目录
Abstract
Introduction
Model
Relationship-Dependent Content Masking
Target Fusion
Loss Function
[1711.03438] Open-World Knowledge Graph Completion (arxiv.org)
Abstract
引入一个名为ConMask的开放世界KGC模型,该模型学习实体名称和部分文本描述的嵌入,将看不见的实体连接到KG。为了减少嘈杂文本描述的存在,ConMask使用依赖关系的内容掩码来提取相关片段,然后训练全卷积神经网络,将提取的片段与KG中的实体融合。
Introduction
定义1:closed-world KGC模型在很大程度上依赖于现有KG的连通性,并且能够最好地预测现有的、连接良好的实体之间的关系。但是它们严格依赖现有KG的连通性,closed-world KGC模型无法预测连通性差或新实体的关系。

但是,大多数现实世界中的KGs都在迅速发展,会不断增添新的实体和关系。
定义2:放宽了T′的限制,使得T′中的三元组可以包含原始实体集E中不存在的实体。

封闭世界KGC模型通过基于KG的拓扑更新初始随机向量来学习实体和关系嵌入向量。因此,任何triple<h,r,t>∈T′使得或
将只由其初始随机向量表示,因为其不存在任何推理函数更新。为了预测看不见实体的缺失连接,需要开发替代特征取代封闭世界模型使用的拓扑特征。
text content是断开连接或新添加实体的缺失拓扑特征的替代。尽管将简单地将实体的描述包括在现有的KGC模型中很直观,但是从非结构化文本中学习有用的嵌入向量比在封闭世界任务中学习拓扑嵌入更有挑战性:1)在封闭世界KGC模型中,每个实体都会有一个唯一的嵌入,这是从其直接连接的邻居那里学习的;而开放世界KGC模型必须将实体嵌入与实体描述的单词嵌入相融合。这些单词嵌入必须由共享相同单词的实体更新,而不管它们的连接状态如何;2)由于包含了非结构化内容,开放世界模型很可能包含嘈杂或冗余的信息。
本文的贡献:
(1)提出一个ConMask开放世界KGC模型,该模型使用依赖关系的内容掩蔽减少给定实体描述中的噪声,并使用FCN将相关文本融合到依赖关系的实体嵌入中。
(2)布了两个由DBPedia和维基百科构建的新知识图完成数据集,用于封闭世界和开放世界KGC评估。
提出了一个名为ConMask的开放世界KGC模型,该模型主要使用文本特征来学习实体和关系嵌入。与基于拓扑的和联合学习模型相比,如果看不见的实体与训练期间看到的实体共享相同的词汇表,ConMask可以为它们生成表示。为了正确处理一对多和多对一关系,我们还应用了依赖关系的内容屏蔽层来生成实体嵌入。
Model
ConMask包含三个部分:(1)依赖关系的内容屏蔽,突出显示与任务相关的单词;(2)目标融合,从相关文本中提取嵌入的目标实体;(3)目标实体解析,通过计算KG中候选目标实体、提取的实体嵌入和其他文本特征之间的相似性得分来选择目标实体。
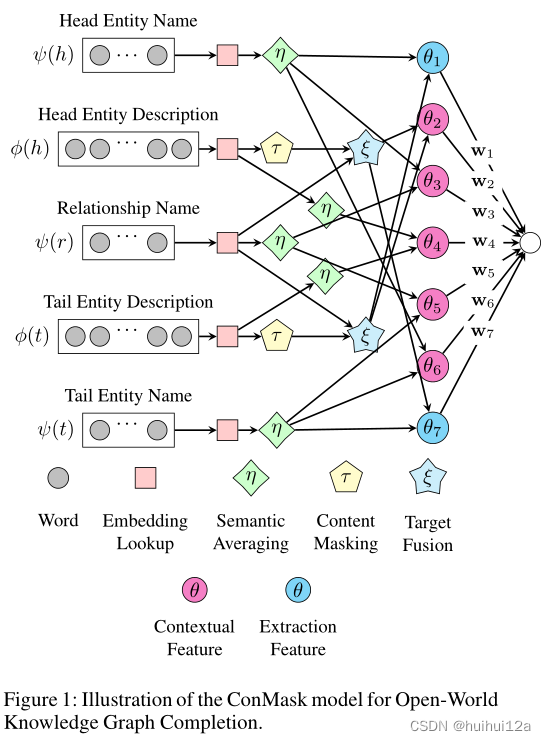
ConMask选择与给定关系相关的单词,以减少包含不相关和嘈杂的单词。然后,从相关文本中,ConMask使用全卷积网络(FCN)来提取基于单词的嵌入。最后,它将提取的嵌入与KG中的现有实体进行比较,以解析目标实体的排序列。
Relationship-Dependent Content Masking
在开放世界中,不能仅根据拓扑结构信息,而要从文本中提取有用信息。通过为给定实体描述中的单词分配依赖于关系的相似性分数来屏蔽不相关的单词,将依赖关系的内容屏蔽定义为:

生成权重的最简单方法是是计算实体描述中的每个单词word和关系名称中
的words之间的相似性分数,这个简单的函数被定义为MWRW:

中第i个单词的权重,是
中第i个词的embedding和
的词嵌入矩阵
中的最大余弦相似性得分。
该函数与给定关系无关的单词分配较低的权重,并为出现在关系中或在语义上与关系相似的单词分配较高的分数,例如当推断(hMichelle Obama,AlmaMater?) MWRW将对普林斯顿大学、哈佛大学等单词赋予高权重,其中包括描述关系目标的单词。但是得分最高的单词并不总是代表实际目标,而是通常代表与关系名称本身相似的单词。 一个反例是:考虑到relation配偶,MWRW得分最高的词是已婚。尽管配偶在语义上与已婚相似,但它并不能回答偏三元组提出的问题。将具有高MWRW权重的词称为指示词,因为正确的目标词通常位于附近。在这个例子中,可以看到,正确的目标Barack Obama出现在指标词已婚之后。为了给目标词分配正确的权重,通过使用最大上下文关系权重(MCRW)来根据上下文调整每个词的权重,从而改进内容屏蔽。

其中φ(e)中第i个单词的权重等于第i个词本身和前km个词的最大MWRW得分。从神经网络的角度来看,重新加权函数fw也可以被视为在Wφ(e)和WTψ(r)的矩阵乘积上应用逐行最大约简,然后应用窗口大小为km的1D最大池化。

综上所述,这里描述的依赖于关系的内容屏蔽过程根据每个单词的上下文与给定关系之间的相似性为实体描述中的单词分配重要性权重。不相关内容被屏蔽后,模型需要从被屏蔽的内容矩阵中学习单个嵌入向量,与候选目标实体的嵌入进行比较。
Target Fusion
本节描述ConMask如何提取基于单词的实体嵌入,将这个过程称为目标融合函数ξ,是基于等式(3)的输出。
本文基于自适应FCNs。使用内容掩蔽的输出生成k维嵌入向量,其中e是来自不完整triple的头或者尾实体。
图3显示了目标融合过程的总体架构及其相关内容屏蔽过程。目标融合过程有三个FCN层。在每一层中,首先使用两个一维卷积算子来执行仿射变换,然后将sigmoid作为激活函数应用于卷积输出,然后进行批量归一化)和最大池化。最后一个FCN层使用平均池化而不是最大池化,以确保目标融合层的输出始终返回单个k维嵌入。

Loss Function
已经通过内容屏蔽和目标融合操作生成了实体嵌入,下一步是定义一个损失函数,该函数查找KG中与生成的嵌入最匹配的一个或多个实体。采用对比学习。