Softmax
与sigmoid不同,softmax可以多个输出,每个输出以概率的形式表示。
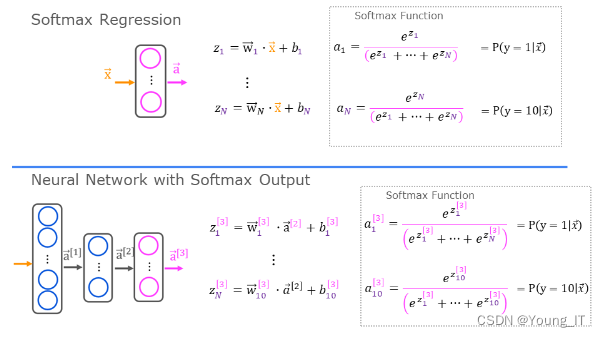

或者
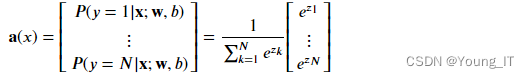
def my_softmax(z):
ez = np.exp(z)
sm = ez/np.sum(ez)
return(sm)1 损失函数Loss
Softmax 相关的损失函数,即交叉熵损失:
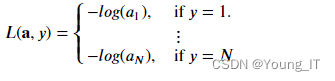
2 成本函数Cost
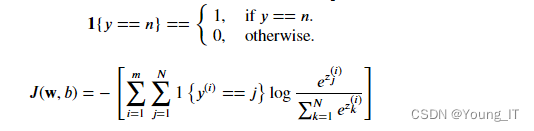
𝑚是例子的数量,𝑁是输出的数量。这是所有损失的平均值。
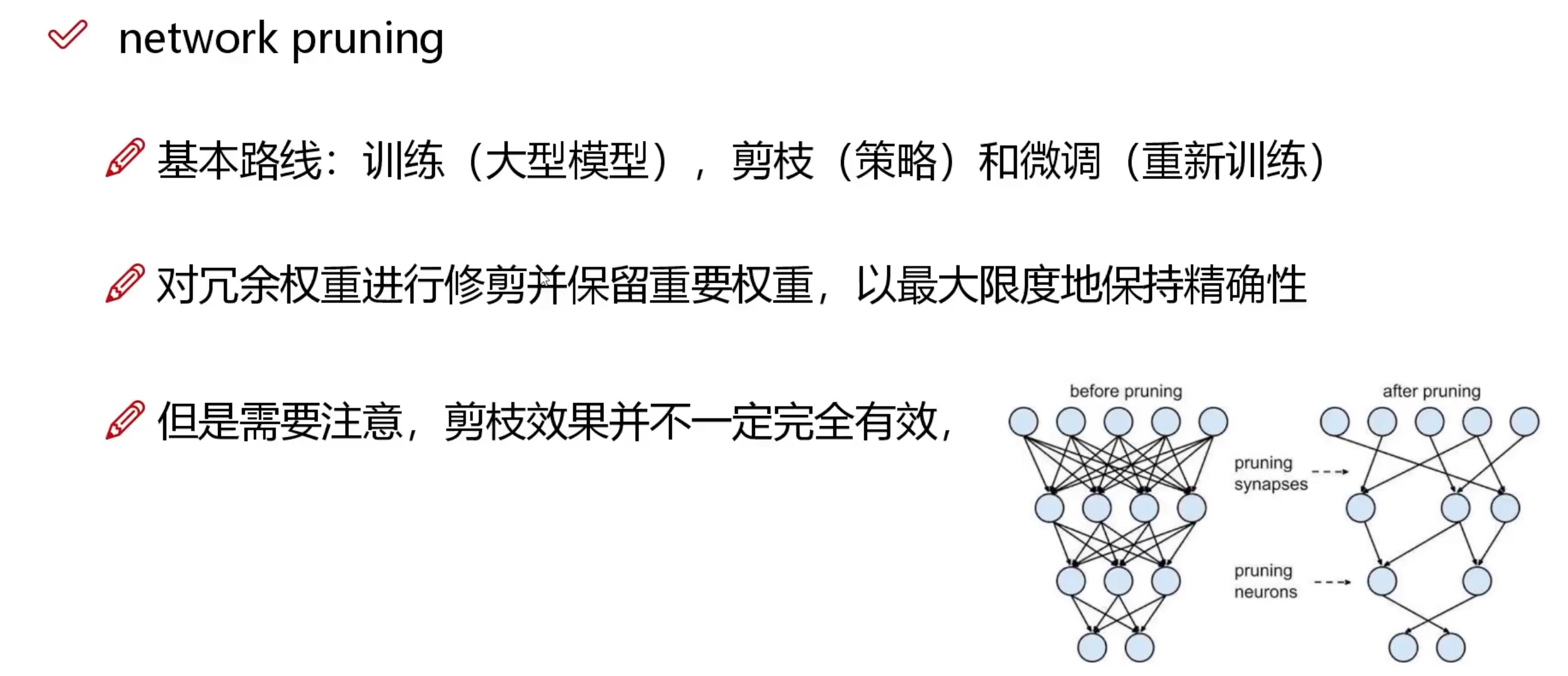
3 Tensorflow实现
model = Sequential(
[
Dense(25, activation = 'relu'),
Dense(15, activation = 'relu'),
Dense(4, activation = 'softmax')
]
)
model.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(), # 损失函数设置
optimizer=tf.keras.optimizers.Adam(0.001),
)
model.fit(
X_train,y_train,
epochs=10
)Preferred
训练过程中将 softmax 和 loss 结合起来,可以获得更稳定和准确的结果。
(简单说就是将softmax整合进loss计算中,并在神经网络最后一层的softmax层变成线性激活层)

preferred_model = Sequential(
[
Dense(25, activation = 'relu'),
Dense(15, activation = 'relu'),
Dense(4, activation = 'linear') # 注意 线性
]
)
preferred_model.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), # 注意!
optimizer=tf.keras.optimizers.Adam(0.001),
)
preferred_model.fit(
X_train,y_train,
epochs=10
)输出示例:
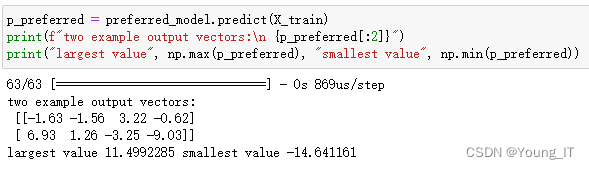
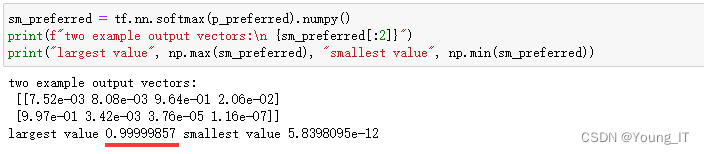
注意:输出预测不是概率!如果所需的输出是概率,则输出应由 softmax处理!
使用softmax处理成概率: tf.nn.softmax(p_preferred).numpy()
SparseCategorialCrossentropy 和 CategoricalCrossEntropy
Tensorflow 有两种可能的目标值格式,损失的选择定义了预期的格式。
- SparseCategorialCrossentropy:期望目标是与索引对应的整数。例如,如果有 10 个潜在目标值,则 y 将介于 0 和 9 之间。
- CategoricalCrossEntropy:期望示例的目标值是单热编码的,其中目标索引处的值为 1,而其他 N-1 个条目为零。一个具有 10 个潜在目标值的示例,其中目标值为 2 将是 [0,0,1,0,0,0,0,0,0,0]。









![[数据结构] 二叉搜索树的详解实现](https://img-blog.csdnimg.cn/c40e1c541f7a49bb9872c56bdc029fb2.png#pic_center)