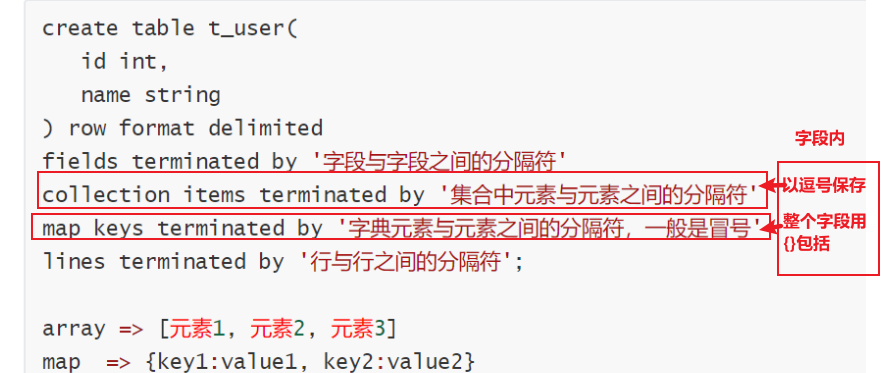
一、Hive的序列化和反序列化
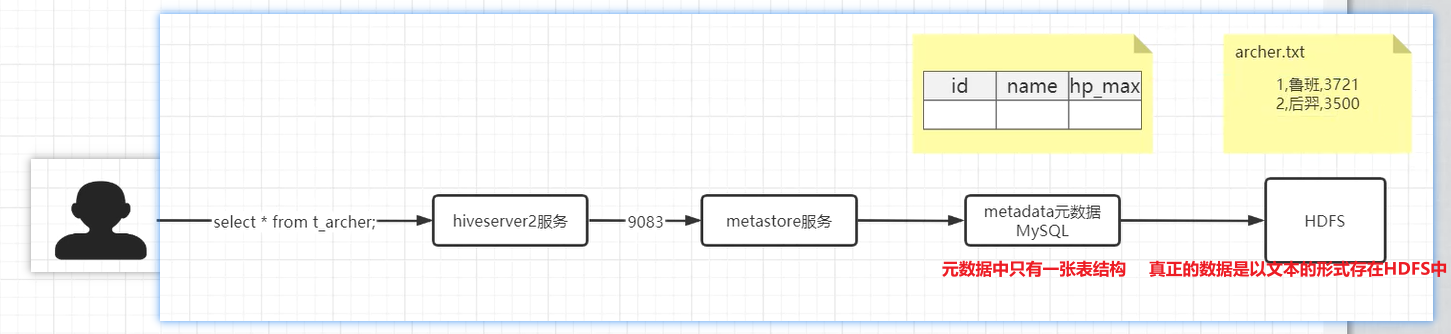
==Hive读取文件机制==:读取文件中的每一行 => 反序列化 => 通过分隔符进行切割,返回数据表中的每一行对象。
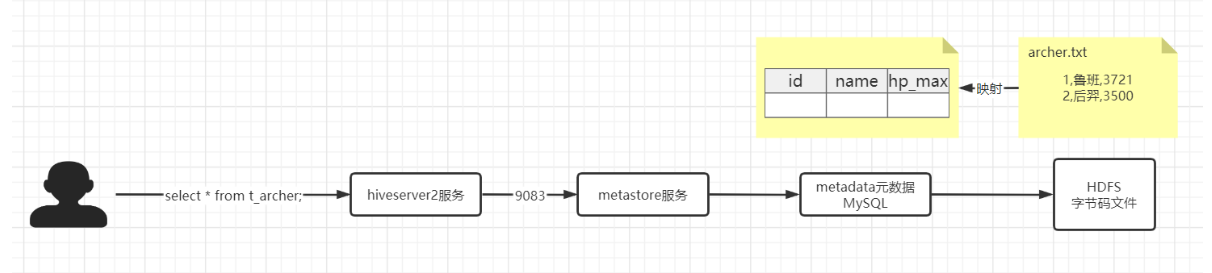
==Hive写文件机制==:把数据表中的每一行Row对象 => 调用LazySimpleSerde类中的序列化方法 => 把Row对象转换为字节码 => 调用OutputFormat方法把字节码写入到文件中。
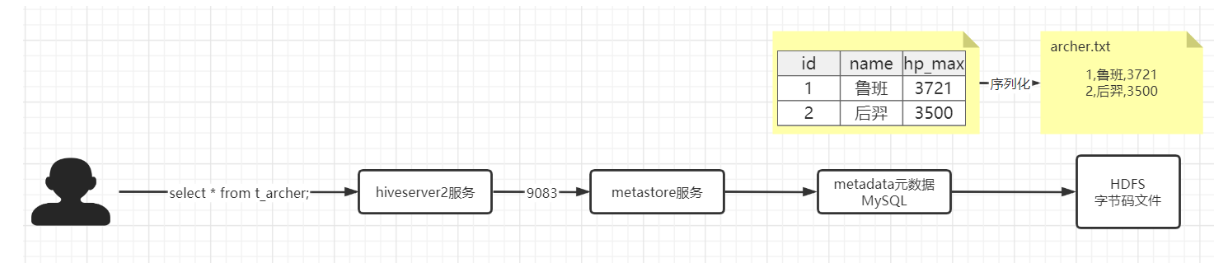 序列化与反序列化的核心:分隔符的定义。分隔符定义的好,有助于序列化和反序列化操作。
序列化与反序列化的核心:分隔符的定义。分隔符定义的好,有助于序列化和反序列化操作。
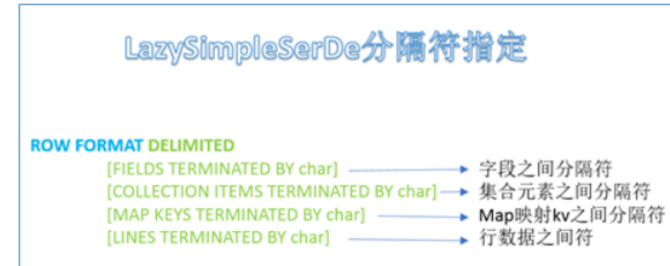

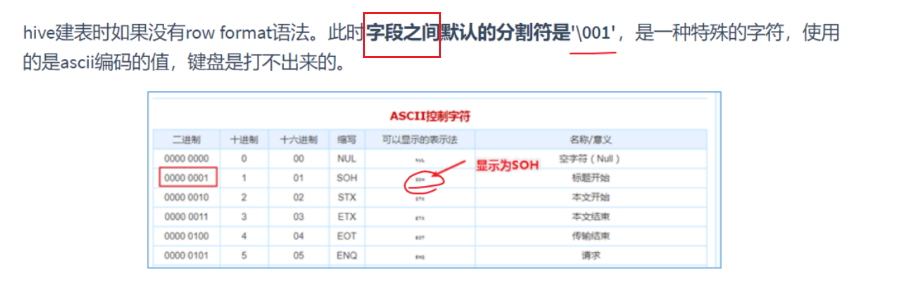 行和行之间默认'\n'分割
行和行之间默认'\n'分割
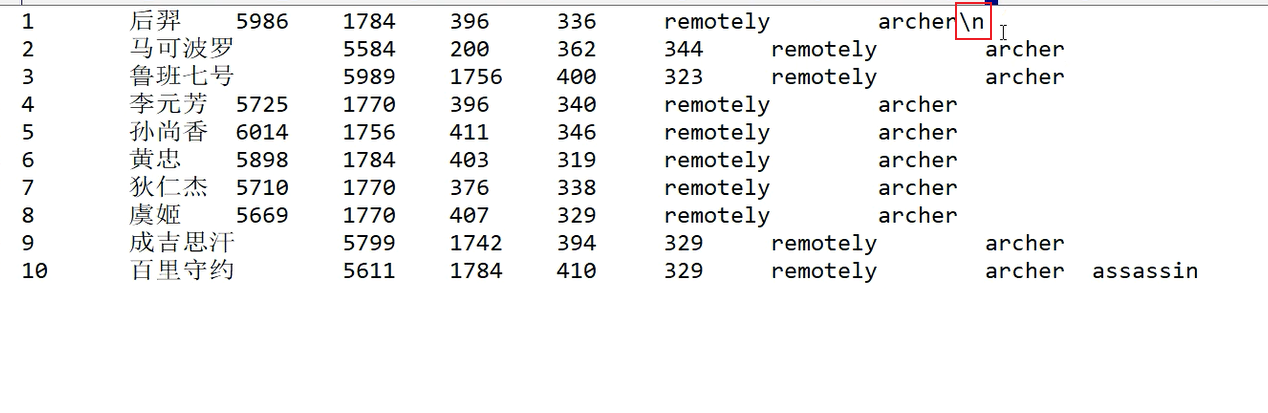
复杂分隔符案例:

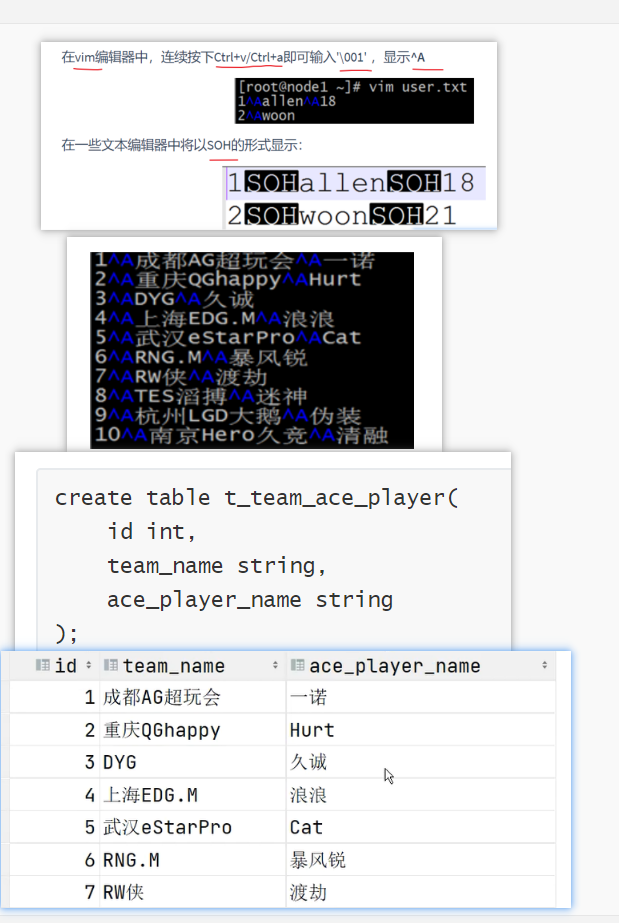
默认分隔符案例:
二、内部表和外部表
内部表(Internal table)也称为被Hive拥有和管理的托管表(Managed table)。==默认情况下创建的表就是内部表==,Hive拥有该表的结构和数据文件。换句话说,Hive完全管理表(元数据和实际数据)的生命周期,类似于RDBMS中的表。删除内部表不仅会删除表元数据,还会从HDFS中删除其所有数据/文件。
外部表(External table)中的数据不是Hive拥有或管理的,只管理表元数据的生命周期。要创建一个==外部表,需要使用EXTERNAL语法关键字==。==而且外部表更为方便的是可以搭配location语法指定数据的路径。==特征:删除外部表只会删除元数据,而不会删除实际数据。在Hive外部仍然可以访问实际数据。
(外部表相当于给HDFS建立了一个链接)
当需要通过Hive完全管理控制表的整个生命周期时,请使用内部表。
当文件已经存在或位于远程位置时,请使用外部表,因为即使删除表,文件也会被保留。
三、分区表

1.静态分区
静态分区指的是分区的字段值是由用户在加载数据的时候手动指定的。
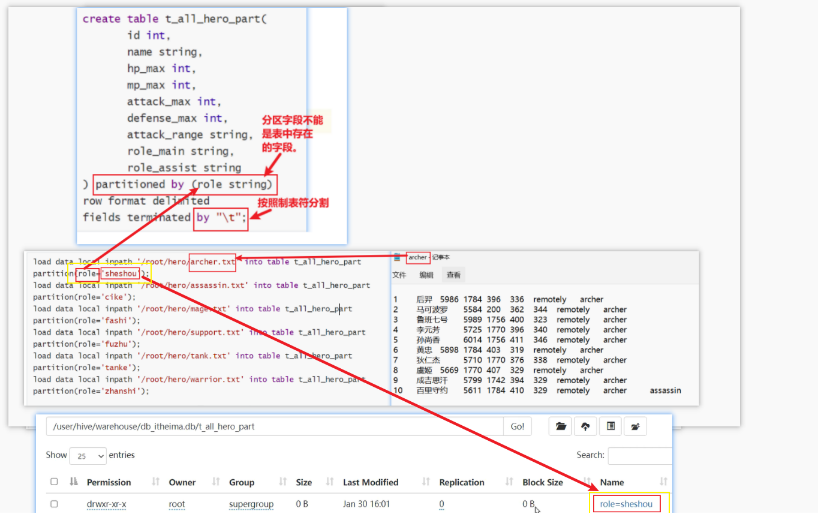

2.动态分区
动态分区指的是分区的字段值是基于查询结果自动推断出来的。核心语法就是insert+select。
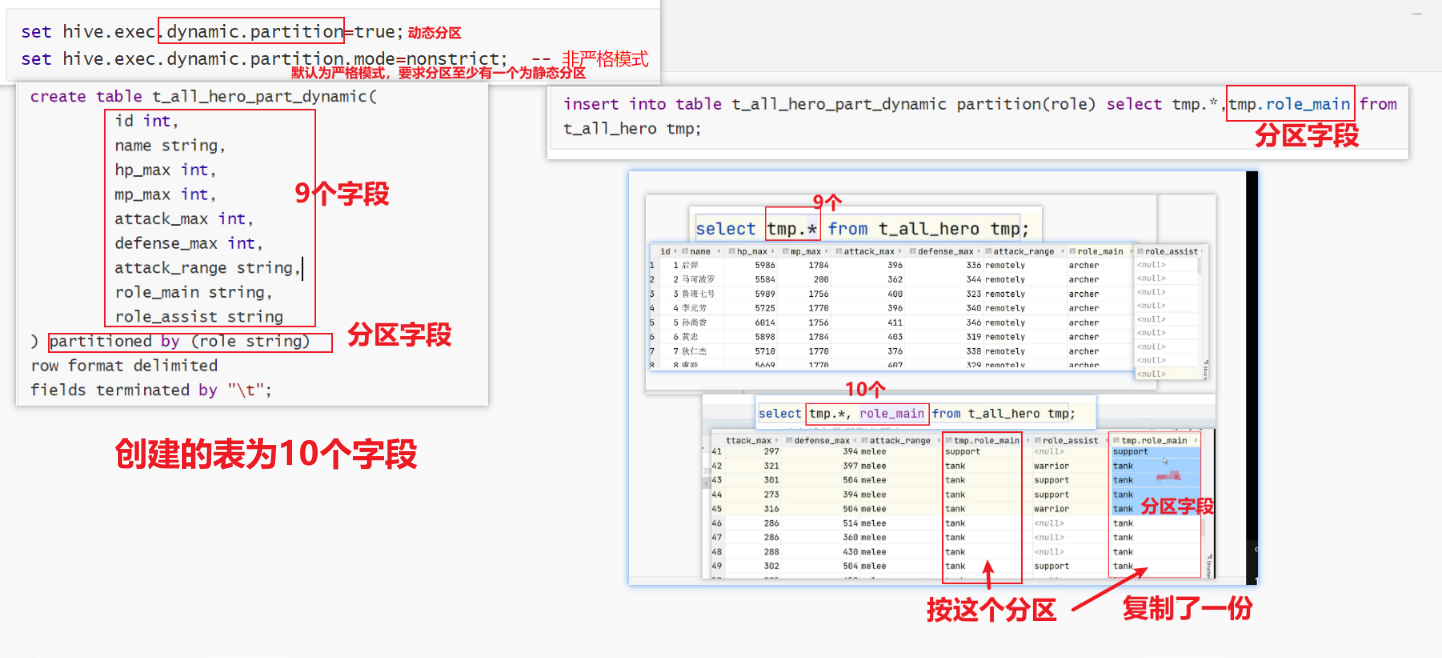
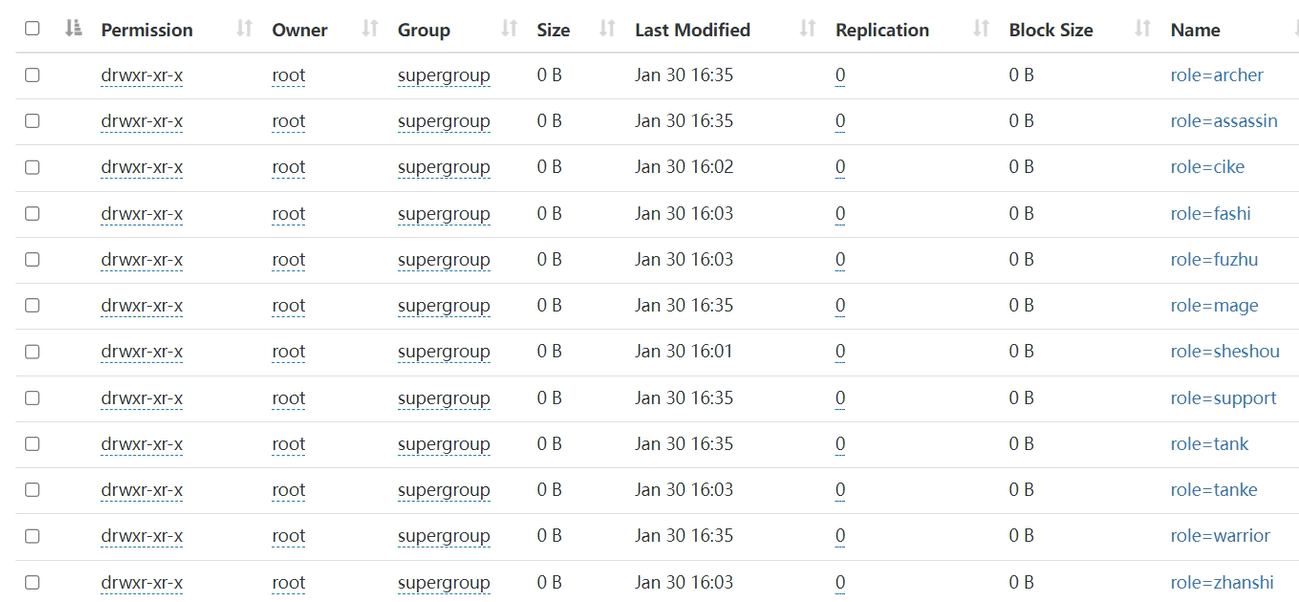
3.分区总结

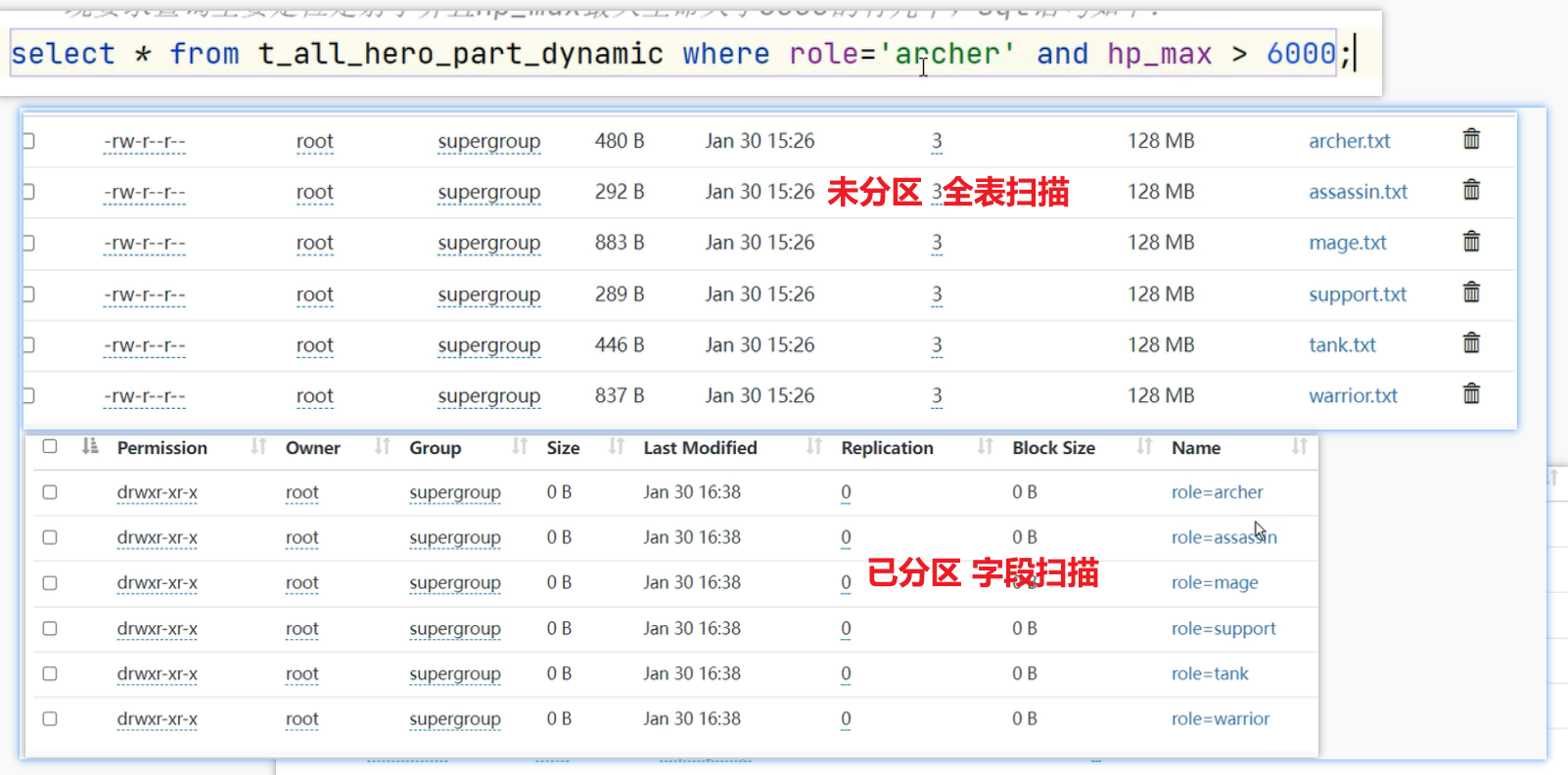
多重分区: