文章目录
- 1.定义以及相关知识
- 1.1定义
- 1.2数据库保存数据的基本单位
- 2.MySQL中索引分类
- 2.1B树和B+树
- 2.2主键索引(聚簇索引)
- 2.3非聚簇索引
- 2.4覆盖索引
- 2.5复合索引(联合索引)
- 2.6基于B+树的索引
- 2.7hash索引
1.定义以及相关知识
1.1定义
使用一定的数据结构来保存索引字段对应的数据,以后根据索引字段来进行检索提高检索效率
注意:使用一定的数据结构需要一定的空间来保存,索引字段可以是一列或多列;是否能够命中索引是SQL性能优化的关键
(1)建立索引:类似建立书籍目录或手机的电话簿
(2)使用索引:查询条件中的字段能够命中索引
(3)创建索引、更新/删除索引字段、插入数据都会导致索引更新的耗时操作
1.2数据库保存数据的基本单位
(1)数据库保存数据的基本单位是page
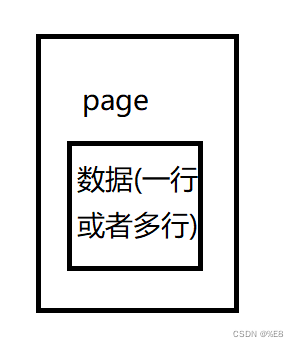
(2)目的:硬盘读取文件到内存的io操作也是耗时的,读取数据最好也就保证能最少次读取到需要的结果集
2.MySQL中索引分类
创建某个索引可以是以下多种类型
(1)从索引存储结构划分:B+树索引,hash索引
(2)从应用层次划分:普通索引、唯一索引、主键索引、复合索引
(3)从索引键值类型划分:主键索引、辅助索引(二级索引)
(4)从数据存储和索引键值逻辑关系划分:聚集索引(聚簇索引)、非聚集索引(非聚簇索引)
(5)从索引列数量划分:单列索引、复合索引
2.1B树和B+树
(1)B树:所有节点都保存有索引列及数据
(2)B+树:每个节点都是page,叶子结点保存有索引列及数据,非叶子结点只有索引字段,B+树叶子结点全部相连
(3)区别:
①数据的保存位置不同:B+树保存在叶子节点,B树保存在所有的节点中(体现出B+树优势:节点不存储data,这样一个节点就可以存储更多的key,可以使得树更矮,所以IO操作次数更少;查询性能稳定:每次查询都是从根节点遍历到叶子节点,查询路径长度相同,即每次查询效率相当,时间复杂度固定是O(log(n))
②叶子节点的指向不同:B+树相邻的叶子节点通过指针相连,B树没有(体现出B+树优势:所有叶子节点形成有序链表,便于范围查找)
2.2主键索引(聚簇索引)
(1)默认是B+树,聚簇索引,一张表只能有一个主键索引
(2)在B+树的叶子结点上存放有主键字段(索引字段)+整行数据
(3)优点:速度快
(4)缺点:主键需要是整形且字段不要太长,更新代价大,效率低
2.3非聚簇索引
(1)非主键索引,可以使用很多类型的索引,如B+树、hash等等
(2)如果使用的是B+树存储结构,叶子结点上存放索引字段的值+主键的值
(3)搜索数据的方式:先通过索引字段找到叶子结点上的主键值,再通过主键值找到整条数据(属于回表操作)
(4)优点:更新代价相对比聚簇索引小(叶子结点是索引值和主键值,没有真实数据)
(5)缺点:依赖有序数据,可能产生回表操作导致效率更低
2.4覆盖索引
(1)覆盖索引是一个索引包含所需要查询的字段的值
(2)使用:select 覆盖索引字段 from 表 where 覆盖索引字段 = “”;
(3)注意:is null / is not null是不会走索引的
(4)优点:不需要回表操作
2.5复合索引(联合索引)
(1)使用多列来创建索引
(2)符合最左匹配原则:联合索引的多个字段遵循从左往右的优先级,最左优先,当出现范围查询是停止匹配
(3)查询的条件字段顺序是无所谓的,关键是索引创建的字段顺序(查询是必须包含创建索引的第一个字段否则不匹配)
2.6基于B+树的索引
(1)主键索引(聚簇索引)
(2)非聚簇索引(可以建立成B+树的索引)
(3)优化原则:索引字段尽量不要有null的值
修正(查询的时候,条件是字段is [not] null, !=会走全表扫描,不会走引);频繁查询的字段建立索引:需要考虑最左匹配原则,顺序是左边;频繁更新的字段,慎用索引(索引更新代价大)=>适用读多写操的场景;范围查询(between, <, <, like等)可能走索引,也可能不走(MySQL中,存在一个查询优化器,用于判断如何执行:多个索引存在时,先找到最优的一个索引,判断是不是走这个索引更快,如果是,走索引;如果不是,全表扫描)
2.7hash索引
(1)HashMap
(2)存储数据的特性:键值对,无序且键唯一
(3)底层数据结构:数组+链表+红黑树
(4)原理:存取元素,复杂的是存(put)流程
①算数组位置,往上边放(根据key的hashcode值,基于内部hash函数计算出数组索引);②如果该位置没有元素,往这个地方放;③如果有元素,往链表上放,看是否存在节点equals(key),如果存在就替换;如果不存在尾插;④如果放进去了东西,可能需要扩容
(5)hash索引的特点:不支持顺序和范围查询