论文信息
| 名称 | 内容 |
|---|---|
| 论文标题 | Label prompt for multi-label text classification |
| 论文地址 | https://link.springer.com/article/10.1007/s10489-022-03896-4 |
| 研究领域 | NLP, 文本分类, 提示学习, 多标签 |
| 提出模型 | LP-MTC(Label Prompt Multi-label Text Classification model) |
| 来源 | Applied Intelligence |
阅读摘要
标签文本分类的关键问题之一是提取和利用标签之间的相关性,但直接建模标签之间的相关性很难。
LP-MTC设计了多标签文本分类模板,将标签整合到预训练语言模型的输入中,可以捕获标签之间的相关性以及标签与文本之间的语义信息,从而有效地提高模型的性能。
1 介绍
由文本分类引出多标签文本分类。
随之介绍解决MTC的三个视角:
1.捕获文档信息;
2.提取文档与标签的判别信息;
3.挖掘标签相关性
阐述二元分类、CNN、注意力机制会忽略标签相关性;生成式网络、学习标签表示、建模标签关联的问题所在:当标签文本之间没有太大差异或缺少标签文本时,这些模型可能会在分类上失败。此外,在未知和复杂的标签空间中对标签的关联进行建模是非常具有挑战性的。
然后从PLM过渡到使用Prompt学习。
LP-MTC利用语言模型学习到的提示模板中的语义信息,学习标签与文本之间的关系;LP-MTC更通用,不需要针对不同的数据集进行定制。
2 相关工作
介绍了多标签文本分类、提示学习。写的比较中规中矩,没有特殊的地方。
3 基础模型
介绍了一下Prompt Learning的基本结构,即PVP模式。

PVP模式可以参考我先前的博客:
1、《基于提示学习的小样本文本分类方法》
2、Knowledgeable Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classific
3、Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference
4 LP-MTC
介绍了文章提出的模型。

提出了两个Trick。一是把文本标签按位置进行MASK,二是联合BERT模型原有的MLM进行联合训练。
4.1 提示模板
对于每个标签,有三个值: Y , N , M Y,N,M Y,N,M,分别表示是、否、MASK。
同时,对于每个标签还显式地赋予了位置编码,即给这个标签的前后分别加上token: S T A R T i START_i STARTi与 E N D i END_i ENDi,而且这每个 S T A R T i START_i STARTi与 E N D i END_i ENDi都需要加入到BERT模型的词汇表里面。
最终,如果这个数据集有3个标签,该条文本的标签为[1, 0, MASK],那么最终会拼接上的模板为:

4.2 联立MLM模型
将标签预测与语言模型的MLM任务结合起来。其实就是利用了BERT模型原本的MLM任务,这在> Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference论文中也有使用。
4.3 损失函数
因为有一个prompt任务,一个MLM任务,要加权一下:

6 分析
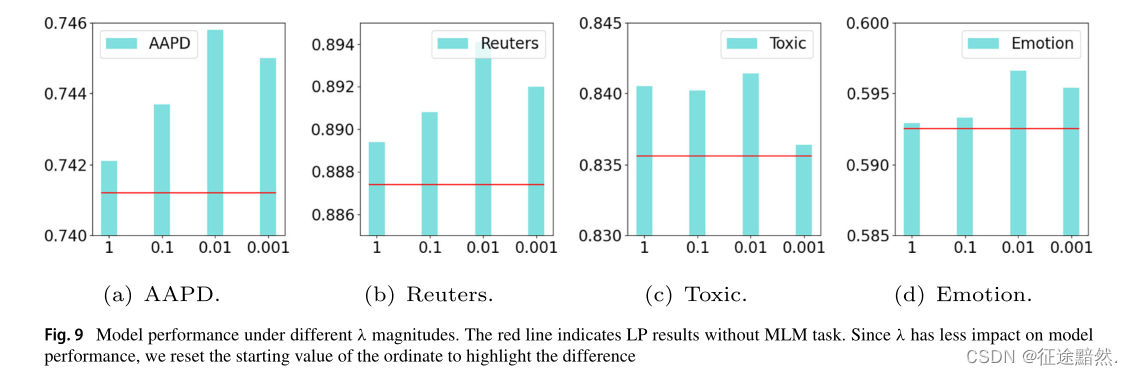
主要说一下参数 a l p h a alpha alpha的设置,和位置编码的效果。
参数在0.01比较好:
消融实验还设置了三种模板形式:
1、普通模板
2、不加位置编码
3、加位置编码

效果如下,说明加位置编码的模板好:








![【PWN刷题__ret2syscall】[Wiki] ret2syscall](https://img-blog.csdnimg.cn/9559d7bdc9bc40bea2e6c5c65c9f5ec1.png)