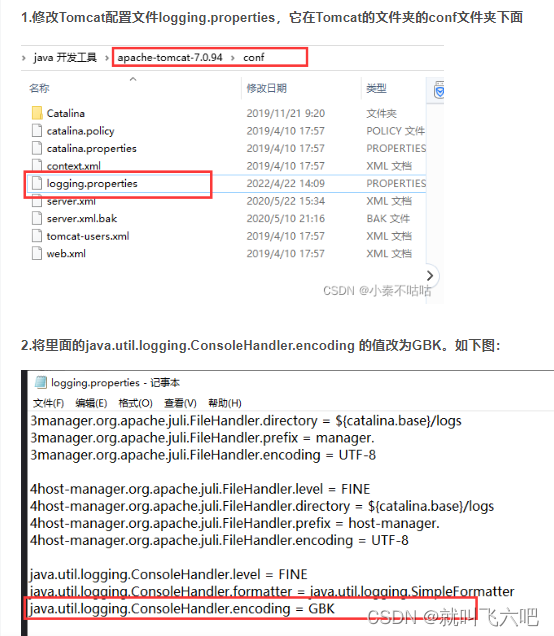
传统机器学习(六)集成算法(2)—Adaboost算法原理
1 算法概述
Adaboost(Adaptive Boosting)是一种自适应增强算法,它集成多个弱决策器进行决策。
Adaboost解决二分类问题,且二分类的标签为{-1,1}。注:一定是{-1,1},不能是{0,1}
它的训练过程是通过不断添加新的弱决策器,使损失函数继续下降,直到添加决策器已无效,最终将所有决策器集成一个整体进行决策。
1.1 Adaboost概述
1.1.1 Adaboost的具体操作
- Adaboost会先训练一个弱决策器进行预测,在单个决策器的预测基础上,添加第二个,让预测更准确,在两个决策器的集成决策基础上,添加第三个,让预测更准确,…,如此类推,通过不断添加新的决策器,使损失函数持续下降,直到新增的决策器无法再让损失函数下降,则停止训练。最终将所有决策器集成一个整体进行决策。
- 理论上Adaboost适用于多种决策器,但实际中基本都是以决策树作为决策器,这样的Adboost也称为提升树。在不特指的情况下,
Adboost一般就是指以决策树为决策器的Adaboost算法。 - 个体学习器之间存在强依赖关系、必须串行生成的序列化方法。
- 【提高】那些在前一轮被弱分类器【分错】的样本的权值
- 【减小】那些在前一轮被弱分类器【分对】的样本的权值
- 【加法模型】将弱分类器进行【线性组合】
1.1.2 Adaboost的模型表达式
F ( x ) = a 1 D 1 ( x ) + a 2 D 2 ( x ) + . . . + a m D m ( x ) 其中, D i ( x ) : 第 i 个决策器 a i :决策器的权重系数,为正数 可以看到 , A d a b o o s t 模型就是一系列决策器的加权和。 F(x) = a_1D_1(x) + a_2D_2(x)+...+a_mD_m(x) \\ 其中,D_i(x):第i个决策器\\ a_i:决策器的权重系数,为正数\\ 可以看到,Adaboost模型就是一系列决策器的加权和。 F(x)=a1D1(x)+a2D2(x)+...+amDm(x)其中,Di(x):第i个决策器ai:决策器的权重系数,为正数可以看到,Adaboost模型就是一系列决策器的加权和。
模型的输出是一个数值(即所有决策器的权重和)
-
如果模型的输出是负数,判为-1标签,
-
如果模型的输出是正数,判为 1标签。
一个Adboost模型由以下参数决定:
- 各个决策器自身的模型参数
- 各个决策器的权重
注意:
在每一轮,分别记录好那些被【当前分类器】正确分类和错误分类的样本,在下一轮训练中,提高【错误分类样本】的权值,同时降低【正确分类样本】的权值,用来训练新的弱分类器。这样一来,没有得到正确分类的数据,由于其权值加大,会受到后一轮弱分类器的更大关注。
【加权多数表决】是指:
1、加大【分类误差率】小的弱分类器的权值,使其在表决中起到较大的作用。
2、减小【分类误差率】大的多分类器的权值,使其在表决中起到较小的作用。
1.1.3 前向分布算法
模型求解采用前向分步算法,即逐个逐个决策器训练,先训练第一个,在第一个基础上,训练第二个…每个决策器的训练目标都力求在当前最优(把损失函数降到最低)。直到新增决策器已无法减少误差(或达到最大决策器个数m)。

Adboost的关键点在于每个决策器的训练上,对于第k个决策器的训练,Adboost的训练方法是把决策器D(k)和系数a(k)拆开训练,先训练D(k),后训练系数a(k)。
1.1.4 算法流程

第一步:初始化样本权重
初始化训练数据(每个样本)的权值分布。每一个训练样本,初始化时赋予同样的权值w=1/N。N为样本总数。
权值分布
D
1
=
(
w
11
,
w
12
,
.
.
.
,
w
1
i
.
.
.
,
w
1
N
)
,
w
1
i
=
1
N
D
1
表示,第一次迭代每个样本的权值。
w
11
表示,第
1
次迭代时的第一个样本的权值。
N
为样本总数。
权值分布D_1 = (w_{11},w_{12},...,w_{1i}...,w_{1N}),w_{1i} =\frac{1}{N} \\ D_1表示,第一次迭代每个样本的权值。w_{11}表示,第1次迭代时的第一个样本的权值。N为样本总数。
权值分布D1=(w11,w12,...,w1i...,w1N),w1i=N1D1表示,第一次迭代每个样本的权值。w11表示,第1次迭代时的第一个样本的权值。N为样本总数。
第二步:进行多次迭代
a
)
使用具有权值分布
D
m
(
m
=
1
,
2
,
3
…
N
)
的训练样本集进行学习,得到弱的分类器。
G
m
(
x
)
取值为
−
1
,
1
意思是,第
m
次迭代时的弱分类器,将样本
x
要么分类成
−
1
,要么分类成
1.
那么根据什么准则得到弱分类器?
准则为:该弱分类器的误差函数最小,也就是【分错的样本对应的权值之和】最小。
ε
m
=
∑
i
=
1
N
w
n
m
I
(
y
m
(
x
n
)
≠
t
n
)
b
)
计算弱分类器
G
m
(
x
)的话语权,话语权
a
m
表示
G
m
(
x
)在最终分类器中的重要程度。其中
e
m
,为上步中的
ε
m
(误差函数的值)
a
m
=
1
2
ln
1
−
e
m
e
m
该式是随
e
m
减小而增大。即误差率小的分类器,在最终分类器的重要程度大。
c
)更新训练样本集的权值分布。用于下一轮迭代。其中,被误分的样本的权值会增大,被正确分的权值减小。
D
m
+
1
=
(
w
m
+
1
,
1
,
w
m
+
1
,
2
,
.
.
.
,
w
m
+
1
,
i
.
.
.
,
w
m
+
1
,
N
)
)
公式
:
w
m
+
1
,
i
=
w
m
,
i
Z
m
e
−
a
m
y
i
G
m
(
x
i
)
,
i
=
1
,
2
,
.
.
.
,
N
Z
m
=
∑
i
=
1
N
w
m
,
i
e
−
a
m
y
i
G
m
(
x
i
)
,是保证权重和为
1
a)使用具有权值分布D_m(m=1,2,3…N)的训练样本集进行学习,得到弱的分类器。\\ G_m(x)取值为{-1,1} \\ 意思是,第m次迭代时的弱分类器,将样本x要么分类成-1,要么分类成1.那么根据什么准则得到弱分类器?\\ 准则为:该弱分类器的误差函数最小,也就是【分错的样本对应的 权值之和】最小。\\ ε_m=\sum\limits_{i=1}^Nw_{n}^mI(y_m(x_n) \neq t_n ) \\ b)计算弱分类器G_m(x)的话语权,话语权a_m表示G_m(x)在最终分类器中的重要程度。其中e_m,为上步中的ε_m(误差函数的值)\\ a_m = \frac{1}{2}\ln\frac{1-e_m}{e_m} \\ 该式是随e_m减小而增大。即误差率小的分类器,在最终分类器的 重要程度大。\\ c)更新训练样本集的权值分布。用于下一轮迭代。其中,被误分的样本的权值会增大,被正确分的权值减小。\\ D_{m+1} = (w_{m+1,1},w_{m+1,2},...,w_{m+1,i}...,w_{m+1,N}))\\ 公式:w_{m+1,i} = \frac{w_{m,i}}{Z_m}e^{-a_my_iG_m(x_i)},i=1,2,...,N \\ Z_m=\sum\limits_{i=1}^Nw_{m,i}e^{-a_my_iG_m(x_i)},是保证权重和为1
a)使用具有权值分布Dm(m=1,2,3…N)的训练样本集进行学习,得到弱的分类器。Gm(x)取值为−1,1意思是,第m次迭代时的弱分类器,将样本x要么分类成−1,要么分类成1.那么根据什么准则得到弱分类器?准则为:该弱分类器的误差函数最小,也就是【分错的样本对应的权值之和】最小。εm=i=1∑NwnmI(ym(xn)=tn)b)计算弱分类器Gm(x)的话语权,话语权am表示Gm(x)在最终分类器中的重要程度。其中em,为上步中的εm(误差函数的值)am=21lnem1−em该式是随em减小而增大。即误差率小的分类器,在最终分类器的重要程度大。c)更新训练样本集的权值分布。用于下一轮迭代。其中,被误分的样本的权值会增大,被正确分的权值减小。Dm+1=(wm+1,1,wm+1,2,...,wm+1,i...,wm+1,N))公式:wm+1,i=Zmwm,ie−amyiGm(xi),i=1,2,...,NZm=i=1∑Nwm,ie−amyiGm(xi),是保证权重和为1
第三步:迭代完成后,组合弱分类器
f
(
x
)
=
∑
m
=
1
N
a
m
G
m
(
x
)
然后,加个
s
i
g
n
函数,该函数用于求数值的正负。得到最终的强分类器
G
(
x
)
G
(
x
)
=
s
i
g
n
(
f
(
x
)
)
f(x)=\sum\limits_{m=1}^Na_{m}G_m(x) \\ 然后,加个sign函数,该函数用于求数值的正负。得到最终的强分类器G(x)\\ G_{(x)} = sign(f(x))
f(x)=m=1∑NamGm(x)然后,加个sign函数,该函数用于求数值的正负。得到最终的强分类器G(x)G(x)=sign(f(x))
迭代终止条件:
(1)如果当前决策器的训练效果不佳,例如em过大
(2)如果当前Adboost的效果已经很好
(3)达到最大决策器个数
1.2 实际案例解释Adaboost算法流程
给定如下表所示训练数据。假设个体学习器由x(输入)和y(输出)产生,其阈值v(判定正反例的分界线)使该分类器在训练数据集上分类误差率最低。(y=1为正例,y=-1为反例)
| x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| y | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
1.2.1 第一个个体学习器
我们首先认为xi(i=1,2,…,10)的权重是一样的,即每一个数据同等重要。(权重是用来计算误差的)

(
a
)
:在权值分布为
D
1
的训练数据上,阈值
v
取
2.5
(红线)时分类误差率最低。
此时
x
=
6
,
7
,
8
的数据被错分为反例,误差为它们的权重之和
e
1
=
0.1
+
0.1
+
0.1
=
0.3
,误差率小于
0.5
才有意义。
此时,个体学习器为
:
G
1
(
x
)
=
{
1
,
x<2.5
−
1
,
x>2.5
(
b
)
:
根据误差
e
1
,利用公式:
a
i
=
1
2
ln
1
−
e
i
e
i
,计算系数
a
1
=
0.4236
。
可以发现只有当
e
i
<
1
2
,此时的个体学习器才有意义。
(
c
)
:更新训练数据的权值分布。
公式
:
w
m
+
1
,
i
=
w
m
,
i
Z
m
e
−
a
m
y
i
G
m
(
x
i
)
,
i
=
1
,
2
,
.
.
.
,
N
Z
m
=
∑
i
=
1
N
w
m
,
i
e
−
a
m
y
i
G
m
(
x
i
)
,是保证权重和为
1
(a):在权值分布为D_1的训练数据上,阈值v取2.5(红线)时分类误差率最低。\\ 此时x=6,7,8的数据被错分为反例,误差为它们的权重之和e_1=0.1+0.1+0.1=0.3,误差率小于0.5才有意义。\\ 此时,个体学习器为: \\ G_1(x) = \begin{cases} 1, & \text{x<2.5}\\ -1,& \text{x>2.5} \end{cases} \\ (b):根据误差e_1,利用公式:a_i = \frac{1}{2}\ln\frac{1-e_i}{e_i},计算系数a_1=0.4236。\\ 可以发现只有当e_i<\frac{1}{2},此时的个体学习器才有意义。\\ (c):更新训练数据的权值分布。\\ 公式:w_{m+1,i} = \frac{w_{m,i}}{Z_m}e^{-a_my_iG_m(x_i)},i=1,2,...,N \\ Z_m=\sum\limits_{i=1}^Nw_{m,i}e^{-a_my_iG_m(x_i)},是保证权重和为1
(a):在权值分布为D1的训练数据上,阈值v取2.5(红线)时分类误差率最低。此时x=6,7,8的数据被错分为反例,误差为它们的权重之和e1=0.1+0.1+0.1=0.3,误差率小于0.5才有意义。此时,个体学习器为:G1(x)={1,−1,x<2.5x>2.5(b):根据误差e1,利用公式:ai=21lnei1−ei,计算系数a1=0.4236。可以发现只有当ei<21,此时的个体学习器才有意义。(c):更新训练数据的权值分布。公式:wm+1,i=Zmwm,ie−amyiGm(xi),i=1,2,...,NZm=i=1∑Nwm,ie−amyiGm(xi),是保证权重和为1
我们用python来计算更新后的权重:
import numpy as np
# 定义计算系数a值公式
def get_a(e):
a = 0.5 * np.log((1-e) / e)
return a
# 定义个体学习器,预测y值,其中x为样本数据,v为阈值
def G(x,v):
y = []
for i in x:
if i < v:
y.append(1)
else:
y.append(-1)
return y
# 训练数据
x = [i for i in range(0,10)]
y = [1, 1, 1, -1, -1, -1, 1, 1, 1, -1]
# 原始的权重为
w = [0.1,0.1,0.1,0.1,0.1, 0.1,0.1,0.1,0.1,0.1]
def update_w(w,a,y,y_pred):
w_u = []
for w_index,w_value in enumerate(w):
r = w_value * np.exp(-a * y[w_index] * y_pred[w_index])
w_u.append(r)
return w_u / np.sum(w_u)
# 误差权重和
e1 = 0.1 + 0.1 + 0.1
# 系数a
a = get_a(e1)
# 阈值v
v = 2.5
# 预测的y值
y_pred = G(x,v)
# 更新权重
w = update_w(w,a,y,y_pred)
w.reshape(-1,10)

可以看到x=6,7,8的数据的权重变大了,而其他数据的权重降低了,这是希望能把之前经常分类错误(经常分类错误,权重会不断变大)的数据能在下一个个体学习器分类正确(记住:权重是用来计算误差的,为了降低误差,选择阈值时会倾向把权重大的分类正确)。

此时,
f
1
(
x
)
=
a
1
G
1
(
x
)
=
0.4236
G
1
(
x
)
=
{
0.4236
∗
1
,
x<2.5
0.426
∗
(
−
1
)
,
x>2.5
集成学习器
(
第一次集成
)
s
i
g
n
[
f
1
(
x
)
]
=
{
1
,
x<2.5
−
1
,
x>2.5
此时,f_1(x) = a_1G_1(x) =0.4236G_1(x)= \begin{cases} 0.4236*1, & \text{x<2.5}\\ 0.426*(-1),& \text{x>2.5} \end{cases}\\ 集成学习器(第一次集成)sign[f_1(x)] = \begin{cases} 1, & \text{x<2.5}\\ -1,& \text{x>2.5} \end{cases}
此时,f1(x)=a1G1(x)=0.4236G1(x)={0.4236∗1,0.426∗(−1),x<2.5x>2.5集成学习器(第一次集成)sign[f1(x)]={1,−1,x<2.5x>2.5
集成学习器(第一次集成,只有一个个体学习器)在训练数据集上有3个误分类点。
1.2.2 第二个个体学习器

(
a
)
:在权值分布为
D
2
的训练数据上,阈值
v
取
8.5
(红线)时分类误差率最低。
此时
x
=
3
,
4
,
5
的数据被错分为反例,误差为它们的权重之和
e
2
=
0.2143
,可以发现,误差率降低了。
此时,个体学习器为
:
G
2
(
x
)
=
{
1
,
x<8.5
−
1
,
x>8.5
(
b
)
:
根据误差
e
2
,计算系数
a
2
=
0.6496
。
(
c
)
:更新训练数据的权值分布。
(a):在权值分布为D_2的训练数据上,阈值v取8.5(红线)时分类误差率最低。\\ 此时x=3,4,5的数据被错分为反例,误差为它们的权重之和e_2=0.2143,可以发现,误差率降低了。\\ 此时,个体学习器为: \\ G_2(x) = \begin{cases} 1, & \text{x<8.5}\\ -1,& \text{x>8.5} \end{cases} \\ (b):根据误差e_2,计算系数a_2=0.6496。\\ (c):更新训练数据的权值分布。
(a):在权值分布为D2的训练数据上,阈值v取8.5(红线)时分类误差率最低。此时x=3,4,5的数据被错分为反例,误差为它们的权重之和e2=0.2143,可以发现,误差率降低了。此时,个体学习器为:G2(x)={1,−1,x<8.5x>8.5(b):根据误差e2,计算系数a2=0.6496。(c):更新训练数据的权值分布。
我们继续用python来计算更新后的权重:
# 误差权重和
e2 = 0.2143
# 系数a
a2 = get_a(e2)
# 阈值v
v = 8.5
y_pred = G(x,v)
# 更新权重
w = update_w(w,a2,y,y_pred)
w.reshape(-1,10)

对比权重D2可以看到x=3,4,5的数据的权重变大了,而其他权重降低了。


1.2.3 第三个个体学习器

( a ) :在权值分布为 D 3 的训练数据上,阈值 v 取 5.5 (红线)时分类误差率最低。 此时 x = 0 , 1 , 2 , 9 的数据被错分为反例,误差为它们的权重之和 e 3 = 0.1820 ,可以发现,误差率又降低了。 此时,个体学习器为 : G 3 ( x ) = { 1 , x<5.5 − 1 , x>5.5 ( b ) : 根据误差 e 3 ,计算系数 a 3 = 0.7514 。 ( c ) :更新训练数据的权值分布。 (a):在权值分布为D_3的训练数据上,阈值v取5.5(红线)时分类误差率最低。\\ 此时x=0,1,2,9的数据被错分为反例,误差为它们的权重之和e_3=0.1820,可以发现,误差率又降低了。\\ 此时,个体学习器为: \\ G_3(x) = \begin{cases} 1, & \text{x<5.5}\\ -1,& \text{x>5.5} \end{cases} \\ (b):根据误差e_3,计算系数a_3=0.7514。\\ (c):更新训练数据的权值分布。 (a):在权值分布为D3的训练数据上,阈值v取5.5(红线)时分类误差率最低。此时x=0,1,2,9的数据被错分为反例,误差为它们的权重之和e3=0.1820,可以发现,误差率又降低了。此时,个体学习器为:G3(x)={1,−1,x<5.5x>5.5(b):根据误差e3,计算系数a3=0.7514。(c):更新训练数据的权值分布。
# 误差权重和
e3 = 0.1820
# 系数a
a3 = get_a(e3)
# 阈值v
v = 5.5
y_pred = G(x,v)
print(a3)
# 更新权重
w = update_w(w,a3,y,y_pred)
w.reshape(-1,10)

此时,我们集成学习器表达式:


我们发现此时的集成学习器,在训练数据集上有0个误分类点。
总结如下
对比三个个体学习器我们可以发现,权值很低的数据从侧面说明,它们在前面的学习器经常被分类正确,也就是说它们被分类正确的票数就比较多(α相当于每个分类器的票数),那么之后的个体学习器把它们分类错也没所谓,反正总票数是分类正确的票数多就可以了。
-
例如x=1,前面两次分类对了,获得正确票数0.4236+0.6496=1.0732,第三次错了,获得错误票数0.7514,正确票数多,最终还是分类正确了。为了想办法让分类错误的数据变为分类正确的,后面的个体学习器也在努力。
-
如x=6,第一次分类错误的票数为0.4236,第二次分类正确的票数0.6496,可以看到为了让前面分类错误的数据变为分类正确的,后面个体学习器的重要性(α)需要比前面的大。
1.3 Adaboost算法原理
1.3.1 加法模型
预测函数

类比Adaboost的预测函数,可以知道Adaboost是一个加法模型。
损失函数
回归问题:MSE均方误差
分类问题:指数函数、交叉熵损失
优化方法

使用【前向分布算法】进行优化。
1.3.2 算法原理
1、优化问题:二分类问题
二分类的标签为{-1,1}。注:一定是{-1,1},不能是{0,1}
2、模型:加法模型
f
(
x
)
=
∑
m
=
1
M
a
m
G
m
(
x
)
f(x)=\sum\limits_{m=1}^Ma_{m}G_m(x) \\
f(x)=m=1∑MamGm(x)
3、最终分类器
G
(
x
)
=
s
i
g
n
[
f
(
x
)
]
G(x)=sign[f(x)]
G(x)=sign[f(x)]
4、损失函数:指数损失函数
L
(
y
,
f
(
x
)
)
=
e
[
−
y
f
(
x
)
]
当
G
(
x
)
分类正确时候,与
y
同号,
L
(
y
,
f
(
x
)
)
<
=
1
,
即损失是一个比较小的数
当
G
(
x
)
分类错误时候,与
y
异号,
L
(
y
,
f
(
x
)
)
>
1
,即损失是一个比较大的数
将损失函数视为训练数据的【权值】
w
m
i
=
e
[
−
y
i
f
m
−
1
(
x
i
)
]
L(y,f(x)) = e^{[-yf(x)]} \\ 当G(x)分类正确时候,与y同号,L(y,f(x))<=1 ,即损失是一个比较小的数\\ 当G(x)分类错误时候,与y异号,L(y,f(x))>1,即损失是一个比较大的数 \\ 将损失函数视为训练数据的【权值】\\ w_{mi}=e^{[-y_if_{m-1}(x_i)]}
L(y,f(x))=e[−yf(x)]当G(x)分类正确时候,与y同号,L(y,f(x))<=1,即损失是一个比较小的数当G(x)分类错误时候,与y异号,L(y,f(x))>1,即损失是一个比较大的数将损失函数视为训练数据的【权值】wmi=e[−yifm−1(xi)]

5、优化算法:前向分布算法

极小化损失函数的公式准换

准换公式推导如下

求解转换后的公式
1、优化Gm(x)

2、优化am
a
m
=
1
2
ln
1
−
e
m
e
m
a_m = \frac{1}{2}\ln\frac{1-e_m}{e_m}
am=21lnem1−em
公式推导:
首先,将准换后的最小化损失函数的公式,再次进行准换

上式中,只有am为变量,对于此凸优化问题,可以对am求导

令求导后的公式为0

然后,对于分子分母,再除以所有样本的权值之和,进行化简,可以得到公式
a
m
=
1
2
ln
1
−
e
m
e
m
a_m = \frac{1}{2}\ln\frac{1-e_m}{e_m}
am=21lnem1−em
3、前向更新fm(x)
f
m
(
x
)
=
f
m
−
1
(
x
)
+
a
m
G
m
(
x
)
f_m(x)=f_{m-1}(x) + a_mG_m(x)
fm(x)=fm−1(x)+amGm(x)
4、更新训练数据权值
公式
:
w
m
+
1
,
i
=
w
m
,
i
Z
m
e
−
a
m
y
i
G
m
(
x
i
)
,
i
=
1
,
2
,
.
.
.
,
N
Z
m
=
∑
i
=
1
N
w
m
,
i
e
−
a
m
y
i
G
m
(
x
i
)
,是保证权重和为
1
公式:w_{m+1,i} = \frac{w_{m,i}}{Z_m}e^{-a_my_iG_m(x_i)},i=1,2,...,N \\ Z_m=\sum\limits_{i=1}^Nw_{m,i}e^{-a_my_iG_m(x_i)},是保证权重和为1
公式:wm+1,i=Zmwm,ie−amyiGm(xi),i=1,2,...,NZm=i=1∑Nwm,ie−amyiGm(xi),是保证权重和为1
公式推导如下(未归一化)

本篇笔记主要参考如下:
李航老师的<学习统计方法>
https://blog.csdn.net/fuqiuai/article/details/79482487
http://ml.bbbdata.com/site/text/100