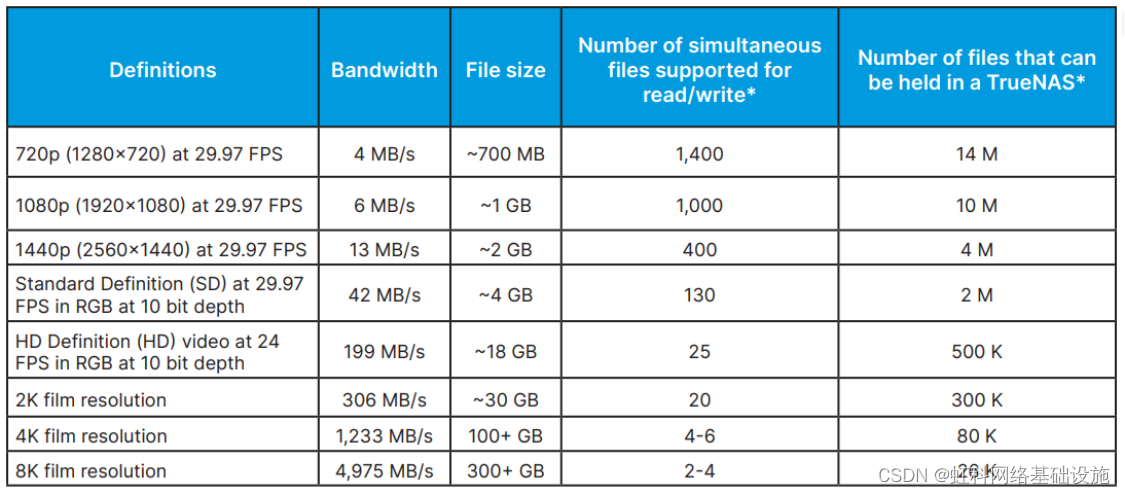
数据清洗
1.删除包含空字段的行
create view v_data_clean_null as
select * from `data` d where
job_href is not null and job_href != '' and
job_name is not null and job_name != '' and
company_href is not null and company_href != '' and
company_name is not null and company_name != '' and
providesalary_text is not null and providesalary_text != '' and
workarea is not null and workarea != '' and
workarea_text is not null and workarea_text != '' and
companytype_text is not null and companytype_text != '' and
degreefrom is not null and degreefrom != '' and
workyear is not null and workyear != '' and
updatedate is not null and updatedate != '' and
issuedate is not null and issuedate != '' and
parse2_job_detail is not null and parse2_job_detail != '';2.按照企业和岗位进行去重保留最新一条
-- 去掉排序字段,把需要的字段都输入一遍
create view v_data_clean_distinct as
with p as
(select *,
row_number () over (partition by company_name,job_name order by issuedate) as row1
from v_data_clean_null )
select
id,
job_href,
job_name,
company_href,
company_name,
providesalary_text,
workarea,
workarea_text,
updatedate,
companytype_text,
degreefrom,
workyear,
issuedate,
parse2_job_detail
from p where row1=1;3.筛选招聘地区在北上广深
-- 过滤招聘地区
create view v_data_clean_workplace as
select * from
(select *,
case
when workarea_text like '%北京%' then '北京'
when workarea_text like '%上海%' then '上海'
when workarea_text like '%广州%' then '广州'
when workarea_text like '%深圳%' then '深圳'
end as workplace
from v_data_clean_distinct ) a where a.workplace is not null;4.过滤周边岗位保留任职要求包含数据的岗位
create view v_data_clean_jobname as
select * from v_data_clean_workplace vdcw where job_name like '%数据%';
-- 最终清洗结果
create view v_data_clean as
(select * from v_data_clean_jobname);市场需求量
需求1:按照城市分组统计招聘总量和招聘职位数
create view v_data_market_demand as
select workplace as '城市',
sum(degreefrom) as '招聘总量',
count(*) as '职位数'
from v_data_clean group by workplace;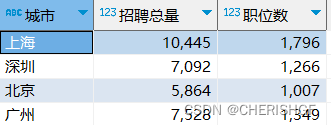
就业企业类型分布
需求2:按照企业类型进行招聘量的统计及招聘占比计算
create view v_data_companytype_degree as
select companytype_text as '企业类型',
companytype_degreefrom as '招聘总量',
concat(cast(companytype_degreefrom /sum_degreefrom*100 as decimal(4,2)),'%') as '招聘占比'
from
(select companytype_text ,
sum(degreefrom) as companytype_degreefrom
from v_data_clean group by companytype_text) f1,
(select sum(degreefrom) as sum_degreefrom from v_data_clean) f2
order by companytype_degreefrom desc;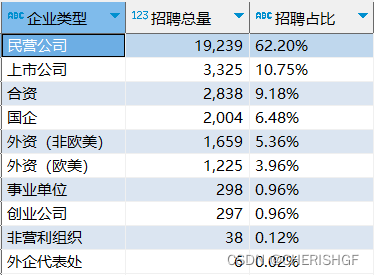
岗位薪资
需求3:计算岗位薪资的单位,最大,最小值,均值
create view v_data_salary_min_max_mean as
with p as
(select * ,
cast(
(case
when unit=10000 then substring_index(substring_index(providesalary_text,'万/月',1),'-',1)
when unit=1000 then substring_index(substring_index(providesalary_text,'千/月',1),'-',1)
when unit=833 then substring_index(substring_index(providesalary_text,'万/年',1),'-',1)
end ) as decimal(10,2))*unit as salary_min,
cast(
(case
when unit=10000 then substring_index(substring_index(providesalary_text,'万/月',1),'-',-1)
when unit=1000 then substring_index(substring_index(providesalary_text,'千/月',1),'-',-1)
when unit=833 then substring_index(substring_index(providesalary_text,'万/年',1),'-',-1)
end ) as decimal(10,2))*unit as salary_max
from v_data_salary_unit)
select *,cast((salary_min+salary_max)/2 as decimal(10,2)) as salary_mean from p;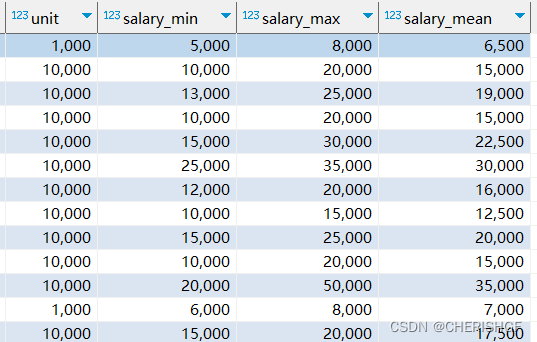
需求4:按照工作年限分组,计算各组平均薪资
create view v_data_workyear_salary as
select workyear as '工作年限',
avg(salary_mean) as '平均薪资'
from v_data_salary_min_max_mean
group by workyear
order by length(workyear),workyear ;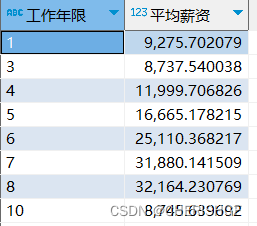
需求5:按照企业类型分组,计算各组平均薪资
create view v_data_companytype_salary as
select companytype_text as '企业类型',
avg(salary_mean) as '平均薪资'
from v_data_salary_min_max_mean
group by companytype_text
order by avg(salary_mean) desc ;
岗位核心技能
需求6:查询技能点在招聘任职要求中出现的次数及前30
create view v_data_skill_quantity as
select st.skill ,
count(*) as quantity
from v_data_clean v
inner join skill_table st on v.parse2_job_detail like concat('%',st.skill,'%')
group by st.skill
order by quantity desc limit 30;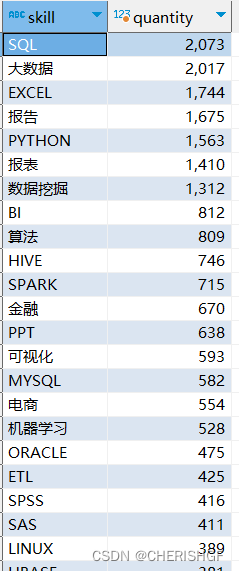
需求7:计算各个技能点出现的频率
create view v_data_skill as
select skill as '技能点',
quantity as '出现频数',
concat(cast(quantity/total_quantity*100 as decimal(10,2)),'%') as '出现频率'
from v_data_skill_quantity ,(select count(*) as total_quantity from v_data_clean ) as f;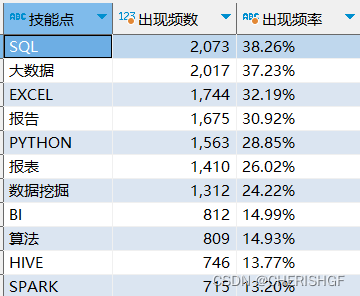
总结
1.上海对于数据分析师需求最大
2.数据分析师在工作第5年薪资即可翻倍
3.民营企业对数据分析师需求最大
4.SQL,大数据,EXCEL,报告撰写等是数据分析岗位中普遍的要求