CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CL
1.ResiDual: Transformer with Dual Residual Connections

标题:ResiDual:具有双剩余连接的Transformer
作者:Shufang Xie, Huishuai Zhang, Junliang Guo, Xu Tan, Jiang Bian, Hany Hassan Awadalla, Arul Menezes, Tao Qin, Rui Yan
文章链接:https://arxiv.org/abs/2304.14802
项目代码:https://github.com/microsoft/ResiDual


摘要:
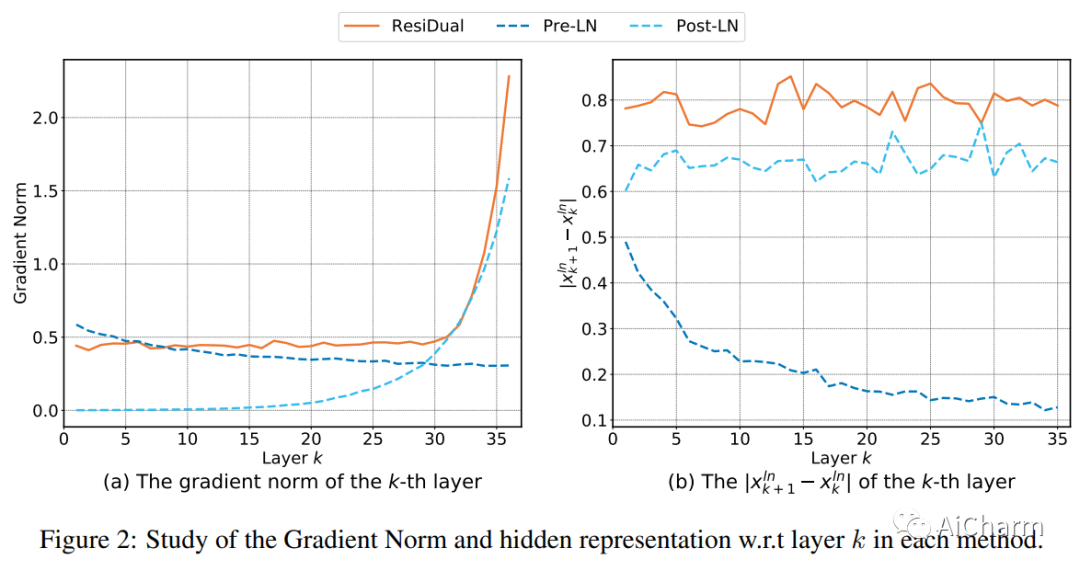
由于其最先进的性能,Transformer 网络已成为许多任务的首选架构。然而,在 Transformer 中实现残差连接的最佳方式仍然存在争议,这对于有效训练至关重要。两种广泛使用的变体是后层归一化 (Post-LN) 和前层归一化 (Pre-LN) 变换器,它们分别在每个残差块的输出之后或每个残差块的输入之前应用层归一化。虽然这两种变体都有其优势,但它们也有严重的局限性:Post-LN 导致梯度消失问题,阻碍了深度 Transformers 的训练,而 Pre-LN 导致表示崩溃问题,限制了模型容量。在本文中,我们提出了 ResiDual,一种具有 Pre-Post-LN (PPLN) 的新型 Transformer 架构,它将 Post-LN 和 Pre-LN 中的连接融合在一起,继承了它们的优点,同时避免了它们的局限性。我们进行了理论分析和实证实验来验证 Residual 的有效性。从理论上讲,我们证明 ResiDual 在梯度上有一个下限,以避免由于 Pre-LN 的残差连接而导致的消失问题。此外,Residual 还具有多样化的模型表示,以避免由于 Post-LN 的残差连接而导致的崩溃问题。根据经验,Residual 在不同网络深度和数据大小的多个机器翻译基准测试中优于 Post-LN 和 Pre-LN。由于良好的理论和实证性能,Residual Transformer 可以作为不同 AI 模型(例如,大型语言模型)的基础架构。我们的代码可在此 https URL 上获得。
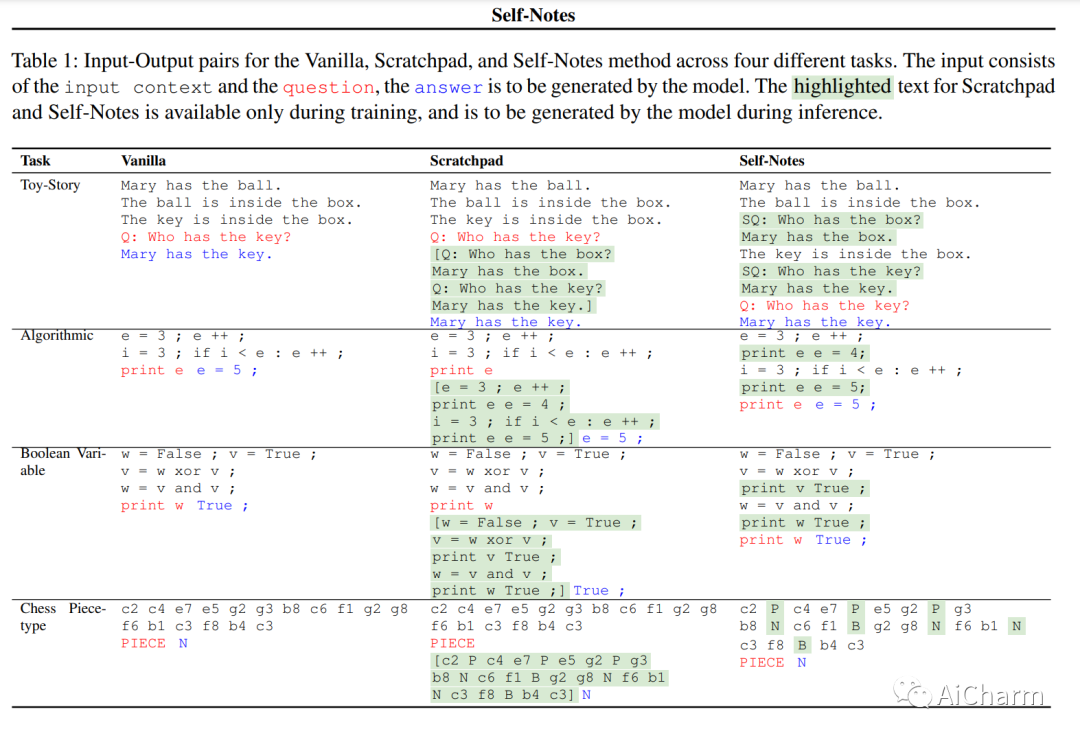
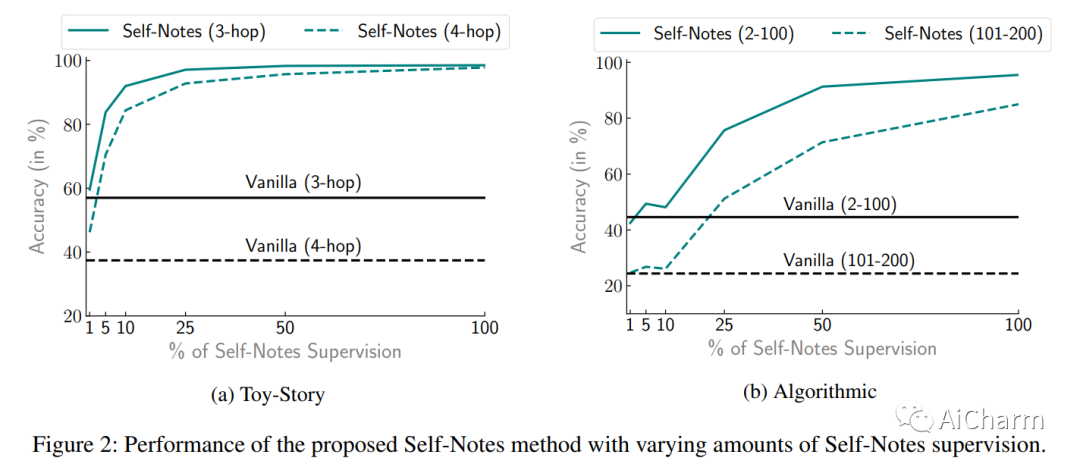
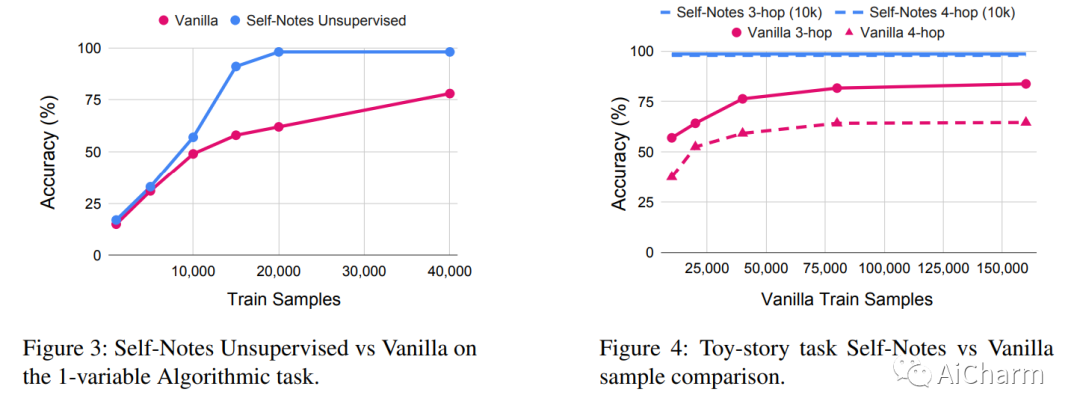
2.Learning to Reason and Memorize with Self-Notes

标题:ImageReward:学习和评估人类对文本到图像生成的偏好
作者:Jack Lanchantin, Shubham Toshniwal, Jason Weston, Arthur Szlam, Sainbayar Sukhbaatar
文章链接:https://arxiv.org/abs/2305.00833

摘要:
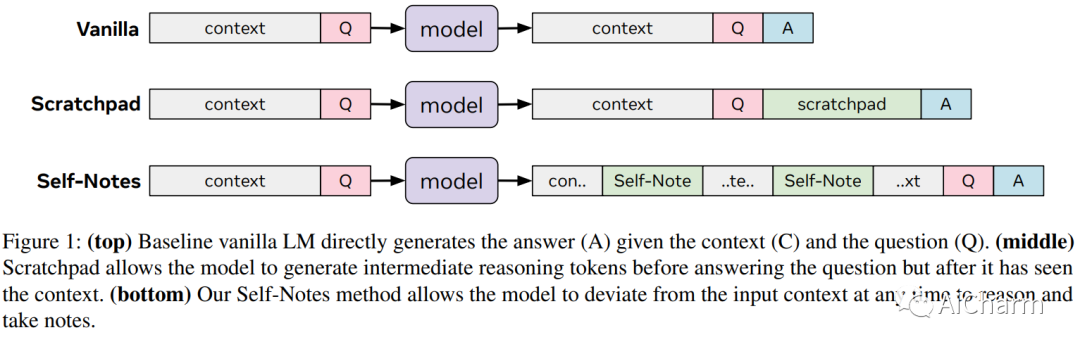
大型语言模型已被证明难以应对有限的上下文记忆和多步推理。我们提出了一种简单的方法来解决这两个问题,即允许模型进行自我注释。与最近的暂存器方法不同,该模型可以随时偏离输入上下文以明确思考。这允许模型在读取上下文时即时调用信息并执行推理,从而扩展其记忆并实现多步推理。我们对多项任务的实验表明,我们的方法可以通过在推理时进行自我注释,成功地从训练设置中泛化到更长、更复杂的实例。
Subjects: cs.CV
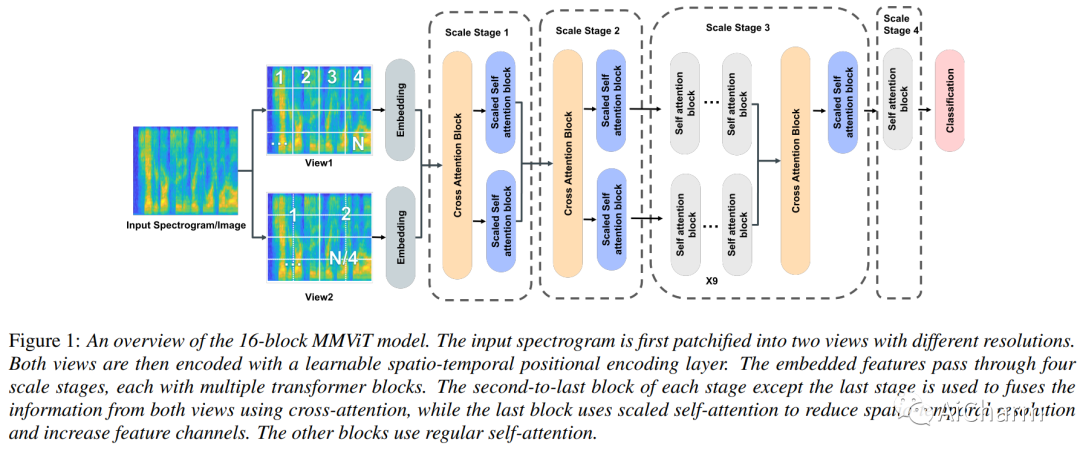
3.MMViT: Multiscale Multiview Vision Transformers

标题:MMViT:多尺度多视图视觉Transformer
作者:Yuchen Liu, Natasha Ong, Kaiyan Peng, Bo Xiong, Qifan Wang, Rui Hou, Madian Khabsa, Kaiyue Yang, David Liu, Donald S. Williamson, Hanchao Yu
文章链接:https://arxiv.org/abs/2305.00104

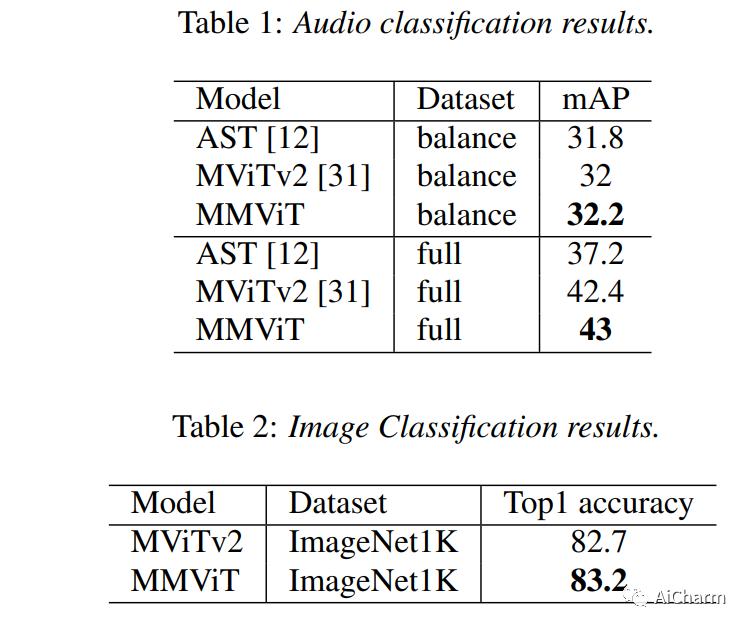
摘要:
我们介绍了多尺度多视图视觉变换器 (MMViT),它将多尺度特征图和多视图编码引入到变换器模型中。我们的模型对输入信号的不同视图进行编码,并构建多个通道分辨率特征阶段,以并行处理不同分辨率下输入的多个视图。在每个规模阶段,我们使用交叉注意块来融合不同视图的信息。这使 MMViT 模型能够以不同的分辨率获取输入的复杂高维表示。所提出的模型可以作为多个领域的骨干模型。我们展示了 MMViT 在音频和图像分类任务上的有效性,实现了最先进的结果。
更多Ai资讯:公主号AiCharm