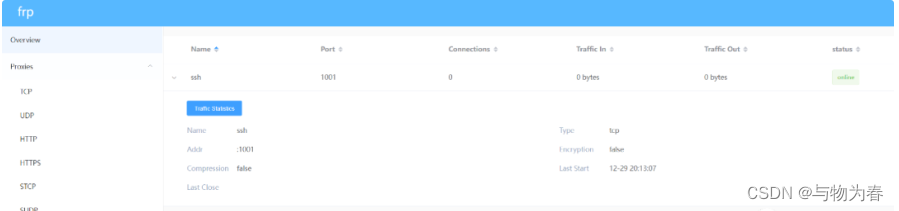
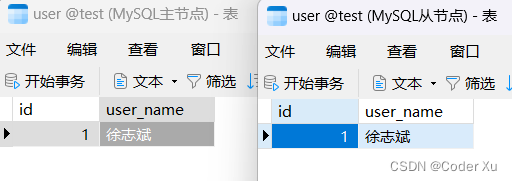
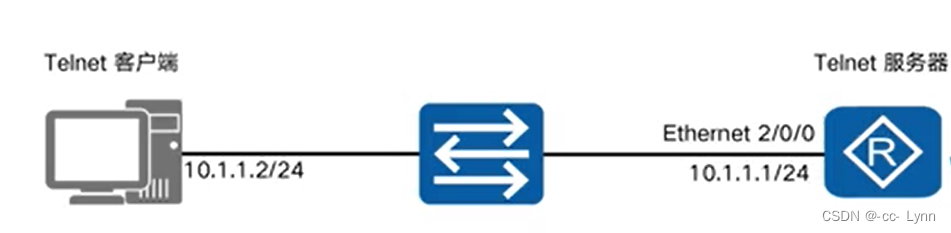
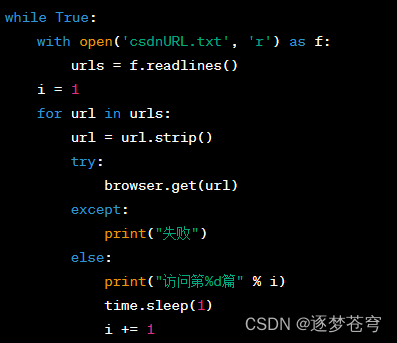
模型创建
title _ count, title _ set, genres2int, features, targets _ values, ratings, users, movies, data, movies _ orig, users _ orig = pickle.load (open (‘preprocess.p’, mode = ‘rb’))
加载数据后定义神经网络的模型结构:
1)定义参数
相关代码如下:


3)定义用户嵌入矩阵
在预处理数据时将UserID、MovieID的字段转成数字,当作嵌入矩阵的索引,在网络的第一层使用嵌入层,维度是(N,32)和(N,16),其中N是电影总数。定义用户嵌入矩阵的相关代码如下:
4)定义电影嵌入矩阵
相关代码如下:
5)定义电影类型嵌入矩阵
有时一个电影有多个类型,从嵌入矩阵索引出来是一个(n,32)的矩阵,这里的n是指某部电影所包含的类型。因为有多个类型,所以要将这个矩阵求和,变成(1,32)的向量。相关代码如下:
电影名的处理比较特殊,未使用循环神经网络,而是用了文本卷积网络。网络的第一层是词嵌入层,由每个单词的嵌入向量组成矩阵。第二层使用多个不同尺寸(窗口大小)的卷积核在嵌入矩阵上做卷积,窗口大小指的是每次卷积覆盖几个单词。这里与图像做卷积不同,图像卷积通常用2×2、3×3、5×5的尺寸,而文本卷积要覆盖整个单词的嵌入向量,尺寸是单词数、向量维度,例如,每次滑动3、4或5个单词。第三层网络是最大池化得到一个长向量,第四层使用丢弃做正则化,得到电影Title的特征。相关代码如下:
7)全连接层
从嵌入层索引出特征后,传入全连接层,将输出再次传入全连接层,模型结构如图4-11所示,最终分别得到(1,200)的用户和电影两个特征向量。

8)定义计算图
目的是训练出用户特征和电影特征,在实现推荐功能时使用。得到这两个特征以后,可以选择任意的方式来拟合评分。对用户特征和电影特征两个(1,200)向量做乘法,将结果与真实评分做回归,采用MSE优化损失。相关代码如下:
.模型训练
定义超参数的代码如下:其中,一个batch就是在一次前向/后向传播过程用到的训练样例数量,训练5轮,每轮第一个batch_size为3125,作为训练集,训练步长为20,第二个batch_size为781,作为测试集,训练步长为20,训练集训练结果如图4-12所示,测试集训练结果如图4-13所示。
通过观察训练集和测试集损失函数的大小来评估模型的训练程度,进行模型训练的进一步决策。一般来说,训练集和测试集的损失函数不变且基本相等为模型训练的较佳状态。可以将训练过程中保存的损失函数以图片的形式表现出来,方便观察,相关代码如下:
获取特征矩阵
本部分包括定义函数张量、生成电影特征矩阵、生成用户特征矩阵。
1)定义函数用于获取保存的张量
相关代码如下: