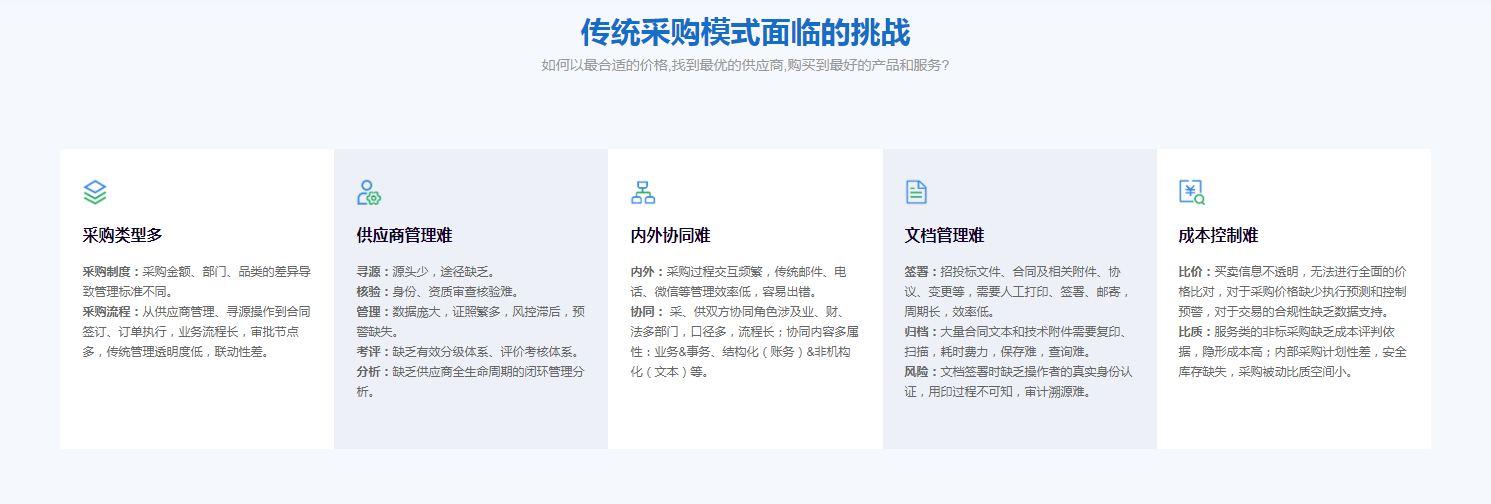
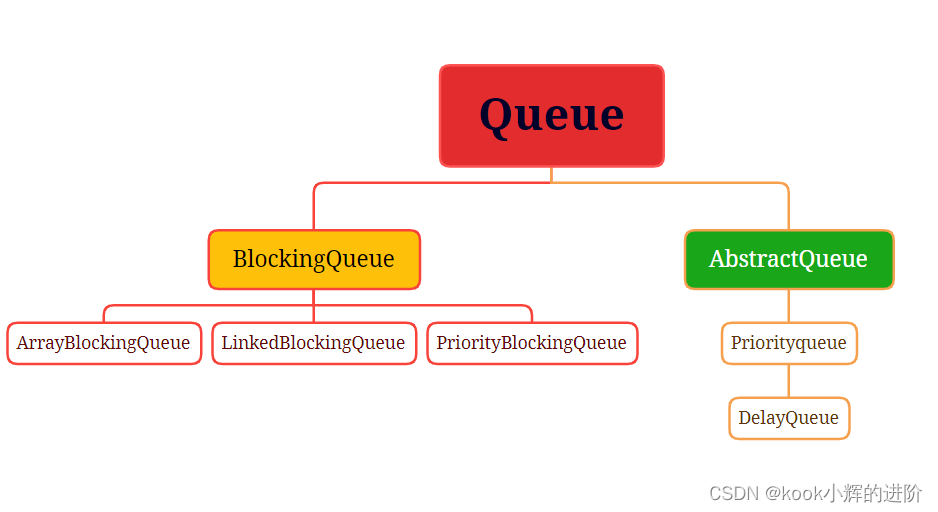
复杂查询
- 上一节说了5种访问类型的查询,这一节就来说说关于这些比较复杂的查询
情况一:多个二级索引查询
- sql:
SELECT * FROM index_value_table WHERE value1 = 'abc' AND value2 > 1000; - 搜索条件:
- value1 等于 abc
- value2 大于 1000
- 我们知道一般情况下,搜索条件会根据单个二级索引进行查询,所以优化器一般会根据 表的统计数据来判断使用哪个搜索条件来进行二级索引。上面这个例子,我们正常情况下会选择 value1 = abc ,因为获取到列最少,在回表的时候可以遍历更少的列来判断另一个搜索条件,步骤可以分为下面两步:
- 使用二级索引定位记录的阶段,也就是根据条件value1 = 'abc’从idx_key1索引代表的B+树中找到对应的二级索引记录。
- 回表阶段,也就是根据上一步骤中找到的记录的主键值进行回表操作,也就是到聚簇索引中找到对应的完整的用户记录,再根据条件value2 > 1000到完整的用户记录继续过滤。将最终符合过滤条件的记录返回给用户。
情况二:多个range访问
- 这个情况有很多种复杂场景,这个时候我们需要了解一下 range访问方法的使用范围区间
- 对于B+树索引来说,只要索引列和常数使用=、<=>、IN、NOT IN、IS NULL、IS NOT NULL、>、<、>=、<=、BETWEEN、!=(不等于也可以写成<>)或者LIKE操作符连接起来,就可以产生一个所谓的区间。
- 对于复杂查询来说,一个查询的where子句有多个小的搜索条件,这些搜索条件都是使用 and 或者 or 连接起来的,而我们想要使用range访问方法执行的话,就需要找出该查询可用的索引中正确的范围区间
- 这里需要普及一个小知识:
- 条件1 AND 条件2:只有当 条件1 和 条件2 都为TRUE时整个表达式才为TRUE
- 条件1 OR 条件2:只要 条件1 或者 条件2 中有一个为TRUE整个表达式就为TRUE
多个range访问 一:所有搜索条件都可以使用某个索引的情况
- sql:
SELECT * FROM index_value_table WHERE value2 > 100 AND value2 > 200; - 搜索条件:
- value2 大于 100
- value2 大于 200
- 因为是and 所以两个查询条件需要取交集,刚好两个查询条件都可以用到 value2 这个索引列,所以我们的查询条件就可以变成 value2 >= 200
- sql:
SELECT * FROM index_value_table WHERE value2 > 100 OR value2 > 200; - 搜索条件:
- value2 大于 100
- value2 大于 200
- 因为是OR所以两个查询条件需要取并集,刚好两个查询条件都可以用到 value2 这个索引列,所以我们的查询条件就可以变成 value2 >100
多个range访问 二:有的搜索条件无法使用索引的情况
-
sql:
SELECT * FROM index_value_table WHERE value2 > 100 AND common_field = 'abc'; -
搜索条件:
- value2 大于 100
- common_field 等于 abc
-
因为 能用索引的搜索条件是 value2 ,但是 在二级索引树里面没有 common_field 这个字段,所以我们只能先更具 value2 大于 100的条件从二级索引树中找出来,回表的时候再判断 common_field 是否是 abc 。所以我们在确定范围区间的时候不需要考虑没有相关索引的搜索条件,把这个条件替换成true就可以了,变化如下:
SELECT * FROM index_value_table WHERE value2 > 100 AND true,化简一下:SELECT * FROM index_value_table WHERE value2 > 100 -
sql :
SELECT * FROM index_value_table WHERE value2 > 100 ORcommon_field = 'abc'; -
搜索条件:
- value2 大于 100
- common_field 等于 abc
-
这个跟上面一个例子的区别就是 and和or的区别,这里如果把 common_field 查询条件变成true 的话 ,查询条件就会变成
value2 > 100 OR TRUE,化简一下就变成 ture了,所以直接变成扫描全表的,所以如果一个使用到索引的搜索条件和没有使用该索引的搜索条件使用OR连接起来后是无法使用该索引的。
多个range访问 三:复杂搜索条件下找出范围匹配的区间
- sql:
SELECT * FROM index_value_table WHERE (value1 > 'xyz' AND value2 = 748 ) OR (value1 < 'abc' AND value1 > 'lmn') OR (value1 LIKE '%suf' AND value1 > 'zzz' AND (value2 < 8000 OR common_field = 'abc')) ; - 查询条件:
- value1 大于 xyz 且 value2 等于 748
- value1 小于 abc 且 value2 大于 lmn
- value1 类似 后缀为 suf 且 value1 大于 zzz 且 ( value2 小于 8000 或者 common_field 等于 abc )
- 这个查询真的,很复杂,优化器会怎么优化这种查询呢,我们先来看看有几个索引列,value1 对应的 idx_key1,value2 对应的 idx_key2,一般都会采用单个二级索引,所以我们把 idx_key1 和 idx_key2 分开看
- 先看 idx_key1 执行查询,把二级索引用不到字段查询替换成true 进行化简
- 替换之后:
(value1 > 'xyz' AND true ) OR (value1 < 'abc' AND value1 > 'lmn') OR (true AND value1 > 'zzz' AND (true OR true)) ;- 化简之后:
value1 > 'xyz' OR (value1 < 'abc' AND value1 > 'lmn') OR value1 > 'zzz'; - 因为 value1 < ‘abc’ and value1 > ‘lmn’ 按照字符集比较规则,这个条件根本不可能生效,所以 继续化简:
value1 > 'xyz' OR value1 > 'zzz'; - 剩下因为 OR 操作符,需要取并集,最终化简:
value1 > 'xyz' - 化简完之后,我们根据这个进行二级索引查询,然后在回表的时候进行其他非这个索引的查询
- 化简之后:
- 替换之后:
- 我们再来看 idx_key2 执行查询
- 我们需要把那些用不到该索引的搜索条件暂时使用TRUE条件替换掉,其中有关value1和common_field的搜索条件都需要被替换掉,替换结果就是:
(true AND value2 = 748 ) OR (true AND value2 = 748) OR (true AND true AND (value2 < 8000 OR true)) ; - 在化简就变成
value2 = 748 OR TRUE - 然后再化简就变成
true - 意思就是如果要使用idx_key2索引查询语句的话,就需要扫描所有记录
- 我们需要把那些用不到该索引的搜索条件暂时使用TRUE条件替换掉,其中有关value1和common_field的搜索条件都需要被替换掉,替换结果就是:
情况三:索引合并
- 一般情况下,mysql执行一个查询的时候只会用到单个二级索引或者聚簇索引,但还是有特殊情况,可能会用到多个二级索引,而这种用到多个二级索引的查询叫做索引合并。
- 索引合并的算法主要有三种:
- Intersection合并:交集合并
- Union合并
- Sort-Union合并
Intersection合并:交集合并
- 什么是Intersection合并?
- 举个例子:
SELECT * FROM index_value_table WHERE value1 = 'a' AND value3 = 'b'; - 执行过程是这样的:
- 从idx_key1二级索引对应的B+树中取出value1 = 'a’的相关记录
- 从idx_key3二级索引对应的B+树中取出value3 = 'b’的相关记录
- 计算得出两个结果集中的主键值交集
- 通过得到的结果集进行回表找到对应的记录
- Intersection 合并 就是 某个查询可以使用多个二级索引,将从多个二级索引中查询到的结果取交集
- 举个例子:
- 为什么会有Intersection合并?
- 从上面的例子可以看出来,我们完全可以选择其中一个二级索引查找,然后通过回表的时候过滤掉另一个条件,为什么不这么做呢?
- 这里就需要分析一下 两种方式所对应的成本代价
- 只读一个二级索引的成本:
- 按照某个搜索条件读取一个二级索引
- 回表 过滤
- 读取多个二级索引之后取交集成本:
- 按照不同的搜索条件分别读取不同的二级索引
- 将从多个二级索引得到的主键值取交集,然后进行回表操作
- 只读一个二级索引的成本:
- 虽然读取多个二级索引比读取一个二级索引消耗性能,但是读取二级索引的操作是顺序I/O,而回表操作是随机I/O,所以如果只读取一个二级索引时需要回表的记录数特别多,而读取多个二级索引之后取交集的记录数非常少,当节省的因为回表而造成的性能损耗比访问多个二级索引带来的性能损耗更高时,读取多个二级索引后取交集比只读取一个二级索引的成本更低。
- 所以 MySQL只会在某些特定的情况下才可能使用到 Intersection索引合并
- 什么情况会使用Intersection合并?
- 情况一:二级索引列是等值匹配的情况,对于联合索引来说,在联合索引中的每个列都必须等值匹配,不能出现只匹配部分列的情况。
- 举个例子:
SELECT * FROM index_value_table WHERE value1 = 'a' AND value_part1 = 'a' AND value_part2 = 'b' AND value_part3 = 'c'; - 为什么这种情况可以?
- 答案是因为,二级索引树,你通过等值查找的时候,会获取很多条记录,只有在这种情况下根据二级索引查询出的结果集是按照主键值排序的,所以你得到两个主键的结果集都是由小到大进行排序的,然后通过一定的算法可以将对应的交集算出来,这种速度是很快的。
- 求交集的方法:
- 假设 从idx_key1中获取到已经排好序的主键值:1、3、5
- 假设从idx_key2中获取到已经排好序的主键值:2、3、4
- 那么求交集的过程就是这样:逐个取出这两个结果集中最小的主键值,如果两个值相等,则加入最后的交集结果中,否则丢弃当前较小的主键值,再取该丢弃的主键值所在结果集的后一个主键值来比较,直到某个结果集中的主键值用完了,过程如下:
* 先取出这两个结果集中较小的主键值做比较,因为1 < 2,所以把idx_key1的结果集的主键值1丢弃,取出后边的3来比较。
* 因为3 > 2,所以把idx_key2的结果集的主键值2丢弃,取出后边的3来比较。
* 因为3 = 3,所以把3加入到最后的交集结果中,继续两个结果集后边的主键值来比较。
* 后边的主键值也不相等,所以最后的交集结果中只包含主键值3。
- 求交集的方法:
- 答案是因为,二级索引树,你通过等值查找的时候,会获取很多条记录,只有在这种情况下根据二级索引查询出的结果集是按照主键值排序的,所以你得到两个主键的结果集都是由小到大进行排序的,然后通过一定的算法可以将对应的交集算出来,这种速度是很快的。
- 举个例子:
- 情况二:主键列可以是范围匹配
- 举个例子:
SELECT * FROM index_value_table WHERE id > 100 AND value1 = 'a'; - 为什么这种情况可以?
- 答案还是因为二级索引树,当你通过索引找到对应的主键id时,就已经可以过滤掉不是这个范围的记录了
- 举个例子:
- 情况一:二级索引列是等值匹配的情况,对于联合索引来说,在联合索引中的每个列都必须等值匹配,不能出现只匹配部分列的情况。
- 注意事项:即使情况一、情况二成立,也不一定发生Intersection索引合并,这得看优化器的心情。优化器只有在单独根据搜索条件从某个二级索引中获取的记录数太多,导致回表开销太大,而通过Intersection索引合并后需要回表的记录数大大减少时才会使用Intersection索引合并。
Union合并
- 什么是Union合并?
- Union合并 就是 某个查询可以使用多个二级索引,将从多个二级索引中查询到的结果取并集
- 什么情况下会有Union合并?
- 情况一:二级索引列是等值匹配的情况,对于联合索引来说,在联合索引中的每个列都必须等值匹配,不能出现只出现匹配部分列的情况。
- 举个例子:
SELECT * FROM index_value_table WHERE value1 = 'a' OR ( value_part1 = 'a' AND value_part2 = 'b' AND value_part3 = 'c');
- 举个例子:
- 情况二:主键列可以是范围匹配
- 情况三:使用Intersection索引合并的搜索条件
- 举个例子:
SELECT * FROM index_value_table WHERE value_part1 = 'a' AND value_part2 = 'b' AND value_part3 = 'c' OR (value1 = 'a' AND value3 = 'b');
- 举个例子:
- 情况一:二级索引列是等值匹配的情况,对于联合索引来说,在联合索引中的每个列都必须等值匹配,不能出现只出现匹配部分列的情况。
- 注意事项:查询条件符合了这些情况也不一定就会采用Union索引合并,也得看优化器的心情。优化器只有在单独根据搜索条件从某个二级索引中获取的记录数比较少,通过Union索引合并后进行访问的代价比全表扫描更小时才会使用Union索引合并。
总结一下
- 索引合并的使用场景:
- 当查询条件中包含多个列时,每个列都有单独的索引,但是MySQL无法使用这些索引进行有效的查询优化。这时,MySQL可以将多个索引合并使用,以便提高查询性能。
- 当查询条件中包含多个列时,每个列都有单独的索引,并且MySQL可以使用这些索引进行有效的查询优化。这时,MySQL可以选择使用索引合并来进一步优化查询性能。
![tensorRT的完整安装以及常见错误 export failure: [WinError 127] 找不到指定的程序。](https://img-blog.csdnimg.cn/e963126d2a4c4dad916e21228324e190.png)