文章目录
Duplicate数据模型以及聚合模型的局限性
一、Duplicate数据模型
二、聚合模型的局限性
Duplicate数据模型以及聚合模型的局限性
一、Duplicate数据模型
在某些多维分析场景下,数据既没有主键,也没有聚合需求,只需要将数据原封不动的存入表中,数据有主键重复也都要存储。因此,我们引入 Duplicate 数据模型来满足这类需求。 Duplicate 数据模型只指定排序列,相同的行不会合并,适用于数据无需提前聚合的分析业务。举例说明,有如下表结构数据:

建表语句如下:
CREATE TABLE IF NOT EXISTS example_db.example_duplicate_tbl
(
`timestamp` DATETIME NOT NULL COMMENT "日志时间",
`type` INT NOT NULL COMMENT "日志类型",
`error_code` INT COMMENT "错误码",
`error_msg` VARCHAR(1024) COMMENT "错误详细信息",
`op_id` BIGINT COMMENT "负责人id",
`op_time` DATETIME COMMENT "处理时间"
)
DUPLICATE KEY(`timestamp`, `type`, `error_code`)
DISTRIBUTED BY HASH(`type`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
创建表成功后,向表中插入如下数据:
insert into example_db.example_duplicate_tbl values
("2023-03-01 08:00:00",1,200,"错误200",1001,"2023-03-01 09:00:00"),
("2023-03-02 08:00:00",2,201,"错误201",1002,"2023-03-02 09:00:00"),
("2023-03-03 08:00:00",3,202,"错误202",1003,"2023-03-03 09:00:00"),
("2023-03-04 08:00:00",4,203,"错误203",1004,"2023-03-04 09:00:00"),
("2023-03-04 08:00:00",4,203,"错误203",1004,"2023-03-04 09:00:00"),
("2023-03-04 08:00:00",4,203,"错误203",1005,"2023-03-05 10:00:00");
插入数据后,表example_db.example_duplicate_tbl结果如下:
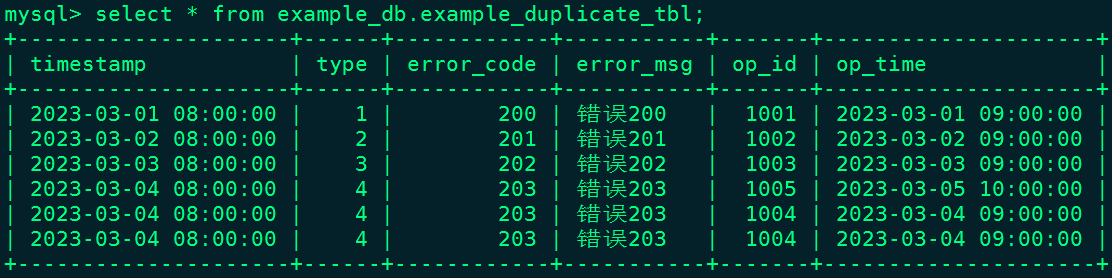
这种数据模型区别于 Aggregate 和 Unique 模型,数据完全按照导入文件/或插入的数据进行存储,不会有任何聚合。 即使两行数据完全相同,也都会保留。 而在建表语句中指定的 DUPLICATE KEY ,只是用来指明底层数据按照那些列进行排序,更贴切的名称应该为 "Sorted Column",这里取名 "DUPLICATE KEY" 只是用以明确表示所用的数据模型。关于 "Sorted Column"的更多解释,可以参考后面的前缀索引。
在 Aggregate、Unique 和 Duplicate 三种数据模型中。底层的数据存储,是按照各自建表语句中,AGGREGATE KEY、UNIQUE KEY 和 DUPLICATE KEY 中指定的列进行排序存储的。 在 DUPLICATE KEY 的选择上,我们建议适当的选择前 2-4 列就可以。
二、聚合模型的局限性
Aggregate数据模型和Unique数据模型是聚合模型,Duplicate数据模型不是聚合模型,聚合模型存在一些局限性,这里说的局限性主要体现在select count(*) from table 操作效率和语意正确性两方面,下面我们针对 Aggregate 模型,来介绍下聚合模型的局限性。
在聚合模型中,模型对外展现的,是最终聚合后的数据。也就是说,在Doris内部任何还未聚合的数据(比如说两个不同导入批次的数据),必须通过某种方式,以保证对外展示的一致性。我们举例说明。
假设表结构如下:
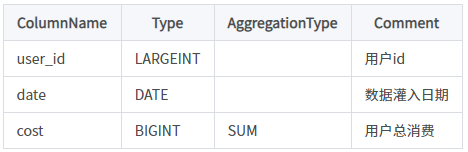
建表语句如下:
CREATE TABLE IF NOT EXISTS example_db.test
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期",
`cost` BIGINT SUM COMMENT "用户总消费"
)
AGGREGATE KEY(`user_id`, `date`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
向表中分别插入两批次数据,第一批次SQL如下:
insert into example_db.test values
(10001,"2017-11-20",50),
(10002,"2017-11-21",39);
第二批次SQL如下:
insert into example_db.test values
(10001,"2017-11-20",1),
(10001,"2017-11-21",5),
(10003,"2017-11-22",22);
可以看到"10001,2017-11-20"这条数据虽然分在了两个批次中,但是由于设置了Aggregate Key 所以是相同数据,进行了聚合。两批次数据插入后,test表中数据如下:
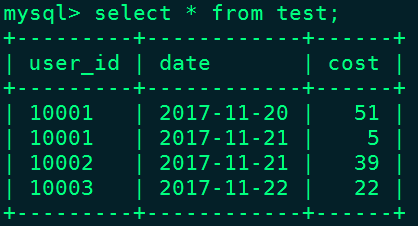
另外, 在聚合列( Value )上,执行与聚合类型不一致的聚合类查询时,要注意语意。 比如我们在如上示例中执行如下查询:
mysql> select min(cost) from test;
+-------------+
| min(`cost`) |
+-------------+
| 5 |
+-------------+
1 row in set (0.03 sec)
以上结果得到的是5,而不是1,归根结底就是底层数据进行了合并,是一致性保证的体现。这种一致性的保证,在某些查询中,会极大的降低查询效率。例如,在"select count(*) from table"这种操作中,这种一致性保证就会大幅降低查询效率,原因如下:
在其他数据库中,这类查询都会很快的返回结果,因为在实现上,我们可以通过如" 导入时对行进行计数,保存 count 的统计信息",或者在查询时" 仅扫描某一列数据,获得 count 值"的方式, 只需很小的开销,即可获得查询结果 。但是在 Doris 的聚合模型中,这种查询的开销非常大。
以上案例中,我们执行"select count(*) from test;"正确结果为4,为了得到正确的结果,我们必须同时读取 user_id 和 date 这两列的数据, 再加上查询时聚合 ,才能返回4 这个正确的结果。也就是说,在 count() 查询中,Doris 必须扫描所有的 AGGREGATE KEY 列(这里就是 user_id 和 date),并且聚合后,才能得到语意正确的结果,当聚合列非常多时,count() 查询需要扫描大量的数据,效率低下。
因此, 当业务上有频繁的 count(*) 查询时 ,我们建议用户 通过增加一个值恒为 1 的,聚合类型为 SUM 的列来模拟 count 。如刚才的例子中的表结构,我们修改如下:

增加一个 count 列,并且导入数据中,该列值恒为 1。则 select count(*) from table; 的结果等价于 select sum(count) from table;。而后者的查询效率将远高于前者。不过这种方式也有使用限制,就是用户需要自行保证,不会重复导入 AGGREGATE KEY 列都相同的行。否则,select sum(count) from table; 只能表述原始导入的行数,而不是 select count(*) from table; 的语义。
建表语句如下:
CREATE TABLE IF NOT EXISTS example_db.test1
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期",
`cost` BIGINT SUM COMMENT "用户总消费",
`count` BIGINT SUM COMMENT "用于计算count"
)
AGGREGATE KEY(`user_id`, `date`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
插入如下数据:
insert into test1 values
(10001,"2017-11-20",50,1),
(10002,"2017-11-21",39,1),
(10001,"2017-11-21",5,1),
(10003,"2017-11-22",22,1);
执行sql语句对比:
# select count(*) from test1; 等价 select sum(count) from test1(效率高);
mysql> select count(*) from test1;
+----------+
| count(*) |
+----------+
| 4 |
+----------+
1 row in set (0.04 sec)
mysql> select sum(*) from test1;
+----------+
| count(*) |
+----------+
| 4 |
+----------+
1 row in set (0.03 sec)
此外,聚合模型的局限性注意以下几点:
- Unique模型的写时合并没有聚合模型的局限性(效率低下局限),因为写时合并原理是写入数据时已经将数据合并并会对过时数据进行标记删除,在数据查询时不需进行任何数据聚合,在测试环境中,count(*) 查询在Unique模型的写时合并实现上的性能,相比聚合模型有10倍以上的提升。
- Duplicate 模型没有聚合模型的这个局限性。因为该模型不涉及聚合语意,在做 count(*) 查询时,任意选择一列查询,即可得到语意正确的结果。
- Duplicate、Aggregate、Unique 模型,都会在建表指定 key 列,然而实际上是有所区别的:对于 Duplicate 模型,表的key列,可以认为只是 "排序列",并非起到唯一标识的作用。而 Aggregate、Unique 模型这种聚合类型的表,key 列是兼顾 "排序列" 和 "唯一标识列",是真正意义上的" key 列"。
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨