一、读写分离
1.1 背景
面对日益增加的系统访问量,数据库的吞吐量面临着巨大瓶颈。 对于同一时刻有大量并发读操作和较少写操作类型的应用系统来说,将数据库拆分为主库和从库,主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。
通过一主多从的配置方式,可以将查询请求均匀的分散到多个数据副本,能够进一步的提升系统的处理能力。 使用多主多从的方式,不但能够提升系统的吞吐量,还能够提升系统的可用性,可以达到在任何一个数据库宕机,甚至磁盘物理损坏的情况下仍然不影响系统的正常运行。
与将数据根据分片键打散至各个数据节点的水平分片不同,读写分离则是根据 SQL 语义的分析,将读操作和写操作分别路由至主库与从库。

读写分离的数据节点中的数据内容是一致的,而水平分片的每个数据节点的数据内容却并不相同。将水平分片和读写分离联合使用,能够更加有效的提升系统性能。
1.2 挑战
读写分离虽然可以提升系统的吞吐量和可用性,但同时也带来了数据不一致的问题。 这包括多个主库之间的数据一致性,以及主库与从库之间的数据一致性的问题。 并且,读写分离也带来了与数据分片同样的问题,它同样会使得应用开发和运维人员对数据库的操作和运维变得更加复杂。 下图展现了将数据分片与读写分离一同使用时,应用程序与数据库集群之间的复杂拓扑关系。

1.3 应用场景
许多系统通过采用主从数据库架构的配置来提高整个系统的吞吐量,但是主从的配置也给业务的使用带来了一定的复杂性。接入 ShardingSphere,可以利用读写分离功能管理主从数据库,实现透明化的读写分离功能,让用户像使用一个数据库一样使用主从架构的数据库。
不足之处:
ShardingSphere实现读写分离不支持多主库数据分片,支持单主库多表数据分片;ShardingSphere实现读写分离需自定实现主从数据库的同步;
二、Mysql主从数据库同步
请见往期章节:Mysql8 数据库安装及主从配置 | Spring Cloud 2
三、读写分离示例示例
3.1 读写分开总体结构
3.1.1 主库数据源write_ds1
| 数据库地址 | 数据源名称 | 真实表名 | 逻辑表名称 | 业务描述 |
|---|---|---|---|---|
| 192.168.0.35 | write_ds1 | t_goods_0 | t_goods | 商品表-分表 |
| 192.168.0.35 | write_ds1 | t_goods_1 | t_goods | 商品表-分表 |
3.1.2 从库数据源read_ds1
| 数据库地址 | 数据源名称 | 真实表名 | 逻辑表名称 | 业务描述 |
|---|---|---|---|---|
| 192.168.0.45 | read_ds1 | t_goods_0 | t_goods | 商品表-分表 |
| 192.168.0.45 | read_ds1 | t_goods_1 | t_goods | 商品表-分表 |
3.1.3 从库数据源read_ds2
| 数据库地址 | 数据源名称 | 真实表名 | 逻辑表名称 | 业务描述 |
|---|---|---|---|---|
| 192.168.0.46 | read_ds2 | t_goods_0 | t_goods | 商品表-分表 |
| 192.168.0.46 | read_ds1 | t_goods_1 | t_goods | 商品表-分表 |
3.1.1 逻辑商品表 t_goods
-- ----------------------------
-- Table structure for t_goods_0
-- ----------------------------
DROP TABLE IF EXISTS `t_goods_0`;
CREATE TABLE `t_goods_0` (
`goods_id` bigint NOT NULL,
`goods_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '商品名称',
`main_class` bigint NULL DEFAULT NULL COMMENT '商品大类数据字典',
`sub_class` bigint NULL DEFAULT NULL COMMENT '商品小类数据字典',
PRIMARY KEY (`goods_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for t_goods_1
-- ----------------------------
DROP TABLE IF EXISTS `t_goods_1`;
CREATE TABLE `t_goods_1` (
`goods_id` bigint NOT NULL,
`goods_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '商品名称',
`main_class` bigint NULL DEFAULT NULL COMMENT '商品大类数据字典',
`sub_class` bigint NULL DEFAULT NULL COMMENT '商品小类数据字典',
PRIMARY KEY (`goods_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
3.2 项目结构
3.2.1 项目总体结构

3.2.2 Maven 依赖
shading-sphere/shading-readwrite/pom.xml:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>shading-sphere</artifactId>
<groupId>com.gm</groupId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>shading-readwrite</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.2.1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.3.1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.5.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.velocity</groupId>
<artifactId>velocity-engine-core</artifactId>
<version>2.3</version>
</dependency>
<dependency>
<groupId>org.yaml</groupId>
<artifactId>snakeyaml</artifactId>
<version>1.33</version>
</dependency>
</dependencies>
</project>
-
shardingsphere-jdbc-core-spring-boot-starter使用版本5.2.1 -
JDBC的ORM框架选用mybatis-plus
3.2.3 配置文件
server:
port: 8844
spring:
application:
name: @artifactId@
shardingsphere:
# 数据源配置
datasource:
names: write_ds1,read_ds1,read_ds2
write_ds1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.0.35:3306/db1?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: '1qaz@WSX'
read_ds1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.0.45:3306/db1?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: '1qaz@WSX'
read_ds2:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.0.46:3306/db1?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: '1qaz@WSX'
# 定义规则
rules:
sharding:
# 数据分片规则配置
tables:
# 指定某个表的分片配置,逻辑表名
t_goods:
# 这个配置是告诉sharding有多少个库和多少个表及所在实际的数据库节点,由数据源名 + 表名组成(参考 Inline 语法规则)
actual-data-nodes: readwrite_ds.t_goods_$->{0..1} # 此处使用下方定义的读写分离数据源
# 配置表分片策略
table-strategy:
# 用于单分片键的标准分片场景
standard:
# 分片列名称
sharding-column: main_class
# 分片算法名称
sharding-algorithm-name: t_goods_table_inline
# 分布式序列策略
key-generate-strategy:
# 自增列名称,缺省表示不使用自增主键生成器
column: goods_id
# 分布式序列算法名称
key-generator-name: snowflake
# 分片算法配置
sharding-algorithms:
# 分片算法名称
t_goods_table_inline:
# 分片算法类型
type: INLINE
# 分片算法属性配置
props:
algorithm-expression: t_goods_${main_class % 2}
# 分布式序列算法配置(如果是自动生成的,在插入数据的sql中就不要传id,null也不行,直接插入字段中就不要有主键的字段)
keyGenerators:
# 分布式序列算法名称
snowflake:
# 分布式序列算法类型
type: SNOWFLAKE
readwrite-splitting:
dataSources:
readwrite_ds: # 此处定义的数据源名称在上分分表中使用
staticStrategy:
writeDataSourceName: write_ds1
readDataSourceNames:
- read_ds1
- read_ds2
# dynamicStrategy:
loadBalancerName: myBalancer
load-balancers:
myBalancer:
type: RANDOM
props:
transactionalReadQueryStrategy: PRIMARY
props:
sql-show: true #显示sql
mybatis:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
配置简要说明:
商品逻辑表
t_goods:
- 按照商品大类取模分片算法进行分表
读写分离规则中定义的数据源名称
readwrite_ds,在逻辑表t_goods的数据分片规则中得用应用(actual-data-nodes属性)
3.2.4 实体定义
com/gm/shading/readwrite/entity/Goods.java:
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
@Data
@TableName("t_goods")
public class Goods {
@TableId(type = IdType.ASSIGN_ID)
private Long goodsId;
private String goodsName;
private Long mainClass;
private Long subClass;
}
3.2.5 定义mapper
com/gm/shading/readwrite/mapper/GoodsMapper.java:
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.gm.shading.readwrite.entity.Goods;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface GoodsMapper extends BaseMapper<Goods> {
void save(Goods goods);
}
src/main/resources/mapper/GoodsMapper.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!--
~ Copyright (c) 2020 mttsmart4cloud Authors. All Rights Reserved.
~
~ Licensed under the Apache License, Version 2.0 (the "License");
~ you may not use this file except in compliance with the License.
~ You may obtain a copy of the License at
~
~ http://www.apache.org/licenses/LICENSE-2.0
~
~ Unless required by applicable law or agreed to in writing, software
~ distributed under the License is distributed on an "AS IS" BASIS,
~ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
~ See the License for the specific language governing permissions and
~ limitations under the License.
-->
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.gm.shading.readwrite.mapper.GoodsMapper">
<insert id="save" parameterType="com.gm.shading.readwrite.entity.Goods">
insert into t_goods (goods_name, main_class, sub_class)
values (#{goodsName}, #{mainClass}, #{subClass})
</insert>
</mapper>
3.2.6 单元测试
src/test/java/com/gm/shading/readwrite/ShadingReadWriteApplicationTests.java:
package com.gm.shading.readwrite;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.gm.shading.readwrite.entity.Goods;
import com.gm.shading.readwrite.mapper.GoodsMapper;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.List;
import java.util.Random;
@SpringBootTest
public class ShadingReadWriteApplicationTests {
@Autowired
GoodsMapper goodsMapper;
// 分布式队列不生效,使用数据库递增
@Test
void addGoods() throws InterruptedException {
for (int i = 1; i <= 10; i++) {
Goods goods = new Goods();
Random random = new Random();
int mainClass = random.nextInt(100) + 1;
int subClass = random.nextInt(100) + 1;
goods.setMainClass((long) mainClass);
goods.setSubClass((long) subClass);
goods.setGoodsName("商品" + i);
goodsMapper.insert(goods);
}
Thread.sleep(2000);
for (int i = 1; i <= 10; i++) {
QueryWrapper<Goods> queryWrapper = new QueryWrapper<>();
List<Goods> list = goodsMapper.selectList(queryWrapper.orderByAsc("goods_id"));
for (Goods goods : list) {
System.out.println(goods.toString());
}
}
}
// 分布式队列生效,使用雪花算法生成ID
@Test
void addGoods2() throws InterruptedException {
for (int i = 1; i <= 10; i++) {
Goods goods = new Goods();
Random random = new Random();
int mainClass = random.nextInt(100) + 1;
int subClass = random.nextInt(100) + 1;
goods.setMainClass((long) mainClass);
goods.setSubClass((long) subClass);
goods.setGoodsName("商品" + i);
goodsMapper.save(goods);
}
Thread.sleep(2000);
for (int i = 1; i <= 10; i++) {
QueryWrapper<Goods> queryWrapper = new QueryWrapper<>();
List<Goods> list = goodsMapper.selectList(queryWrapper.orderByAsc("goods_id"));
for (Goods goods : list) {
System.out.println(goods.toString());
}
}
}
}
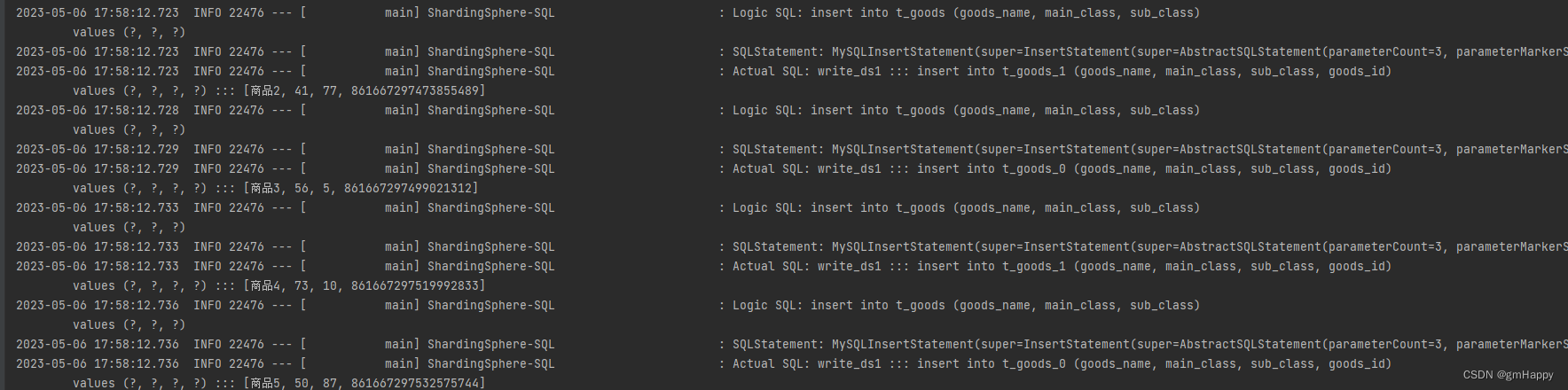
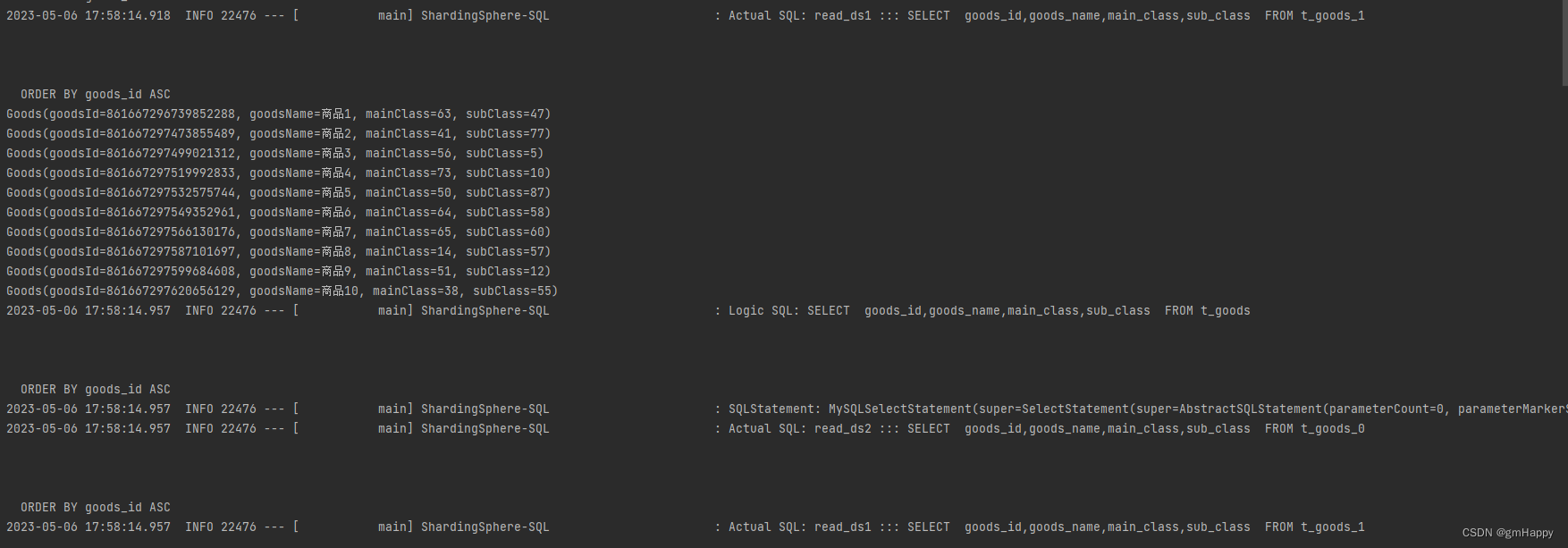
3.2.7 数据分片及读写分离效果









![[MySQL / Mariadb] 数据库学习-Linux中二进制方式安装MySQL5.7](https://img-blog.csdnimg.cn/c0223722813d4283a2ec85cc7a54b9e1.png)