一、概述
title:Doc2Bot: Accessing Heterogeneous Documents via Conversational Bots
论文地址:Doc2Bot: Accessing Heterogeneous Documents via Conversational Bots - ACL Anthology
数据地址(大概5千多轮开源数据):GitHub - Doc2Bot/Doc2Bot
modescope地址:ModelScope 魔搭社区
1.1 Motivation
- 有些公司以及组织有大量的手册以及说明书,基于这些文档对话完成信息查找非常有用。
- 文档有很多种结构(本文,表格等),目前大部分数据集主要是纯文本。
- 用户需求通常没有明确说明。
1.2 Methods
- 构建了5大领域,多种文档类型的数据集,超过10万轮对话数据。
- 提出了dst(对话状态跟踪)、dpl(对话策略学习)、dg(对话生成)三个任务来完成这个数据集。
- 提出了一种基于文档构件数据集的策略(引入图的结构,然后根据图的路径,由总包模拟生成对话数据)。
1.3 Conclusion
- 测试了机器处理各种类型的文档数据集的能力 + 澄清用户需求的能力。
- 该任务还是有挑战性的,特别在文档检索任务上指标还偏差,值得进一步研究。
1.4 limitation
- 构建文档的graph结构还需要大量人工参与,比较麻烦。
- 暂时还没包括无法回答的case。
- 由于隐私等其他原因,只开放了部分数据。
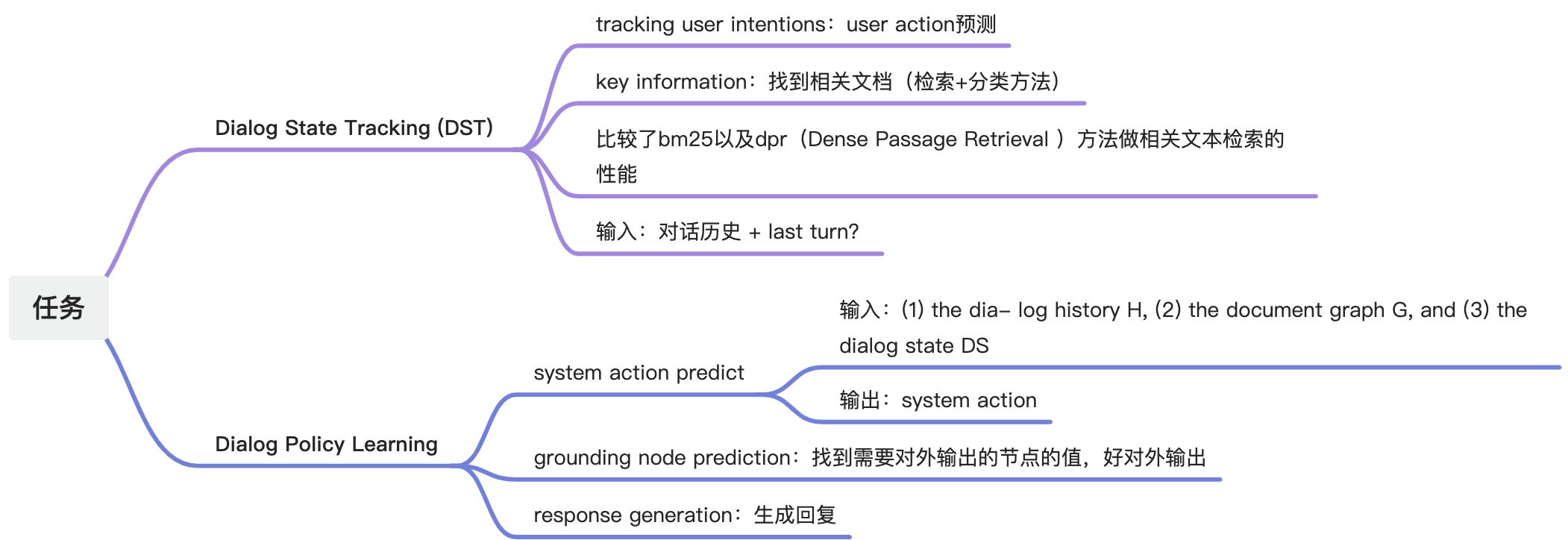
二、baseline任务说明
三、详细内容
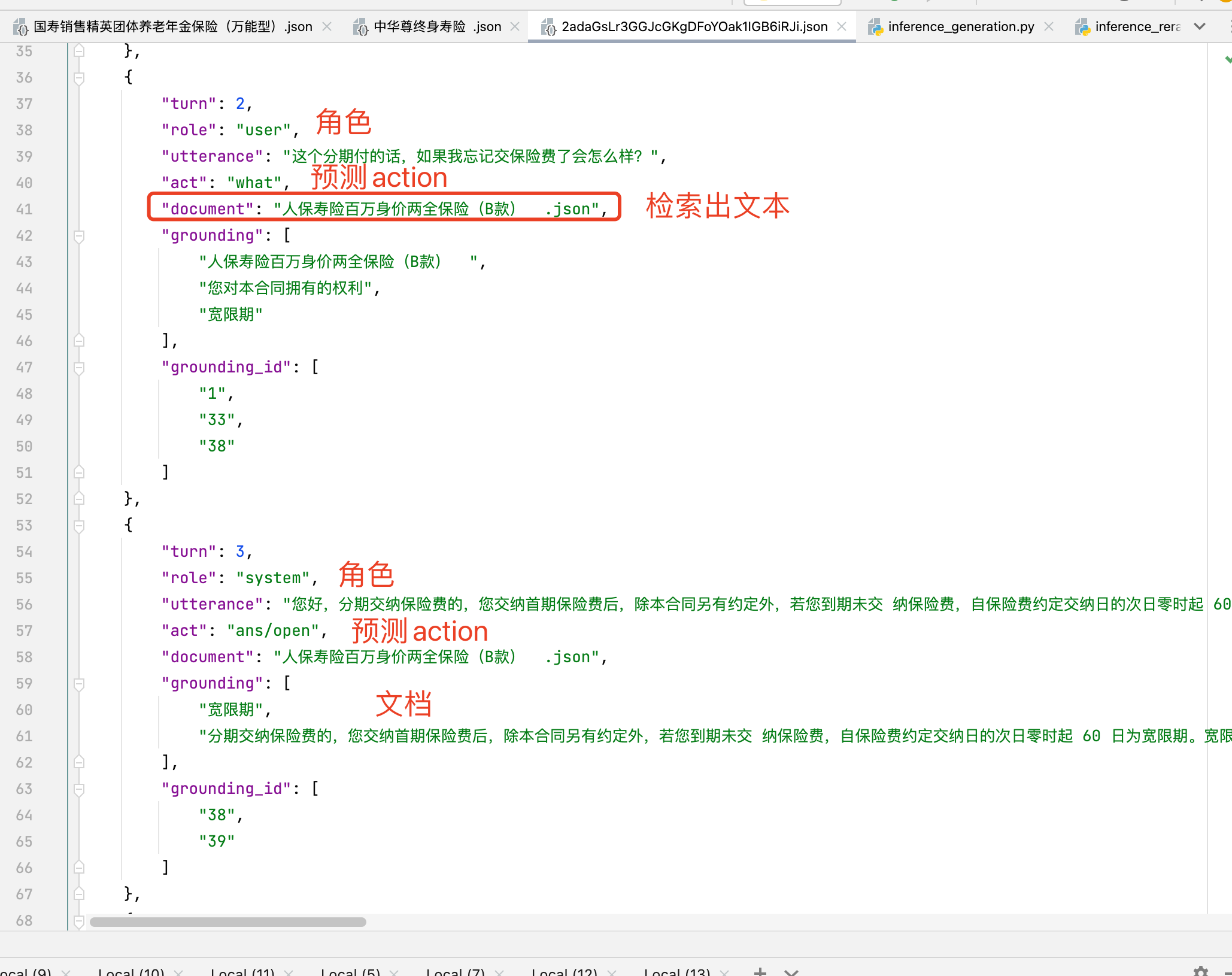
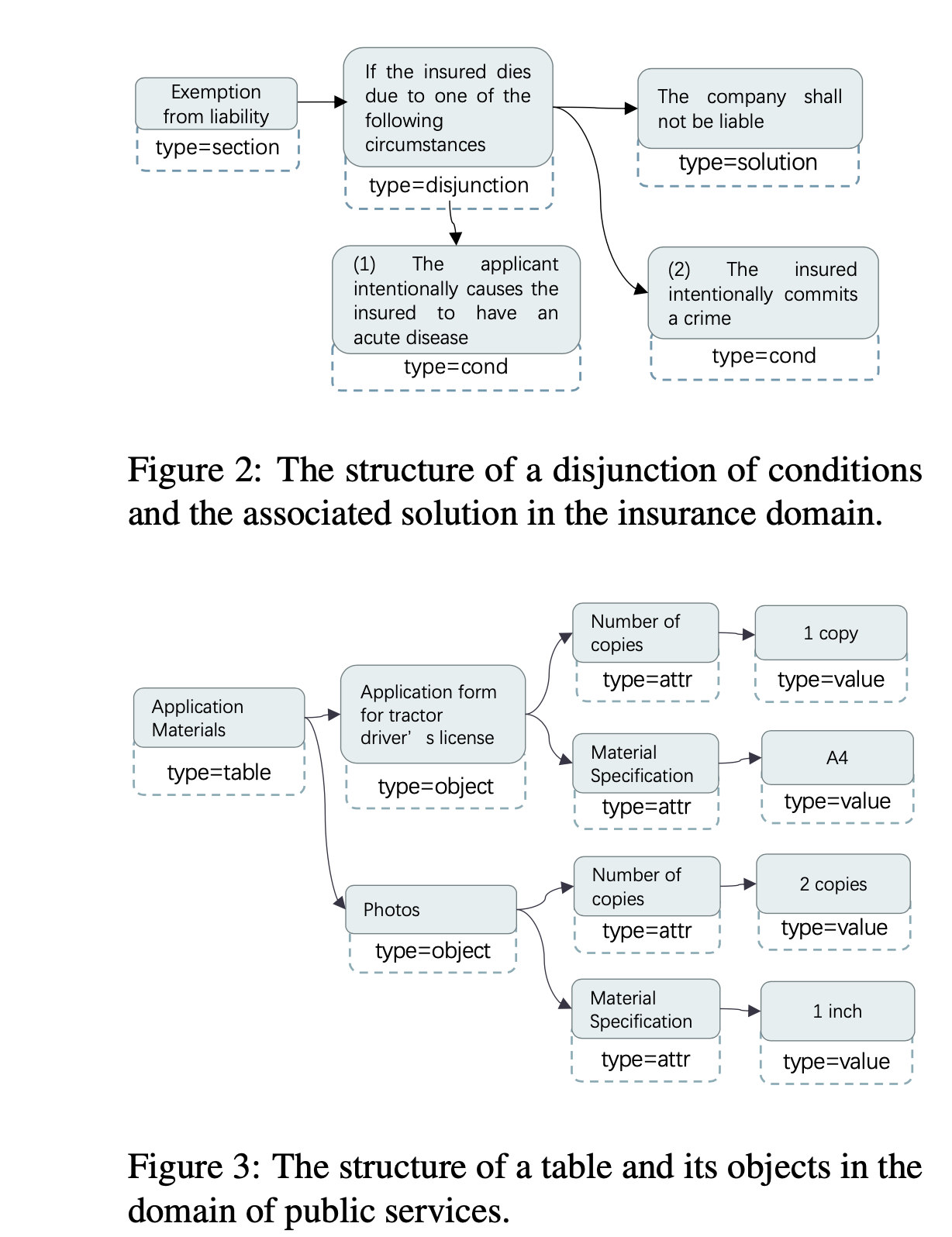
3.1 基于文档(文档有段落、表格等各种各样的形式)对话例子


3.2 基于文档构件graph(后续基于graph来生成对话)
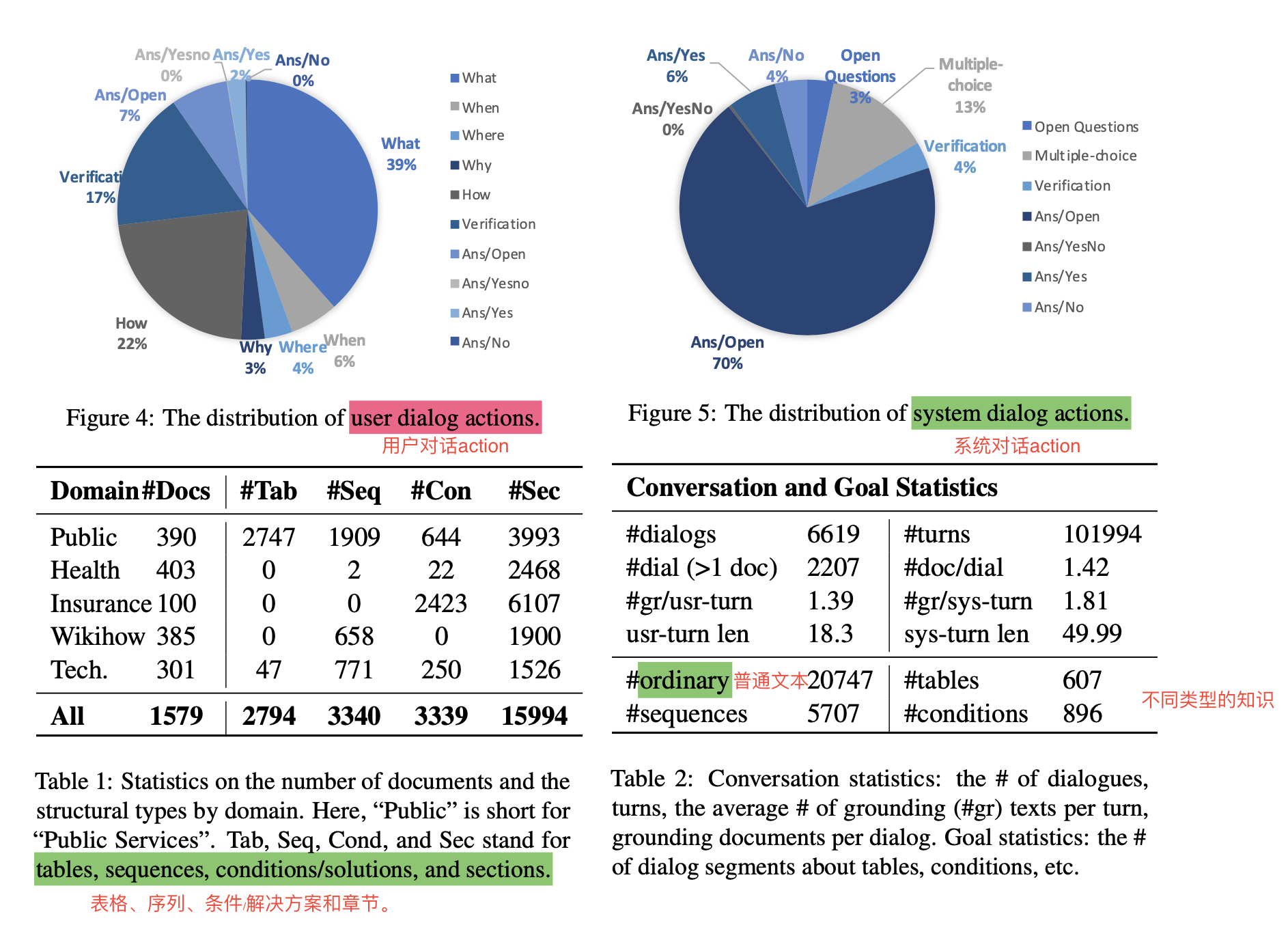
3.3 对话数据统计
- user action的比例 + system action比例
- 5大领域,以纯文本为主,但是还是包括其他类型的document
3.4 baseline实验
Dialog State Tracking
- user action预测(分类问题)
- grounding text prediction:找出文档依据的来源(检索 + 分类)

Dialog Policy Learning
- 系统action预测(分类问题) + 节点预测(分类问题)
- 回复生成(生成模型)

3.5 真实数据 举例