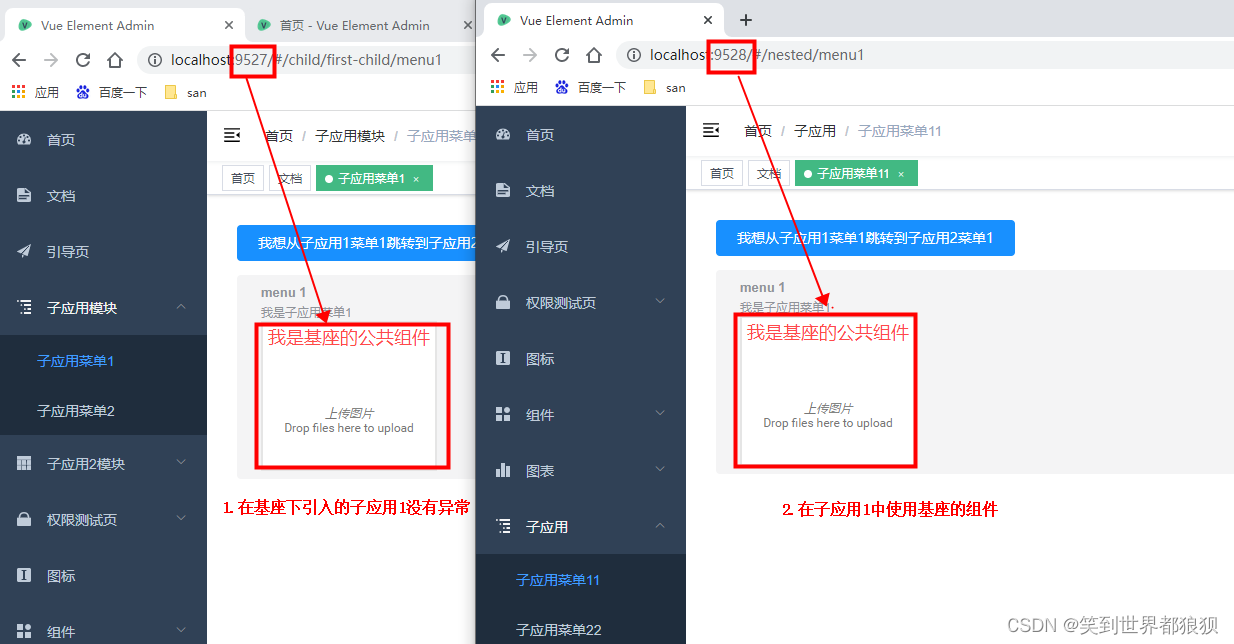
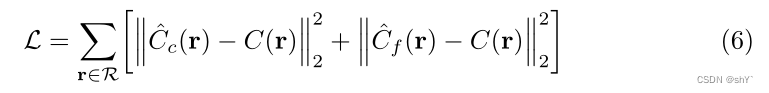来源:投稿 作者:小灰灰
编辑:学姐

论文标题:MarginGAN: Adversarial Training in Semi-Supervised Learning
论文链接: https://papers.nips.cc/paper/2019/file/517f24c02e620d5a4dac1db388664a63-Paper.pdf
代码链接:https://github.com/DJjjjhao/MarginGAN
1.摘要
针对半监督学习问题,提出了一种边缘生成对抗网络(MarginGAN)。与TripleGAN一样, MarginGAN由三个组件组成:生成器、鉴别器和分类器,其中出现了两种形式的对抗性训练, 鉴别器按常规进行训练,以区分真实数据和生成器生成的假数据,分类器可以增加真实样本的边缘,并减少假样本的边缘。生成器的目的是生成真实的、大幅度的数据,以便同时欺骗鉴别器和分类器,伪标签用于在训练中生成和未标记的数据。我们的方法是基于大边缘分类器的成功以及最近的观点,即好的半监督学习需要“坏”的GAN。在基准数据集上的实验证明,MarginGAN与几种最先进的方法正交,提供了改进的错误率和更短的训练时间。
2.介绍
在现实世界中,未标记的数据可以相对容易地获得,而手动标记的数据成本很高,伪标签是未标记数据的人工标签,其作用与人工标注数据的标签相同,是半监督学习中一种简单有效的方法。几种传统的SSL方法,如自训练[1]和协同训练[4],都基于伪标签。在过去几年中,深度神经网络在SSL方面取得了巨大的进步,因此伪标签的概念被纳入深度学习中,以利用未标记的数据, 在[5]中,选择具有最大预测概率的类作为伪标签。[6]中提出的时间集合使用集合预测作为伪标签,这是在不同正则化和输入增强条件下,不同时期的标签预测的指数移动平均值. 与[6]中的标签预测进行平均相比,在平均教师方法[7]中,模型权重进行平均。[5]中的伪标签具有与地面真值标签相同的效果,以最小化交叉熵损失,而[6,7]中的伪标签用作预测目标,以实现一致性正则化,这可以使分类器为相似数据点提供一致的输出。
最近,生成性对抗网络(GANs)被应用于SSL,并取得了惊人的结果。[8]中提出的特征匹配(FM)GANs方法用(K+1)类分类器代替了原始的二元鉴别器。分类器(即鉴别器)的目的是将标记样本分类为正确类,将未标记样本分类到前K类中的任何一类,并将生成样本分类到第(K+1)类,作为特征匹配GANs的改进,在[9]中提出的方法验证了良好的半监督学习需要“坏”生成器。所提出的补码生成器可以在低密度区域中产生人工数据点,从而鼓励分类器在这些区域中放置类边界,并提高泛化性能。
尽管在深度学习中使用伪标签的想法简单有效,但有时可能会发生不正确的伪标签会损害泛化性能并减慢深度网络的训练。先前的工作,如[6,7]致力于如何提高伪标签的质量。受[9]的启发,我们提出了一种方法,鼓励生成器在SSL中生成“坏”示例,从而提高对错误伪标签的容忍度,并进一步降低错误率。
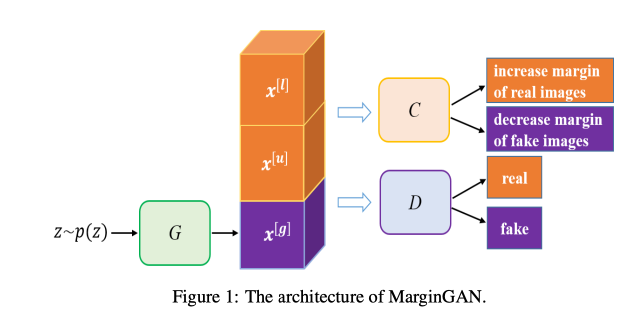
为了解决由错误伪标签引起的问题,我们提出了MarginGAN,一种基于分类器边缘理论的半监督学习中的GAN模型。MarginGAN由三个组件组成——生成器、鉴别器和分类器(MarginGAN的架构见图1)。鉴别器的作用与标准GAN中的作用相同,区分样本是来自真实分布还是由生成器生成。训练多类分类器以增加真实数据(包括标记数据和未标记数据)的分类边缘,同时减少生成的假样本的边缘,生成器的目标是生成看起来真实且具有较大余量的伪标签,旨在同时欺骗鉴别器和分类器。
3.方法
3.1 本文的动机
在通常的GAN模型中,目标是训练一个生成器,该生成器可以生成真实的假样本,使得鉴别器无法辨别真实或假样本。然而,在SSL问题中,我们的目的是训练高精度分类器,从而获得大量训练示例,我们希望生成器能够产生接近真实决策边界的“信息”样本,就像支持向量机模型中的支持向量一样。这里出现了另一种对抗性训练:生成器试图生成大幅度的假样本,而分类器旨在对这些假示例进行小幅度预测。
未标记样本(和假样本)的错误伪标签大大降低了基于伪标签的先验方法的准确性,但我们的MarginGAN对错误伪标签表现出更好的容忍度。由于鉴别器在通常的GAN中起着相同的作用,我们认为MarginGAN获得的提高的准确性来自生成器和分类器之间的对抗性交互。
首先,我们消融研究中的极端训练案例表明,MarginGAN生成的假样本可以积极纠正错误伪标签的影响。由于分类器强制执行假样本的小边界值,因此生成器必须在“正确”决策边界附近生成假样本。这将细化和缩小围绕真实样本的决策边界。
其次,我们说明了四类问题的大幅度直觉。如果分类器选择相信错误的伪标签,则决策边界必须跨越两类示例之间的“真实”差距。但是错误的伪标签会导致边缘值减少,从而影响泛化精度。因此,为了获得更高的准确度,大边缘分类器应该忽略那些错误的伪标签。
3.2 Matgin
在机器学习中,单个数据点的边缘定义为从该数据点到决策边界的距离,该距离可用于限制分类器的泛化误差。支持向量机(SVM)和boosting都可以用基于边缘的泛化边界来解释, 在AdaBoost算法中,是在迭代t和 ≥ 0中获得的基本分类器,并且ht(x)∈ {1, −1} 是在迭代t和
中获得的基本分类器≥ 0是分配给ht的相应权重,组合分类器f是T基分类器的加权多数表决,其公式为
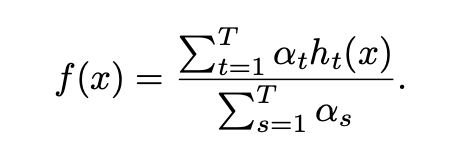
实例标签对(x,y)的边距定义为
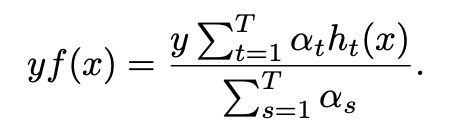
3.3 架构总览
GAN的原始架构由两个组件组成,一个生成器和一个鉴别器,生成器G变换潜在变量z∼p(z)到假样本xˆ∼(xˆ) 使得生成的分布
(xˆ) 近似于真实数据分布p(x)。鉴别器D用于区分生成的假样本和真实样本。为了适应半监督学习,我们在原始架构中添加了分类器C,我们保留鉴别器,以鼓励生成器生成视觉上真实的样本。我们对每个组件的描述如下。MarginGAN的架构如图1所示。
3.3.1 分类器
我们将多分类器添加到原始的GAN中,因为高精度分类是我们在SSL中的目标。 分类器接收与判别器相同的输入--标记样本、未标记样本和生成的假样本。
对于标记的样本,分类器具有与普通多类分类器相同的目标。给定实例标签对(x,y),分类器C尝试最小化真实标签y和预测标签C(x)之间的交叉熵损失:
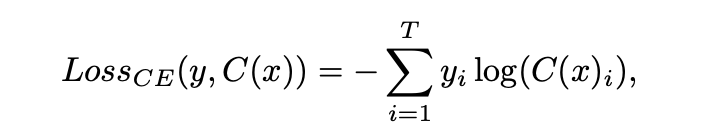
标记样本的损失函数可以公式化为:
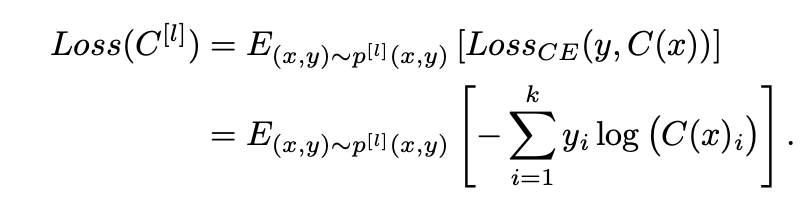
对于未标记的示例,分类器的目标是增加这些数据点的边缘。然而,由于没有关于相应真实标签的信息,我们不知道哪个类概率应该达到峰值。我们在一个热编码中利用伪标签来处理未标记的示例。
4.实验
4.1 初训练
与我们的工作类似,在先前的工作[5]中使用了伪标记,并报告了MNIST的实验。为了清楚地显示MarginGAN带来的改进,我们首先对MNIST进行了初步实验。我们使用infoGAN[22]中的生成器和鉴别器,并使用具有六层的简单卷积网络作为分类器。尽管我们使用的分类器可能比[5]中使用的更强大,但随后的消融研究可以揭示生成的假样本带来的贡献。
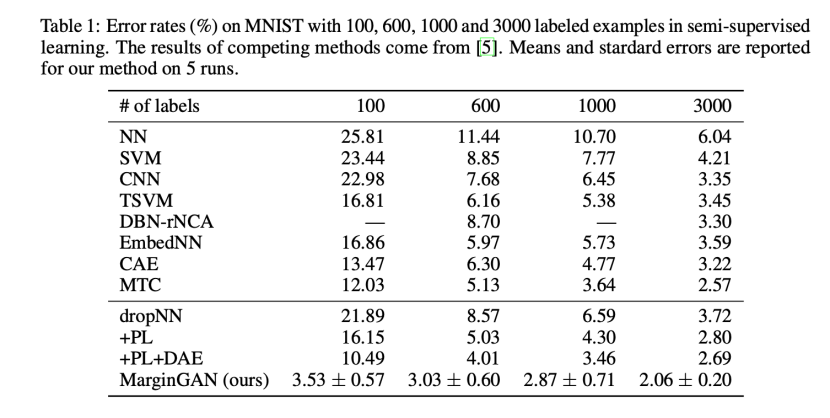
MNIST由60000幅图像的训练集和10000幅图像的测试集组成,所有图像均为28×28灰度像素。在设置中,我们采样100、600、1000或3000个标记样本,并将训练集的其余部分用作未标记样本。在训练时,我们首先对分类器进行预训练,以实现错误率低于8.0%、9.3%、9.5%和9.7%,仅使用标记样本,分别对应于100、600、1000和3000个标记样本。然后,未标记样本和生成样本参与训练过程。表1将我们的结果与[5]中的其他竞争方法进行了比较。我们可以看到,所提出的MarginGAN在每个设置上都优于这些基于伪样本的先前方法,这可以归因于生成的伪样本的参与。尽管与现有算法的比较有点不公平,但我们的方法在所有设置下都实现了更高的精确度,随后的消融研究进一步验证了我们方法的改进。
4.2 MNIST的消融研究
为了找出标记样本、未标记样本和生成的假样本的影响,我们在一次输入一种或多种样本的情况下进行消融实验。在消融研究中,由于伪标记的不稳定性和某些情况下缺乏标记示例,我们将学习率从0.1降低到0.01。我们测量了不同设置下训练收敛所需的最低错误率和时间,结果如表2所示。
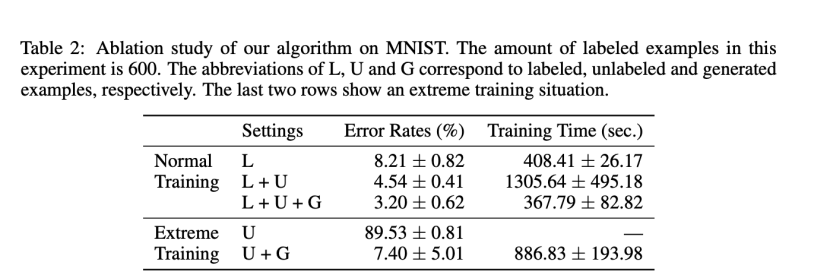
表2:MNIST算法的消融研究。本实验中标记的示例数量为600个。L、U和G的缩写分别对应于标记的示例、未标记的示例和生成的示例。最后两行显示了极端的训练情况。
未标记示例在半监督学习中起着重要作用。我们可以看到,添加未标记的示例可以将错误率从8.21%降低到4.54%,提高了3.67%。为了验证伪标签正确性的不确定性,我们进行了一次极端的尝试:对分类器进行预训练,以达到9.78%(±0.14%)的错误率,然后我们单独向分类器提供未标记的示例。换句话说,分类器不能再次访问标记的示例。令我们惊讶的是,错误率急剧上升,很快达到89.53%以上。不正确的伪标签将误导分类器并阻碍其泛化。
生成假示例我们将生成的示例反馈给分类器,使其对错误的伪标签具有鲁棒性,并提高了性能。我们可以看到,与只训练标记样本和未标记样本相比,生成的示例可以进一步将错误率从4.54%提高到3.20%。此外,值得注意的是,生成的示例可以显著减少71.8%的训练时间。然而,当我们继续训练时,错误率开始增加,出现过度拟合。当生成的图像逐渐变得更真实时,分类器仍然会减少边缘,这可能会影响性能。回到上述极端情况,当在预训练后组合未标记图像和生成图像时,错误率确实可以提高(从9.78%到7.40%)。
4.3 Generated Fake Images
我们在图3中显示了当分类器的精度增加时由MarginGAN生成的图像。正如我们所看到的,这些假图像看起来真的很“糟糕”:例如,MNIST和SVHN中生成的大多数数字都接近决策边界,因此无法以高置信度确定它们的标签。这种情况符合本文的动机。
5.结论
在这项工作中,我们提出了边缘生成对抗网络(MarginGAN),它由三部分组成:一个生成器、一个鉴别器和一个分类器。关键是分类器可以利用生成器生成的假示例来提高泛化性能。具体而言,分类器的目标是最大化真实示例的边缘值,最小化假样本的边缘。生成器试图产生真实的、大幅度的示例,以欺骗鉴别器和分类器。在多个基准上的实验结果表明,MarginGAN可以提高精度并缩短训练时间。
参考文献:
[1] Probability of error of some adaptive pattern-recognition machines
[4] Combining labeled and unlabeled data with co-training
[5] D.-H. Lee. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. ICML Workshop, 2013.
[6] S. Laine and T. Aila. Temporal ensembling for semi-supervised learning. arXiv:1610.02242, 2016.
[7] A.TarvainenandH.Valpola.Meanteachersarebetterrolemodels:Weight-averagedconsistency targets improve semisupervised deep learning results. NeurIPS, 2017.
关注下方《学姐带你玩AI》🚀🚀🚀
回复“500”获取更多经典高分论文
码字不易,欢迎大家点赞评论收藏!