当一个模块充满了接口时, 每当你需要添加新的东西时, 你所需要做的就是为其中的一个抽象提供一个新的具体实现.
这将防止你为了适应你的模块而触及稳定模块的源代码, 并可能破坏其他依赖模块.
稳定的模块应该是抽象的多于具体的, 以便有更多的灵活性, 而不稳定的模块应该是具体的多于抽象的, 以便于改变代码.
虽然你希望稳定的模块非常抽象, 以允许灵活性, 但一个100%抽象的模块是一个无用的模块, 因为没有实际的逻辑可以重复使用.
显然, 一个100%具体化的稳定模块是一个改变起来非常痛苦的模块.
这里的黄金法则是, 一个模块应该依赖于它的依赖关系的抽象, 而不是具体化.
如果你的类遵守了依赖反转原则, 你就应该免费得到这个.
参考文献
- Clean Architecture, 第14章(组件耦合)
包设计的解决方案
如果你看了上面的六条原则感到无聊, 不用担心, 因为现在我要进入有趣的部分了.
现在我们知道了如何实现高内聚和低耦合, 是时候讨论哪些方法可行, 哪些不可行了.
因为应用程序开发人员是最难实现模块化的, 而且库开发人员通常不需要处理大量的模块, 所以我将只关注如何实现应用程序的模块化(否则这篇文章会变得更长!).
分层打包

在分层打包中, 你把代码库分成三个大模块, 每层一个.
这种方法相当容易做到, 但违反了上述的大部分原则.
每当你从事一项新的功能时, 你很可能要修改所有的模块.
这样做, 你可能会破坏其他功能的代码, 踩到队友的脚, 并在任何新的迭代中重新编译整个依赖图.
模块也会非常大, 因为它们将包含你的应用程序中所有功能的层逻辑.
为什么这种方法如此受欢迎?
如果你从广告炒作开始就一直在读Clean Architecture的文章, 你会注意到大多数作者在讨论模块化时, 不断推动分层打包的方法, 认为层(表现-域-数据)应该决定他们项目的模块结构.
*如果这些作者当初读过 Clean Architecture 这本书, 他们就会知道这种方法是广告中最反对的方法. *
这个糟糕的建议之所以让我感到不安, 不仅仅是因为开发人员使用了错误的模块化方法的结果, 还因为它把公司引入了歧途, 因为他们用这些层来分隔开发团队.
如果我想把一个数据库换成另一个数据库怎么办?
难道改变一个模块不是更好吗?
我听过很多次支持这种打包方式的说法, 简短的回答是:不, 这不是更好.
首先, 改变数据库不是你日常工作的一部分. 这可能会在几年内发生, 但绝对不是每周一次.
更不用说这对移动开发者来说是非常罕见的工作(一些不幸的开发者不得不用Realm替换Sqlite, 然后用Room回到Sqlite, 但这发生在很多年以后).
其次, 一鼓作气地交换数据库是个坏主意. 更好的做法是将你的数据逐一迁移到新的数据库中, 这样你就可以逐步释放你的迁移, 并限制可能出现的潜在bug的数量.
分特性打包
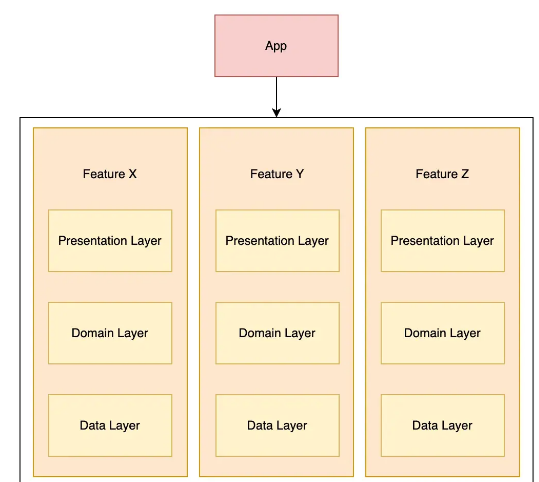
在分特性打包中, 你将代码库分割成特性模块, 每个特性都有一个
这种方法有很多优点, 而且几十年来一直是最值得推荐的方法:
- 当在一个特性上工作时, 你只改变一个模块, 这对维护来说是最理想的.
- 当你打开你的项目时, 你清楚地知道你的项目是做什么的, 因为它向你喊出了它的内容(尖叫架构).
- 每个跨职能的团队都可以独立完成一个功能, 而不会踩到其他团队的脚.
- 独立的团队也意味着独立的模块, 所以你可以充分利用Gradle的并行编译, 除了要求你只重新编译那个改变了的单一功能外, 它还会减少你的整体编译时间.
- 你不会失去层, 因为层可以很容易地在特性模块内作为包来实现.
那么, 这就是我应该将我的应用程序模块化的方式, 对吗?
并非如此. 这种方法看起来对维护来说是最理想的, 但完全没有复用性!这种方法的缺点是非常昂贵!
这种方法的缺点是非常昂贵:
- 如果你的特性模块需要重用另一个特性模块的一些代码, 你就需要在一个非常不稳定的模块上建立依赖关系, 这会破坏SDP, 同时因为功能会包含大量的UI代码, 而UI代码是非常具体的;你也会破坏SAP.
- 特性模块包含presentation, domain,和data逻辑, 这导致大模块(CRP违反)包含经常变化的代码(UI)以及很少变化的代码(业务逻辑).
- 依赖于功能的特性往往会产生大的"核心功能"模块, 使你的项目逐渐恢复到一个单体.
按功能打包在UI不重的项目中效果很好, 如后台或旧的前端应用程序.
在后端项目中, 控制器的代码(presentation层)通常很薄, 与domain层的用例或服务匹配.
后台也可以依靠服务(或微服务)而不是模块, 所以组件内的通信不需要一个服务知道另一个服务的内部结构. 相反, 公共API的协议使得整个组件的结构在编译时是独立的.
在移动或网络前端项目中, "屏幕"是一些特性的集群.
想想一个电子商务的产品详情页, 它允许你把产品添加到购物车和用户的愿望清单中.
这些同样的操作可以在产品列表页或购物车页, 或愿望清单页进行.
在这种情况下, 你怎么能按功能划分呢?
你要把所有的东西都归入一个单一的功能吗?
你打算创建一个大的共享功能模块来共享公共代码吗?
你要重复大量的代码, 以便有独立的模块吗?
任何这些解决方案都是次优的, 都不是问题的答案.
分特性打包不适合重度UI项目, 所以不要在专业的Android项目中使用它(同样适用于iOS和Web).
分组件打包
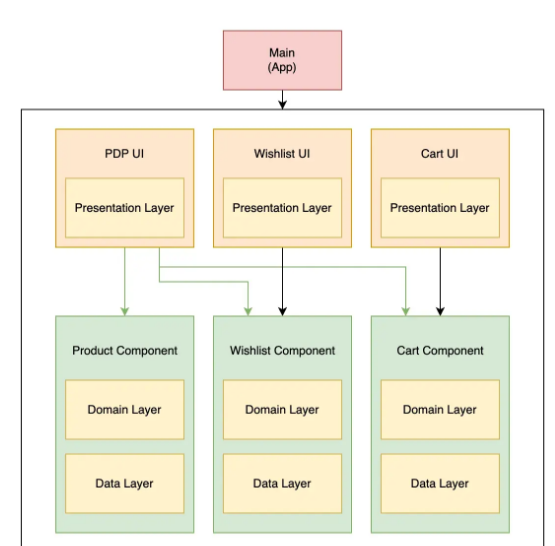
按组件打包的PDP方案示意图
在分组件打包中, 你把代码库分成UI模块和组件模块(特性的domain+data层).
谁应该指导你的应用程序的各个模块?
当然不是我们在分特性打包中看到的UI逻辑. 用例应该指导你的模块化, 就像它们指导你的开发一样.
用例告诉我们应用是做什么的, 和什么很少改变. 它们也是presentation层唯一可见的架构组件.
数据层的存在只是为了支持领域层. 因此, 领域层的修改往往需要数据层的修改, 以便与更新的资源库接口兼容.
通过使用用例对代码库进行纵向和横向分割, 我们可以实现我们在分特性打包时没有的重用性.
回到产品详情页的例子(查看图表). 如果我有一个购物车组件模块, 一个愿望清单组件模块和一个PDP UI模块, 我现在可以重复使用购物车和愿望清单的代码, 而不需要依赖任何显示购物车或愿望清单屏幕的UI细节.
如果产品团队决定在愿望清单界面中引入添加到购物车的功能, 我们只需将购物车组件模块作为依赖关系添加到愿望清单UI模块中, 并将其链接.
我现在不仅有了更多可重用的方法, 而且还将经常变化的类与很少变化的类分开, 从而最大限度地减少了重新编译的次数.
因为组件仍然是独立的, 我们可以并行地编译模块, 从而提高了整体的编译时间.
如果我需要在组件模块或UI模块之间共享代码怎么办?
如果你在一个专业项目上工作, 你很可能会遇到这个问题, 解决办法如下:
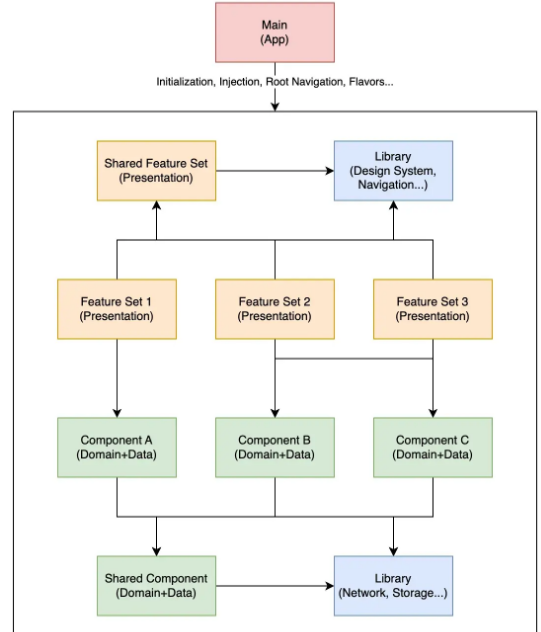
如果你需要分享的是一个功能的具体代码, 你可以在共享组件模块或共享UI模块中提取你需要重用的内容.
如果你需要分享的是通用代码, 比方说执行网络请求或设计系统的代码, 你将遵循与第三方库(如Retrofit, Dagger…)相同的方法, 不同的是这个模块不会公开, 而是对你的项目来说是私有的(直到你决定与公众分享它).
如果我需要从PDP导航到Cart屏幕或Wishlist屏幕怎么办?
DIP是你的朋友. 如果你需要在模块中导航, 你所需要做的就是有一个接口, 比方说:
interface PDPNavigator {
// you can adapt for fragments, navigation component, compose....
fun navigateToCart(activity: Activity)
fun navigateToWishlist(activity: Activity)
}
这将由主(app)模块中的一个类来实现:
class AppNavigator: PDPNavigator, WishlistNavigator, CartNavigator.... {
override fun navigateToCart(activity: Activity) {
//...
}
override fun navigateToWishlist(activity: Activity) {
//...
}
}
*对于同一模块内的界面, 你不需要这样做. *
封装
如果说有一件事开发者从来没有做得好, 那就是封装工作.
打开你的一个模块的代码. 如果每一个类或接口都是公共的, 那么你的封装就做错了.
“public"是一个修饰词, 应该只用于那些要在模块外使用的类或接口. 其他的都应该是"internal”.
如果一个模块中的每一个类或接口都是"public"的, 那么开发者可能会被误导, 认为所有的东西都需要被其他模块重复使用, 从而不敢去碰这些代码.
更有纪律的开发者, 为了获得信心, 会使用IDE的查找使用工具来检查这些类是否在模块之外使用. *如果有一个修改器就好了, 它可以避免这些额外的步骤, 让开发者更有生产力. *
模块封装不仅仅是为了自信, 也是为了未来的改进.
通过了解什么是public, 什么是不public的, 你可能会找到一种方法, 在你只是因为少量的类/接口而使用模块的情况下, 将模块与依赖关系解耦.
这并不以public/internal修饰符为终点.
你可能会发现的另一个封装问题是与反式依赖的暴露有关的.
这种情况发生在你的一个依赖关系通过使用api而不是implementation而泄露了一个横向的依赖关系.
理想情况下, 你总是使用implementation, 因为这避免了依赖关系的泄露和额外的编译时间.
通过分组件打包进行封装
在分组件打包中, 使用封装是非常简单的, 因为可以公开的文件数量只有几个.
- 在组件模块中:唯一应该public的文件是用例接口和需要在模块外使用的模型. 用例实现, 资源库接口, 资源库实现, 映射器接口, 映射器实现, DTO等, 应该始终是internal的, 因为表现层不应该访问它们. 组件模块是稳定的(坚持SDP), 包含业务规则和用例. 通过只公开用例接口, 我们也坚持了SAP, 因为现在其他模块将只依赖于这个模块的抽象性.
- 在用户界面模块中:唯一应该public的文件是屏幕(fragments, activities, 组合界面的Composables)和外部导航器. UI模块是不稳定的, 因为UI是非常不稳定的;因此, 我们应该尽量不把它们作为依赖关系加入, 只在主(app)模块中导入它们, 以连接导航.
如果你正在使用Dagger, 提供这些依赖关系的模块也应该做成internal的.
// Dagger module for a Wishlist Component Module
@Module
@InstallIn(SingletonComponent::class) // Or any other scope
internal object WishlistComponentModule {
@Provides
fun provideAddToWishlistUseCase(
addToWishlistUseCaseImpl: AddToWishlistUseCaseImpl
): AddToWishlistUseCase = addToWishlistUseCaseImpl
@Provides
fun provideGetWishlistUseCase(
getWishlistUseCaseImpl: GetWishlistUseCaseImpl
): GetWishlistUseCase = getWishlistUseCaseImpl
@Provides
fun provideWishlistRepository(
wishlistRepositoryImpl: WishlistRepositoryImpl
): WishlistRepository = wishlistRepositoryImpl
//...
}
// Dagger module for a Wishlist UI Module
@Module
@InstallIn(ActivityComponent::class) // Or any other scope
internal object WishlistUIModule {
@Provides
fun provideSomeDependency(
someDependencyImpl: SomeDependencyImpl
): SomeDependency = someDependencyImpl
//...
}
如果你使用手动注入, 你可以把你的依赖容器变成public的, 并确保只有public的文件才能从public方法中返回(否则你会得到一个编译错误).
主组件
在每个系统中, 至少有一个组件创建, 协调和监督其他组件.
主组件(Android中的app模块)是最终的细节, 它包含最低级别的策略, 是系统的入口. 它是一个脏手了的低级模块, 位于clean architecture的最外圈. 它为高层系统加载一切, 然后将控制权移交给它.
以下内容应该被放在这个区域里:
- 所有连接模块所需的"胶水代码".
- 所有不能在模块内部使用的注入代码
- 所有不能在模块内部使用的导航代码
- 你的口味配置
- 框架所需的所有初始化
为了帮助到大家更好的掌握 Android 组件化、插件化、模块化等中的所有知识点,在这特别准备了《Android组件化强化实战》帮助大家去熟知该功能的应用。
第一章 Android组件化初识:https://qr21.cn/CaZQLo?BIZ=ECOMMERCE

第二章 Android组件化初探:https://qr21.cn/CaZQLo?BIZ=ECOMMERCE
第三章 架构演化(大厂篇):https://qr21.cn/CaZQLo?BIZ=ECOMMERCE