Hadoop入门篇01---基础概念和部署教程
- Hadoop是什么
- Hadoop发展史
- Hadoop特点有哪些
- Hadoop版本
- Hadoop架构
- Hadoop 3.0新特性
- Hadoop集群搭建
- 集群简介
- 集群部署方式
- standalone mode(独立模式)
- Pseudo-Distributed mode(伪分布式模式)
- Cluster mode(集群模式)
- hadoop重新编译
- Hadoop3编译
- Hadoop集群安装
- 部署小结
- NameNode format(格式化操作)
- hadoop集群启动和停止
- Web UI界面访问测试
- Hadoop HDFS初体验
- 小结
- Hadoop MapReduce + YARN初体验
- 小结
- Hadoop HDFS基准测试
- 测试写入速度
- 测试读取速度
- 清除测试数据
本文参考: Hadoop3.x教程
Hadoop是什么
Hadoop是Apache旗下的一个用java语言实现开源软件框架,是一个开发和运行处理大规模数据的软件平台。允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理。
狭义上说,Hadoop指Apache这款开源框架,它的核心组件有:
- HDFS(分布式文件系统):解决海量数据存储
- YARN(作业调度和集群资源管理的框架):解决资源任务调度
- MAPREDUCE(分布式运算编程框架):解决海量数据计算
广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
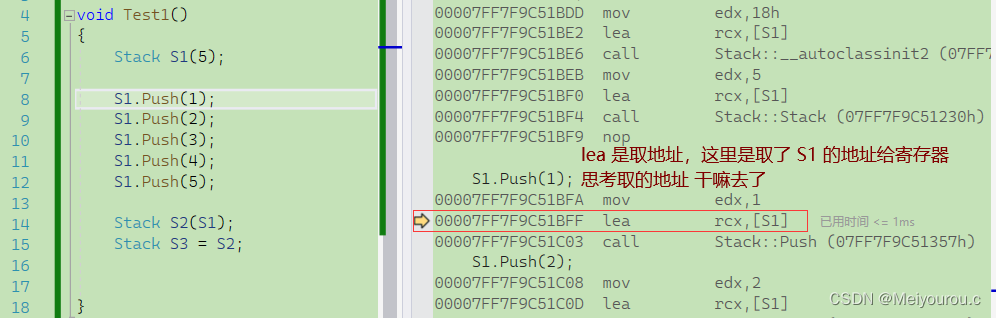
当下的Hadoop已经成长为一个庞大的体系,随着生态系统的成长,新出现的项目越来越多,其中不乏一些非Apache主管的项目,这些项目对HADOOP是很好的补充或者更高层的抽象。比如:
| 框架 | 用途 |
|---|---|
| HDFS | 分布式文件系统 |
| MapReduce | 分布式运算程序开发框架 |
| ZooKeeper | 分布式协调服务基础组件 |
| HIVE | 基于HADOOP的分布式数据仓库,提供基于SQL的查询数据操作 |
| FLUME | 日志数据采集框架 |
| oozie | 工作流调度框架 |
| Sqoop | 数据导入导出工具(比如用于mysql和HDFS之间) |
| Impala | 基于hive的实时sql查询分析 |
| Mahout | 基于mapreduce/spark/flink等分布式运算框架的机器学习算法库 |
Hadoop发展史
Hadoop是Apache Lucene创始人 Doug Cutting 创建的。最早起源于Nutch,它是Lucene的子项目。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题:如何解决数十亿网页的存储和索引问题。
2003年Google发表了一篇论文为该问题提供了可行的解决方案。论文中描述的是谷歌的产品架构,该架构称为:谷歌分布式文件系统(GFS),可以解决他们在网页爬取和索引过程中产生的超大文件的存储需求。
2004年 Google发表论文向全世界介绍了谷歌版的MapReduce系统。
同时期,以谷歌的论文为基础,Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目,迎来了它的快速发展期。
2006年Google发表了论文是关于BigTable的,这促使了后来的Hbase的发展。
因此,Hadoop及其生态圈的发展离不开Google的贡献。
Hadoop特点有哪些
- 扩容能力(Scalable):Hadoop是在可用的计算机集群间分配数据并完成计算任务的,这些集群可用方便的扩展到数以千计的节点中。
- 成本低(Economical):Hadoop通过普通廉价的机器组成服务器集群来分发以及处理数据,以至于成本很低。
- 高效率(Efficient):通过并发数据,Hadoop可以在节点之间动态并行的移动数据,使得速度非常快。
- 可靠性(Rellable):能自动维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy)计算任务。所以Hadoop的按位存储和处理数据的能力值得人们信赖。
Hadoop版本
Hadoop历史版本:
• 1.x版本系列:hadoop版本当中的第二代开源版本,主要修复0.x版本的一些bug等,该版本已被淘汰
• 2.x版本系列:架构产生重大变化,引入了yarn平台等许多新特性,是现在使用的主流版本。
• 3.x版本系列:对HDFS、MapReduce、YARN都有较大升级,还新增了Ozone key-value存储。
Hadoop发行版公司:
-
Hadoop发行版本分为开源社区版和商业版。社区版是指由Apache软件基金会维护的版本,是官方维护的版本体系。
-
商业版Hadoop是指由第三方商业公司在社区版Hadoop基础上进行了一些修改、整合以及各个服务组件兼容性测试而发行的版本,比较著名的有cloudera的CDH、mapR、hortonWorks等。
社区版:
免费开源版本Apache: http://hadoop.apache.org/
-
优点:拥有全世界的开源贡献者,代码更新迭代版本比较快,
-
缺点:版本的升级,版本的维护,版本的兼容性,版本的补丁都可能考虑不太周到
Apache所有软件的下载地址(包括各种历史版本):http://archive.apache.org/dist/
免费开源版本HortonWorks:
- hortonworks主要是雅虎主导Hadoop开发的副总裁,带领二十几个核心成员成立Hortonworks,核心产品软件HDP(ambari),HDF免费开源,并且提供一整套的web管理界面,供我们可以通过web界面管理我们的集群状态,web管理界面软件HDF网址(http://ambari.apache.org/),2018年,大数据领域的两大巨头公司Cloudera和Hortonworks宣布平等合并,Cloudera以股票方式收购Hortonworks,Cloudera股东最终获得合并公司60%的股份
收费版本:
-
软件收费版本Cloudera: https://www.cloudera.com/
-
cloudera主要是美国一家大数据公司在apache开源hadoop的版本上,通过自己公司内部的各种补丁,实现版本之间的稳定运行,大数据生态圈的各个版本的软件都提供了对应的版本,解决了版本的升级困难,版本兼容性等各种问题
Hadoop架构
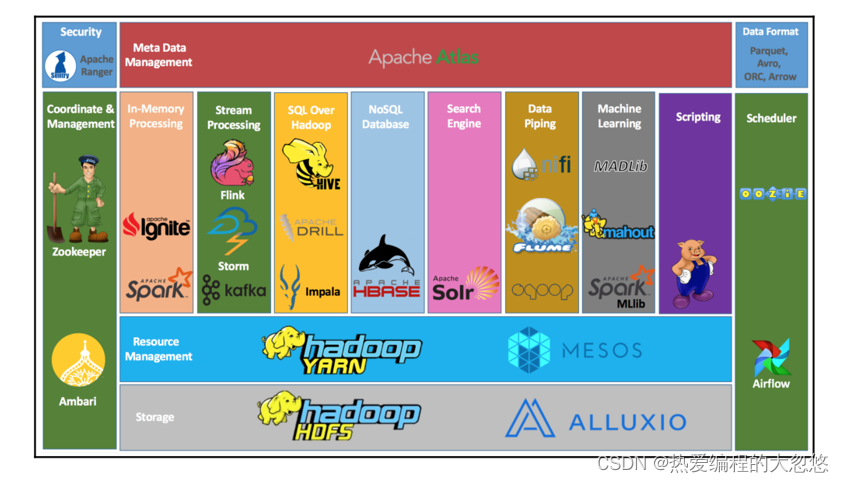
Hadoop 1.0 :
- HDFS(分布式文件存储)
- MapReduce(资源管理和分布式数据处理)
Hadoop 2.0 :
- HDFS(分布式文件存储)
- MapReduce(分布式数据处理)
- YARN(集群资源管理、任务调度)
由于Hadoop 2.0是基于JDK 1.7开发的,而JDK 1.7在2015年4月已停止更新,这直接迫使Hadoop社区基于JDK 1.8重新发布一个新的Hadoop版本,即hadoop 3.0。
Hadoop 3.0中引入了一些重要的功能和优化,包括HDFS 可擦除编码、多Namenode支持、MR Native Task优化、YARN基于cgroup的内存和磁盘IO隔离、YARN container resizing等。
Apache hadoop 项目组最新消息,hadoop3.x以后将会调整方案架构,将Mapreduce 基于内存+io+磁盘,共同处理数据。
改变最大的是hdfs,hdfs 通过最近block块计算,根据最近计算原则,本地block块,加入到内存,先计算,通过IO,共享内存计算区域,最后快速形成计算结果,比Spark快10倍。
Hadoop 3.0新特性
初学阶段,了解即可
Hadoop 3.0在功能和性能方面,对hadoop内核进行了多项重大改进,主要包括:
通用性:
- 精简Hadoop内核,包括剔除过期的API和实现,将默认组件实现替换成最高效的实现。
- Classpath isolation:以防止不同版本jar包冲突
- Shell脚本重构: Hadoop 3.0对Hadoop的管理脚本进行了重构,修复了大量bug,增加了新特性。
HDFS:
Hadoop3.x中Hdfs在可靠性和支持能力上作出很大改观:
1.HDFS支持数据的擦除编码,这使得HDFS在不降低可靠性的前提下,节省一半存储空间。
2.多NameNode支持,即支持一个集群中,一个active、多个standby namenode部署方式。
注:多ResourceManager特性在hadoop 2.0中已经支持。
HDFS纠删码:
- 在Hadoop3.X中,HDFS实现了Erasure Coding这个新功能。Erasure coding纠删码技术简称EC,是一种数据保护技术.最早用于通信行业中数据传输中的数据恢复,是一种编码容错技术。
- 它通过在原始数据中加入新的校验数据,使得各个部分的数据产生关联性。在一定范围的数据出错情况下,通过纠删码技术都可以进行恢复。
- hadoop-3.0之前,HDFS存储方式为每一份数据存储3份,这也使得存储利用率仅为1/3,hadoop-3.0引入纠删码技术(EC技术),实现1份数据+0.5份冗余校验数据存储方式。
- 与副本相比纠删码是一种更节省空间的数据持久化存储方法。标准编码(比如Reed-Solomon(10,4))会有1.4 倍的空间开销;然而HDFS副本则会有3倍的空间开销。
支持多个NameNodes:
- 最初的HDFS NameNode high-availability实现仅仅提供了一个active NameNode和一个Standby NameNode;并且通过将编辑日志复制到三个JournalNodes上,这种架构能够容忍系统中的任何一个节点的失败。
- 然而,一些部署需要更高的容错度。我们可以通过这个新特性来实现,其允许用户运行多个Standby NameNode。比如通过配置三个NameNode和五个JournalNodes,这个系统可以容忍2个节点的故障,而不是仅仅一个节点。
MapReduce:
Hadoop3.X中的MapReduce较之前的版本作出以下更改:
-
Tasknative优化:为MapReduce增加了C/C++的map output collector实现(包括Spill,Sort和IFile等),通过作业级别参数调整就可切换到该实现上。对于shuffle密集型应用,其性能可提高约30%。
-
MapReduce内存参数自动推断。在Hadoop 2.0中,为MapReduce作业设置内存参数非常繁琐,一旦设置不合理,则会使得内存资源浪费严重,在Hadoop3.0中避免了这种情况。
-
Hadoop3.x中的MapReduce添加了Map输出collector的本地实现,对于shuffle密集型的作业来说,这将会有30%以上的性能提升。
默认端口更改:
- 在hadoop3.x之前,多个Hadoop服务的默认端口都属于Linux的临时端口范围(32768-61000)。这就意味着用户的服务在启动的时候可能因为和其他应用程序产生端口冲突而无法启动。
- 现在这些可能会产生冲突的端口已经不再属于临时端口的范围,这些端口的改变会影响NameNode, Secondary NameNode, DataNode以及KMS。与此同时,官方文档也进行了相应的改变,具体可以参见 HDFS-9427以及HADOOP-12811。
Namenode ports: 50470 —> 9871, 50070—> 9870, 8020 —> 9820
Secondary NN ports: 50091 —> 9869,50090 —> 9868
Datanode ports: 50020 —> 9867, 50010—> 9866, 50475 —> 9865, 50075 —> 9864
Kms server ports: 16000 —> 9600 (原先的16000与HMaster端口冲突)
YARN 资源类型:
-
YARN 资源模型(YARN resource model)已被推广为支持用户自定义的可数资源类型(support user-defined countable resource types),不仅仅支持 CPU 和内存。
-
比如集群管理员可以定义诸如 GPUs、软件许可证(software licenses)或本地附加存储器(locally-attached storage)之类的资源。YARN 任务可以根据这些资源的可用性进行调度。
Hadoop集群搭建
集群简介
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起。
HDFS集群负责海量数据的存储,集群中的角色主要有:
- NameNode
- DataNode
- SecondaryNameNode
YARN集群负责海量数据运算时的资源调度,集群中的角色主要有:
- ResourceManager
- NodeManager
那mapreduce是什么呢?
- 它其实是一个分布式运算编程框架,是应用程序开发包,由用户按照编程规范进行程序开发,后打包运行在HDFS集群上,并且受到YARN集群的资源调度管理。
集群部署方式
Hadoop部署方式分三种:
standalone mode(独立模式)
独立模式又称为单机模式,仅1个机器运行1个java进程,主要用于调试。
Pseudo-Distributed mode(伪分布式模式)
伪分布模式也是在1个机器上运行HDFS的NameNode和DataNode、YARN的 ResourceManger和NodeManager,但分别启动单独的java进程,主要用于调试。
Cluster mode(集群模式)
集群模式主要用于生产环境部署。会使用N台主机组成一个Hadoop集群。这种部署模式下,主节点和从节点会分开部署在不同的机器上。
hadoop重新编译
为什么要编译hadoop?
- 由于apache给出的hadoop的安装包没有提供带C程序访问的接口,所以我们在使用本地库(本地库可以用来做压缩,以及支持C程序等等)的时候就会出问题,需要对Hadoop源码包进行重新编译。
Hadoop3编译
- 基础环境:Centos 7.7
编译环境软件安装目录
mkdir -p /export/server
- 安装编译相关的依赖
1、yum install gcc gcc-c++
#下面这个命令不需要执行 手动安装cmake
2、yum install make cmake #(这里cmake版本推荐为3.6版本以上,版本低源码无法编译!可手动安装)
3、yum install autoconf automake libtool curl
4、yum install lzo-devel zlib-devel openssl openssl-devel ncurses-devel
5、yum install snappy snappy-devel bzip2 bzip2-devel lzo lzo-devel lzop libXtst
- 手动安装cmake
#yum卸载已安装cmake 版本低
yum erase cmake
#解压
tar zxvf cmake-3.13.5.tar.gz
#编译安装
cd /export/server/cmake-3.13.5
./configure
make && make install
#验证
[root@node4 ~]# cmake -version
cmake version 3.13.5
#如果没有正确显示版本 请断开SSH连接 重写登录
- 手动安装snappy
#卸载已经安装的
cd /usr/local/lib
rm -rf libsnappy*
#上传解压
tar zxvf snappy-1.1.3.tar.gz
#编译安装
cd /export/server/snappy-1.1.3
./configure
make && make install
#验证是否安装
[root@node4 snappy-1.1.3]# ls -lh /usr/local/lib |grep snappy
-rw-r--r-- 1 root root 511K Nov 4 17:13 libsnappy.a
-rwxr-xr-x 1 root root 955 Nov 4 17:13 libsnappy.la
lrwxrwxrwx 1 root root 18 Nov 4 17:13 libsnappy.so -> libsnappy.so.1.3.0
lrwxrwxrwx 1 root root 18 Nov 4 17:13 libsnappy.so.1 -> libsnappy.so.1.3.0
-rwxr-xr-x 1 root root 253K Nov 4 17:13 libsnappy.so.1.3.0
- 安装配置JDK 1.8
#解压安装包
tar zxvf jdk-8u65-linux-x64.tar.gz
#配置环境变量
vim /etc/profile
export JAVA_HOME=/export/server/jdk1.8.0_65
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
source /etc/profile
#验证是否安装成功
java -version
java version "1.8.0_65"
Java(TM) SE Runtime Environment (build 1.8.0_65-b17)
Java HotSpot(TM) 64-Bit Server VM (build 25.65-b01, mixed mode)
You have new mail in /var/spool/mail/root
- 安装配置maven
#解压安装包
tar zxvf apache-maven-3.5.4-bin.tar.gz
#配置环境变量
vim /etc/profile
export MAVEN_HOME=/export/server/apache-maven-3.5.4
export MAVEN_OPTS="-Xms4096m -Xmx4096m"
export PATH=:$MAVEN_HOME/bin:$PATH
source /etc/profile
#验证是否安装成功
[root@node4 ~]# mvn -v
Apache Maven 3.5.4
#添加maven 阿里云仓库地址 加快国内编译速度
vim /export/server/apache-maven-3.5.4/conf/settings.xml
<mirrors>
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
</mirrors>
- 安装ProtocolBuffer 2.5.0
#解压
tar zxvf protobuf-2.5.0.tar.gz
#编译安装
cd /export/server/protobuf-2.5.0
./configure
make && make install
#验证是否安装成功
[root@node4 protobuf-2.5.0]# protoc --version
libprotoc 2.5.0
- 编译hadoop

#上传解压源码包
tar zxvf hadoop-3.1.4-src.tar.gz
#编译
cd /export/server/hadoop-3.1.4-src
mvn clean package -Pdist,native -DskipTests -Dtar -Dbundle.snappy -Dsnappy.lib=/usr/local/lib
#参数说明:
Pdist,native :把重新编译生成的hadoop动态库;
DskipTests :跳过测试
Dtar :最后把文件以tar打包
Dbundle.snappy :添加snappy压缩支持【默认官网下载的是不支持的】
Dsnappy.lib=/usr/local/lib :指snappy在编译机器上安装后的库路径
- 编译之后的安装包路径
/export/server/hadoop-3.1.4-src/hadoop-dist/target
Hadoop集群安装
集群模式主要用于生产环境部署,需要多台主机,并且这些主机之间可以相互访问,我们在之前搭建好基础环境的三台虚拟机上进行Hadoop的搭建。
集群中各个节点角色规划的准则:
- 根据软件工作特性和服务器硬件资源情况合理分配
- 比如依赖内存工作的NameNode是不是部署在大内存机器上?
角色规划注意事项:
- 资源上有抢夺冲突的,尽量不要部署在一起
- 工作上需要互相配合的。尽量部署在一起
- 集群规划: 准备三台服务器
node1 node2 node3
HDFS集群守护进程:
NameNode Y
SecondaryNameNode Y
DataNode Y Y Y
YARN集群守护进程:
ResourceManager Y
NodeManager Y Y Y
- 服务器基础环境准备
1.分别设置好三台服务器的主机名为node1,node2,node3
vim /etc/hostname

2.在每台服务器都建立好HOSTS映射
vim /etc/hosts
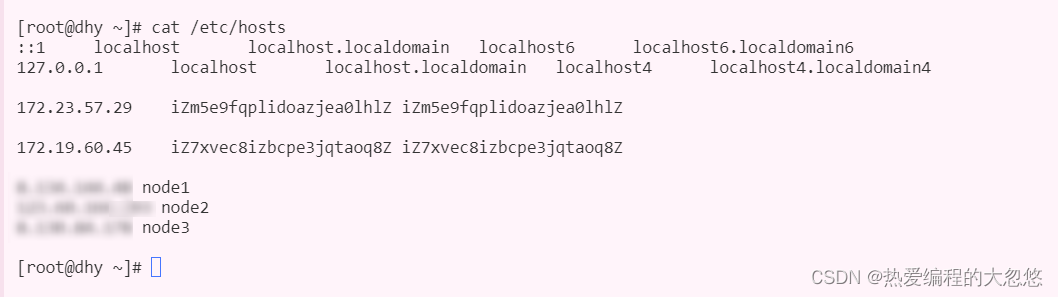
如果采用云服务部署,每台云服务节点对应的hosts文件中,将自身节点的ip地址填写为内网ip,其他节点为外网ip.
阿里云搭建hadoop集群服务器,内网、外网访问问题
- 将hadoop通信涉及到的端口号全部放开
Hadoop 3.x版本的组件之间的通信需要放开以下端口:
- HDFS:
- Namenode Web UI: 9870 (可配置)
- Datanode 数据传输端口:9864 (可配置)
- Datanode Web UI: 9864 (可配置)
- Secondary Namenode Web UI: 9868 (可配置)
- JournalNode RPC: 8485 (可配置)
- NFS Gateway 服务:111, 2049 (可配置)
- NFS Gateway Web UI: 2049 (可配置)
- YARN:
- Resource Manager Web UI: 8088 (可配置)
- Node Manager Web UI: 8042 (可配置)
- Application History Web UI: 8188 (可配置)
- Timeline Server Web UI: 8188 (可配置)
- MapReduce:
- JobHistory Server Web UI: 19888 (可配置)
注意:这些端口号是默认配置值,具体的端口号需要根据实际部署情况进行配置。同时,不同的Hadoop组件之间也需要相互通信,具体的端口号需要根据实际部署情况进行配置。
- ssh免密登录配置
没有必要两两打通免密登录,这里为了方便后续脚本一键启动,可以只打通node1到node1,node2,node3的单向免密登录即可
此处以配置node1免密登录node1,node2,node3为例:
ssh-keygen #4个回车 生成公钥、私钥
ssh-copy-id node1、ssh-copy-id node2、ssh-copy-id node3 #
- 集群时间同步
yum -y install ntpdate
ntpdate ntp4.aliyun.com

- 在三台服务器上安装jdk 1.8
ubuntun:
sudo apt-get install openjdk-8-jdk
centos:
yum install java-1.8.0-openjdk* -y
- 创建统一的工作目录
mkdir -p /export/server #软件安装路径
mkdir -p /export/data #数据存储路径
mkdir -p /export/software #安装包存放路径
- 上传,解压Hadoop安装包(node1)
# hadoop-3.1.4-bin-snappy-CentOS7.tar.gz是已经编译好的安装包压缩包
tar zxvf hadoop-3.1.4-bin-snappy-CentOS7.tar.gz -C /export/server/
Hadoop安装包目录结构:

- 进入etc目录,编辑hadoop-env.sh配置文件
cd /export/server/hadoop-3.1.4/etc/hadoop/
vim hadoop-env.sh
#配置JAVA_HOME
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.362.b08-1.el7_9.x86_64/jre
#设置用户以执行对应角色shell命令
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
- 编辑修改 core-site.xml
cd /export/server/hadoop-3.1.4/etc/hadoop/
vim core-site.xml
<configuration>
<!-- 默认文件系统的名称。通过URI中schema区分不同文件系统。-->
<!-- file:///本地文件系统 hdfs:// hadoop分布式文件系统 gfs://。-->
<!-- hdfs文件系统访问地址:http://nn_host:8020(nn表示nameNode节点所在位置)。-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<!-- hadoop本地数据存储目录 format时自动生成 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop-3.1.4</value>
</property>
<!-- 在Web UI访问HDFS使用的用户名。-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
- 编辑修改hdfs-site.xml
cd /export/server/hadoop-3.1.4/etc/hadoop/
vim hdfs-site.xml
<!--设定SNN运行主机和端口(主角色的辅助角色)-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:9868</value>
</property>
- 编辑修改mapred-site.xml
cd /export/server/hadoop-3.1.4/etc/hadoop/
vim mapred-site.xml
<!-- mr程序默认运行方式。yarn集群模式 local本地模式-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR App Master环境变量。-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR MapTask环境变量。-->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR ReduceTask环境变量。-->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
- 编辑修改yarn-site.xml
cd /export/server/hadoop-3.1.4/etc/hadoop/
vim yarn-site.xml
<!-- yarn集群主角色RM运行机器。-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<!-- 0.0.0.0表示该地址将监听所有网络接口上的请求,而不仅仅是监听localhost上的请求。8088是ResourceManager Web UI使用的端口号,可以根据实际情况进行更改。-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>0.0.0.0:8088</value>
</property>
<!-- NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MR程序。-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 每个容器请求的最小内存资源(以MB为单位)。-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<!-- 每个容器请求的最大内存资源(以MB为单位)。-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<!-- 容器虚拟内存与物理内存之间的比率。-->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>
- 编辑修改workers配置文件(配置从角色所在主机位置)
cd /export/server/hadoop-3.1.4/etc/hadoop/
vim workers
node1
node2
node3
- 分发同步安装包—在node1机器上将Hadoop安装包scp同步到其他机器
cd /export/server/
scp -r hadoop-3.1.4 root@node2:/export/server/
scp -r hadoop-3.1.4 root@node3:/export/server/
- 配置hadoop的环境变量
- 在node1上配置Hadoop环境变量
vim /etc/profile
export HADOOP_HOME=/export/server/hadoop-3.1.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 将修改后的环境变量同步其他机器
scp /etc/profile root@node2:/etc/
scp /etc/profile root@node3:/etc/
- 重新加载环境变量 验证是否生效(3台机器)
source /etc/profile
hadoop #验证环境变量是否生效

部署小结
1.服务器基础环境
2.Hadoop源码编译
3.Hadoop配置文件修改
4.shell文件、4个xml文件、workers文件
5.配置文件集群同步
NameNode format(格式化操作)
首次启动HDFS时,必须对其进行格式化操作。
- format本质上是初始化工作,进行HDFS清理和准备工作
命令:
hdfs namenode -format
format帮助创建了nameNode的工作目录,和nameNode初始化时相关文件。


注意:
1.首次启动之前需要format操作
2.format只能进行一次 后续不再需要
3.如果多次format除了造成数据丢失外,还会导致hdfs集群主从角色之间互不识别,通过删除所有机器hadoop.tmp.dir目录重新forma解决
hadoop集群启动和停止
手动逐个进程启动和停止:
- 每台机器上每次手动启动关闭一个角色进程
- HDFS集群
hdfs --daemon start namenode|datanode|secondarynamenode
hdfs --daemon stop namenode|datanode|secondarynamenode
- YARN集群
yarn --daemon start resourcemanager|nodemanager
yarn --daemon stop resourcemanager|nodemanager
shell脚本一键启动停止:
此处的脚本一键启动停止,依赖于我们上面配置好的免密登录配置
- 在node1上,使用软件自带的shell脚本一键启动
- 前提:配置好机器之间的SSH免密登录和workers文件。
单独启动HDFS集群的启停脚本:
- start-dfs.sh
- stop-dfs.sh
单独启动YARN集群的启停脚本:
- start-yarn.sh
- stop-yarn.sh
启动Hadoop集群的启停脚本(包含上诉两个集群):
- start-all.sh
- stop-all.sh
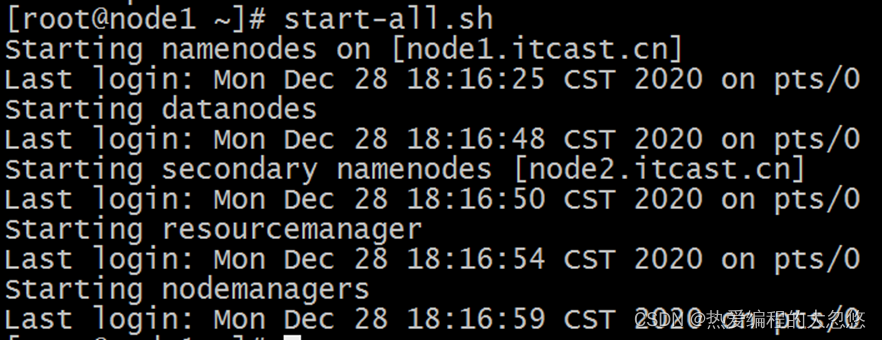
启动完毕之后可以使用jps命令查看进程是否启动成功:
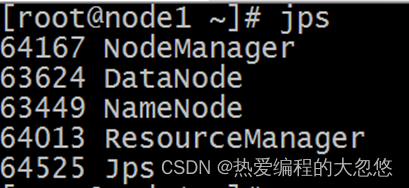

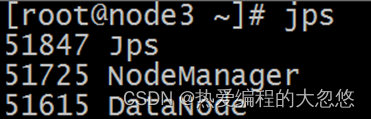
Hadoop启动日志路径:/export/server/hadoop-3.1.4/logs/

Web UI界面访问测试
Hadoop Web UI界面HDFS集群地址:http://namenode_host:9870
其中namenode_host是namenode运行所在机器的主机名或者ip, 如果使用主机名访问,别忘了在Windows配置hosts

Hadoop Web UI界面YARN集群地址:http://resourcemanager_host:8088/cluster
其中resourcemanager_host是resourcemanager运行所在机器的主机名或者ip,如果使用主机名访问,别忘了在Windows配置hosts
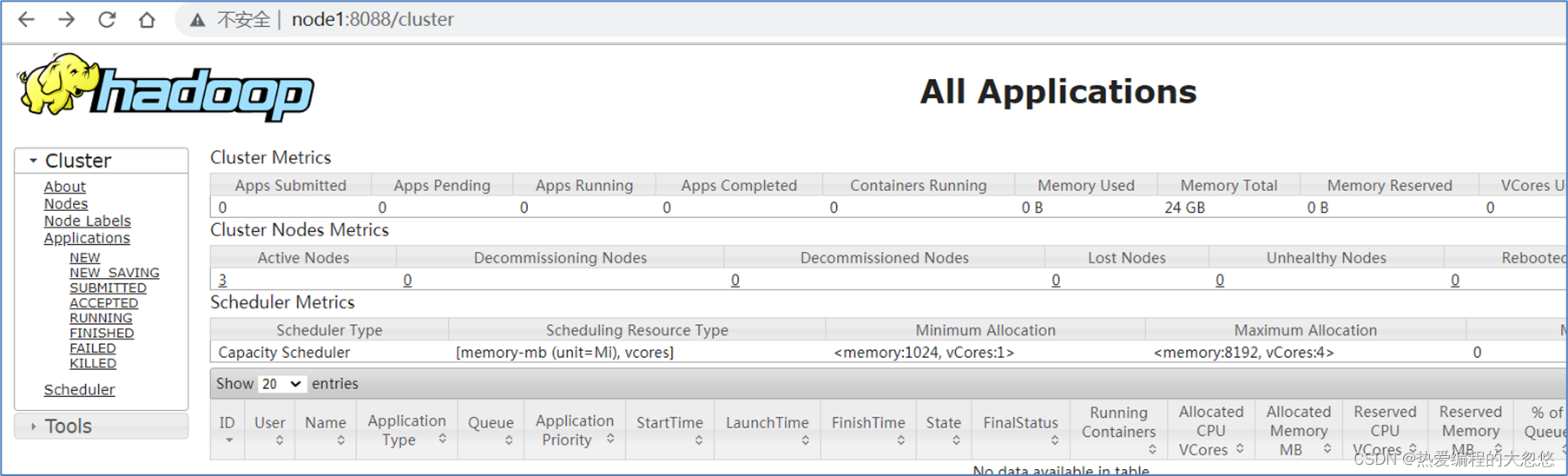
Hadoop HDFS初体验
- 创建目录
hadoop fs -mkdir /dhy
- 上传文件
hadoop fs -put hadoop-root-datanode-dhy.out.1 /dhy
- 查询文件
hadoop fs -ls /

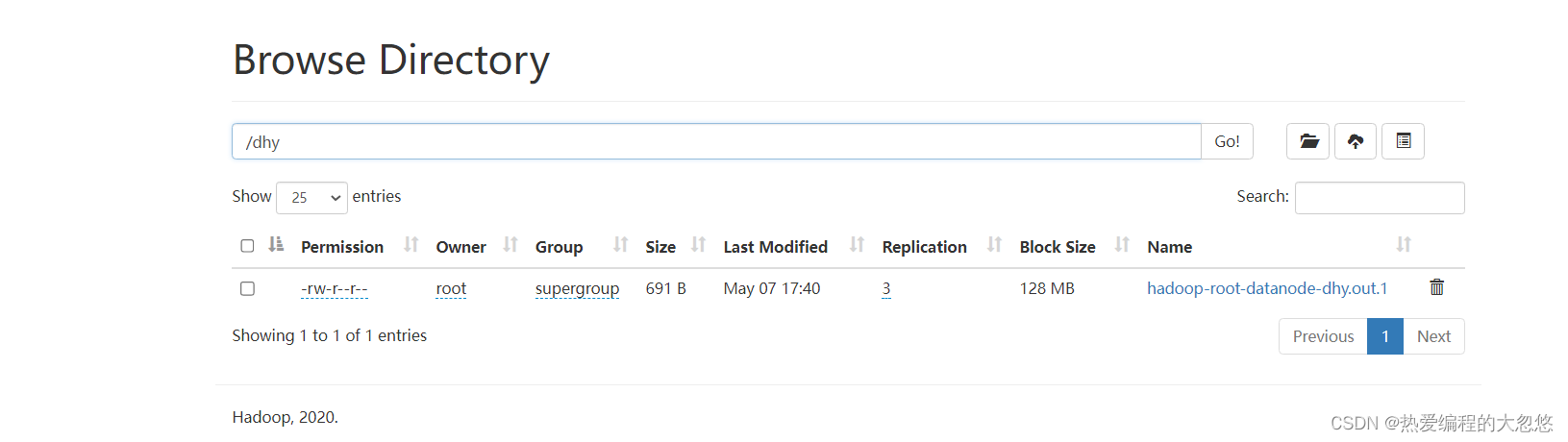
小结
-
HDFS本质就是一个文件系统
-
有目录树结构 和Linux类似,分文件、文件夹
-
但是为什么上传一个小文件也这么慢?大家可以思考一下
Hadoop MapReduce + YARN初体验
- 执行Hadoop官方自带的MapReduce案例 : 评估圆周率π的值
cd /export/server/hadoop-3.1.4/share/hadoop/mapreduce/
hadoop jar hadoop-mapreduce-examples-3.1.4.jar pi 2 4

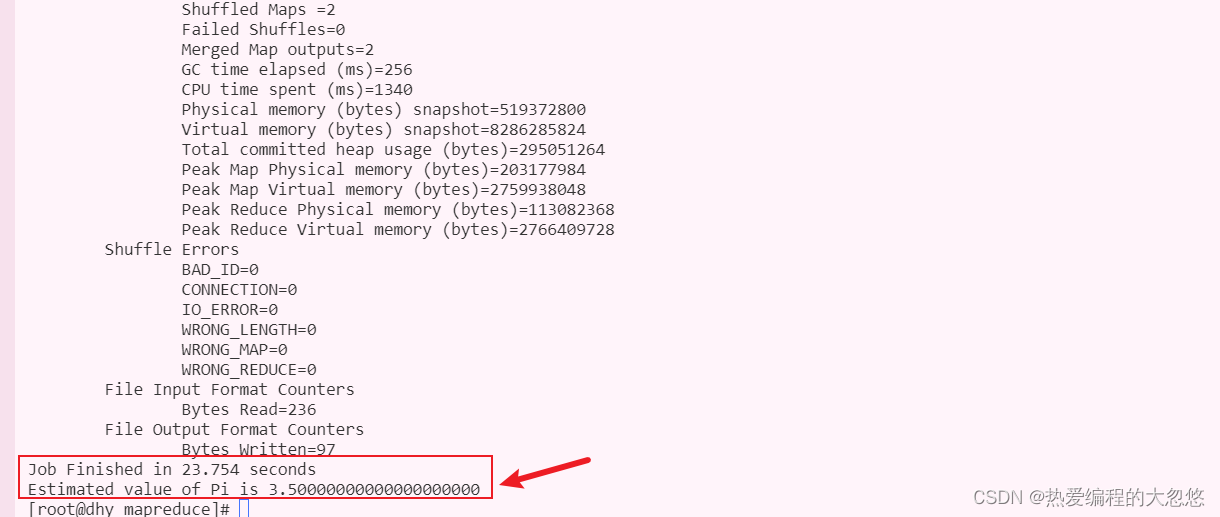
访问Yarn提供的Web UI界面查看执行任务的结果:
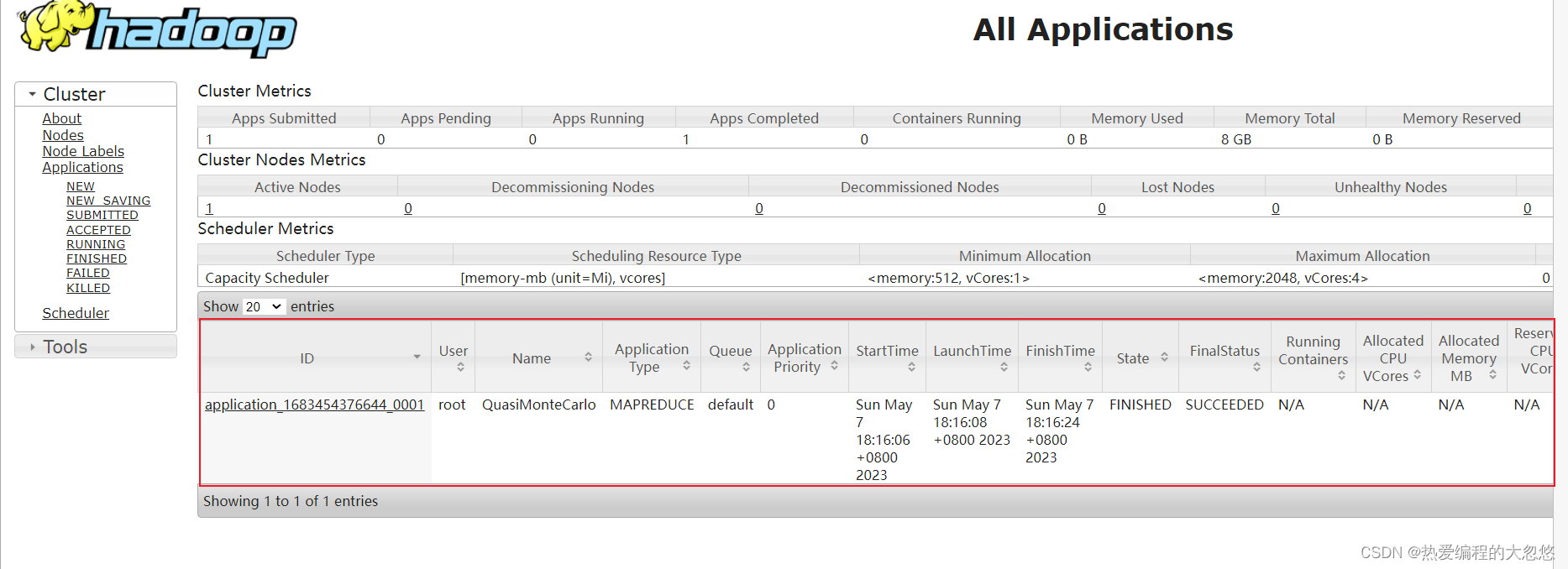
小结
1.MapReduce本质是程序?
2.执行MapReduce的时候,为什么首先请求YARN?
3.MapReduce看上去好像是两个阶段?
4.先Map,再Reduce?
5.处理小数据的时候,MapReduce速度快吗?
Hadoop HDFS基准测试
测试写入速度
- 确保HDFS集群和YARN集群成功启动
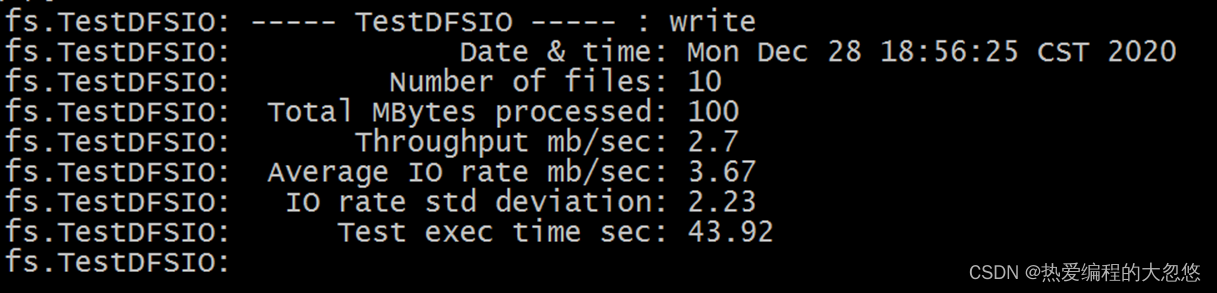
hadoop jar /export/server/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.4-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 10MB
说明:向HDFS文件系统中写入数据,10个文件,每个文件10MB,文件存放到/benchmarks/TestDFSIO中
Throughput:吞吐量、Average IO rate:平均IO率、IO rate std deviation:IO率标准偏差
测试读取速度
- 确保HDFS集群和YARN集群成功启动
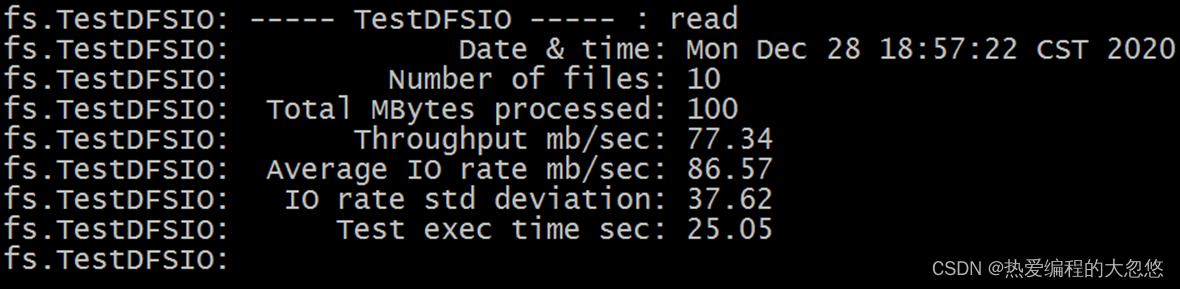
hadoop jar /export/server/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.4-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 10MB
说明:在HDFS文件系统中读入10个文件,每个文件10M
Throughput:吞吐量、Average IO rate:平均IO率、IO rate std deviation:IO率标准偏差
清除测试数据
- 确保HDFS集群成功启动
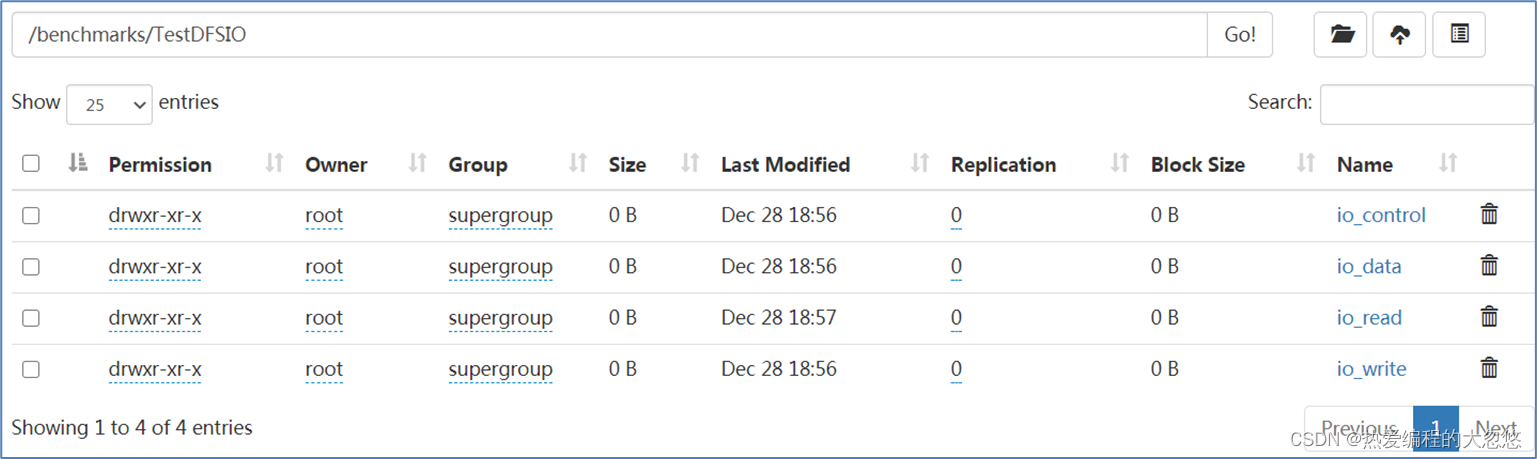
hadoop jar /export/server/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.4-tests.jar TestDFSIO -clean
说明:测试期间,会在HDFS集群上创建 /benchmarks目录,测试完毕后,我们可以清理该目录。







![[羊城杯 2020]a_piece_of_java](https://img-blog.csdnimg.cn/414ba59cca7745009fd7bd1a645da217.png)