文章目录
- 一 处理迟到元素
- 1 处理策略
- (3)使用迟到元素更新窗口计算结果
- a 代码编写
- b 测试
- 二 自定义水位线
- 1 产生水位线的接口
- 2 自定义水位线的产生逻辑
- 三 多流的合流与分流
- 1 union算子
- 2 水位线传递规则
- (1) 分流
- a 代码编写
- b 测试
- (2) 合流
- a 代码编写
- b 测试
- 3 connect算子
一 处理迟到元素
1 处理策略
(3)使用迟到元素更新窗口计算结果
由于存在迟到的元素,所以已经计算出的窗口结果是不准确和不完全的。我们可以使用迟到元素更新已经计算完的窗口结果。
如果我们要求一个 operator 支持重新计算和更新已经发出的结果,就需要在第一次发出结果以后也要保存之前所有的状态。但显然我们不能一直保存所有的状态,肯定会在某一个时间点将状态清空,而一旦状态被清空,结果就再也不能重新计算或者更新了。而迟到的元素只能被抛弃或者发送到旁路输出流。
window operator API 提供了方法来明确声明我们要等待迟到元素。当使用 event-timewindow,我们可以指定一个时间段叫做 allowed lateness(允许等待时间)。window operator 如果设置了allowed lateness,这个 window operator 在水位线没过窗口结束时间时也将不会删除窗口和窗口中的状态。窗口会在一段时间内 (allowed lateness 设置的) 保留所有的元素。
当迟到元素在 allowed lateness 时间内到达时,这个迟到元素会被实时处理并发送到触发器 (trigger)。当水位线超过了窗口结束时间 + allowed lateness 时间时,窗口会被删除,并且所有后来的迟到的元素都会被丢弃。
使用迟到数据更新窗口的计算结果:
a 代码编写
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<String> result = env
.socketTextStream("localhost", 9999)
.map(new MapFunction<String, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(String value) throws Exception {
String[] arr = value.split(" ");
return Tuple2.of(arr[0], Long.parseLong(arr[1]) * 1000L);
}
})
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Tuple2<String, Long>>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner(
new SerializableTimestampAssigner<Tuple2<String, Long>>() {
@Override
public long extractTimestamp(Tuple2<String, Long> element, long recordTimestamp) {
return element.f1;
}
}
)
)
.keyBy(r -> r.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
// 允许等待时间为5S,5S后窗口被销毁
.allowedLateness(Time.seconds(5))
// 等待5S后到来的数据被输出到侧输出流中
.sideOutputLateData(new OutputTag<Tuple2<String, Long>>("late") {
})
.process(new ProcessWindowFunction<Tuple2<String, Long>, String, String, TimeWindow>() {
// 在窗口闭合的时候调用
@Override
public void process(String s, Context context, Iterable<Tuple2<String, Long>> elements, Collector<String> out) throws Exception {
// 初始化一个窗口状态变量,注意,窗口状态变量的可见范围是当前窗口
// 是否为第一次触发计算
ValueState<Boolean> firstCalcaulate =
context.windowState().getState(new ValueStateDescriptor<Boolean>("first", Types.BOOLEAN));
// 闭合窗口,产生第一次计算
if (firstCalcaulate.value() == null) {
out.collect("窗口第一次触发了计算!水位线是【" + context.currentWatermark()
+ "】窗口中共有【" + elements.spliterator().getExactSizeIfKnown() + "】条元素");
// 第一次触发process计算,将状态更新为true
firstCalcaulate.update(true);
} else {
out.collect("迟到数据到了,更新以后窗口中的元素数量是【" + elements.spliterator().getExactSizeIfKnown() + "】");
}
}
});
result.print("正常数据:");
result.getSideOutput(new OutputTag<Tuple2<String,Long>>("late"){}).print("迟到数据:");
env.execute();
}
b 测试
输入数据输出结果如下:
a 1
a 2
a 10 输出:正常数据:> 窗口第一次触发了计算!水位线是【4999】窗口中共有【2】条元素
注意:此时【0-5】窗口不会被销毁,窗口销毁时间 = 5 + 5 - 1ms = 9999ms
a 1 输出:正常数据:> 迟到数据到了,更新以后窗口中的元素数量是【3】
a 1 输出:正常数据:> 迟到数据到了,更新以后窗口中的元素数量是【4】
a 7 注意:属于【5-10】窗口,不会触发【5-10】窗口的第一次计算
a 8
注意:输入a 15,关闭【0-5】窗口,且触发【5-10】窗口的计算
a 15 输出:正常数据:> 窗口第一次触发了计算!水位线是【9999】窗口中共有【2】条元素
注意:再输入【0-5】窗口中的数据,被输出到侧输出流中
a 1 输出:迟到数据:> (a,1000)
所以从本质上看,此种处理迟到数据的策略是【上文(2)】的扩展,那么为什么不直接将延迟时间设置为10S呢?因为
- 有些窗口不存在迟到数据
- 能够更快的看到计算结果
所以对于迟到数据的处理方法,要根据实际情况进行权衡。
二 自定义水位线
1 产生水位线的接口
@Public
public interface WatermarkGenerator<T> {
/**
* 每来一个事件都会调用, 允许水位线产生器记忆和检查事件的时间戳。
* 允许水位线产生器基于事件本身发射水位线。
*/
void onEvent(T event, long eventTimestamp, WatermarkOutput output);
/**
* 周期性的调用(默认 200ms 调用一次), 可能会产生新的水位线,也可能不会。
*
* 调用周期通过 ExecutionConfig#getAutoWatermarkInterval() 方法来配置。
*/
void onPeriodicEmit(WatermarkOutput output);
}
2 自定义水位线的产生逻辑
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env
.socketTextStream("localhost",9999)
.map(new MapFunction<String, Tuple2<String,Long>>() {
@Override
public Tuple2<String, Long> map(String value) throws Exception {
String[] arr = value.split(" ");
return Tuple2.of(arr[0],Long.parseLong(arr[1]) * 1000L);
}
})
.assignTimestampsAndWatermarks(new CustomerWatermarkGenerator())
.print();
env.execute();
}
public static class CustomerWatermarkGenerator implements WatermarkStrategy<Tuple2<String,Long>> {
@Override
public TimestampAssigner<Tuple2<String, Long>> createTimestampAssigner(TimestampAssignerSupplier.Context context) {
return new SerializableTimestampAssigner<Tuple2<String, Long>>() {
@Override
public long extractTimestamp(Tuple2<String, Long> element, long recordTimestamp) {
return element.f1;
}
};
}
@Override
public WatermarkGenerator<Tuple2<String, Long>> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) {
return new WatermarkGenerator<Tuple2<String, Long>>() {
// 延迟时间为5s
private long bound = 5000L;
// 防止溢出,最后计算水位线时需要- bound - 1L
private long maxTs = -Long.MAX_VALUE + bound + 1L;
// 来一个事件,执行一次
@Override
public void onEvent(Tuple2<String, Long> event, long eventTimestamp, WatermarkOutput output) {
// 更新观察到的最大事件事件
maxTs = Math.max(maxTs,event.f1);
}
// 周期型计算水位线
@Override
public void onPeriodicEmit(WatermarkOutput output) {
// 发送水位线,注意水位线的计算公式
output.emitWatermark(new Watermark(maxTs - bound - 1L));
}
};
}
}
三 多流的合流与分流
1 union算子
union算子用于多条流的合并,所有流中的元素类型必须相同。
多流按照先进先出(FIFO)的原则进行合并。
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//DataStreamSource<T> extends SingleOutputStreamOperator<T>
//SingleOutputStreamOperator<T> extends DataStream<T>
DataStreamSource<Integer> stream1 = env.fromElements(1, 2);
DataStreamSource<Integer> stream2 = env.fromElements(3, 4);
DataStreamSource<Integer> stream3 = env.fromElements(5, 6);
DataStream<Integer> result = stream2.union(stream1, stream3);
result.print();
env.execute();
}
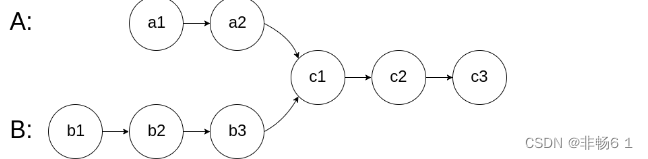
水位线在单条流进行分流(找最小的时钟)和多条流进行合流(复制,向下广播)的时候,可以从union中看出来,如下:
当三条流进行合流时,会更新事件时钟算子,选择最小的(详情见2(2)合流的测试);向下传播的时候,会进行广播(详情见2(1)分流的测试),此为水位线传播规则。

2 水位线传递规则
(1) 分流
a 代码编写
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env
.socketTextStream("localhost",9999)
.map(new MapFunction<String, Tuple2<String,Long>>() {
@Override
public Tuple2<String, Long> map(String value) throws Exception {
String[] arr = value.split(" ");
return Tuple2.of(arr[0],Long.parseLong(arr[1]) * 1000L);
}
})
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Tuple2<String, Long>>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<String, Long>>() {
@Override
public long extractTimestamp(Tuple2<String, Long> element, long recordTimestamp) {
return element.f1;
}
})
)
.keyBy(r -> r.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.process(new ProcessWindowFunction<Tuple2<String, Long>, String, String, TimeWindow>() {
@Override
public void process(String s, Context context, Iterable<Tuple2<String, Long>> elements, Collector<String> out) throws Exception {
out.collect("key:" + s + " 的窗口触发了");
}
})
.print();
env.execute();
}
b 测试
输入输出结果如下:
由于分流开窗,每个key的每个窗口都会有一个ProcessWindowFunction,水位线也会进入process算子里面
初始 负无穷大的水位线
a 1 后面跟了一个999ms的水位线
b 5 后面跟了一个4999ms的水位线,当b的4999进入process,就会关闭a和b的窗口
输出:key:a 的窗口触发了
a 6
b 6
a 10 输出:key:b 的窗口触发了
key:a 的窗口触发了
分流会向不同的分区广播水位线。
(2) 合流
a 代码编写
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Tuple2<String, Long>> stream1 = env
.socketTextStream("localhost", 9999)
.map(new MapFunction<String, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(String value) throws Exception {
String[] arr = value.split(" ");
return Tuple2.of(arr[0], Long.parseLong(arr[1]) * 1000L);
}
})
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Tuple2<String, Long>>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<String, Long>>() {
@Override
public long extractTimestamp(Tuple2<String, Long> element, long recordTimestamp) {
return element.f1;
}
})
);
SingleOutputStreamOperator<Tuple2<String, Long>> stream2 = env
.socketTextStream("localhost", 9998)
.map(new MapFunction<String, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(String value) throws Exception {
String[] arr = value.split(" ");
return Tuple2.of(arr[0], Long.parseLong(arr[1]) * 1000L);
}
})
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Tuple2<String, Long>>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<String, Long>>() {
@Override
public long extractTimestamp(Tuple2<String, Long> element, long recordTimestamp) {
return element.f1;
}
})
);
stream1
.union(stream2)
.process(new ProcessFunction<Tuple2<String, Long>, String>() {
@Override
public void processElement(Tuple2<String, Long> value, Context ctx, Collector<String> out) throws Exception {
out.collect("当前水位线是:" + ctx.timerService().currentWatermark());
}
})
.print();
env.execute();
}
b 测试
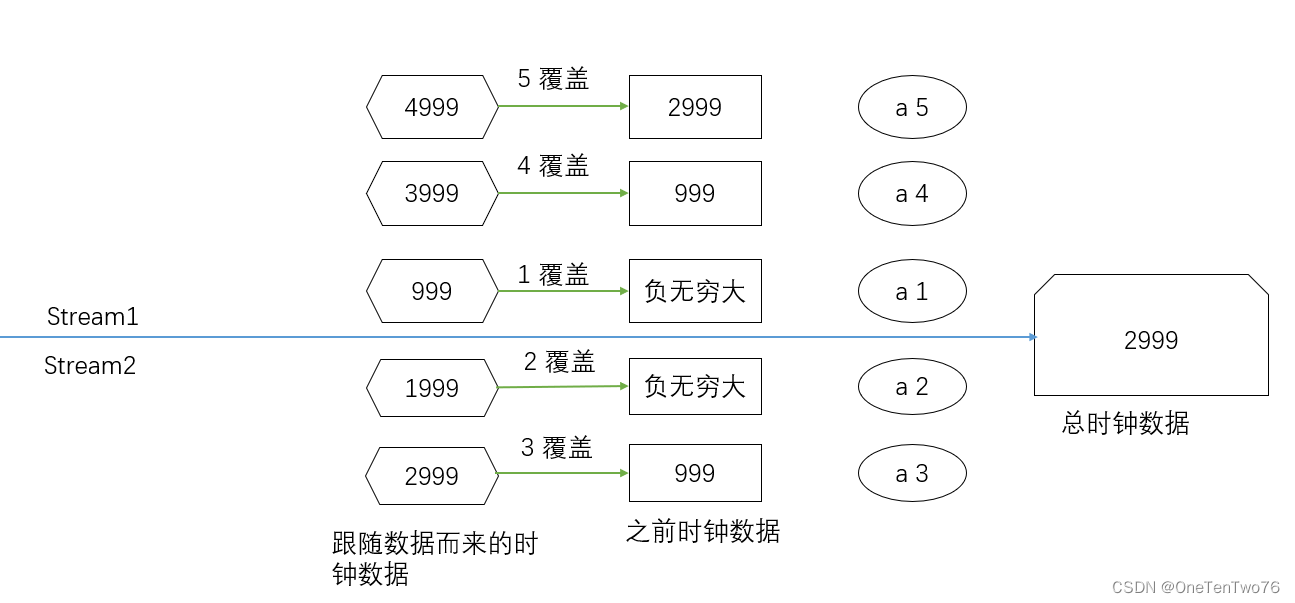
在流一种输入a 1,流二中输入a 2、a 3,流一中输入a 4、a 5。
监控9999和9998端口
9999:
负无穷大水位线
a 1 到达后200ms,后面会跟随着一个999ms的水位线,首先输出当前水位线
输出:当前水位线是:-9223372036854775808
并覆盖掉自己的负无穷大时钟,更新算子时钟min(-MAX,999),仍然为负无穷大
a 4 到达后200ms,后面会跟随着一个3999的水位线,首先选择两条流中较小的水位线输出,min(999,3999)
输出:当前水位线是:999
并覆盖掉自己的999时钟,更新算子时钟min(2999,3999)为2999
a 5 到达后200ms,后面会跟随着一个4999的水位线,首先选择两条流中较小的水位线输出,min(2999,3999)
输出:当前水位线是:2999
并覆盖掉自己的3999时钟,更新算子时钟min(2999,4999)为2999
9998:
负无穷大水位线
a 2 到达后200ms,后面会跟随着一个1999ms的水位线,首先输出当前水位线
输出:当前水位线是:-9223372036854775808
并覆盖掉自己的负无穷大时钟,更新算子时钟min(1999,999),为999
a 3 到达后200ms,后面会跟随着一个2999ms的水位线,首先选择两条流中较小的水位线,min(999,1999)输出
输出:当前水位线是:999
并覆盖自己的1999ms时钟,更新算子时钟min(999,2999)为999
元素到来首先调用processElement,水位线到来,更新时钟。
分析过程如下图:
3 connect算子
union算子用于两条流的合并,两条流中的元素类型可以不同。
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Example1.Event> clickStream = env.addSource(new Example1.ClickSource());
DataStreamSource<String> queryStream = env.socketTextStream("localhost", 9999).setParallelism(1);
clickStream
.keyBy(r -> r.user)
// 和查询流的广播流进行连接,即对点击流的每一个分区都广播一份
// 实现在查询流中输入./home可以将用户访问./home的数据过滤出来
// 这也是为什么要连接查询流的广播流
.connect(queryStream.broadcast())
// 依次为第一条流、第二条流、输出的泛型
// CoFlatMapFunction是和FlatMapFunction对应的一种接口,不是复函数
// 功能相对受限,没有办法注册定时器、状态变量
.flatMap(new CoFlatMapFunction<Example1.Event, String, Example1.Event>() {
private String query = "";
// 不同元素类型的两条流合并到了一起
// 第一条流中的元素调用flatMap1方法,反之调用flatMap2方法
@Override
public void flatMap1(Example1.Event value, Collector<Example1.Event> out) throws Exception {
if(value.url.equals(query)) out.collect(value);
}
@Override
public void flatMap2(String value, Collector<Example1.Event> out) throws Exception {
query = value;
}
})
.print();
env.execute();
}
可以随时在查询流中改变想要查找的内容,查询流和点击流合并,不满足条件的数据会被放弃掉,无法查找以前的数据。
connect一般用于两条流都进行keyBy,即将两条数据相同分区的数据进行合流处理;要么一条流进行keyBy,另一条流进行广播,类似于spark中的广播变量(使用不同key将数据shuffle到了不同的分区,针对每一个分区广播一个变量),只不过这里针对的对象是流,流中的每一条元素进行复制,广播到所有分区。





![[附源码]计算机毕业设计JAVA小说网站的设计与实现1](https://img-blog.csdnimg.cn/d5b0a6b2160e46d88ccb73874113b208.png)