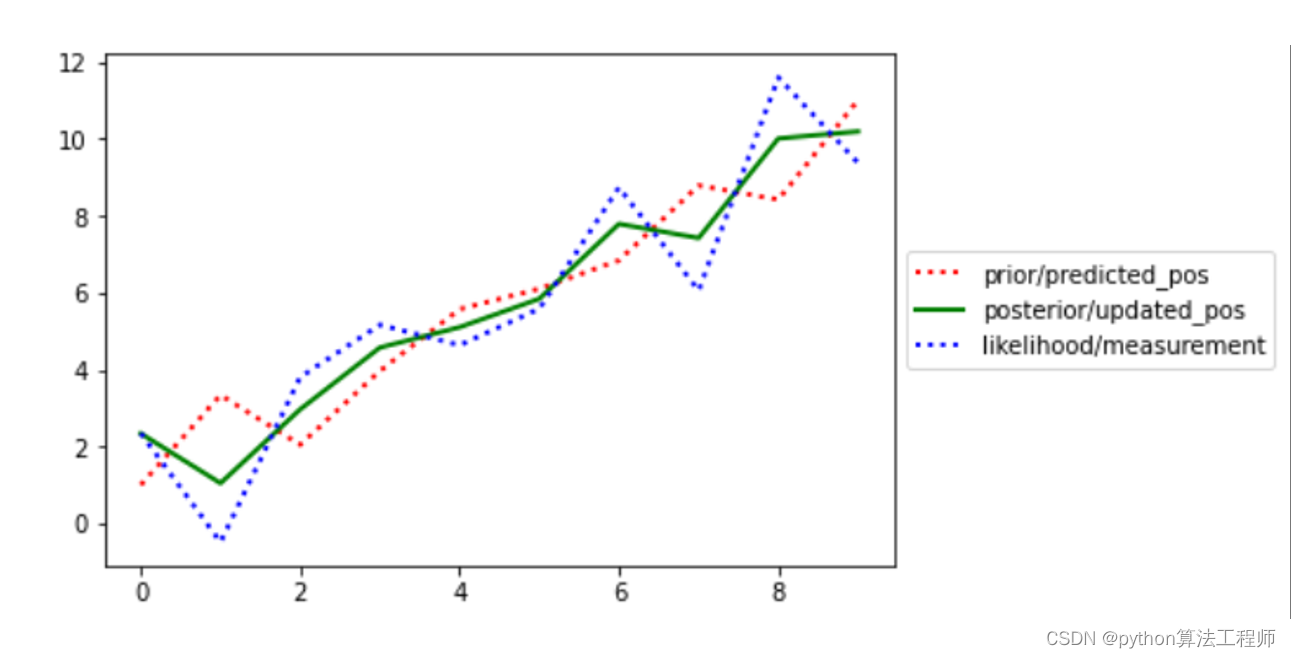
模型训练
下载数据集,解压到项目目录下的./ml-1m文件夹下。数据集分用户数据users.dat、电影数据movies.dat和评分数据ratings.dat。
**
数据集分析
**
user.dat:分别有用户ID、性别、年龄、职业ID和邮编等字段。
数据集网站地址为http://files.grouplens.org/datasets/movielens/ml-1m-README.txt对数据的描述:
使用UserID、Gender、Age、Occupation、Zip-code分别表示用户ID、性别、年龄、职业和邮政编码,M表示男性,F表示女性。年龄范围表示:

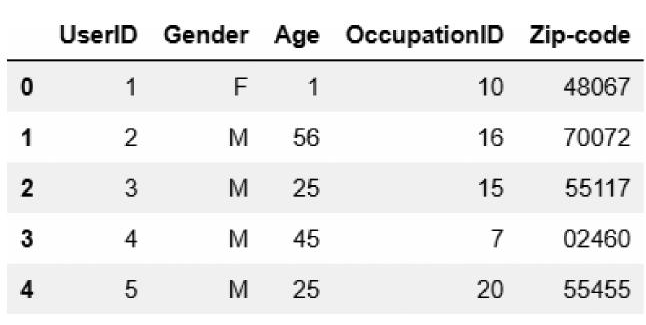
UserID、Gender、Age和Occupation都是类别字段,其中邮编字段不使用。rating.dat数据分别有用户ID、电影ID、评分和时间戳等字段。数据集网站的描述:UserID范围为16040;MovieID范围为13952;Rating表示评分,最高5星;Timestamp为时间戳,每个用户至少20个评分。查看ratings.dat的前5个数据,结果如图4-7所示,相关代码如下:
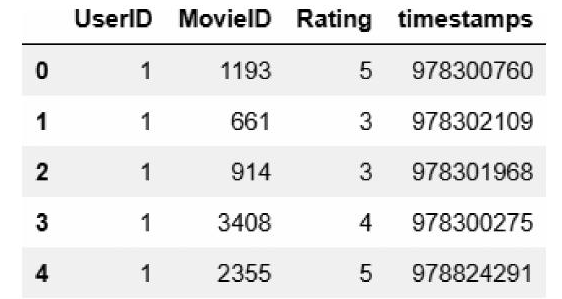
评分字段Rating是监督学习的目标,时间戳字段不使用。movies.dat数据集分别有电影ID、电影名和电影风格等字段。数据集网站的描述:
使用MovieID、Title和Genres,其中MovieID和Genres是类别字段,Title是文本。Title与IMDB提供的标题相同(包括发行年份),Genres是管道分隔,并且选自以下流派:
数据预处理
通过研究数据集中的字段类型,发现有一些是类别字段,将其转成独热编码,但是UserID、MovieID的字段会变稀疏,输入数据的维度急剧膨胀,所以在预处理数据时将这些字段转成数字。操作如下:
UserID、Occupation和MovieID不变。
Gender字段:需要将F和M转换成0和1。
Age字段:转成7个连续数字0~6。
Genres字段:是分类字段,要转成数字。将Genres中的类别转成字符串到数字的字典,由于部分电影是多个Genres的组合,将每个电影的Genres字段转成数字列表。
Title字段:处理方式与Genres一样,首先,创建文本到数字的字典;其次,将Title中的描述转成数字列表,删除Title中的年份。
统一Genres和Title字段长度,这样在神经网络中方便处理。空白部分用PAD对应的数字填充。实现数据预处理相关代码如下: